Download as KEY, PPTX




















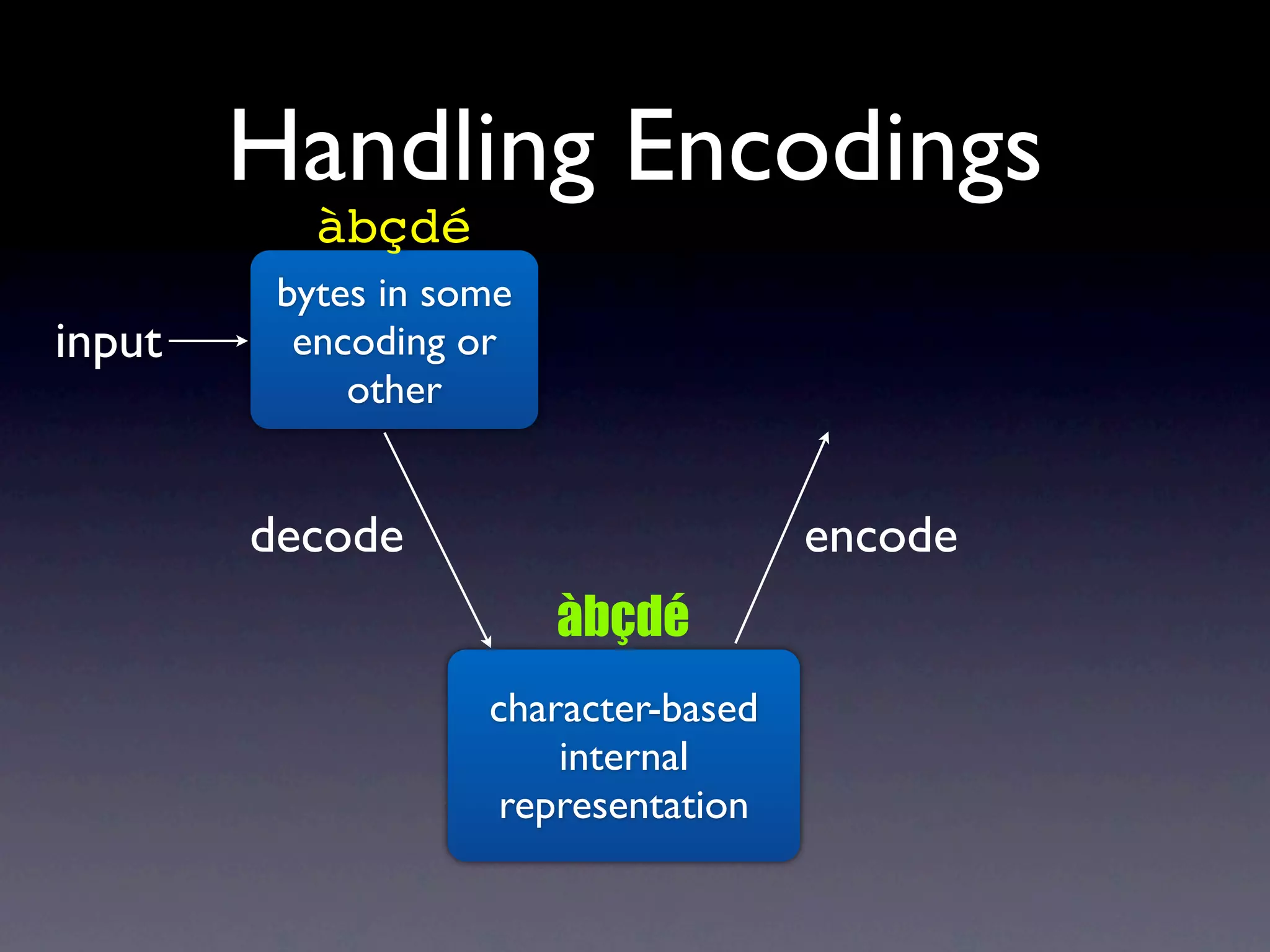
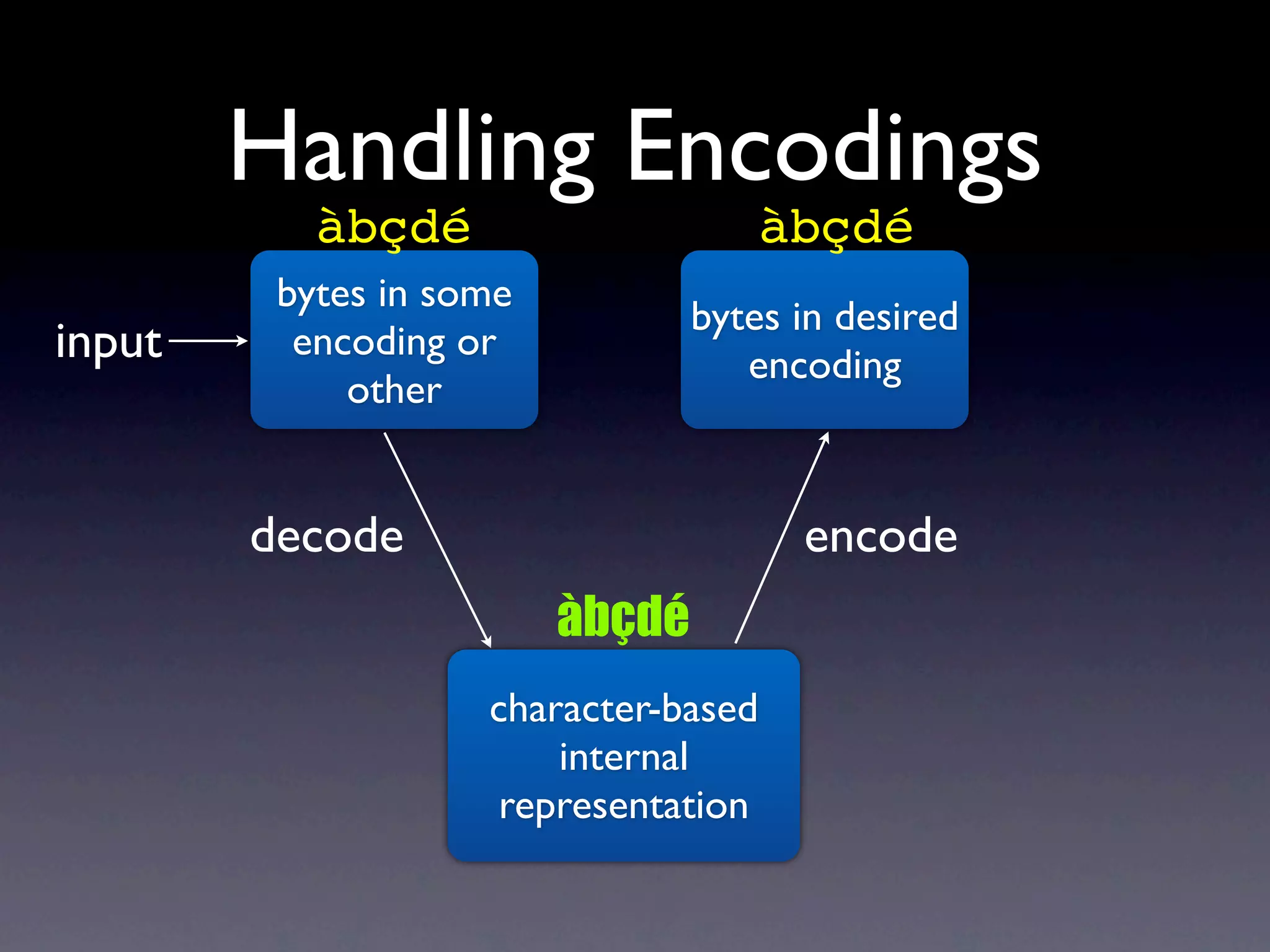
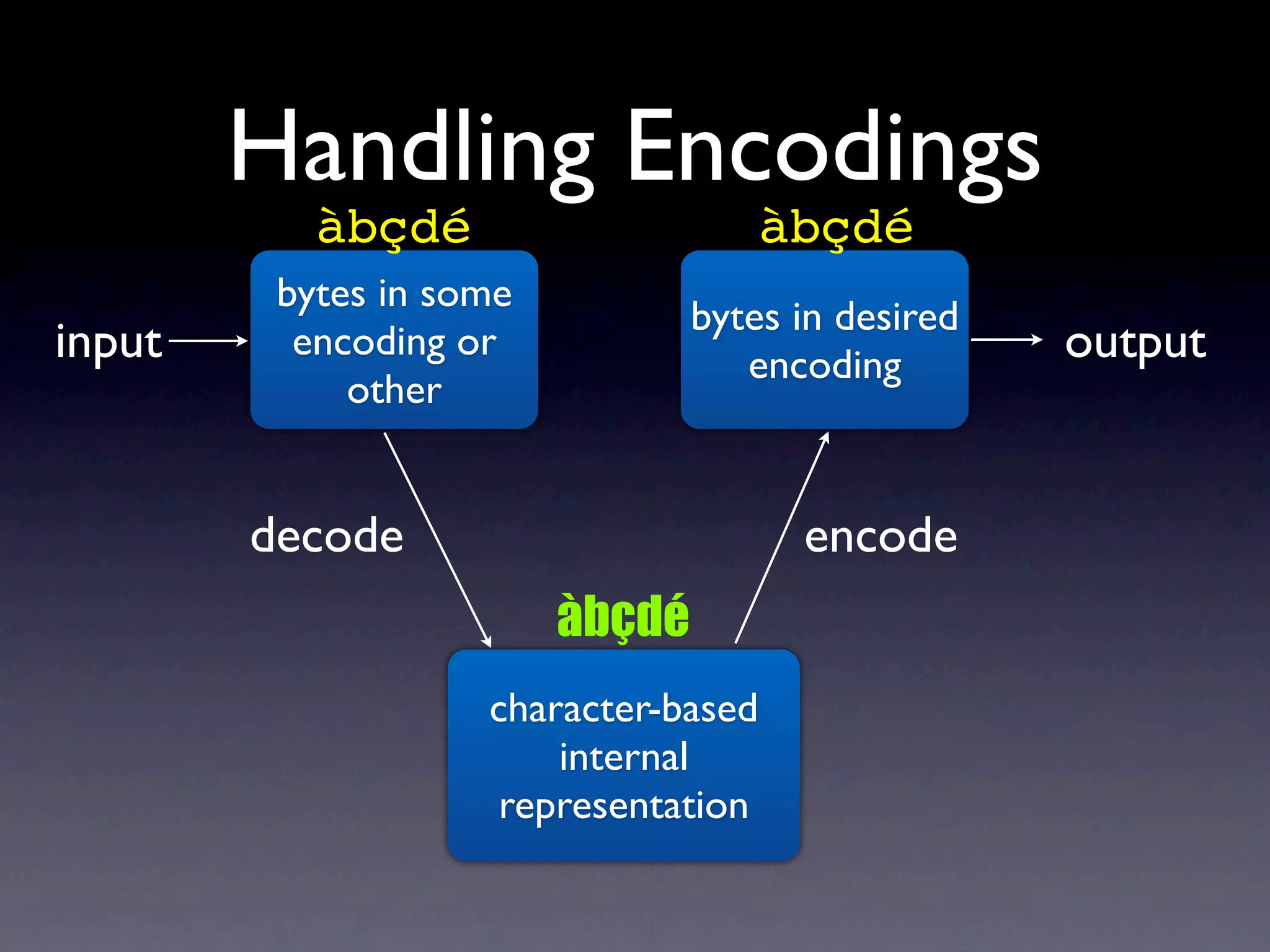
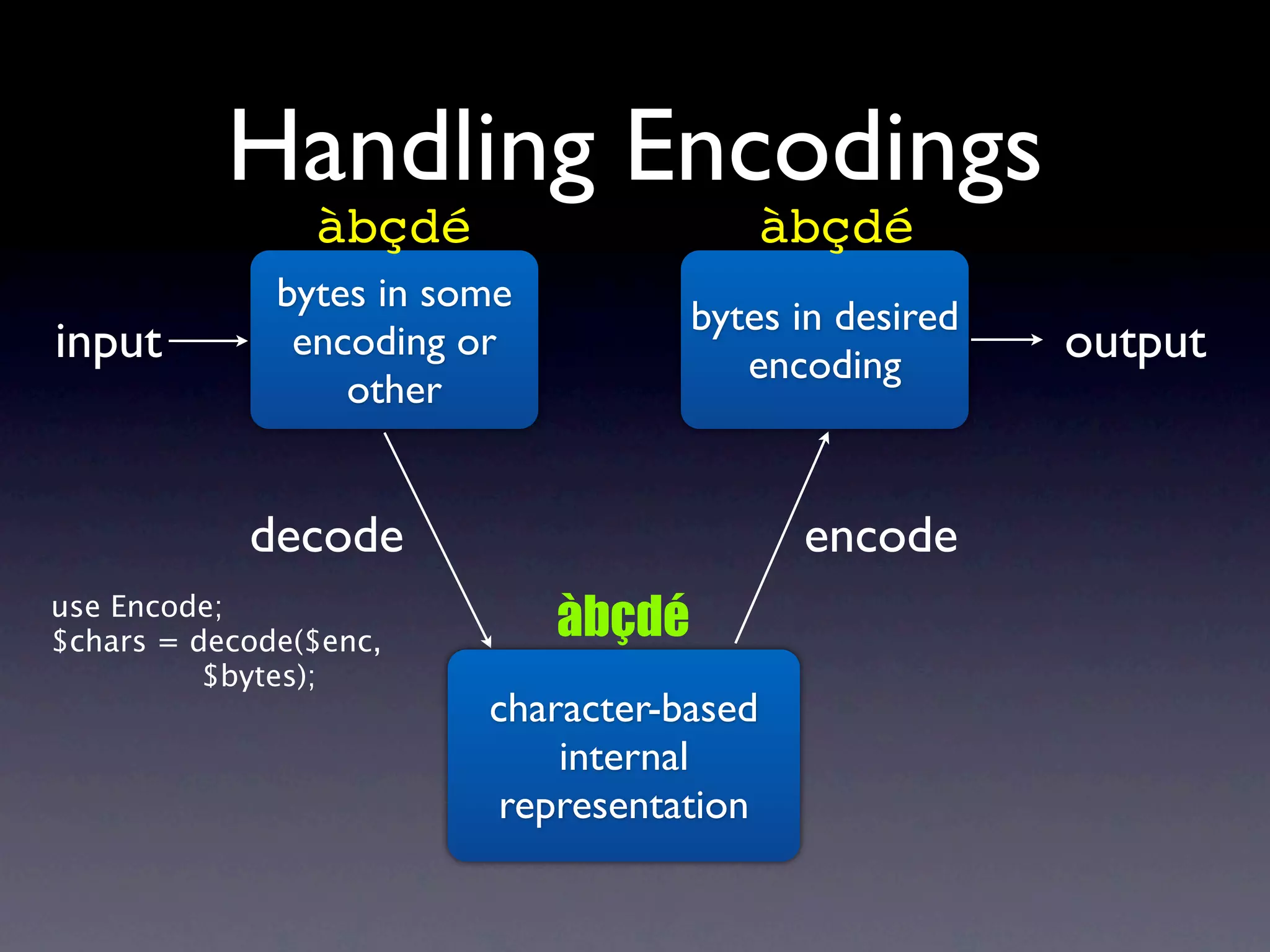
