Download to read offline






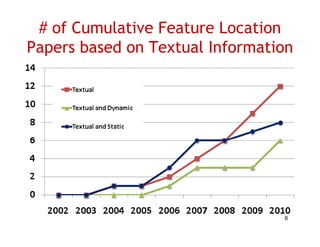









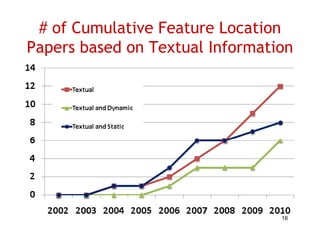
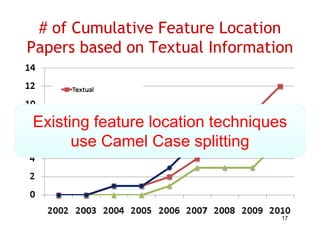



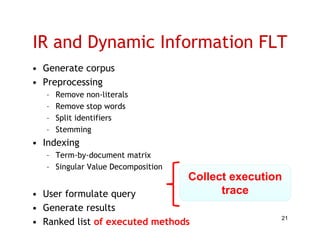



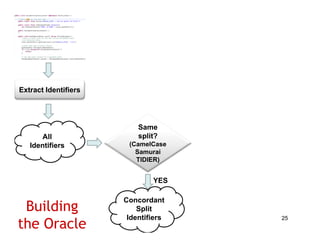
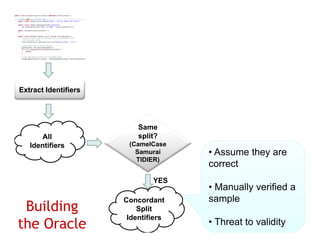
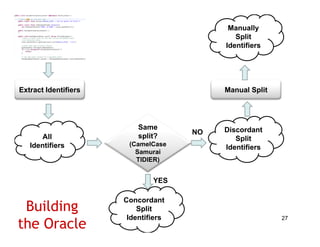
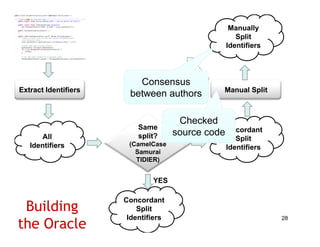
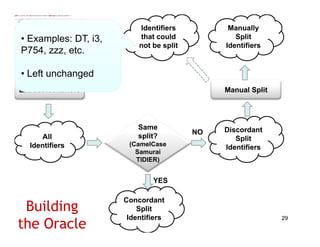




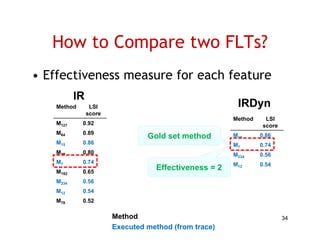







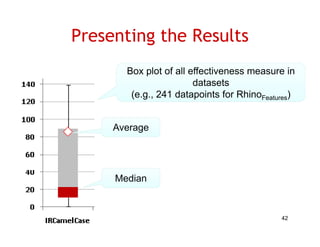
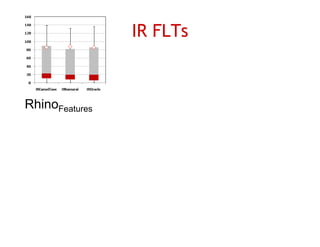
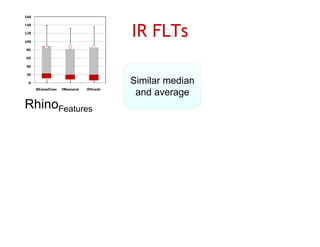
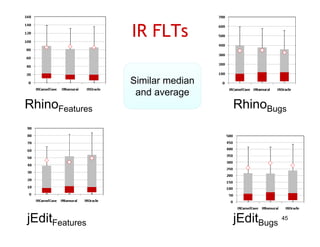
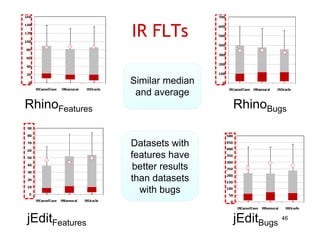
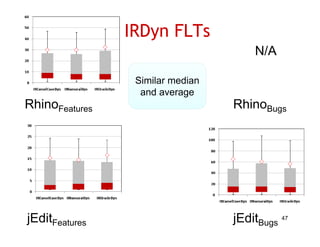
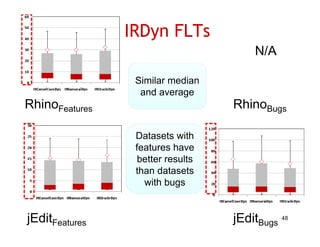
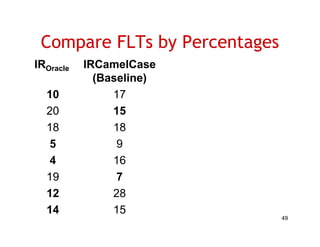
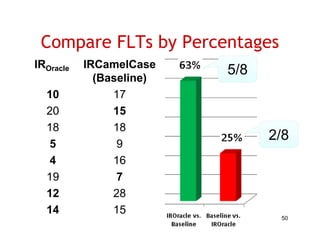
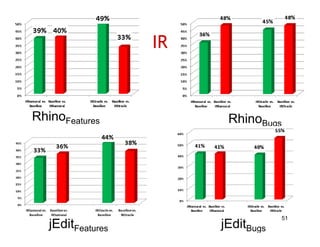
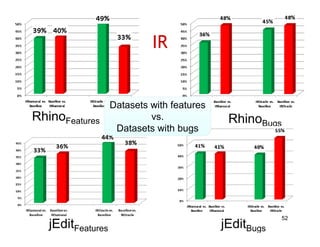
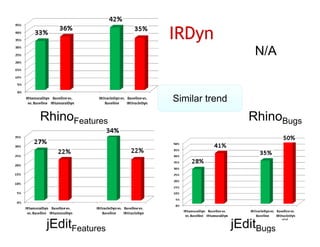

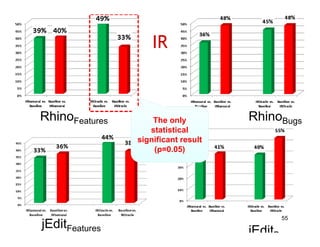

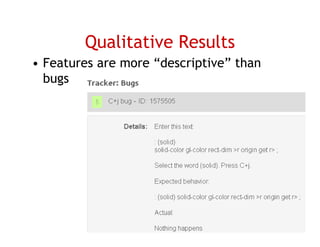








The document discusses evaluating how advanced techniques for splitting identifiers impact the performance of feature location techniques. It describes using different identifier splitting algorithms, such as CamelCase, Samurai, and a manually developed "perfect" splitting algorithm, within information retrieval and dynamic feature location techniques. The study compares the effectiveness of these feature location techniques when using different splitting algorithms using four software systems and associated datasets involving features and bugs. Results are presented using box plots to compare the median and average effectiveness across all data points for each technique and dataset.









































































