Downloaded 52 times







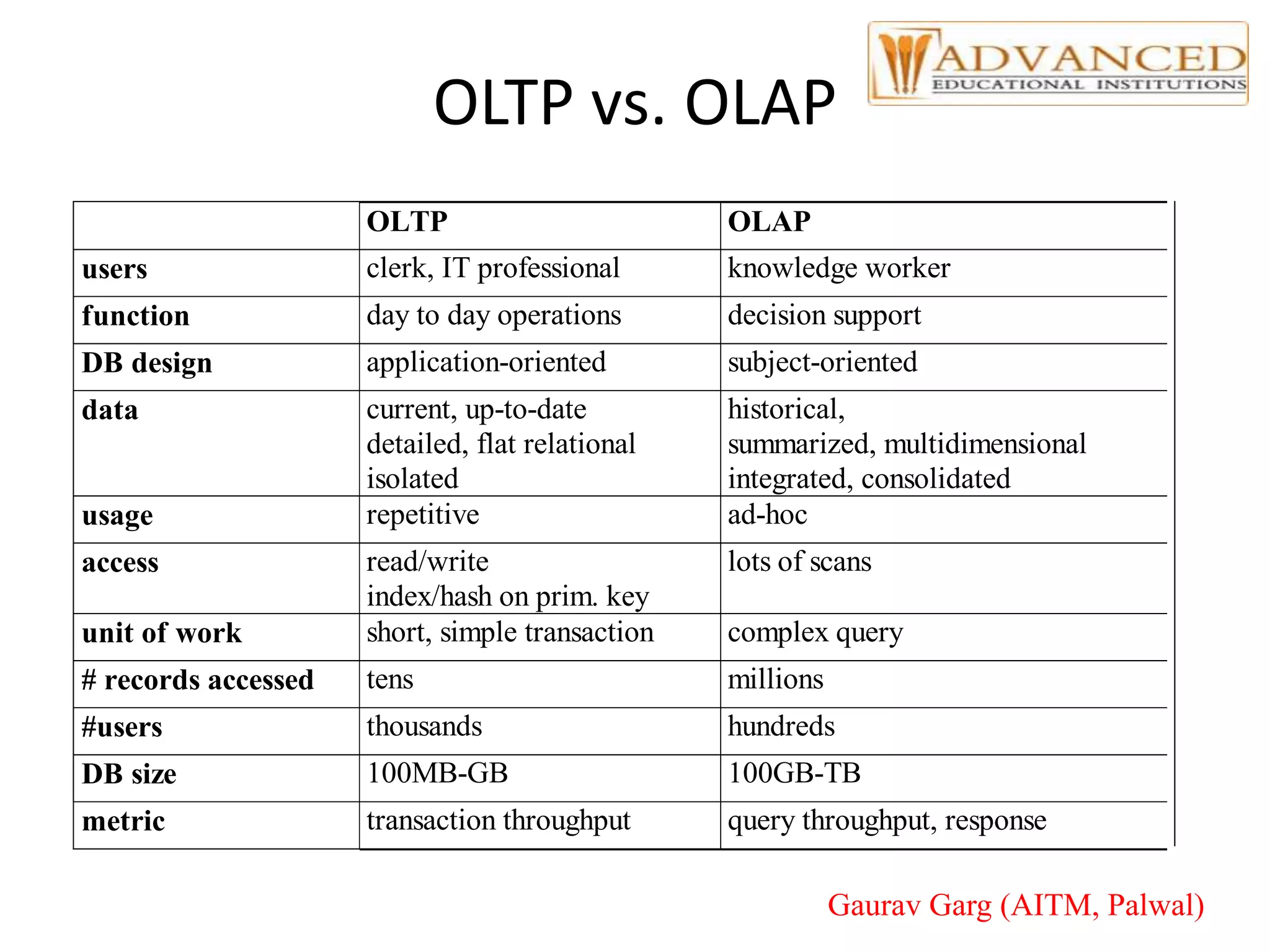



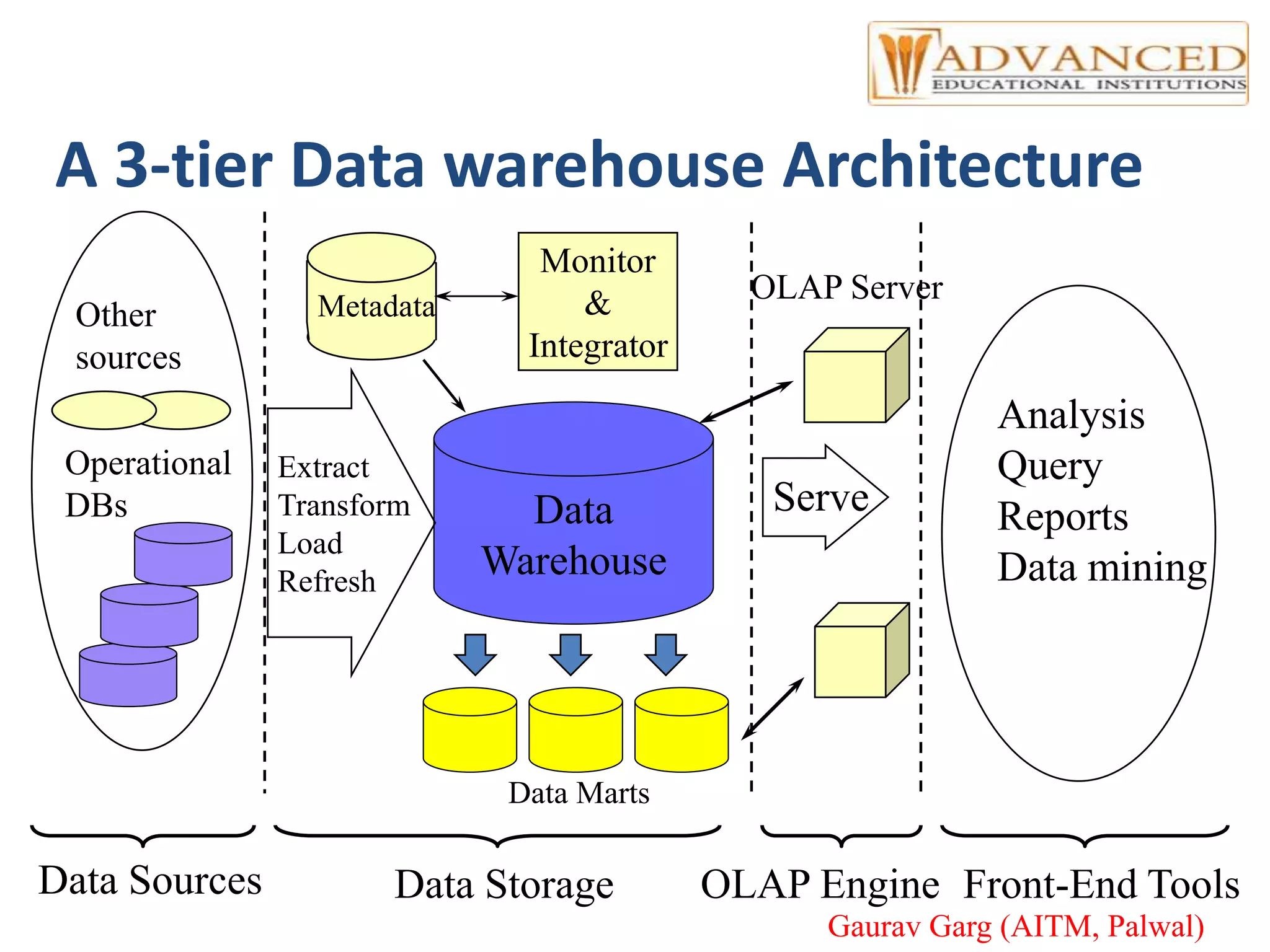







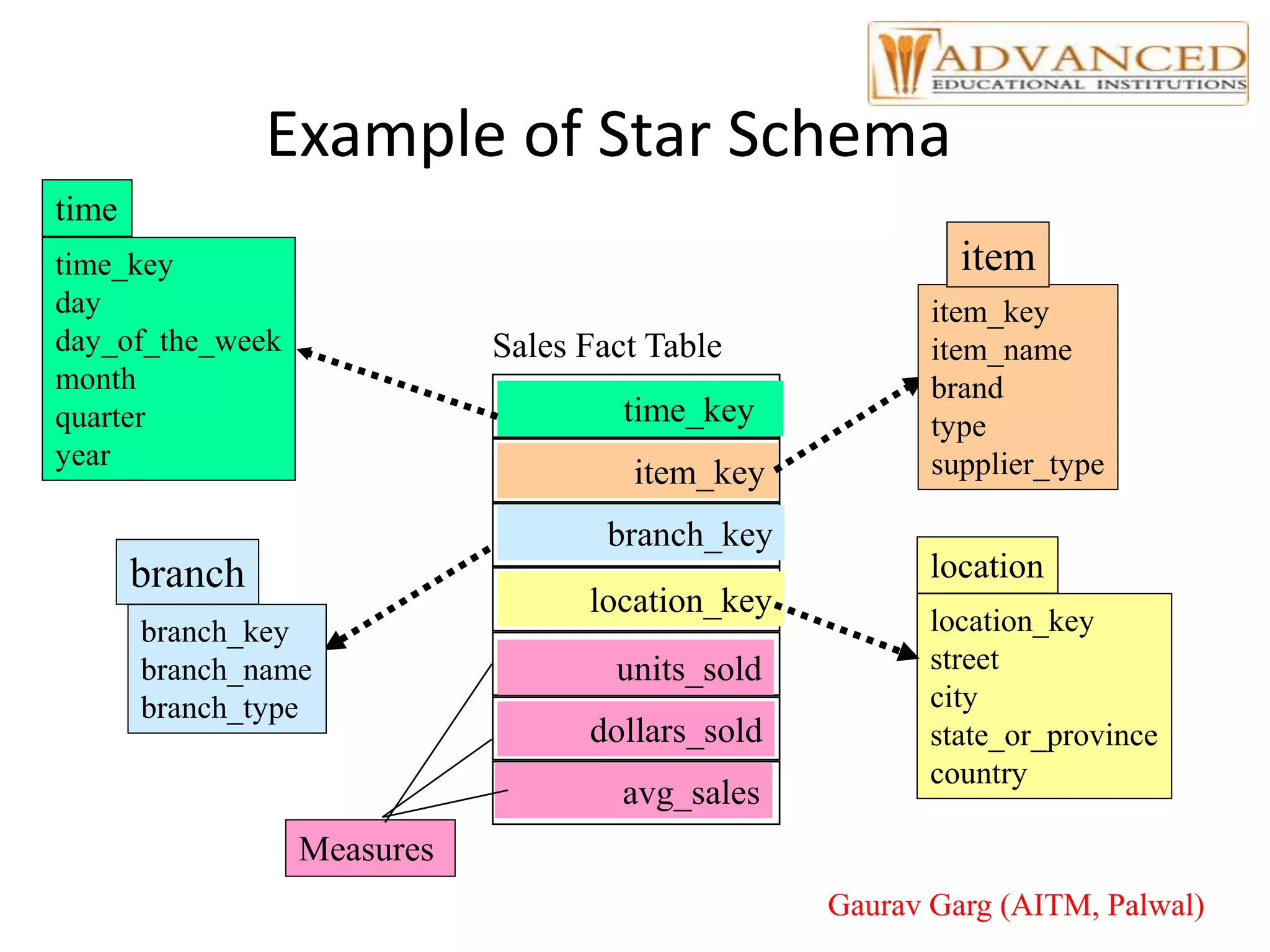
