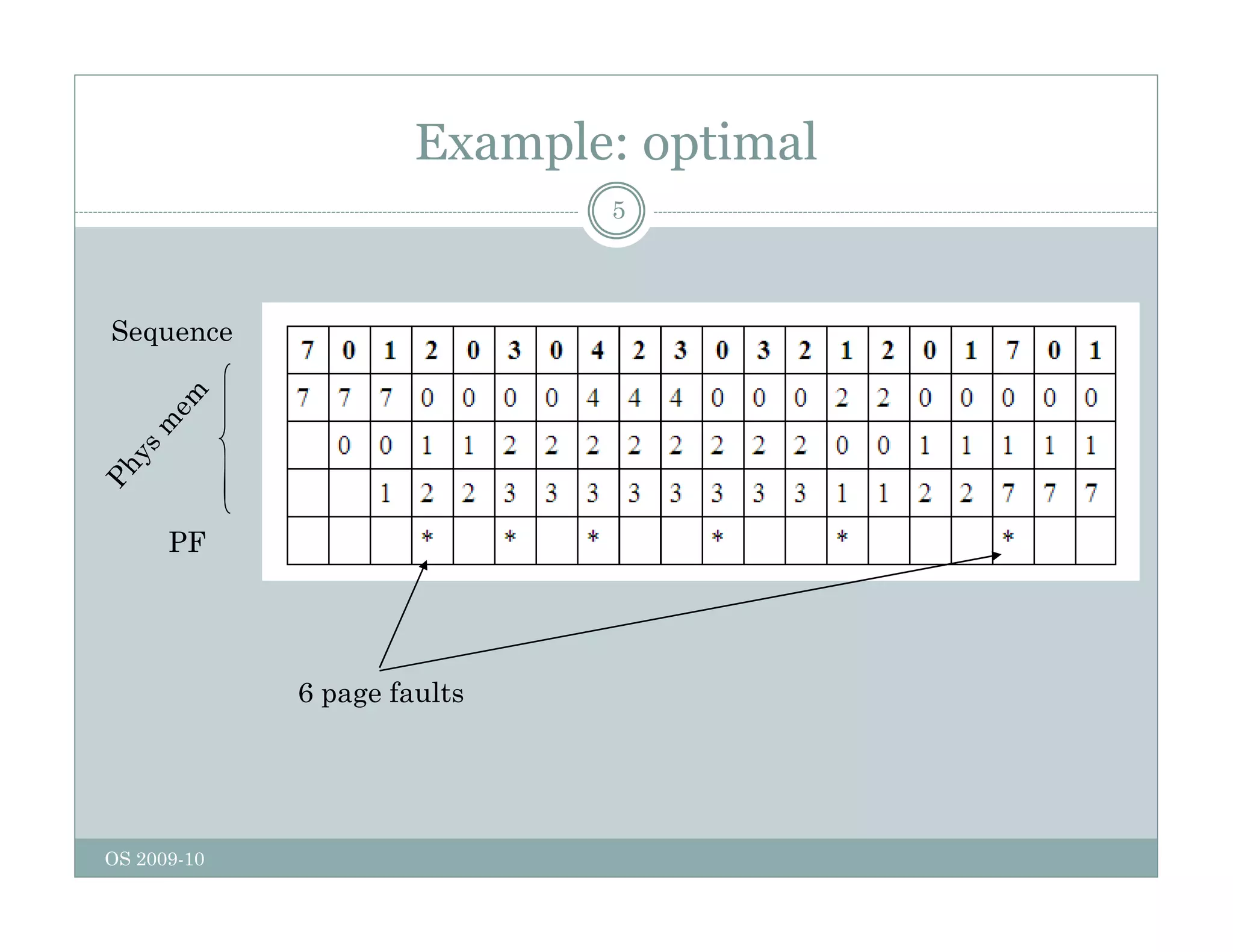
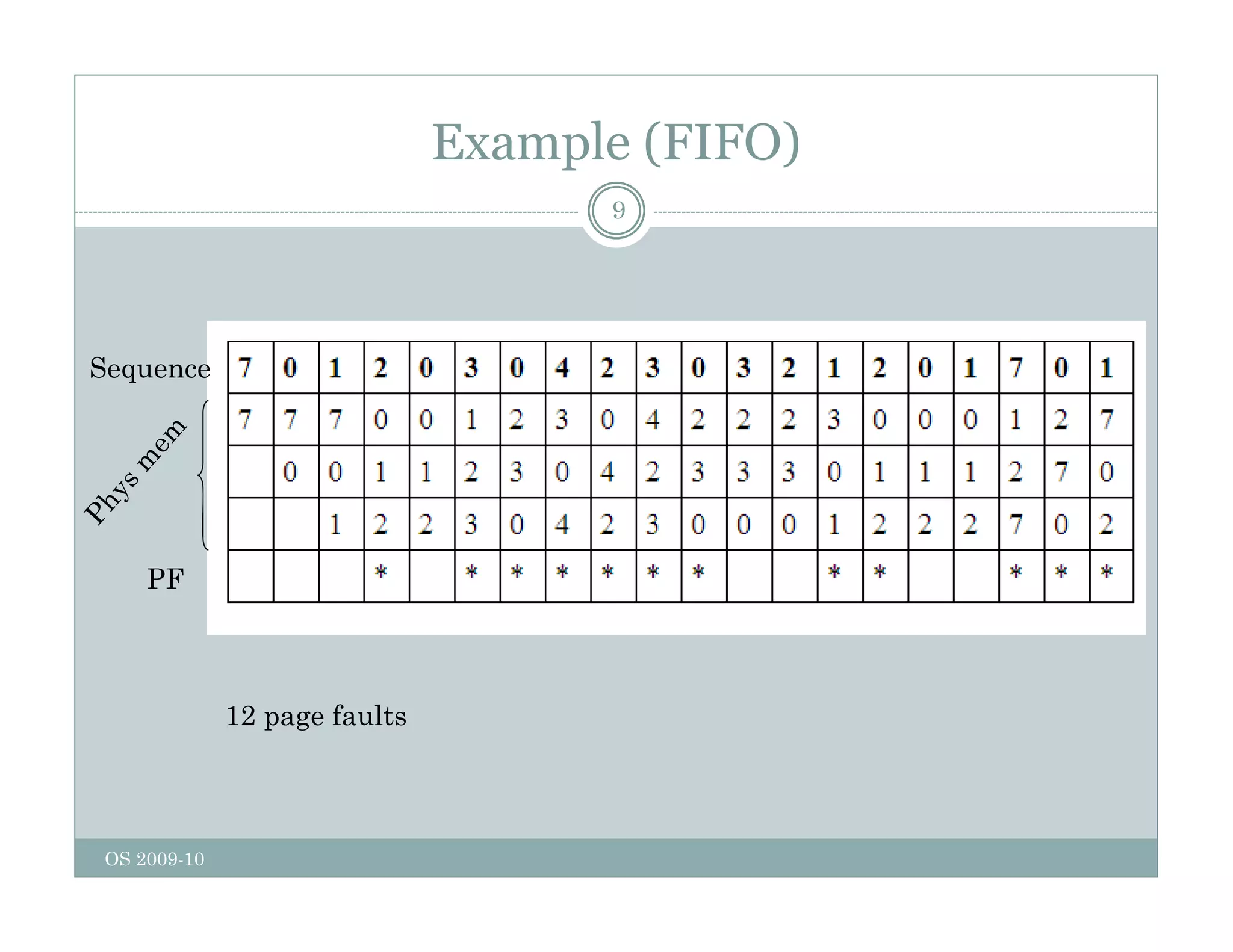
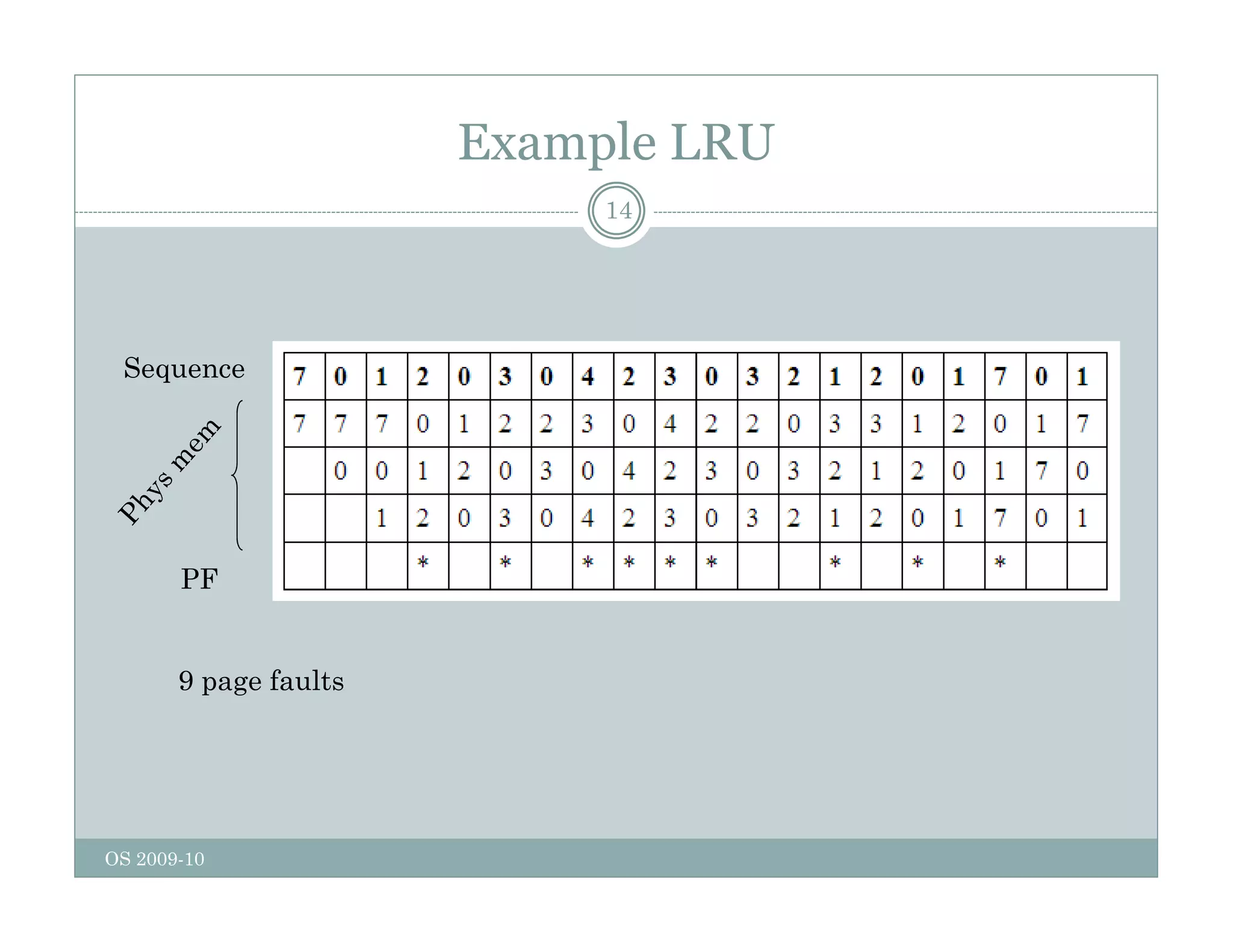
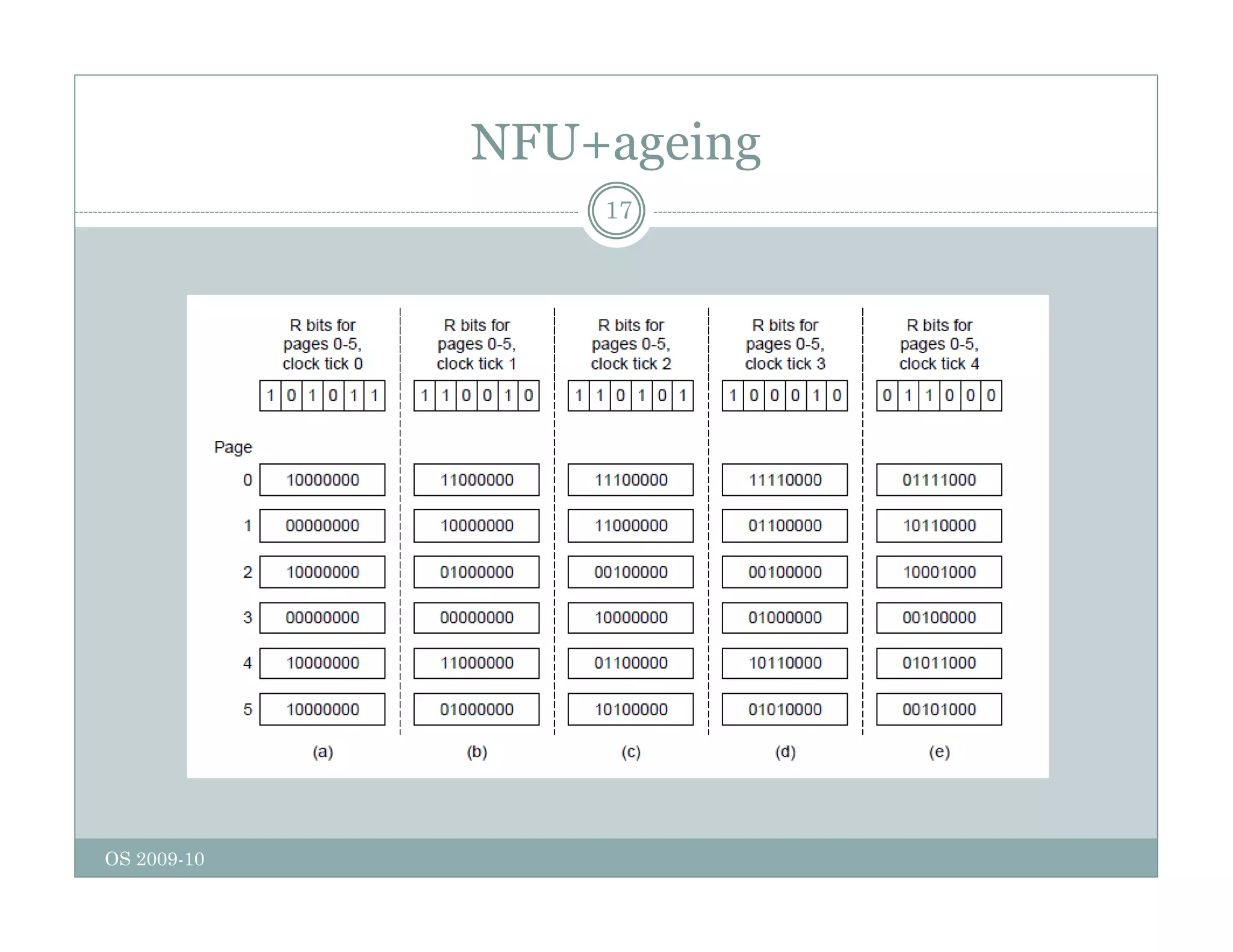