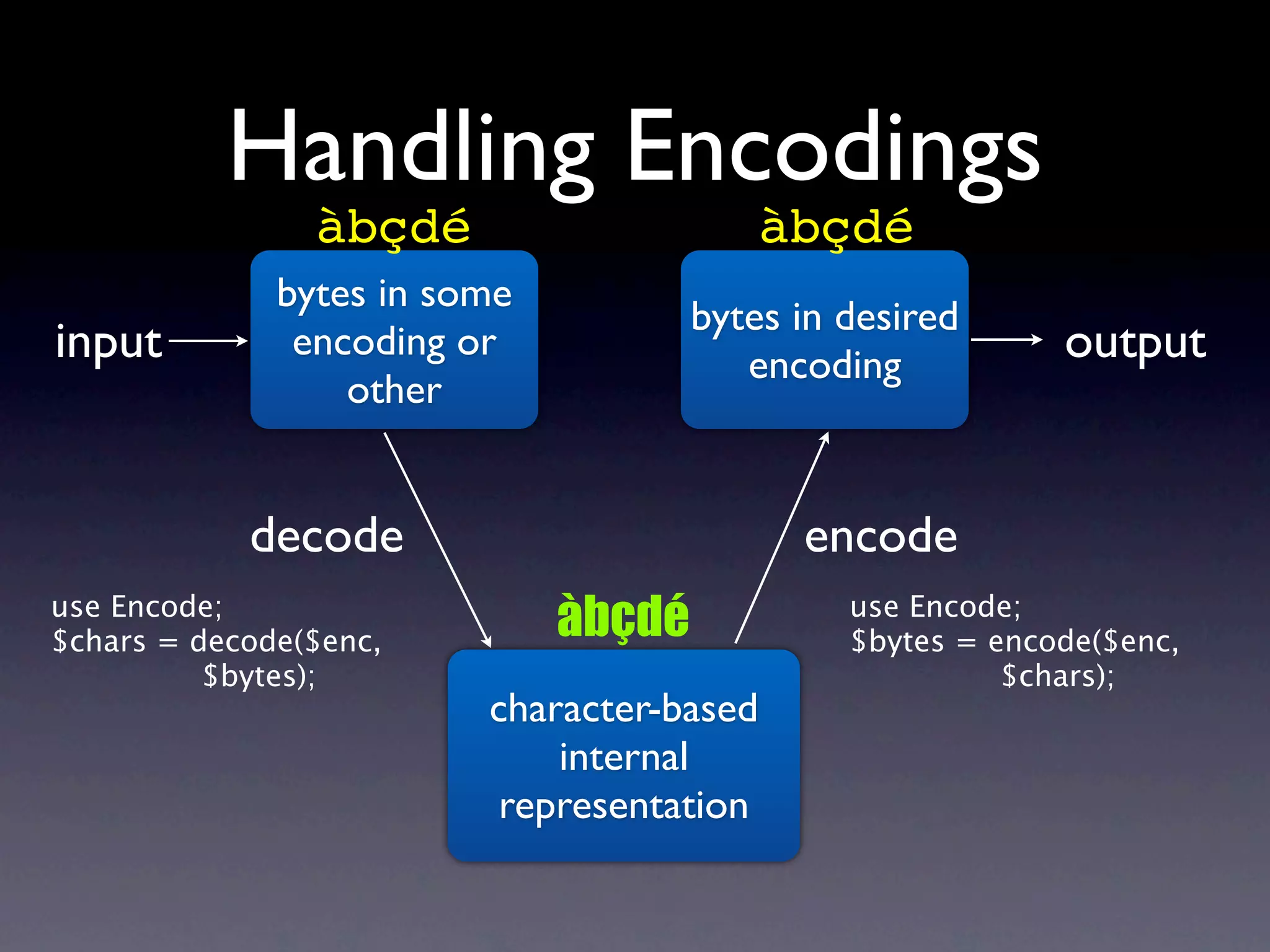


















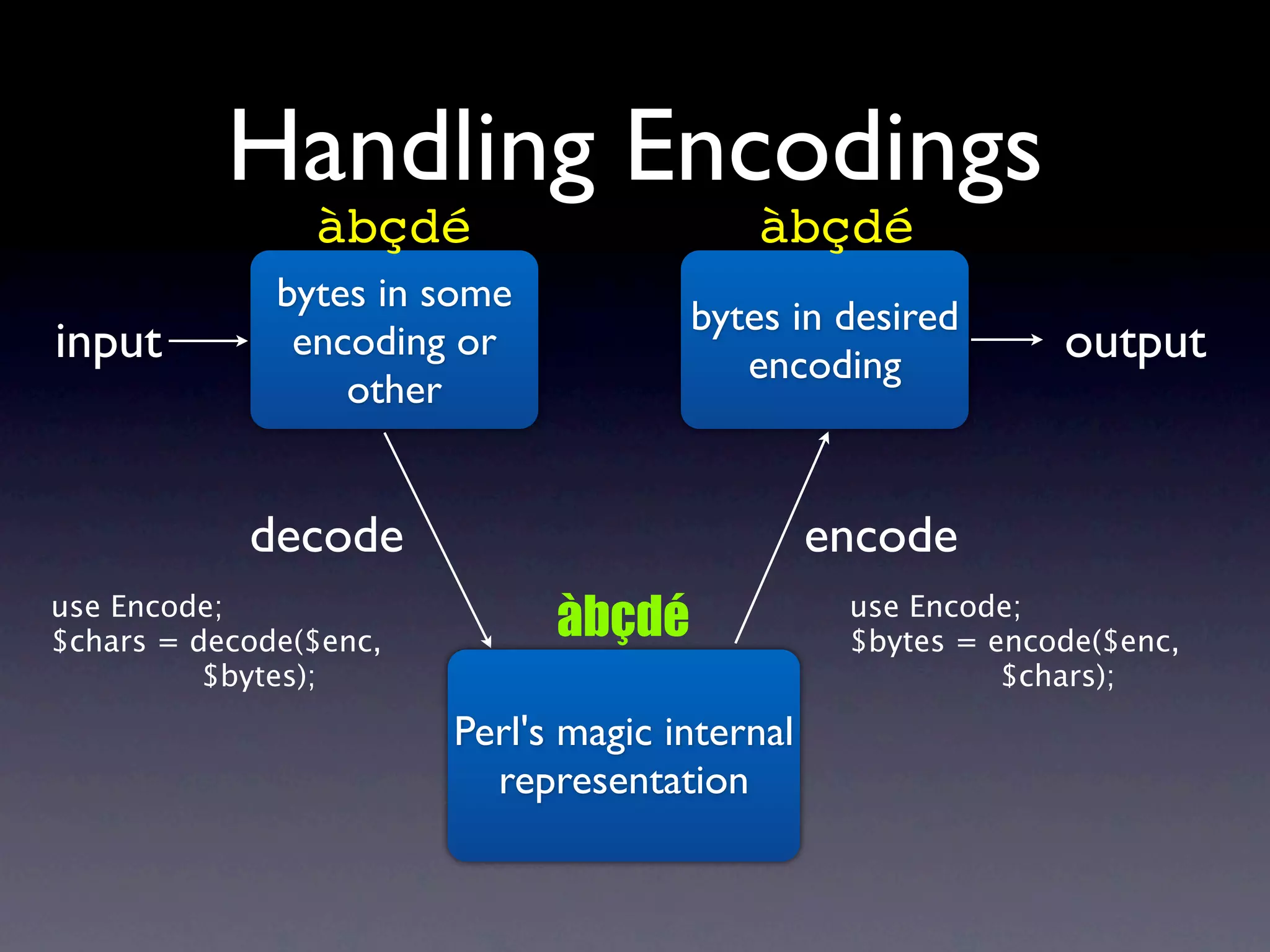
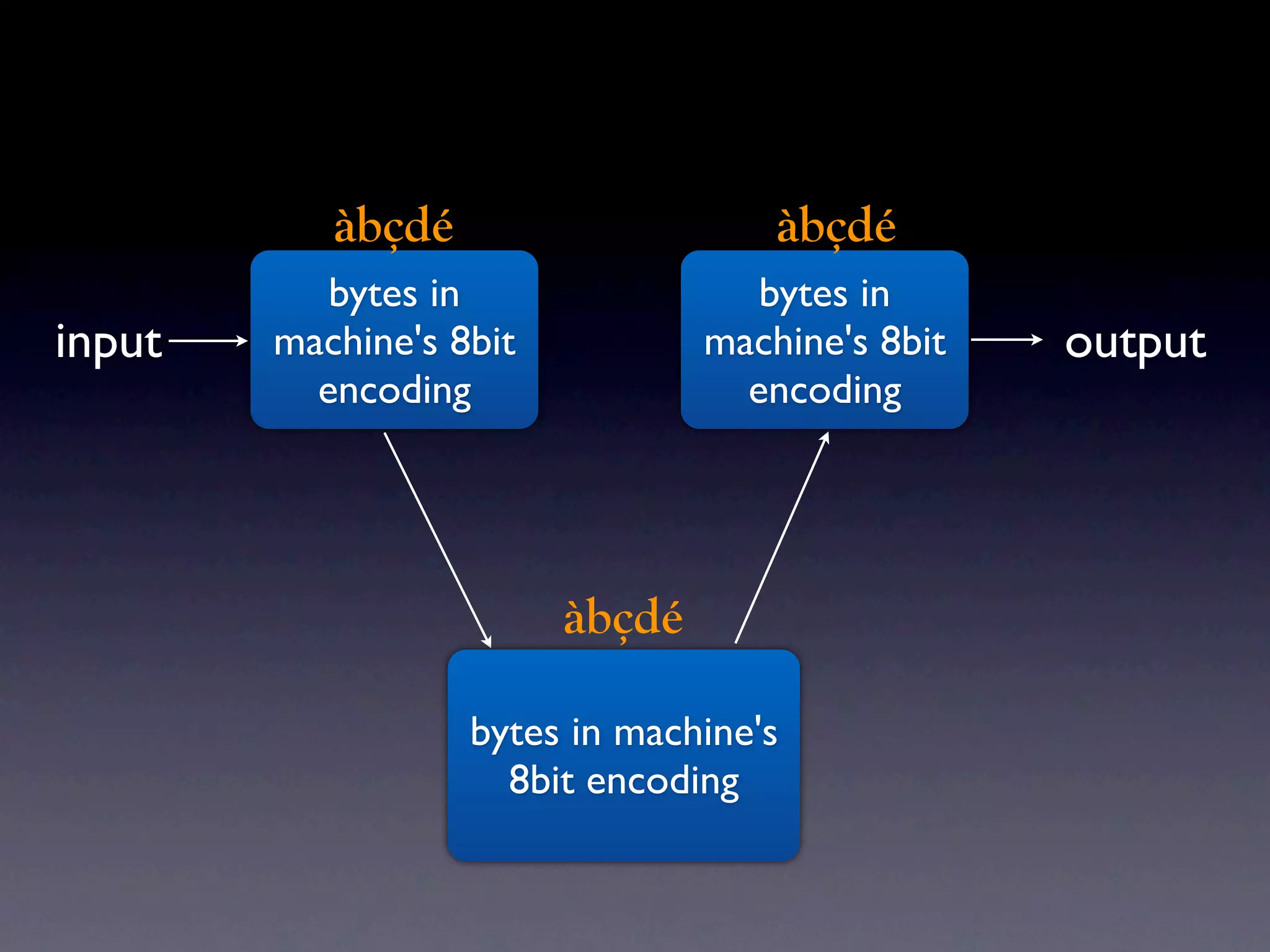
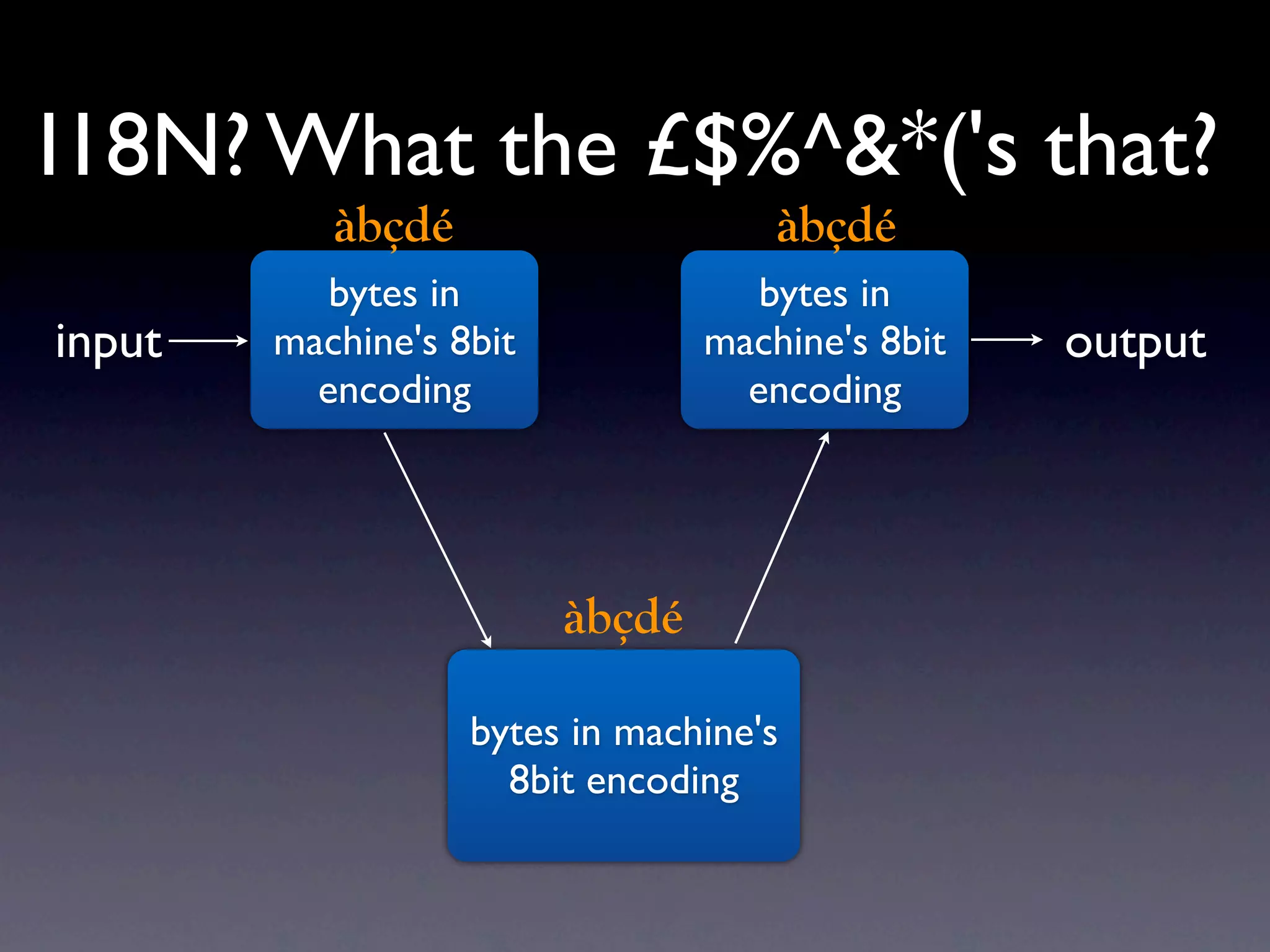












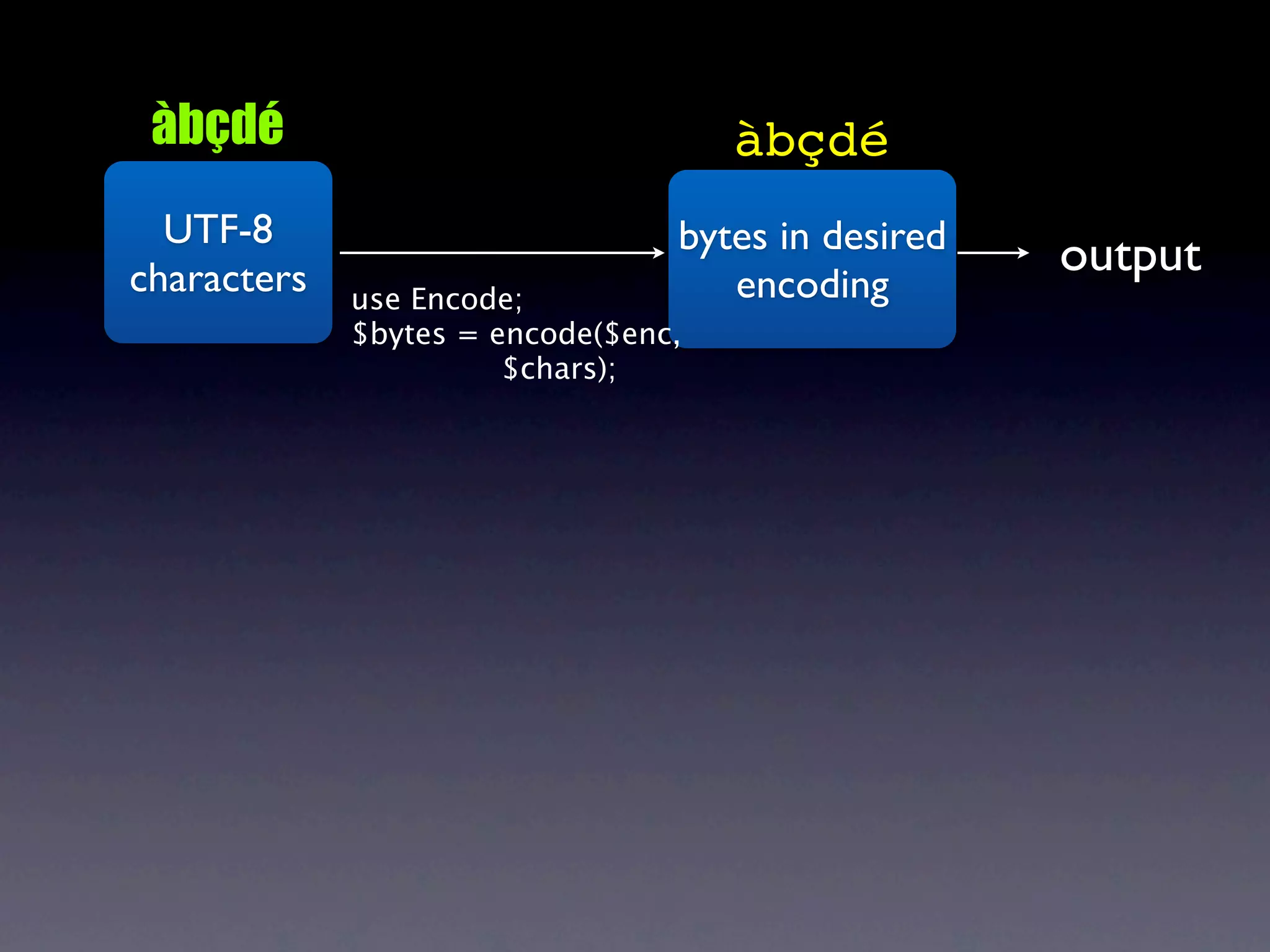
