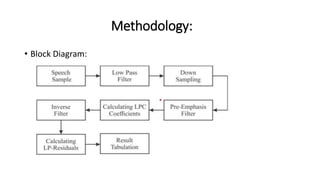
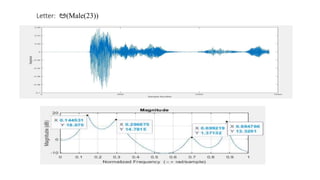
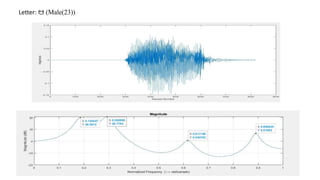
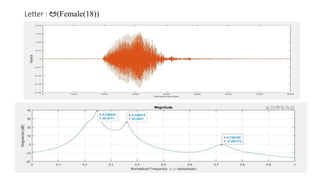
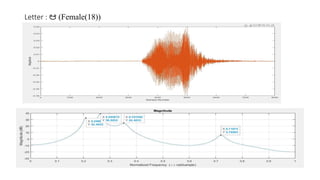
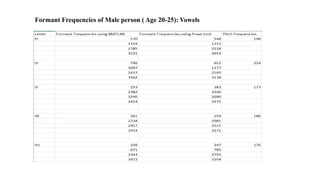
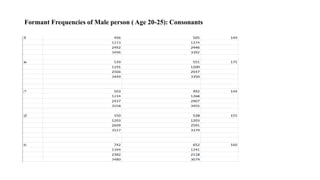
The document explores the application of Linear Predictive Coding (LPC) for estimating formant frequencies of Kannada speech sounds, aiming to enhance understanding of the spectral characteristics of the vocal tract. It outlines the project objectives, methodology, and literature survey, detailing various studies on Kannada phonetics and LPC analysis. The findings reveal variations in formant frequencies across different genders and age groups, highlighting the importance of LPC in speech processing tasks such as recognition and synthesis.