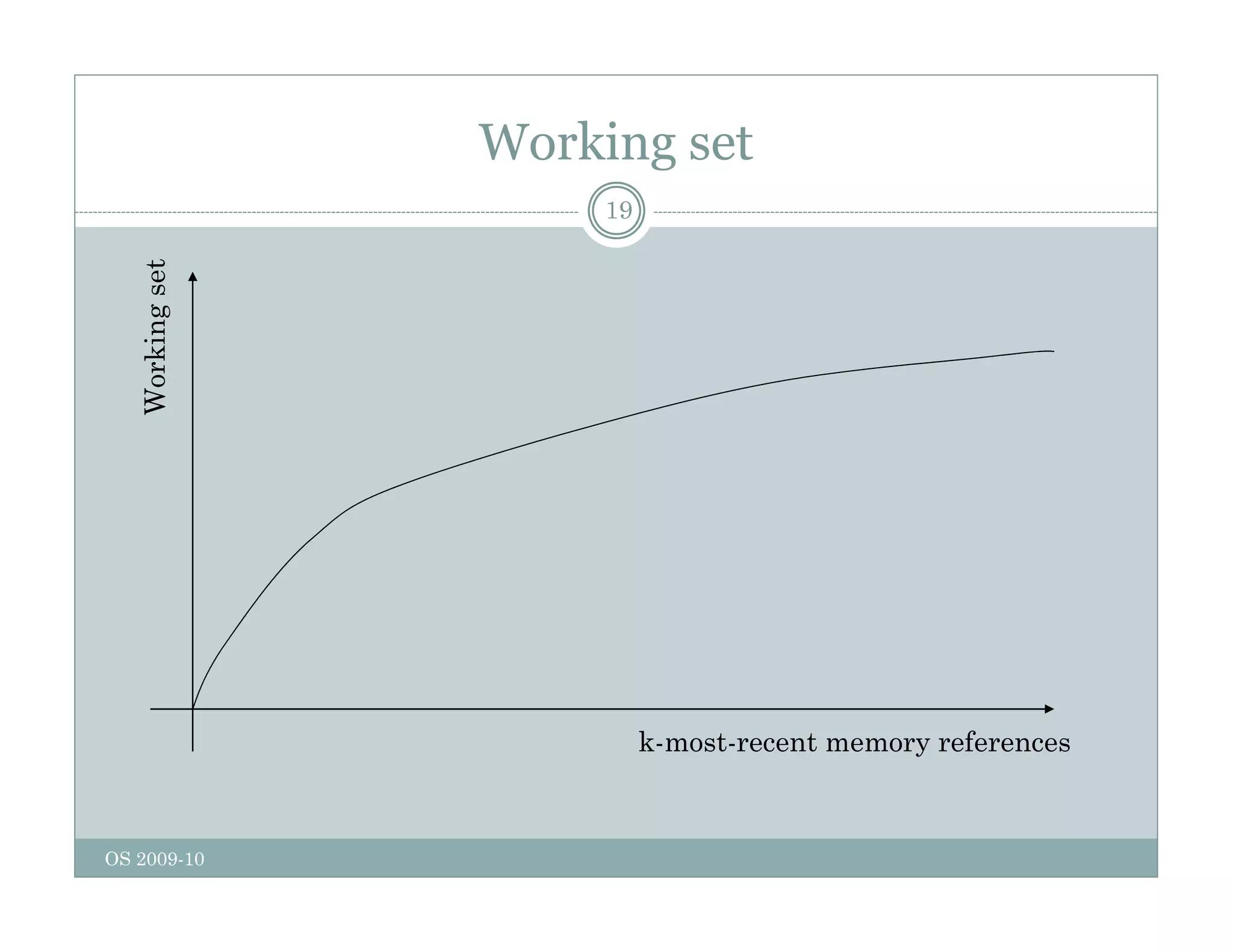
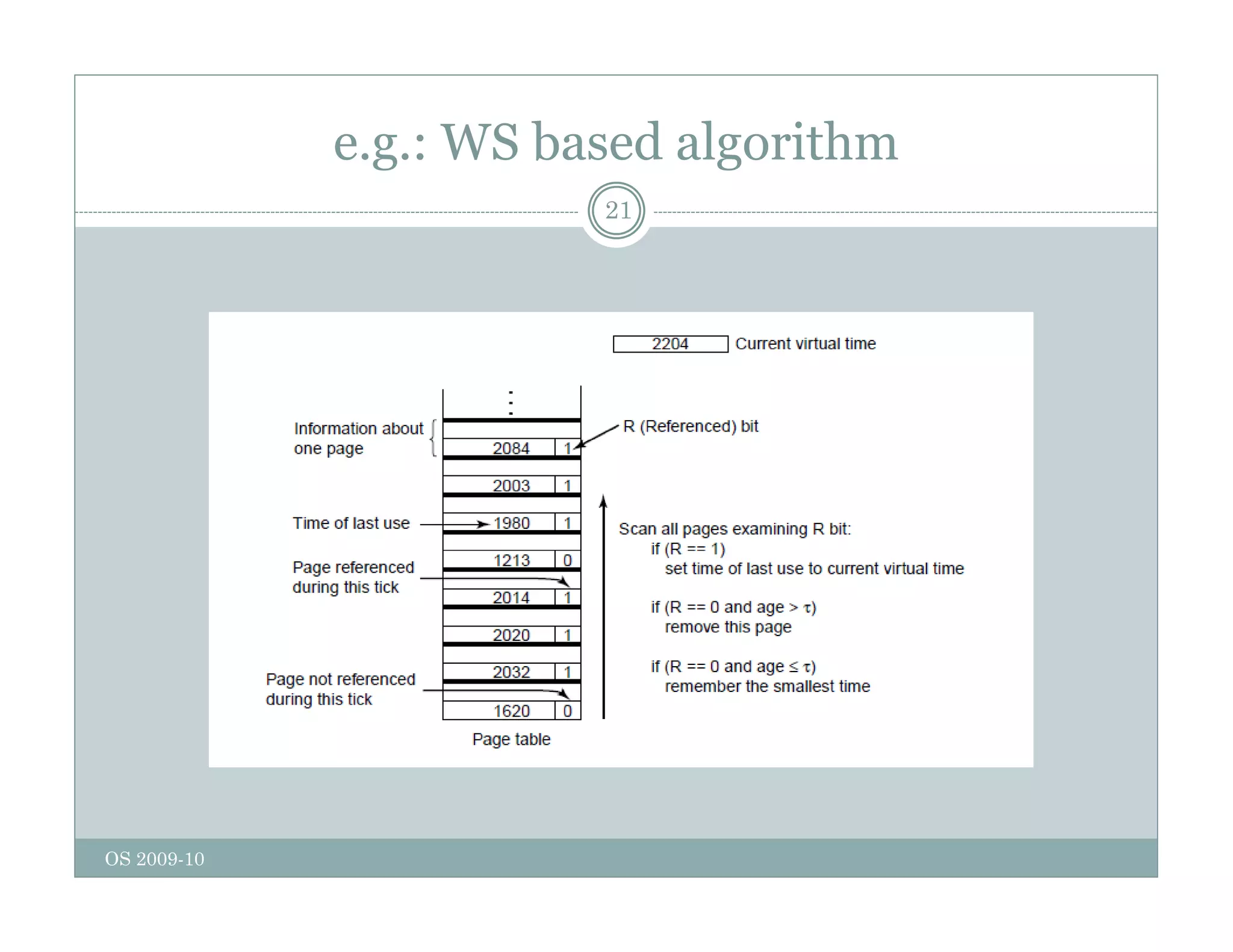
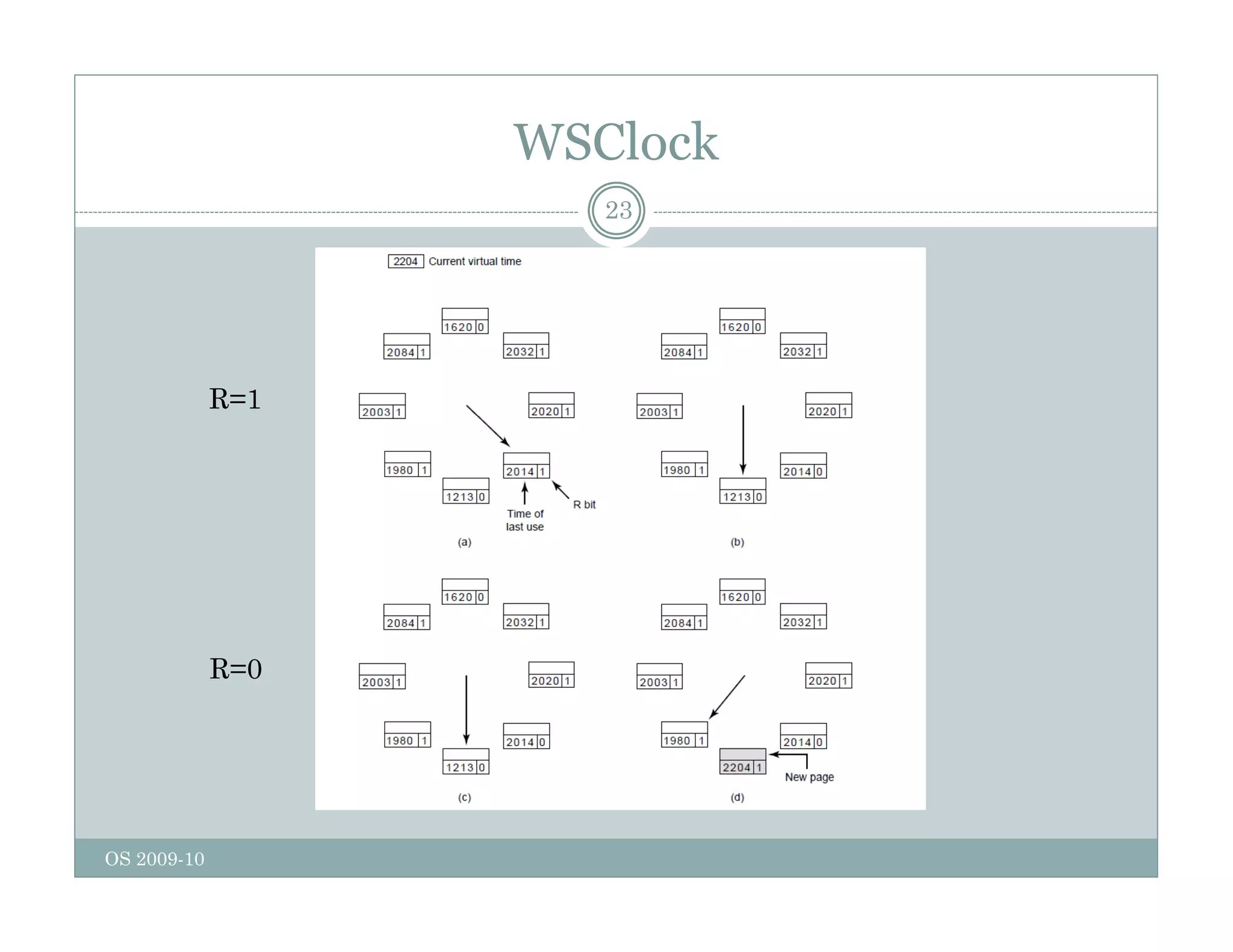