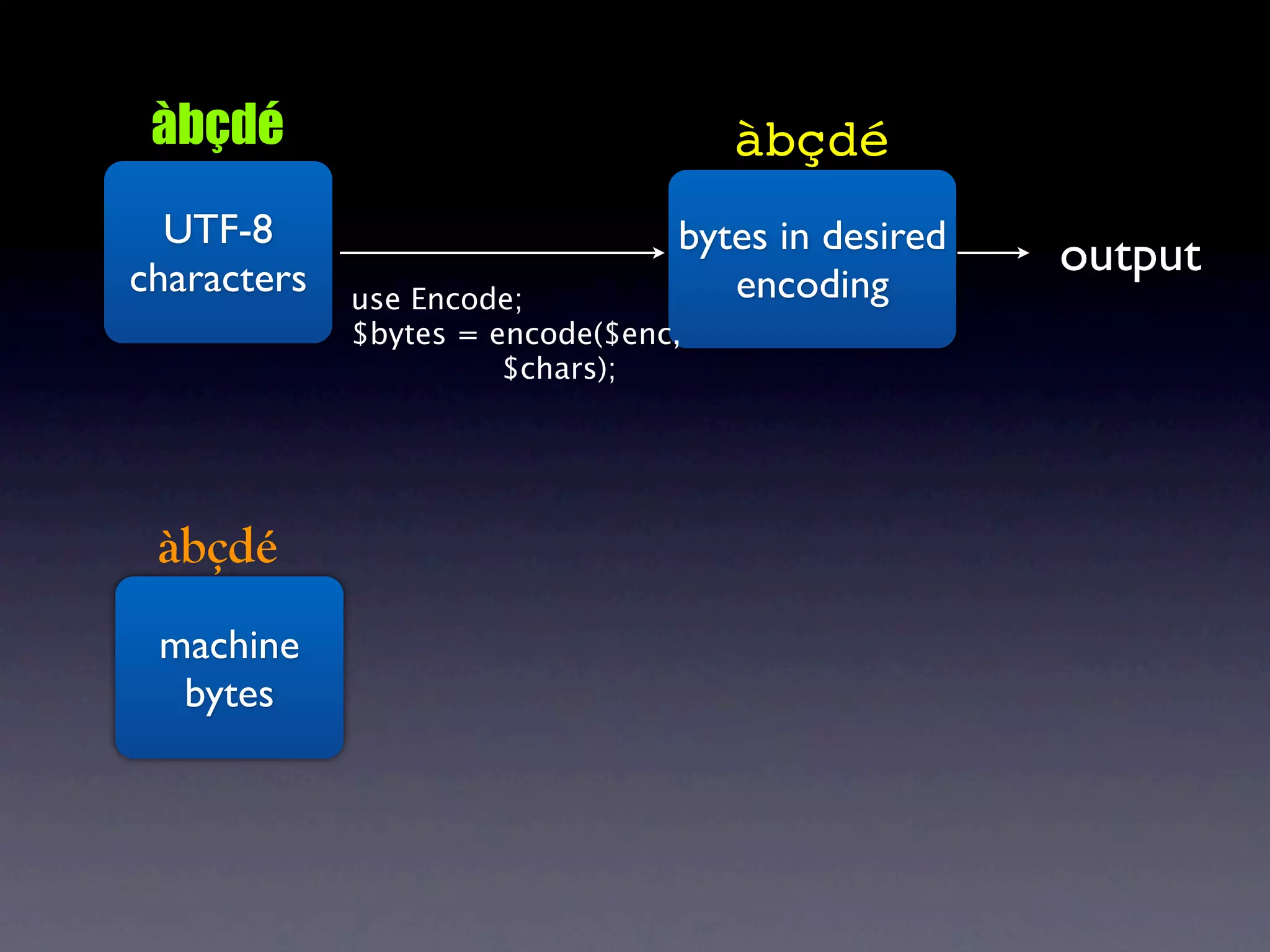
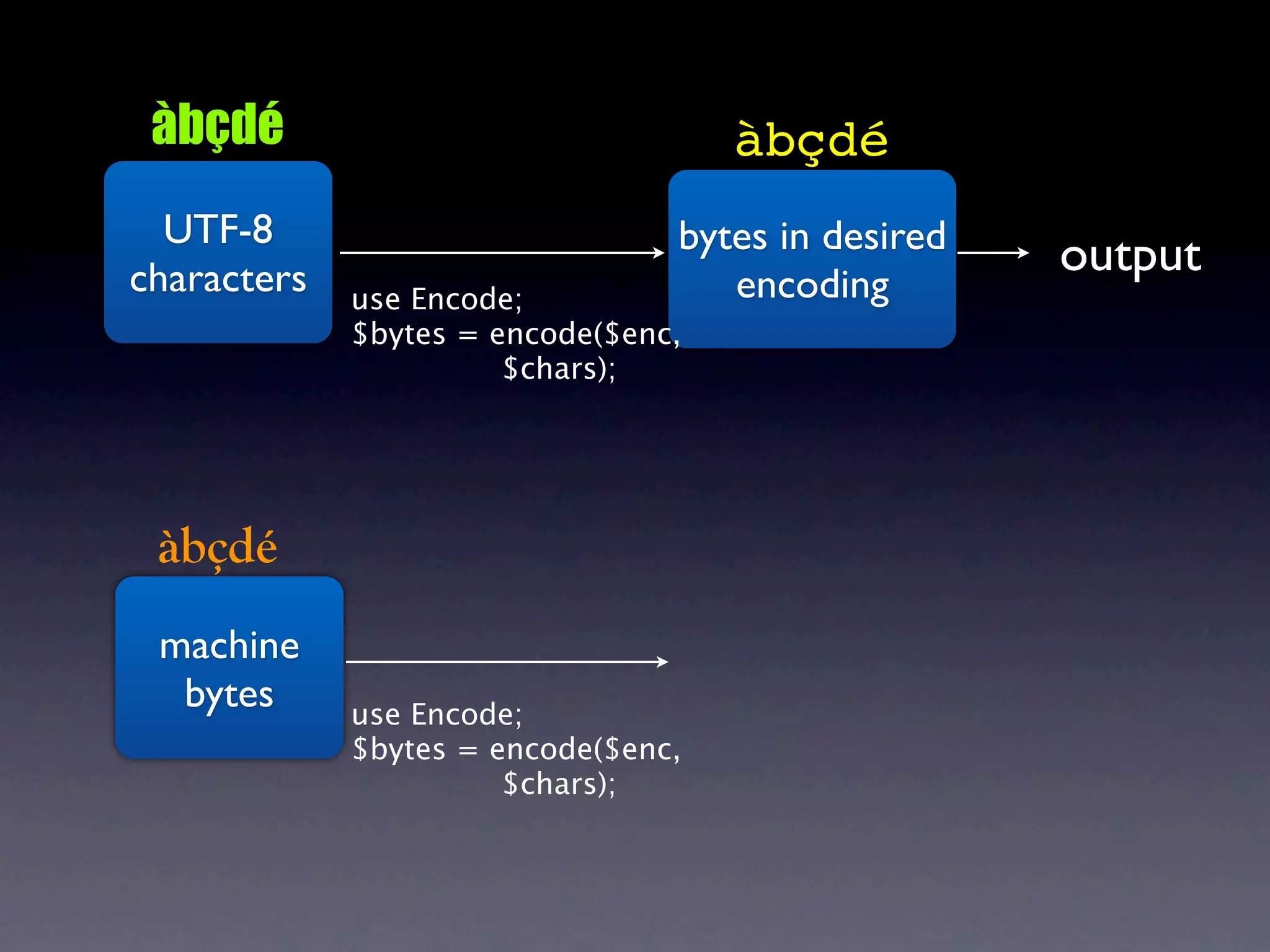
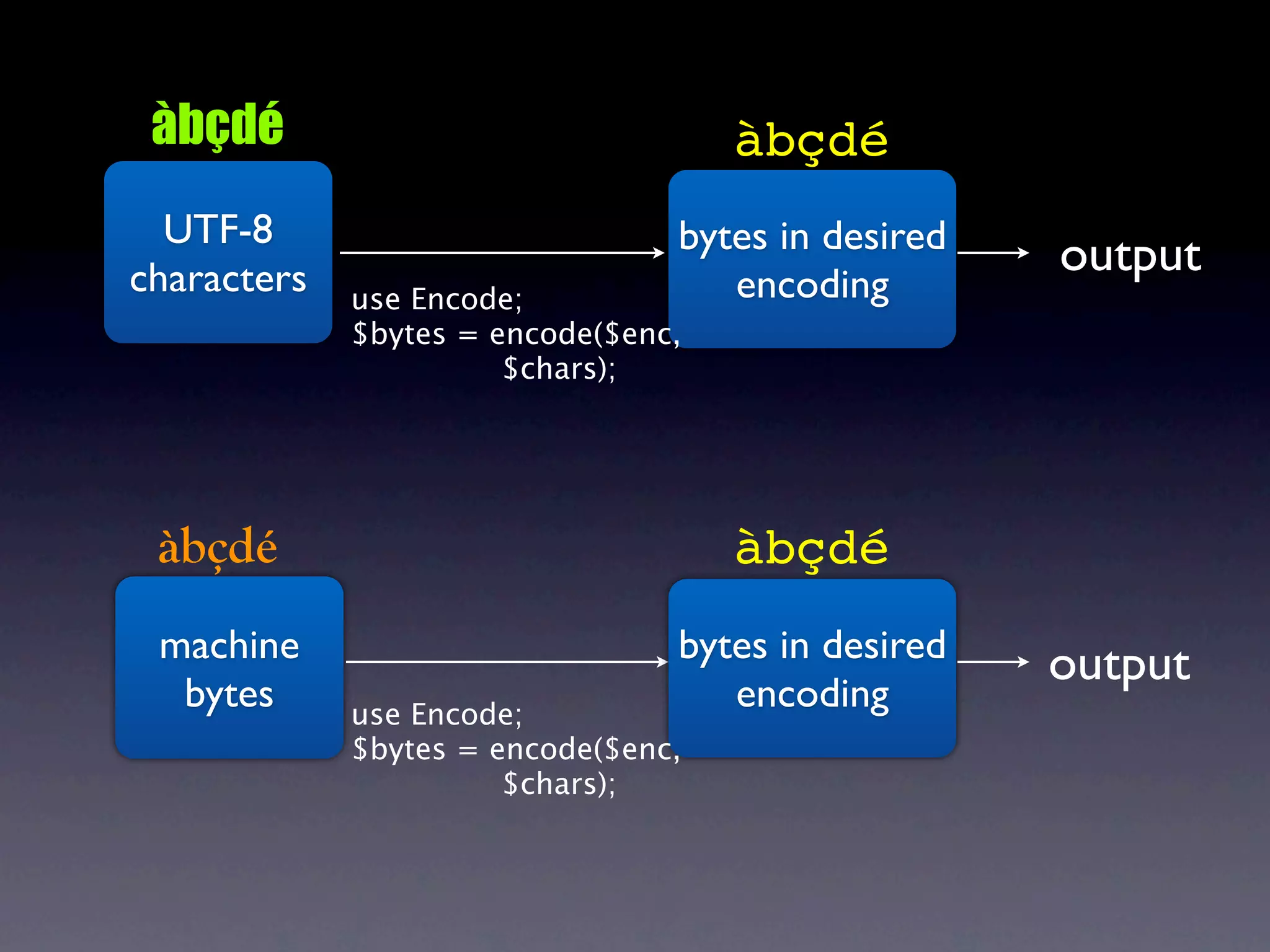



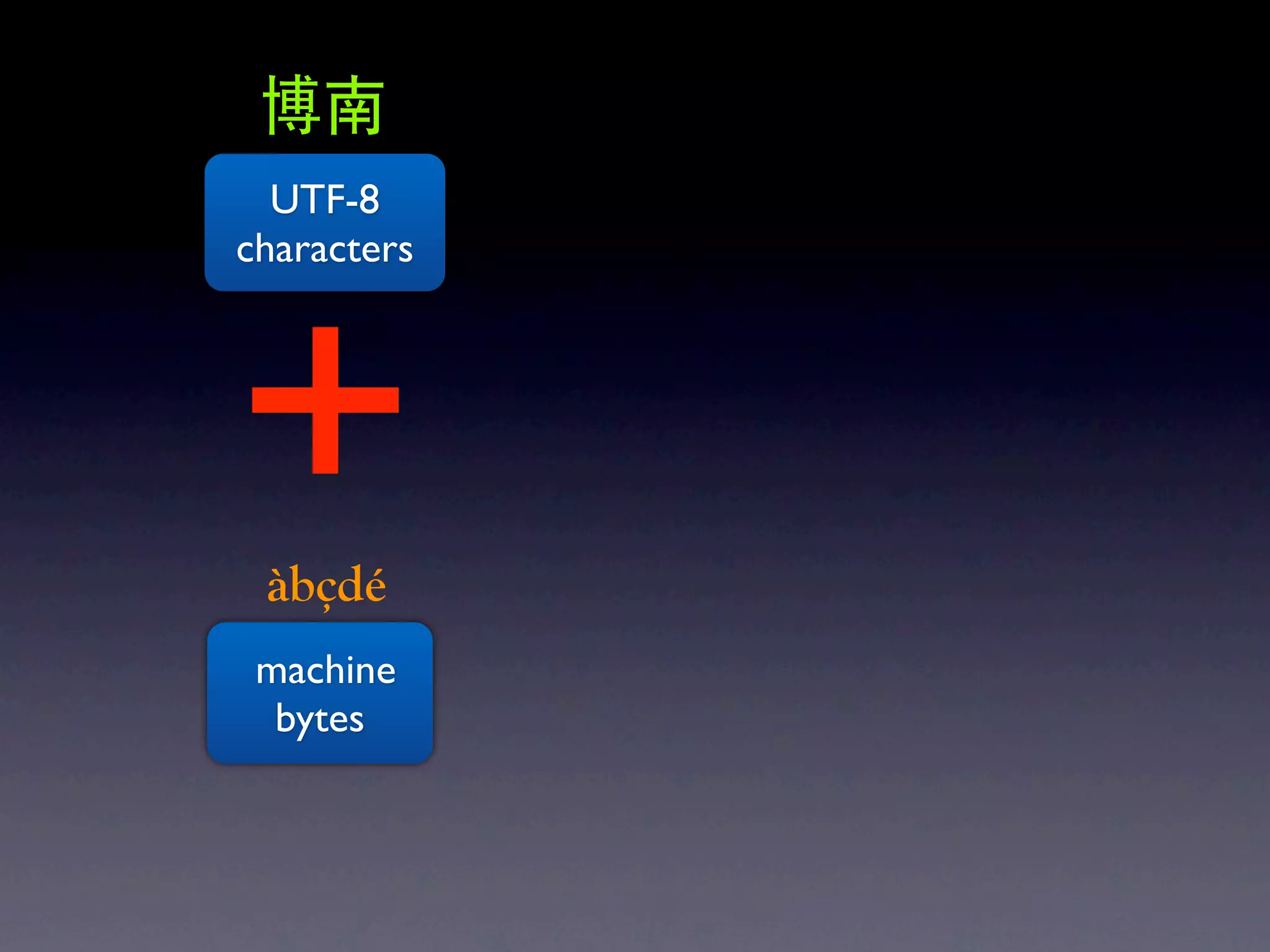
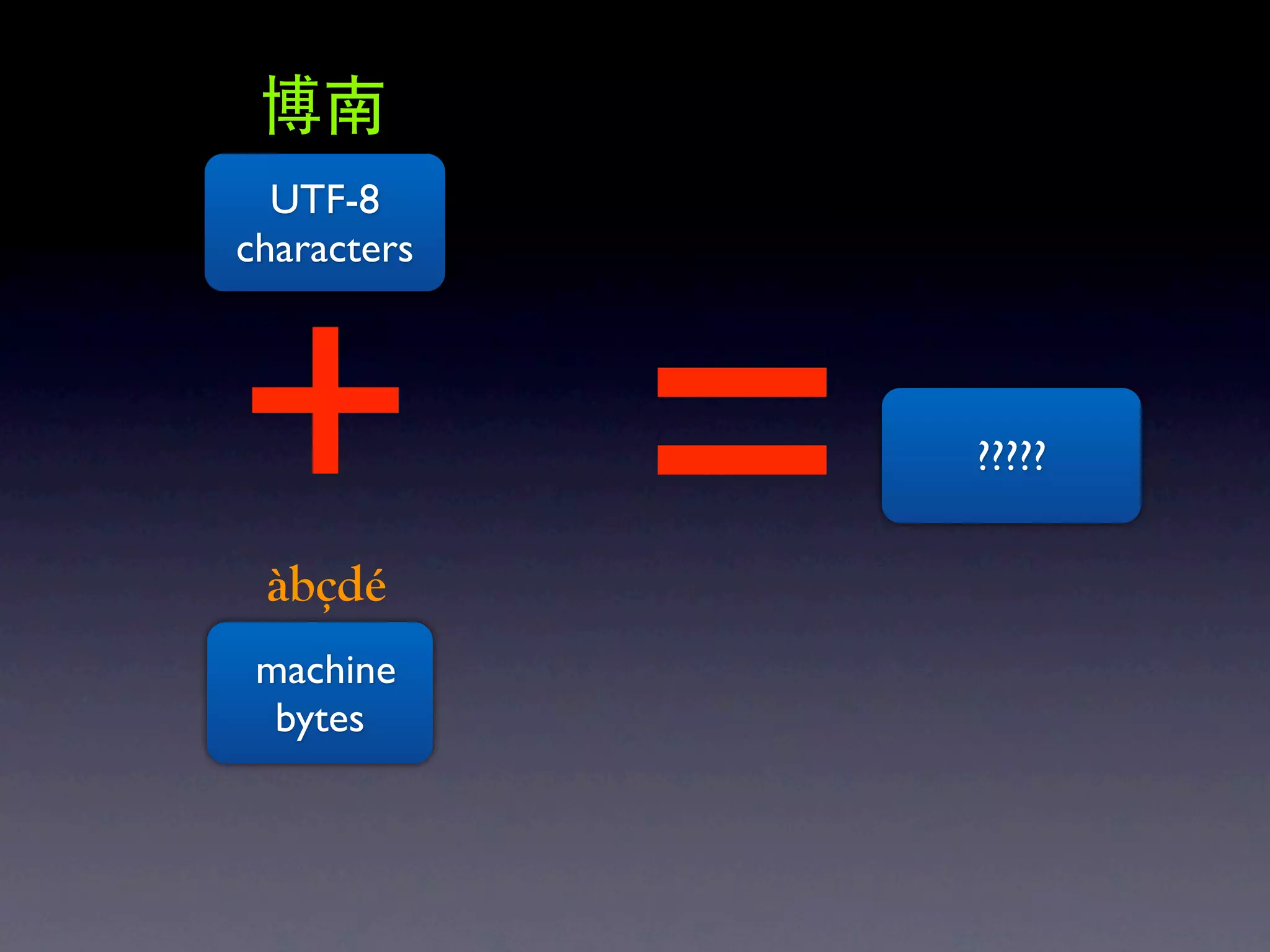

