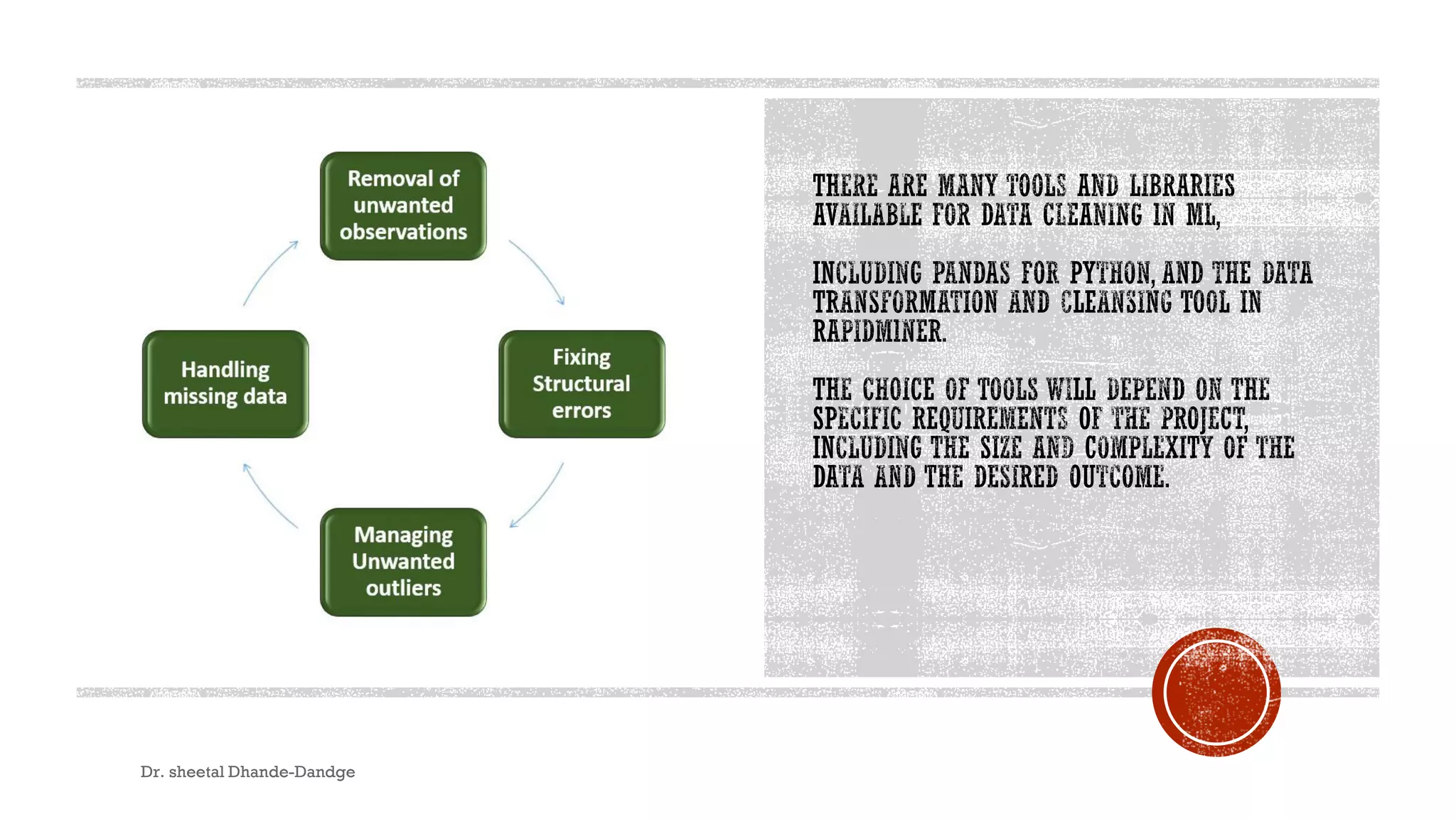
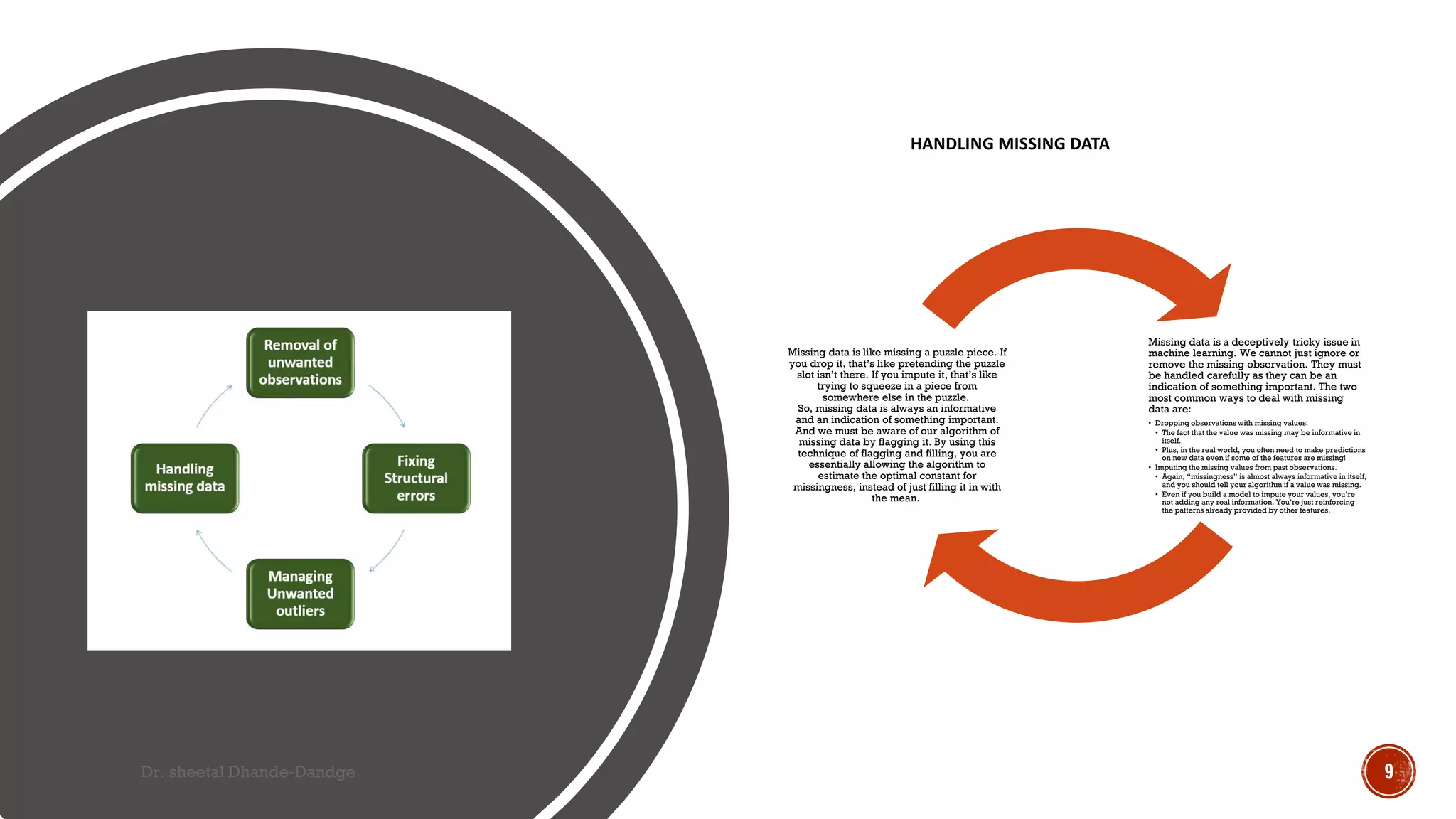
Data cleaning is a vital process in machine learning that ensures data accuracy and consistency, directly impacting model performance. It involves steps such as handling missing data, removing duplicates, correcting errors, and addressing outliers. While crucial, data cleaning can be time-consuming and may lead to errors if not conducted carefully, emphasizing the need for a systematic approach.








![ Here is a simple example of data cleaning in Python:
import pandas as pd
# Load the data
df = pd.read_csv("data.csv")
# Drop rows with missing values
df = df.dropna()
# Remove duplicate rows
df = df.drop_duplicates()
# Remove unnecessary columns
df = df.drop(columns=["col1", "col2"])
# Normalize numerical columns
df["col3"] = (df["col3"] - df["col3"].mean()) / df["col3"].std()
# Encode categorical columns
df["col4"] = pd.get_dummies(df["col4"])
# Save the cleaned data
df.to_csv("cleaned_data.csv", index=False)
The code I provided does not have any explicit output statements, so it
will not produce any output when it is run. Instead, it modifies the data
stored in the df DataFrame and saves it to a new CSV file.
If you want to see the cleaned data, you can print the df DataFrame or
read the saved CSV file. For example, you can add the following line at the
end of the code to print the cleaned data:
print(df)
Dr. sheetal Dhande-Dandge 11](https://image.slidesharecdn.com/overviewofdatacleaning-230227115557-6514a4b9/75/Overview-of-Data-Cleaning-pdf-11-2048.jpg)



























![Dimension reduction techniques[Feature Selection]](https://cdn.slidesharecdn.com/ss_thumbnails/dimensionreductiontechnibyaakankshajain-210625102243-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