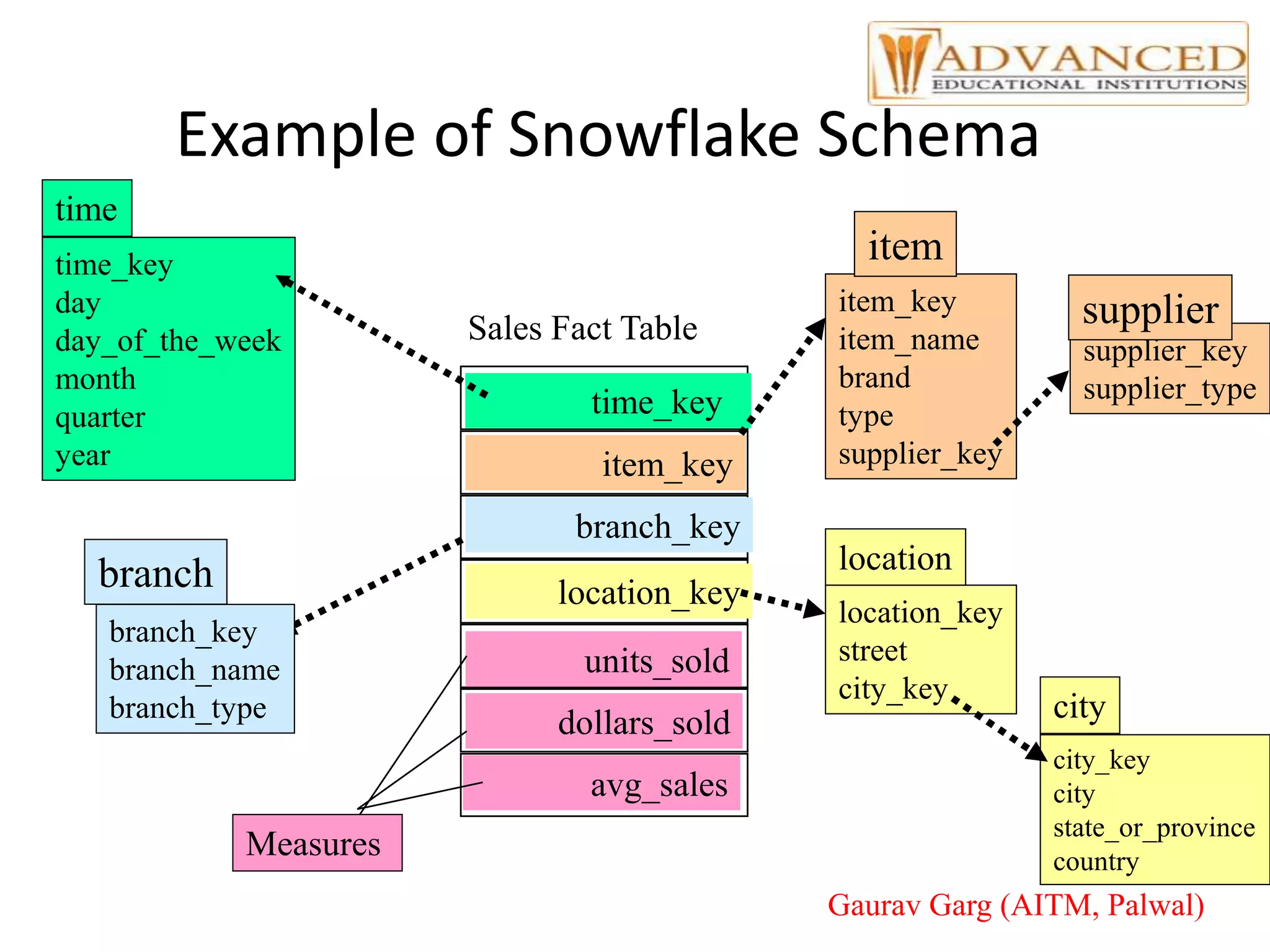

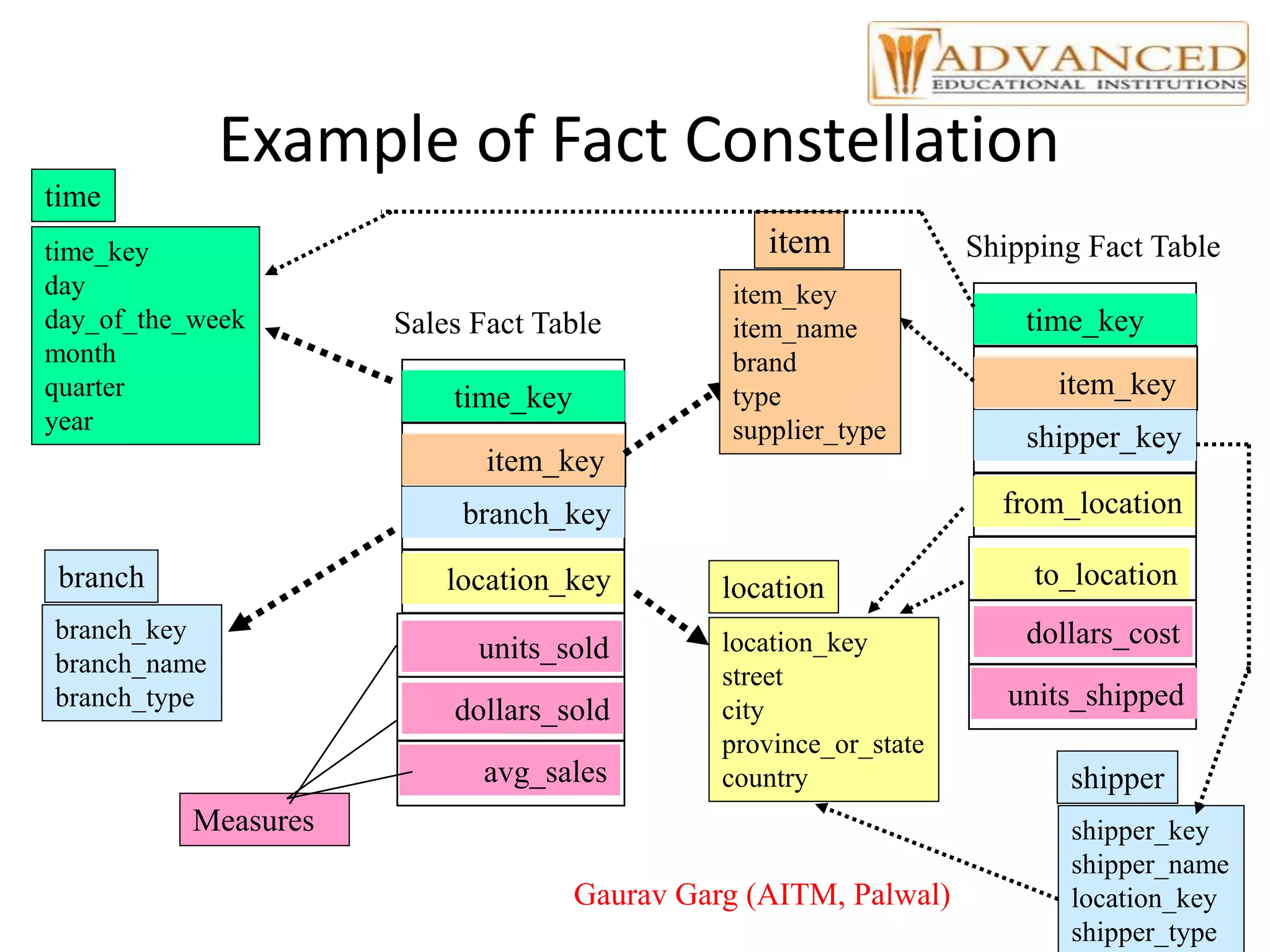





The document provides a comprehensive overview of data warehousing, highlighting its definition, architecture, and the differences between operational databases and data warehouses. It discusses the key concepts of OLAP, data marts, and the backend processes involved in data extraction, transformation, and loading (ETL). Additionally, it covers schema types, multidimensional data models, and partitioning techniques for optimizing performance in large data warehouses.



































