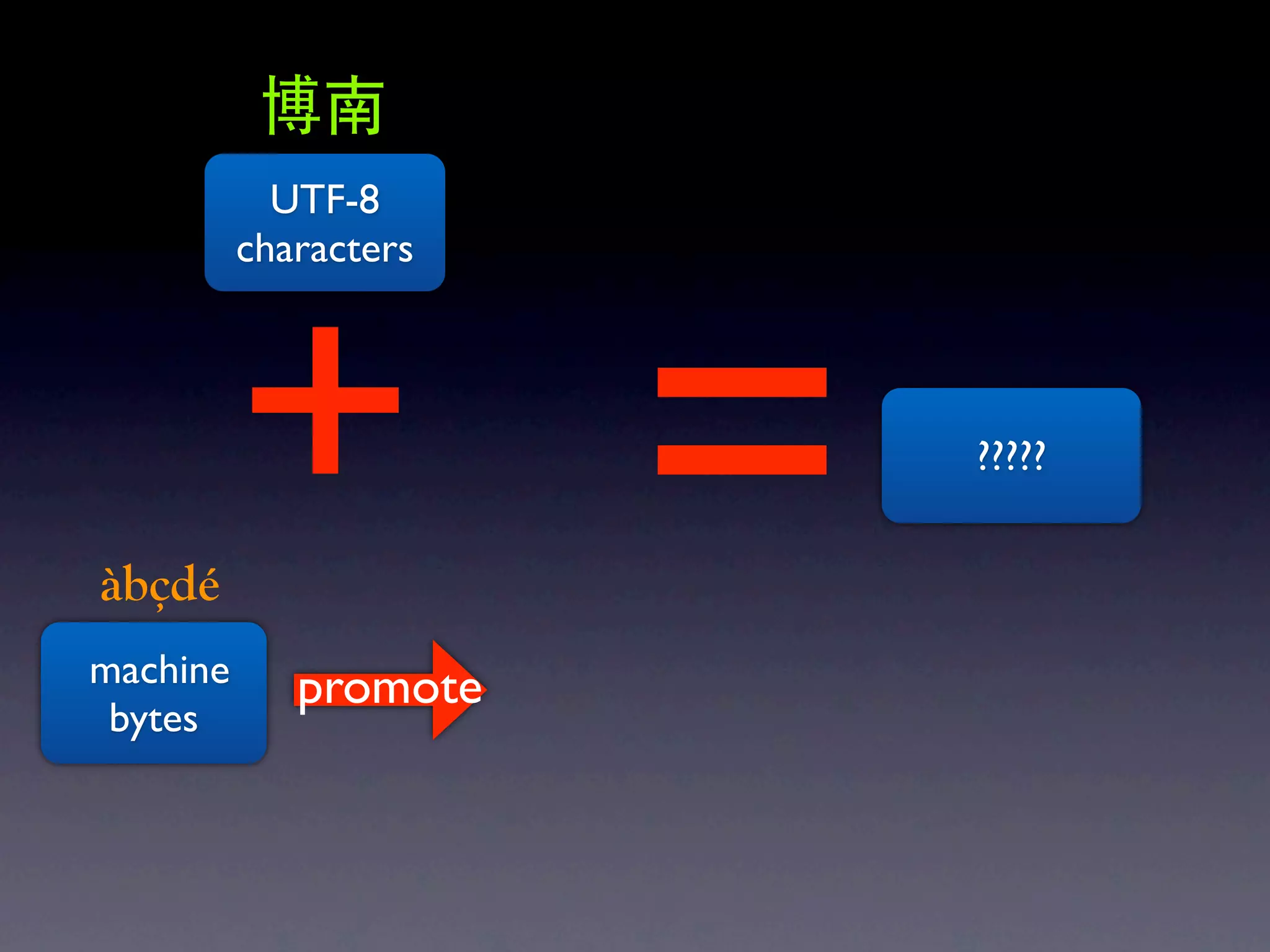
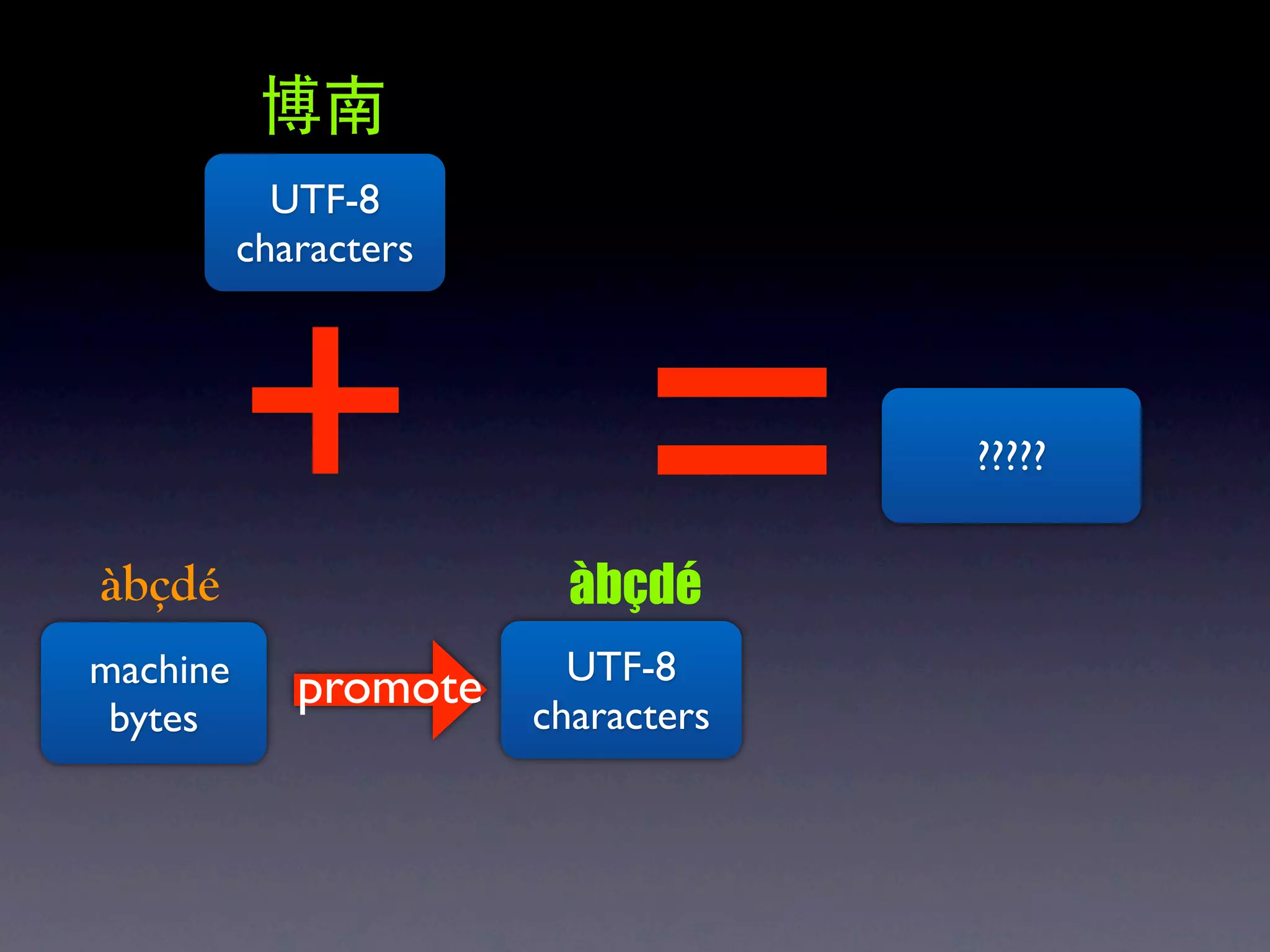
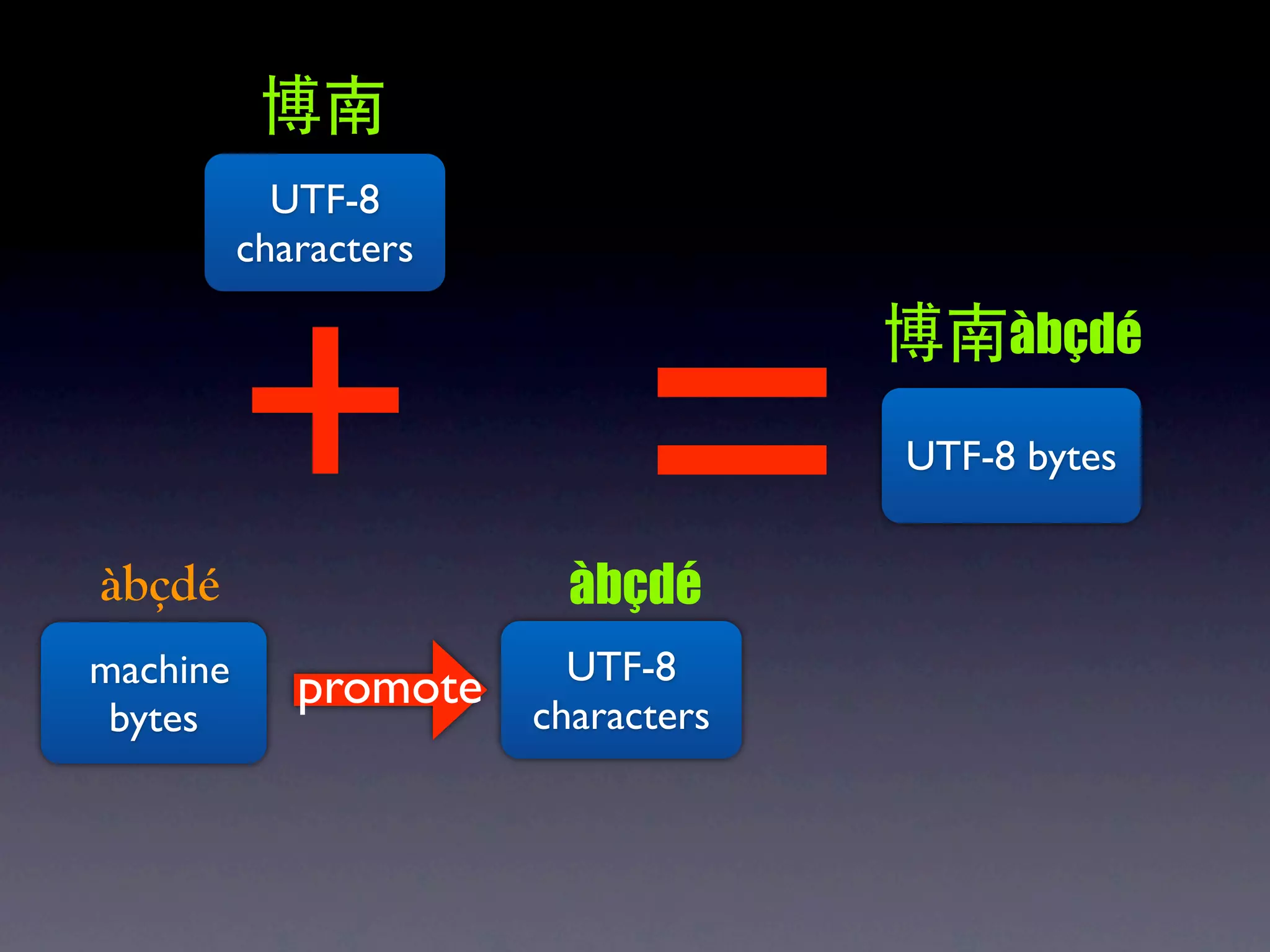









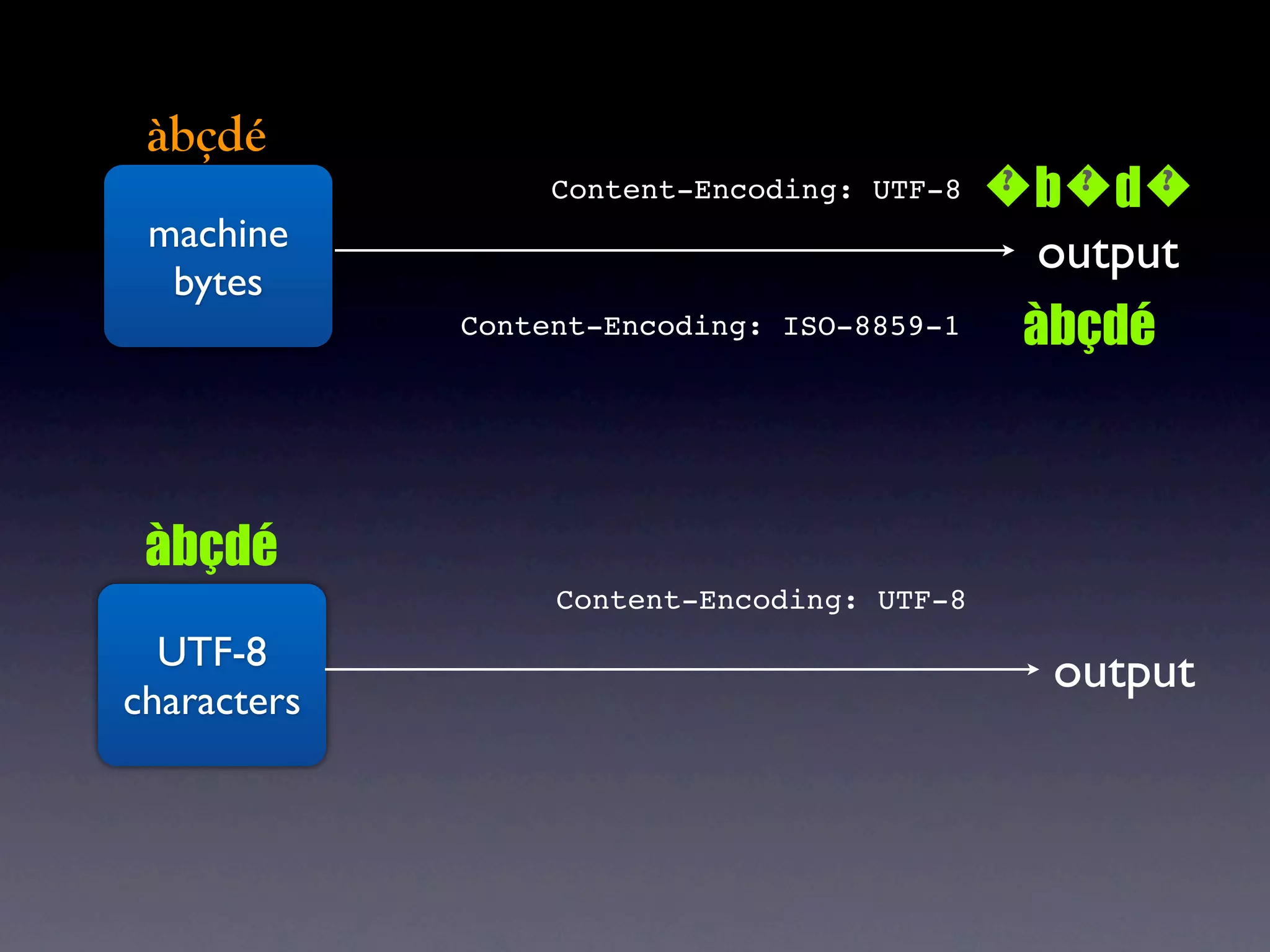
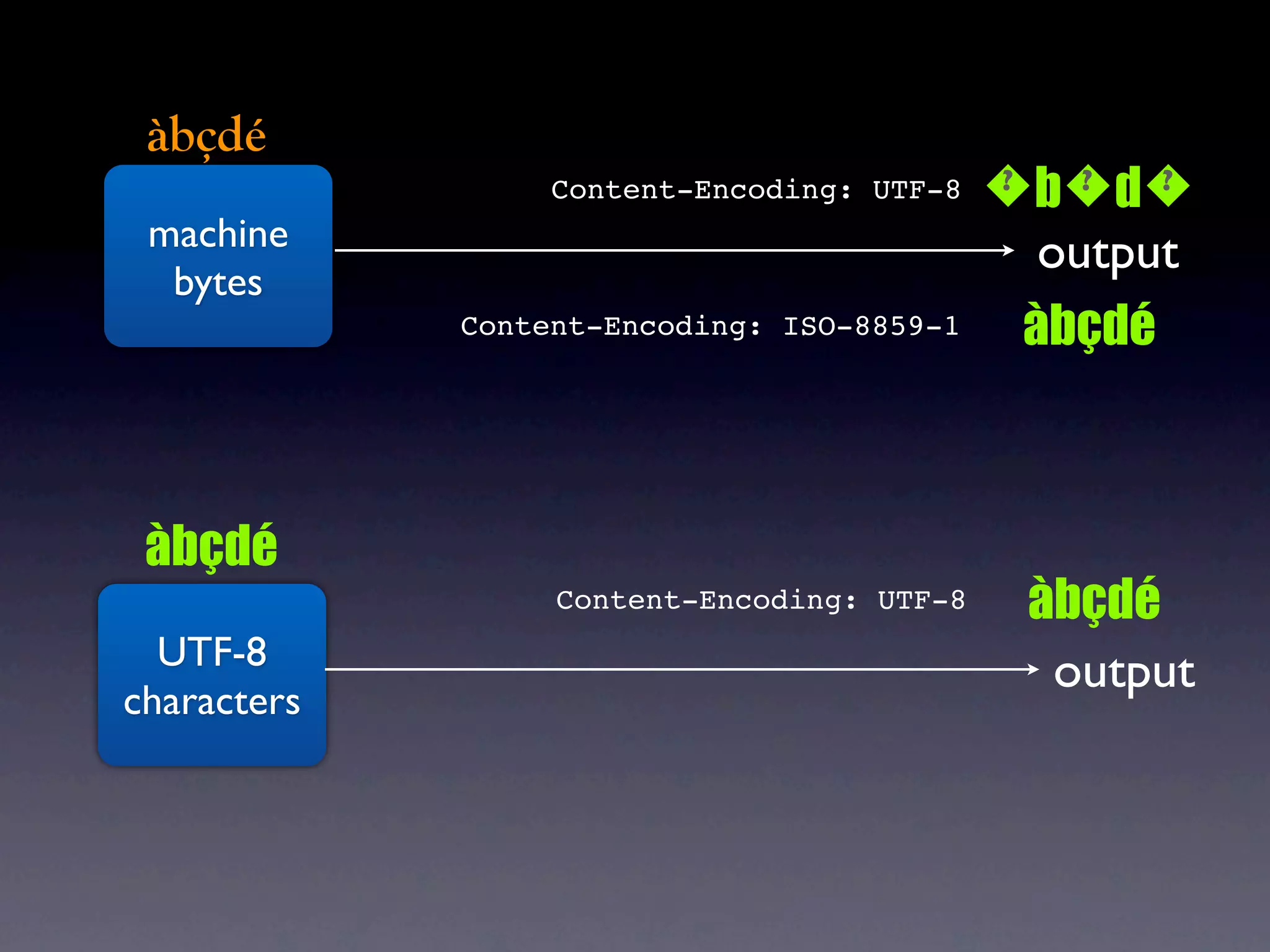
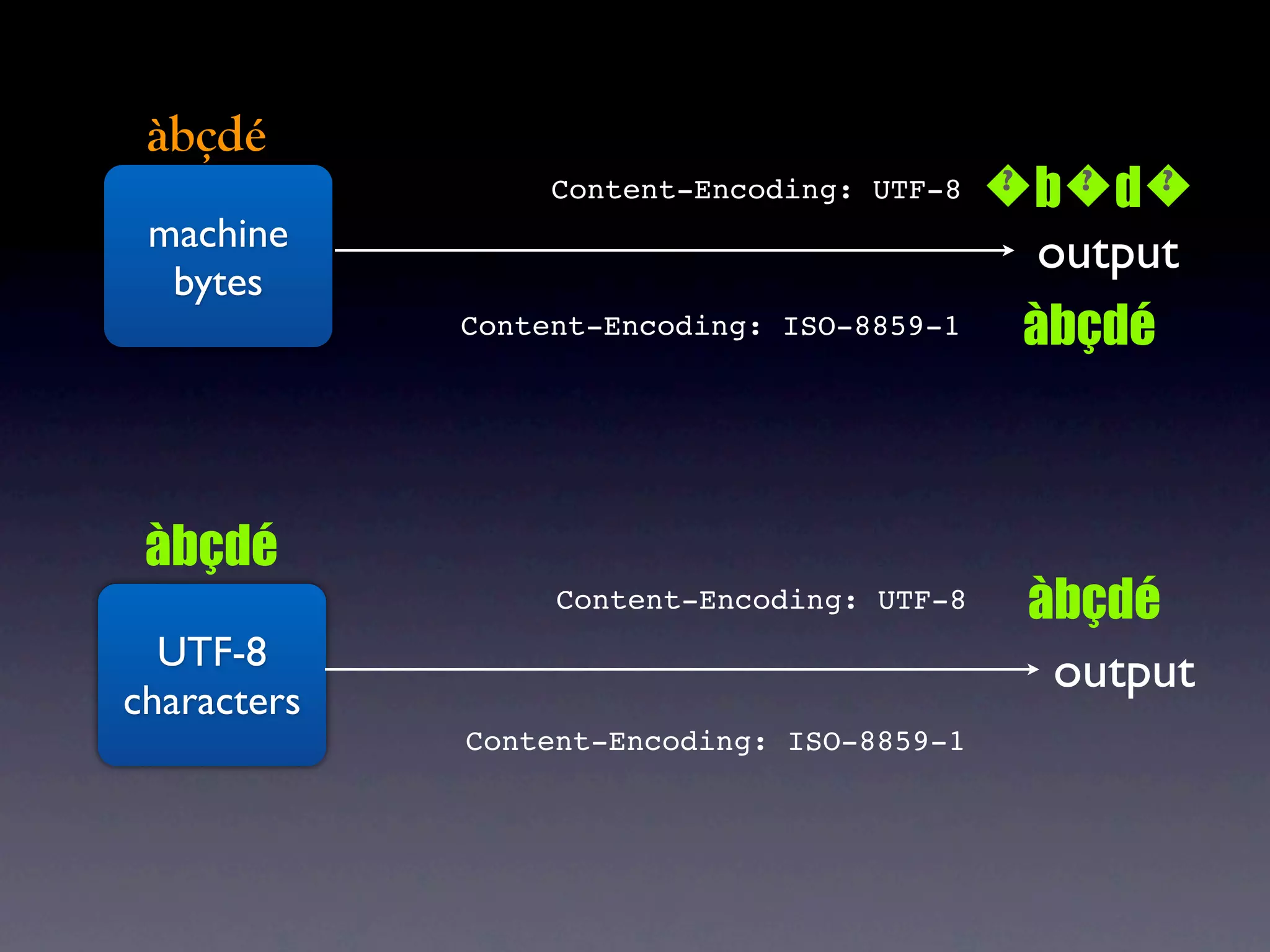
