Downloaded 14 times









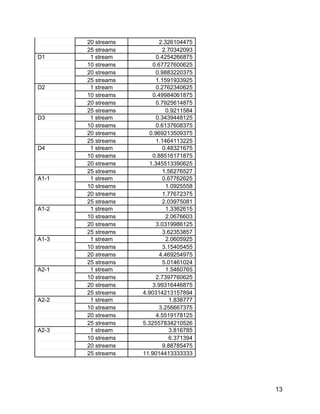


This document summarizes the results of performance tests conducted on SAP HANA to demonstrate its efficiency and scalability for real-time business intelligence (BI) queries on large datasets. Key findings include: - HANA processed a 100TB dataset representing 5 years of sales data across a 16-node cluster, with queries returning results in under 4 seconds. - Throughput testing showed HANA could process over 52,000 queries per hour under mixed concurrent workloads. - HANA achieved over 20x data compression and was able to analyze the entire dataset without additional configuration or tuning.






















































