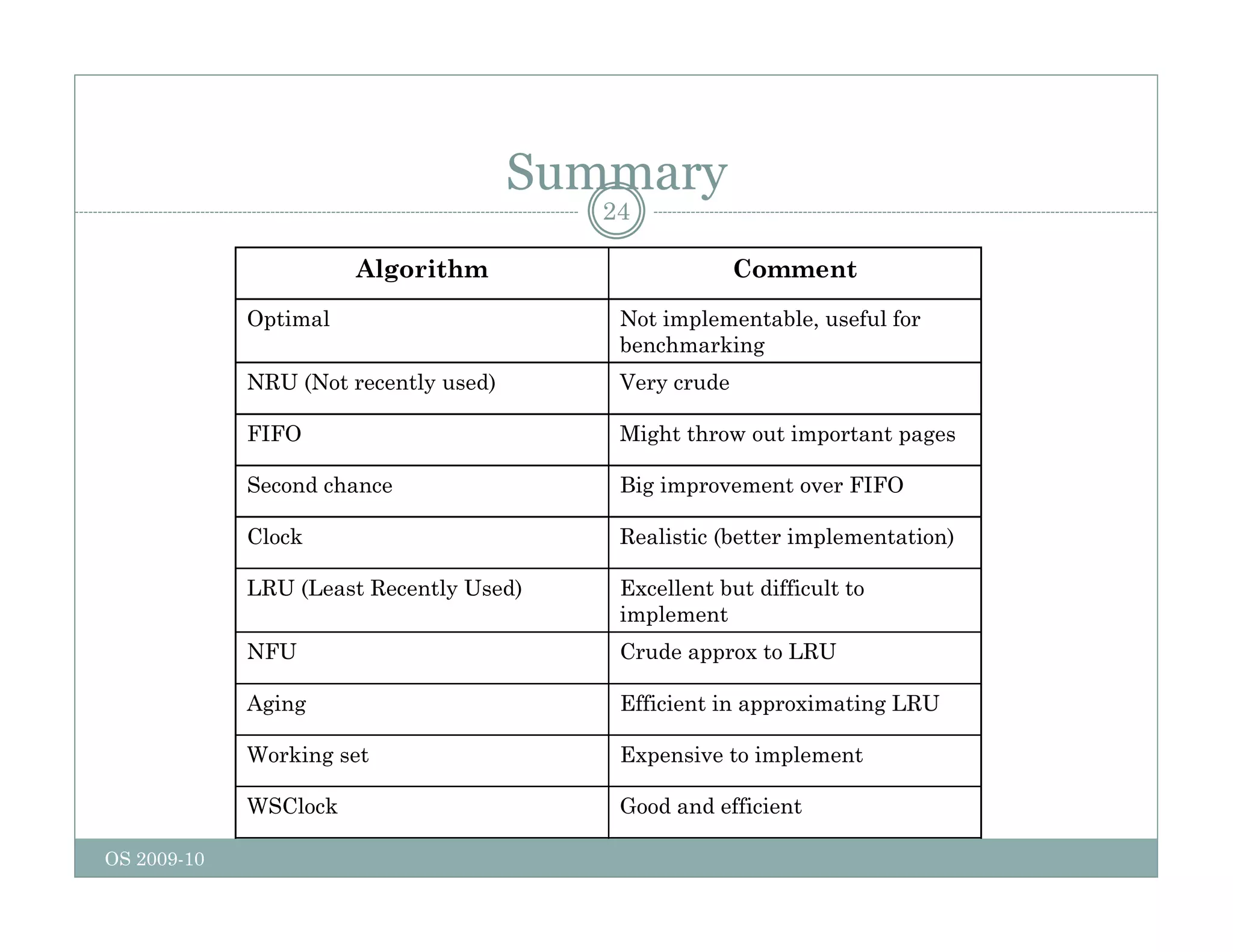
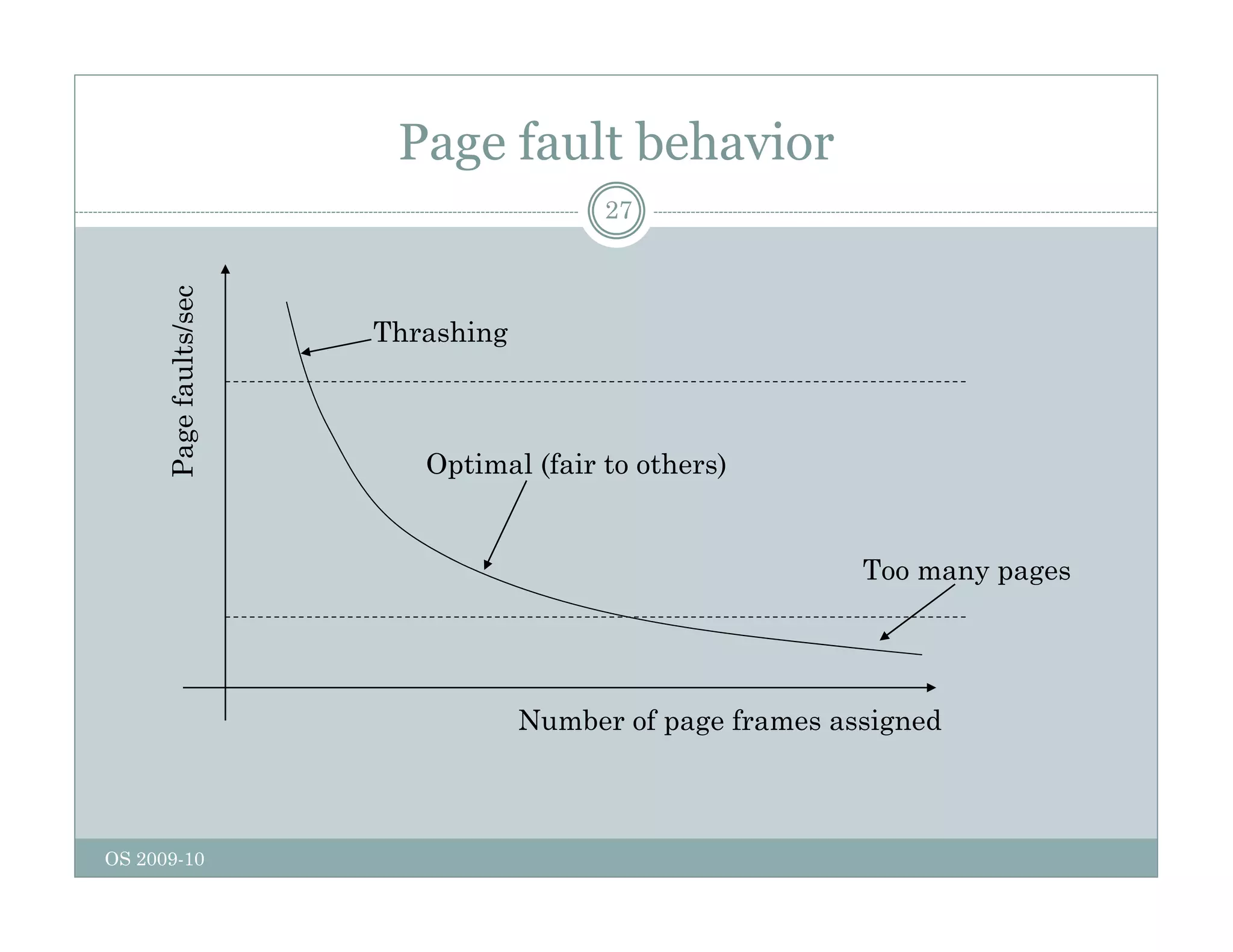
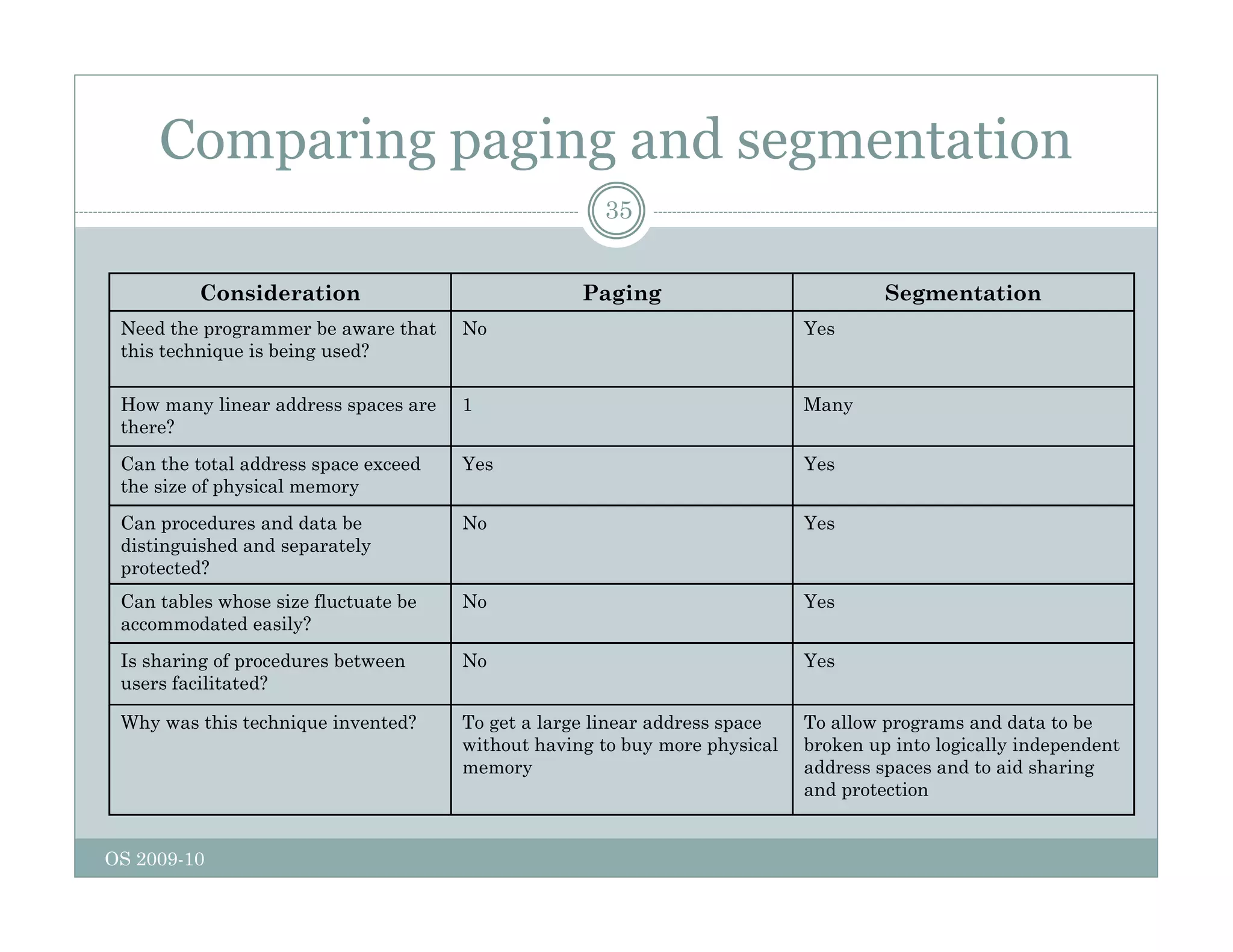
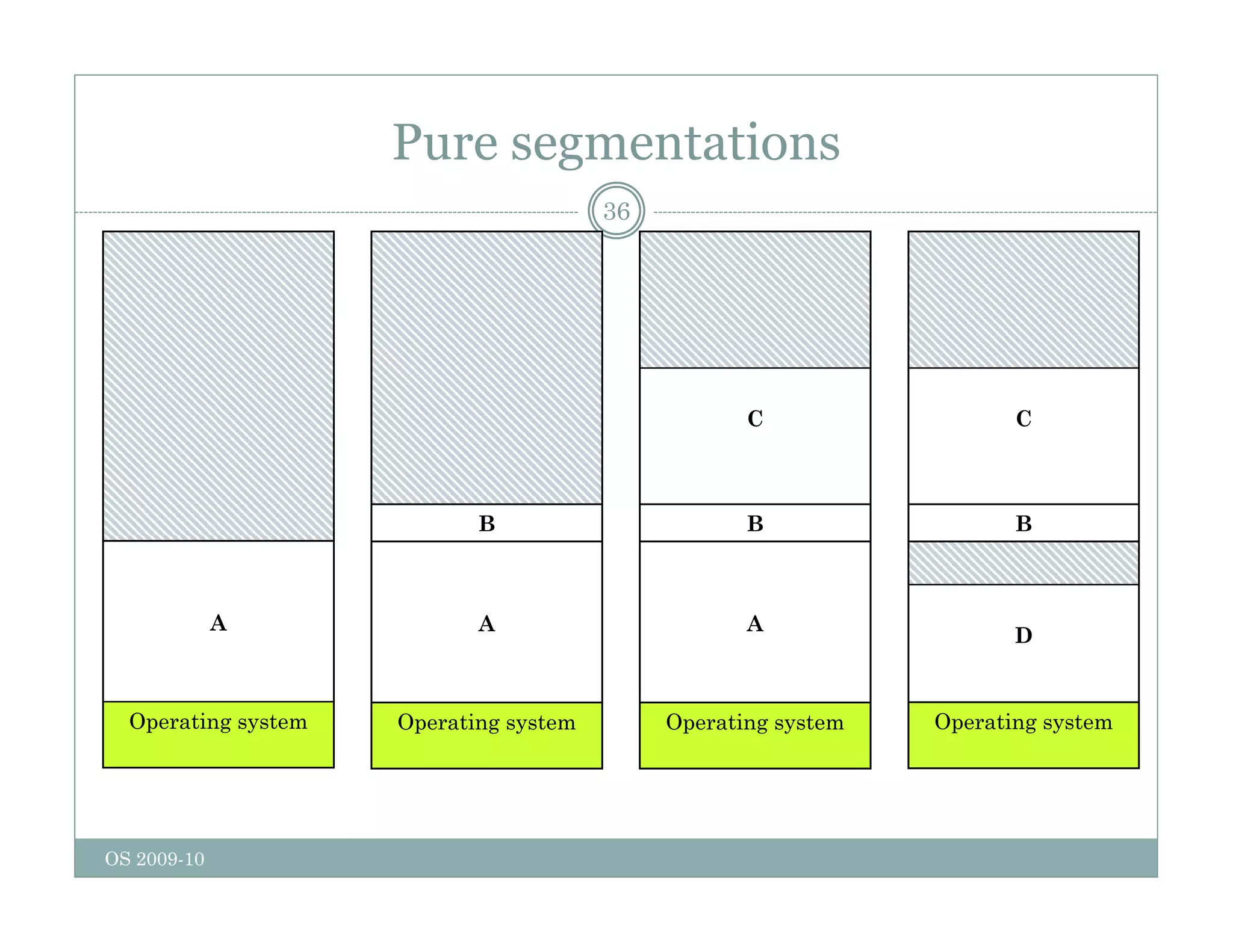