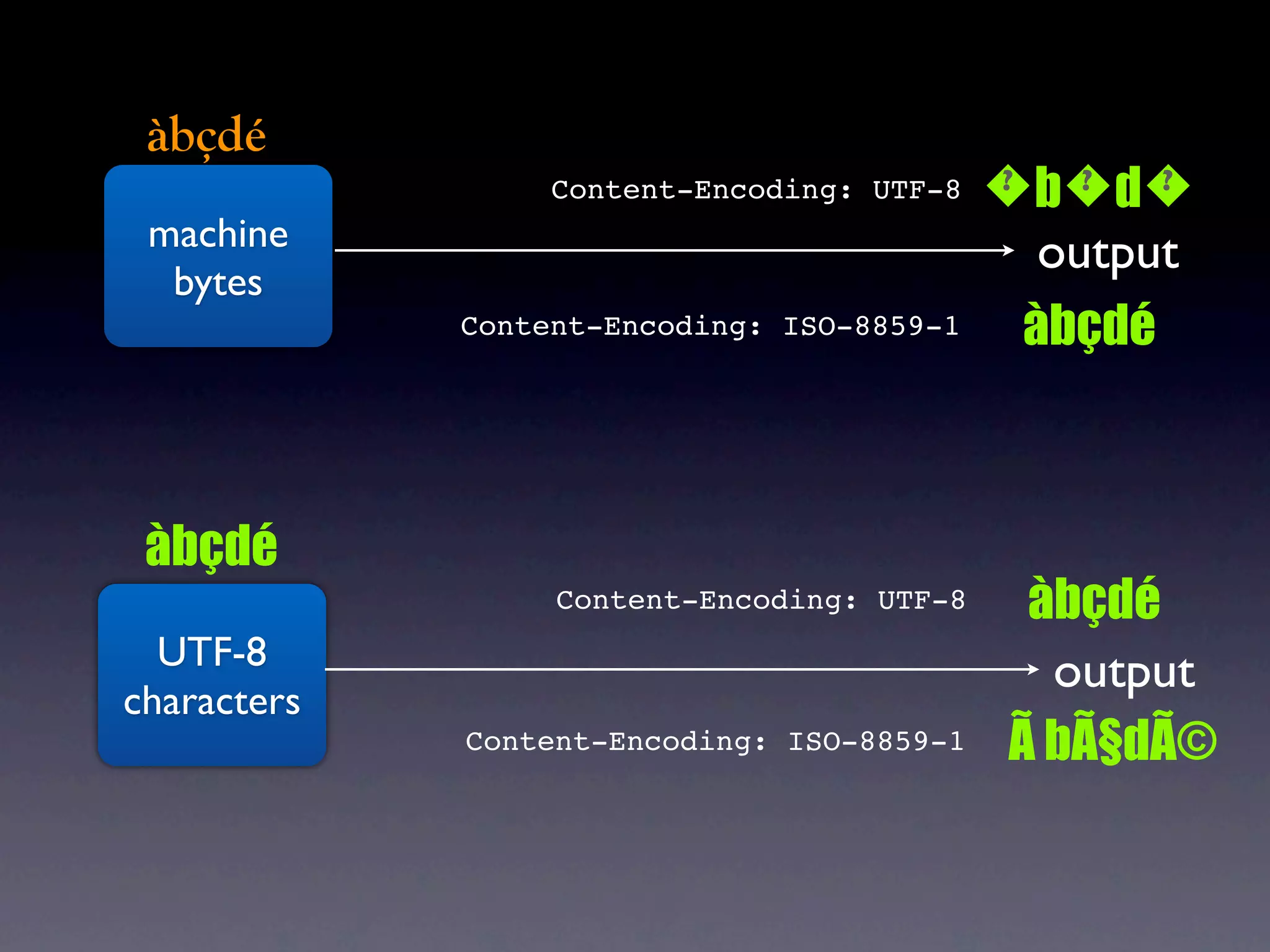














































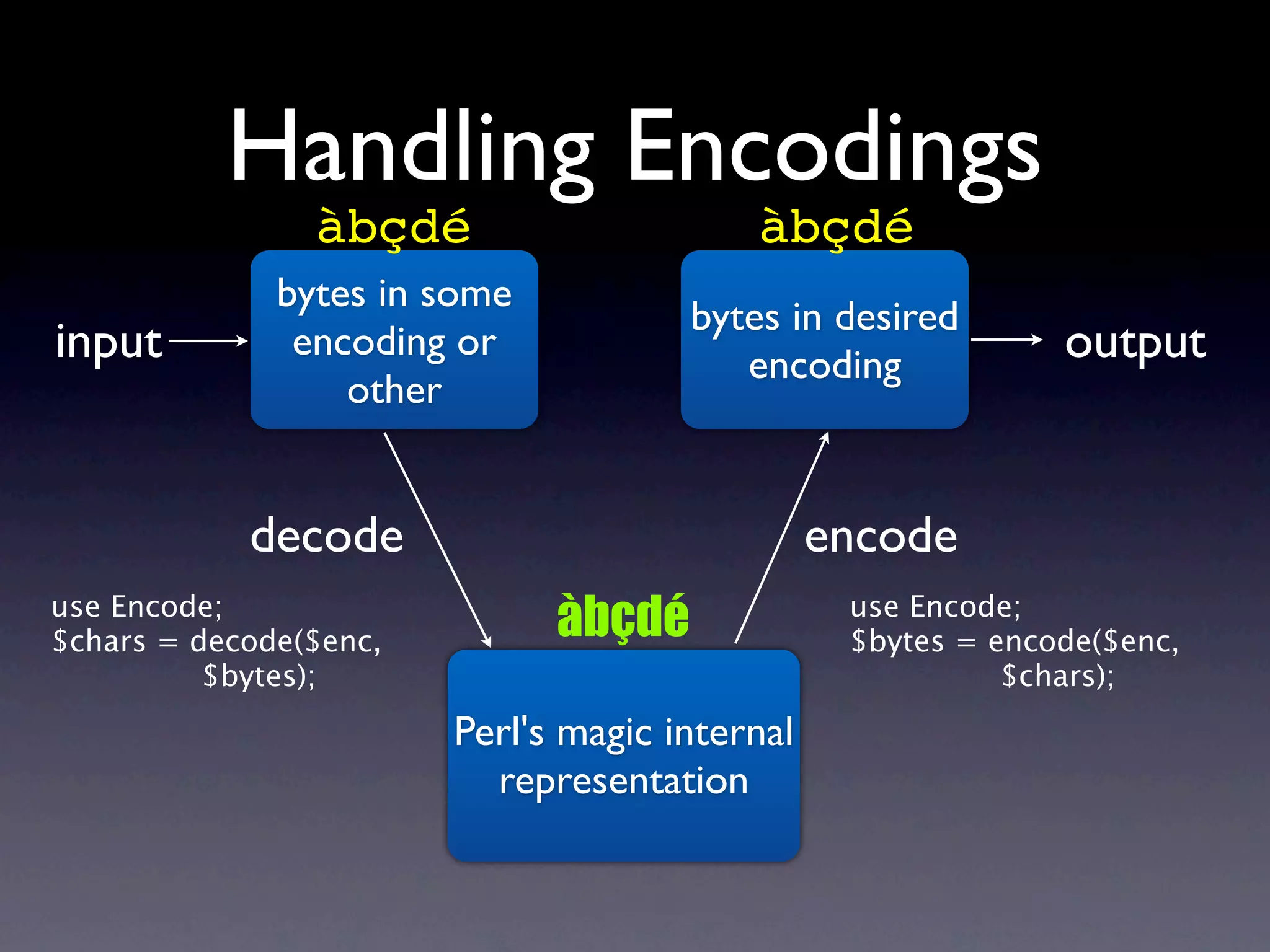
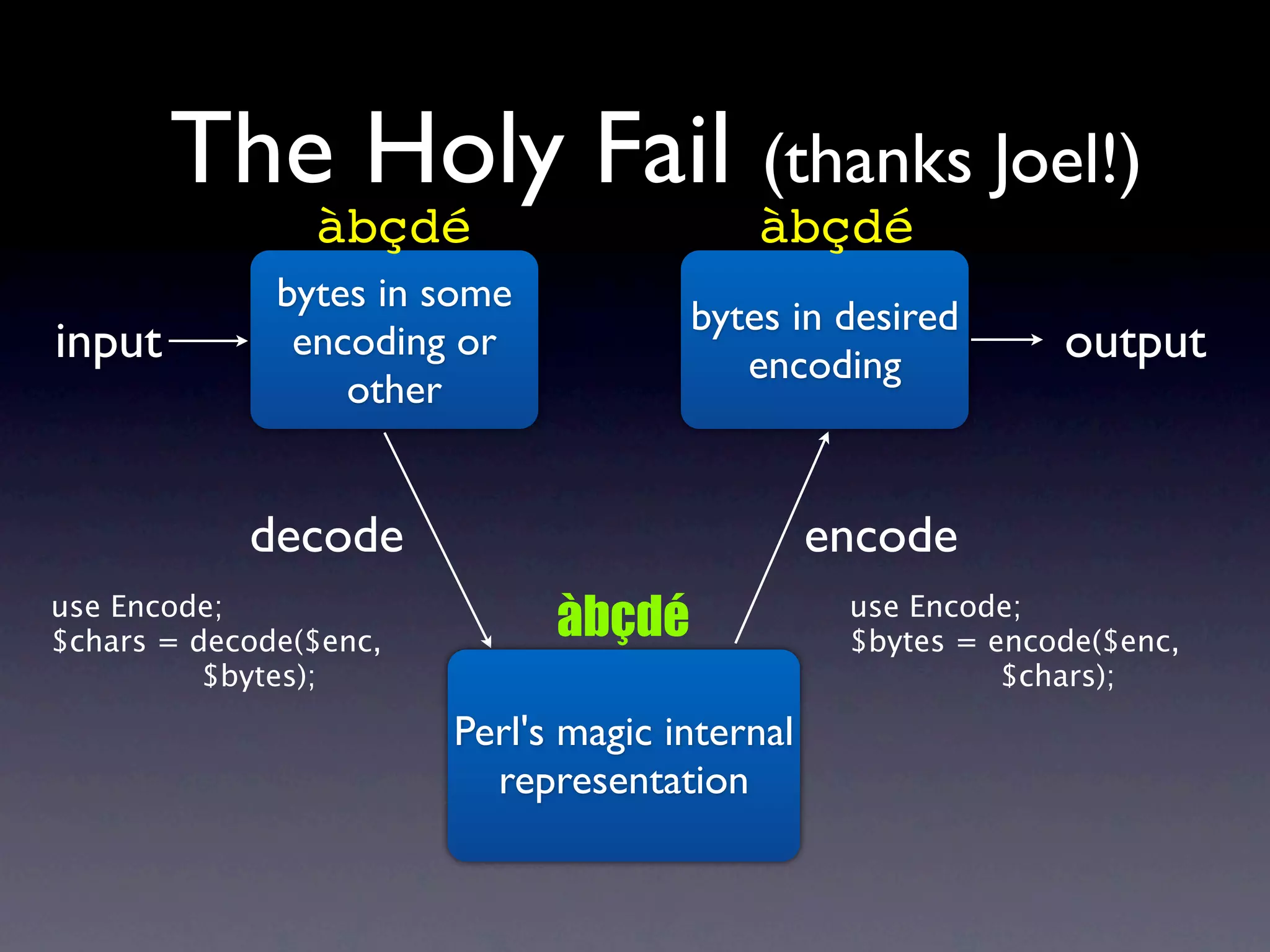


The document discusses Perl and Unicode. It begins by outlining some of the key challenges with Unicode support in Perl, namely keeping track of encodings, avoiding data loss, and distinguishing between characters and bytes. It then explains Perl's internal representation of strings as UTF-8 and how this allows string functions to work on the character level rather than byte level. Finally, it discusses various Perl modules and functions that can help with encoding and decoding strings, like Encode.pm and different argument forms of open(), and clarifies the difference between 'utf8' and 'UTF-8' encodings.





























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

