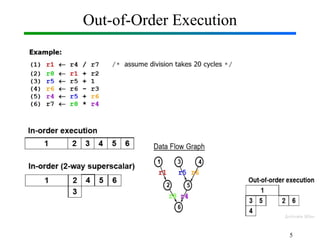
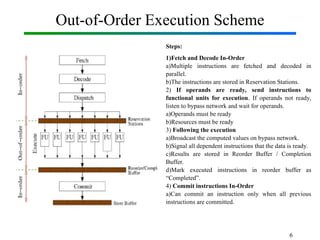
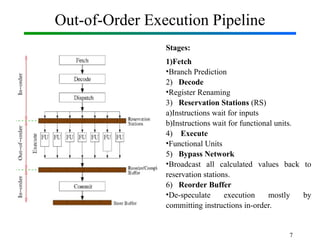
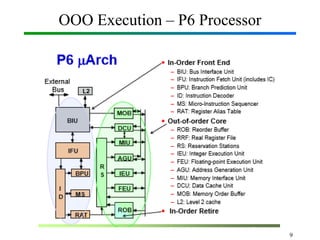
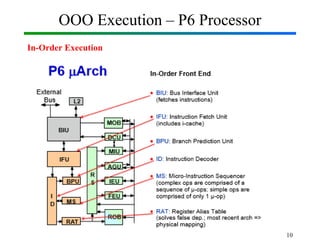
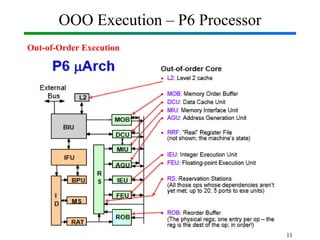
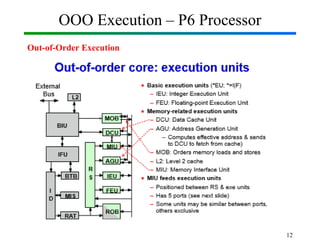
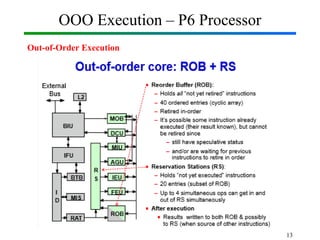
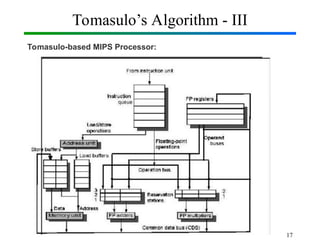
Out-of-Order Execution (OOE) is a technique used in modern processors to improve performance by executing instructions as soon as their required operands are available, rather than strictly following the original program order. In Computer Organization and Architecture (COA), this concept is implemented through hardware mechanisms such as instruction pipelines, reservation stations, and reorder buffers. The CPU analyzes dependencies between instructions and allows independent instructions to execute in parallel while waiting for others to complete, thereby reducing idle cycles caused by delays like memory access. The results are then committed in the correct program order to ensure correctness and maintain the illusion of sequential execution. From the Operating System (OS) perspective, out-of-order execution is transparent: the OS schedules processes and threads as usual, while the hardware handles the reordering internally. This improves CPU utilization, instruction throughput, and overall system performance, but also introduces challenges such as handling data hazards, control hazards, and ensuring precise exceptions. Modern processors like Intel and ARM heavily rely on OOE to achieve high instruction-level parallelism.