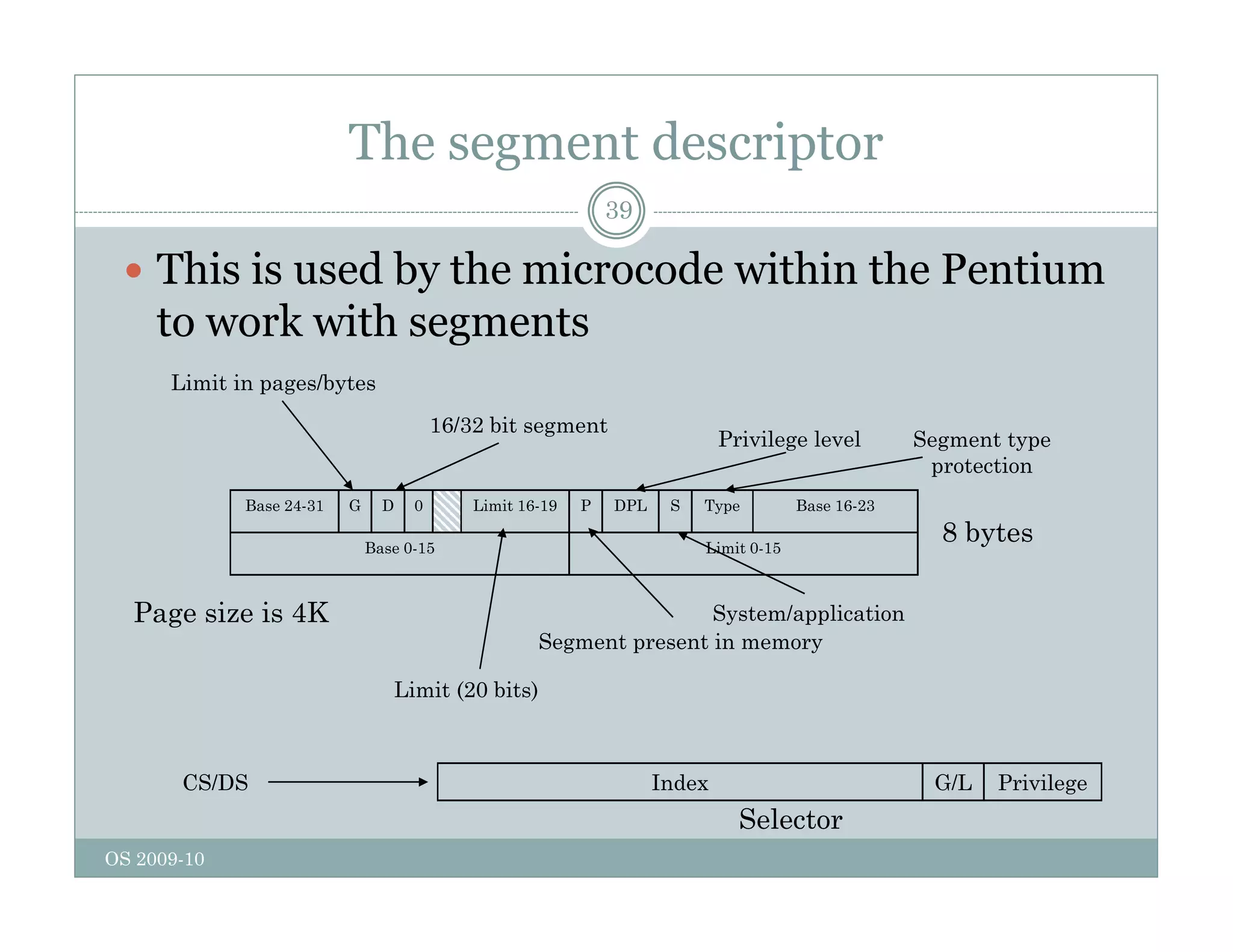
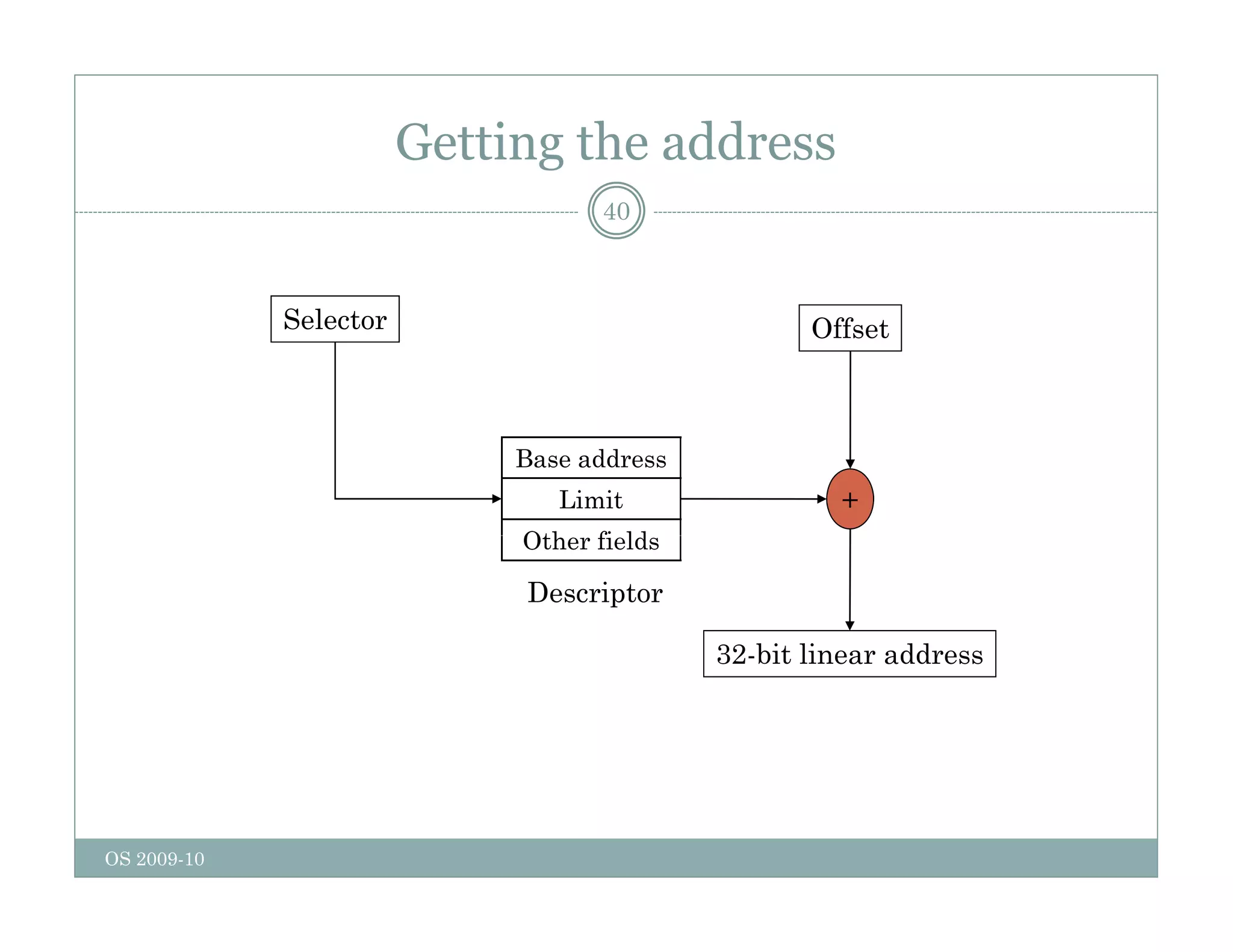
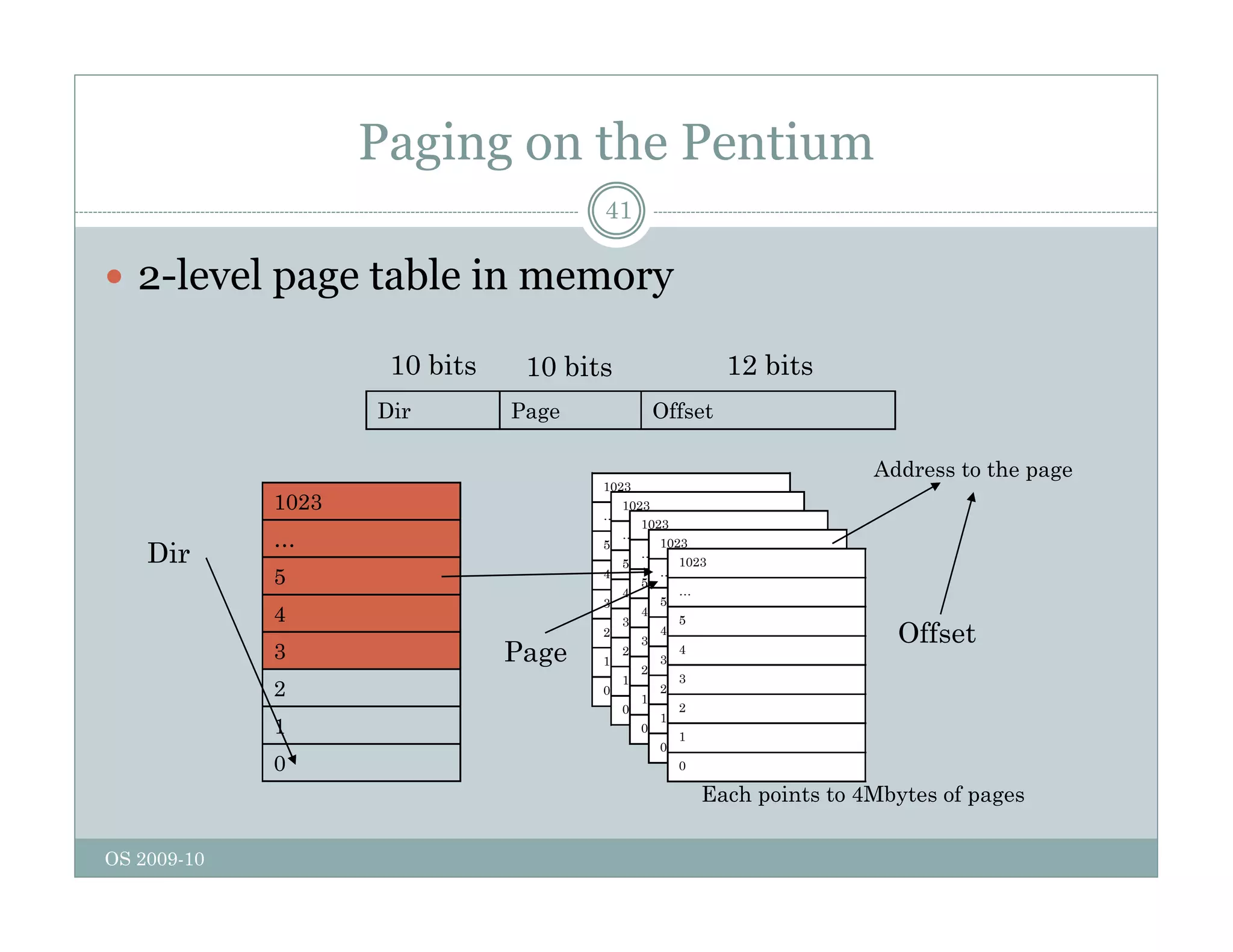
Page replacement algorithms are used in operating systems to determine which memory page to remove when a new page needs to be loaded into memory due to a page fault. Several algorithms were discussed, including optimal, FIFO, second chance, clock, LRU, NFU, and working set. The optimal algorithm is not practical as it requires knowledge of future references. More realistic algorithms include second chance, clock, LRU, and working set, with LRU being excellent but difficult to implement. Design considerations for page replacement include local vs global policies, page fault behavior, load control, page size, and handling dirty pages.