Downloaded 19 times






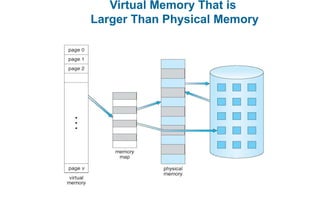
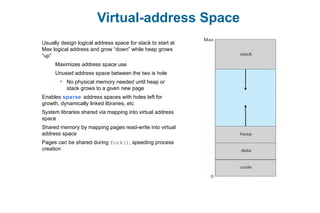
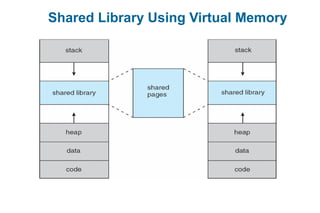
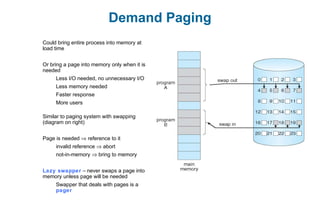


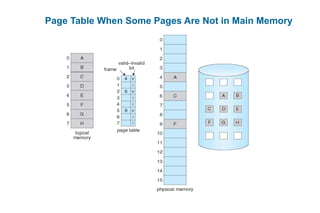

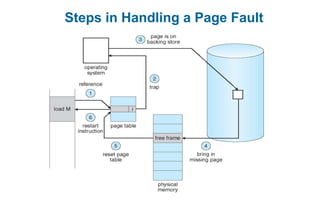







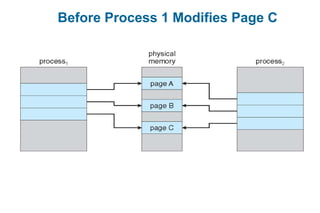
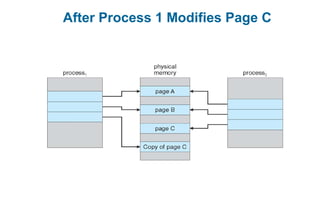


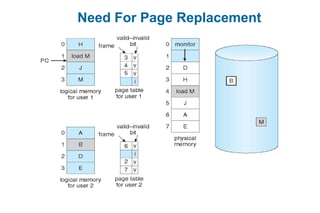

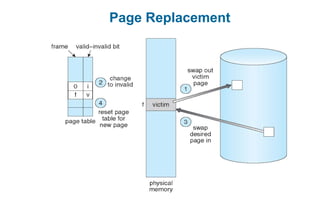

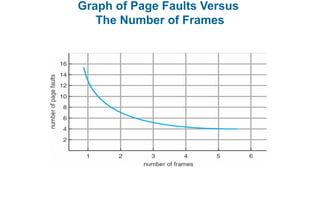

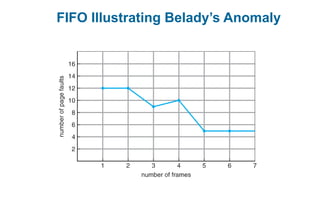



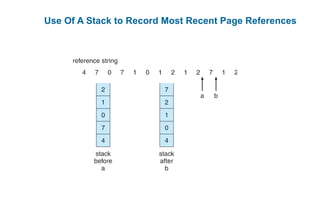

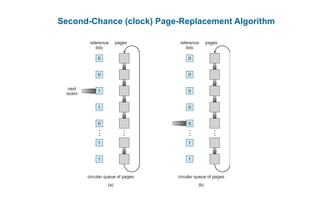










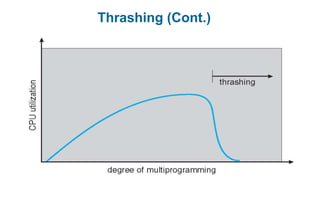



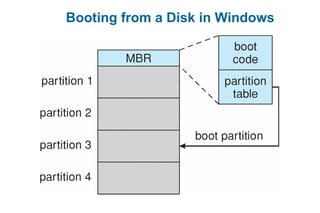

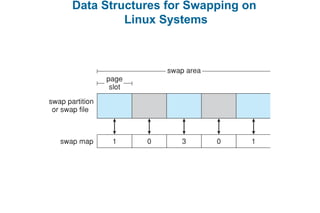


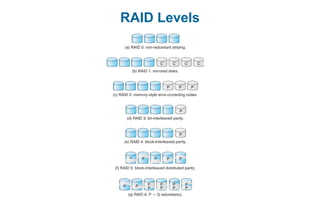
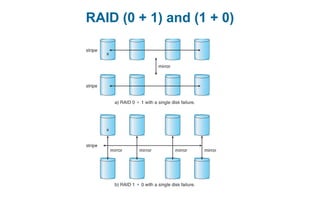


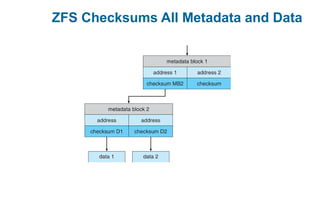
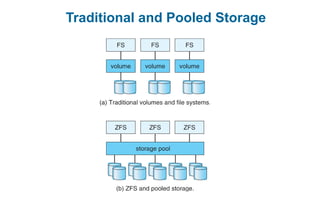


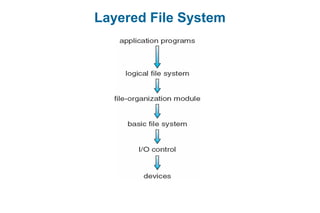




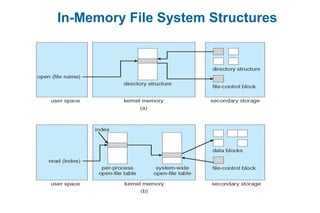

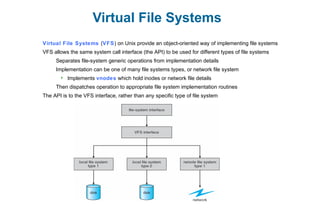











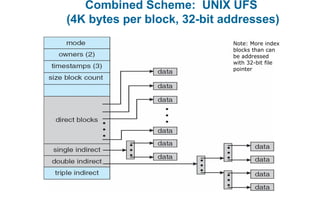
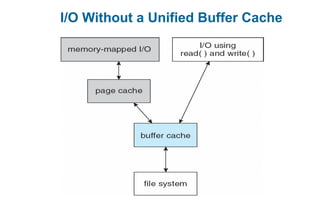

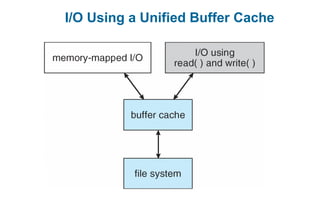




This document discusses virtual memory management. It begins with background on virtual memory and how it allows logical address spaces to be larger than physical memory. It describes demand paging, where pages are only loaded into memory when needed rather than all at once. Copy-on-write is explained as a way to share pages between processes initially. When memory runs out, page replacement algorithms are used to select pages to remove from memory. Optimizations like faster swap space I/O and demand paging from files rather than swapping are also covered.































































































