Download as PDF, PPTX
















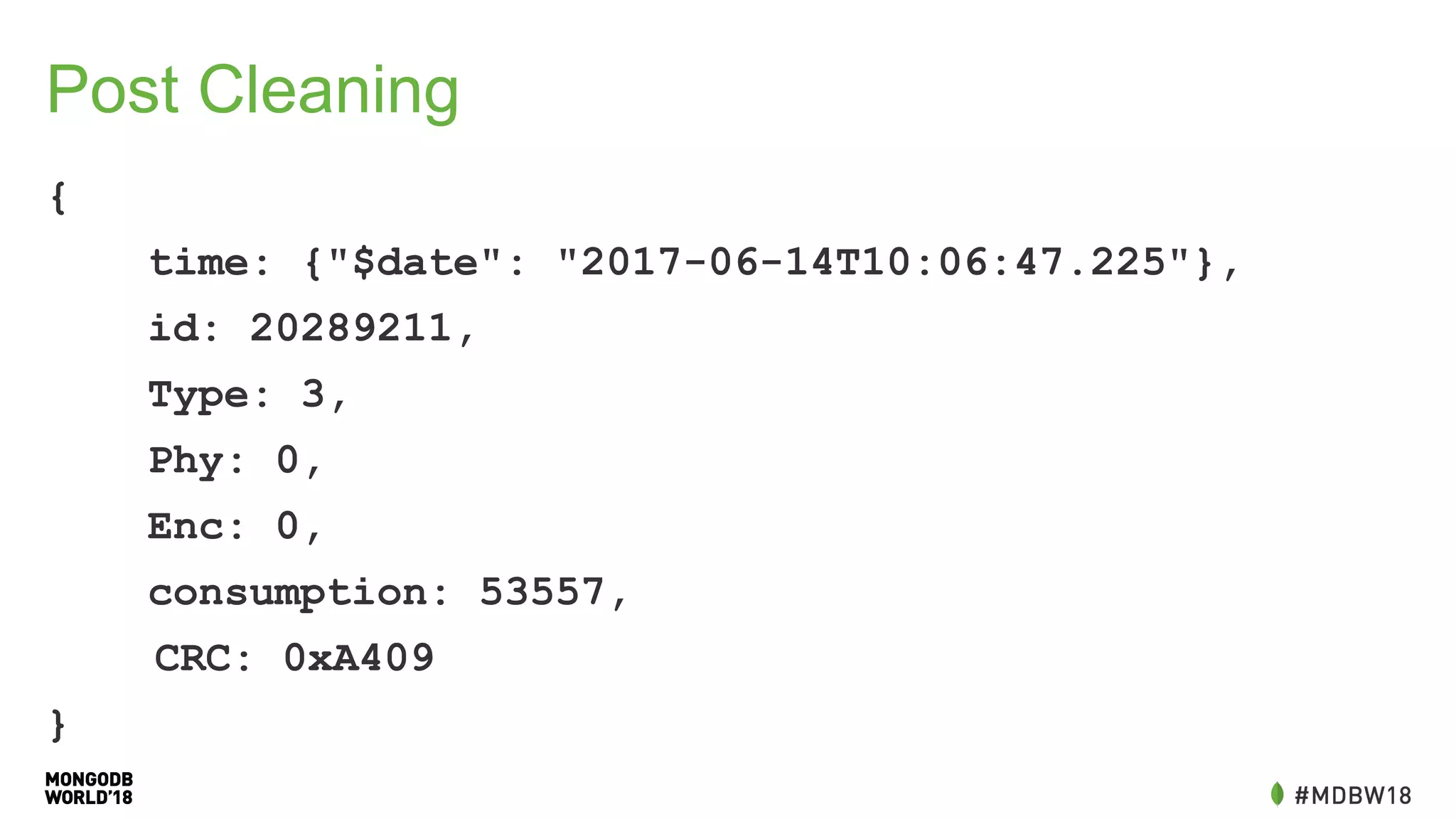
![Data Cleaning
#!/bin/bash
cat - | grep -E '^{' |
sed -e 's/Time.*Time/{Time/g' |
sed -e 's/:00,/:@/g' |
gsed -e 's/s+/ /g' |
sed -e 's/[{}]//g' |
sed -e 's/SCM://g' |
sed -e 's/Tamper://g' |
sed -e 's/^/{/g' |
sed -e 's/$/}/g' |
gsed -e 's/: +/:/g' |
sed -e 's/ /, /g' |
sed -e 's/, }/}/g' |
sed -e 's/Time:([^,]*),/Time:{"$date":"1Z"},/g' |
gsed -e 's/:0+([1-9][0-9]*,)/:1/g' |
sed -e 's/([^0-9]):0([^x])/1:2/g' |
sed -e 's/Time/time/g' |
sed -e 's/ID/id/g' |
sed -e 's/Consumption/consumption/g' |
sed -e 's/:@,/:0,/g' |
sed -e 's/Type:,/Type:0,/g' |
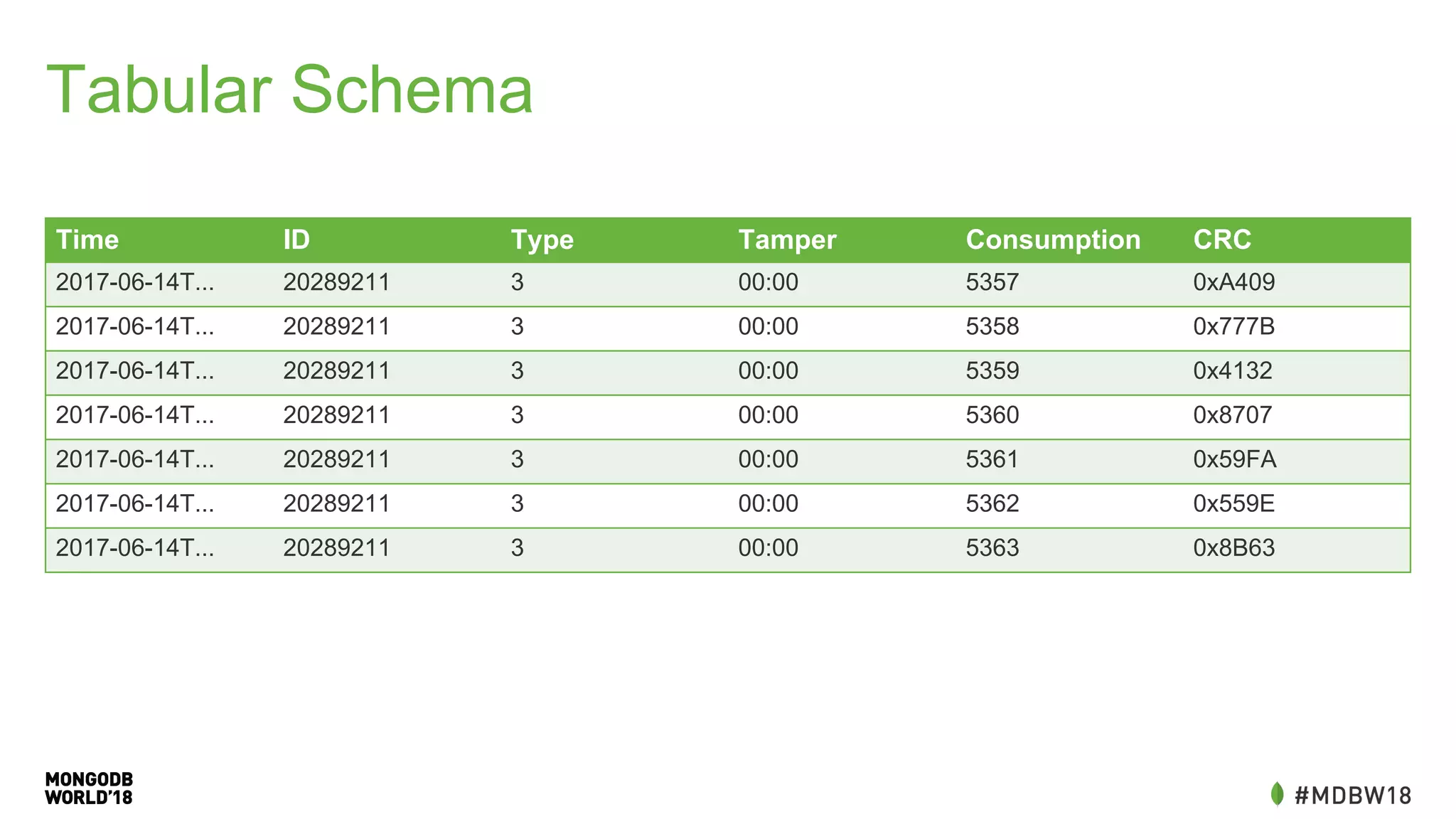
grep -v 'consumption:,'](https://image.slidesharecdn.com/mdbw2018overnightto60secondskevinarhelger-180709191547/75/MongoDB-World-2018-Overnight-to-60-Seconds-An-IOT-ETL-Performance-Case-Study-19-2048.jpg)




![Problem: Queries
• Query for monthly, daily, day of
week are similar.
• Generate ranges, grab a pair of
readings, calculate the
difference.
• Aggregation isn’t a great match.
before =
db.getSiblingDB("meters").mine.find({scm.id
: myid, time: {'$lte':
begin}}).sort({time:-1}).limit(1).toArray()
[0];
after =
db.getSiblingDB("meters").mine.find({scm.id
: myid, time: {'$gte':
end}}).sort({time:-1}).limit(1).toArray()[0
];
consumption = after.consumption -
before.consumption](https://image.slidesharecdn.com/mdbw2018overnightto60secondskevinarhelger-180709191547/75/MongoDB-World-2018-Overnight-to-60-Seconds-An-IOT-ETL-Performance-Case-Study-26-2048.jpg)

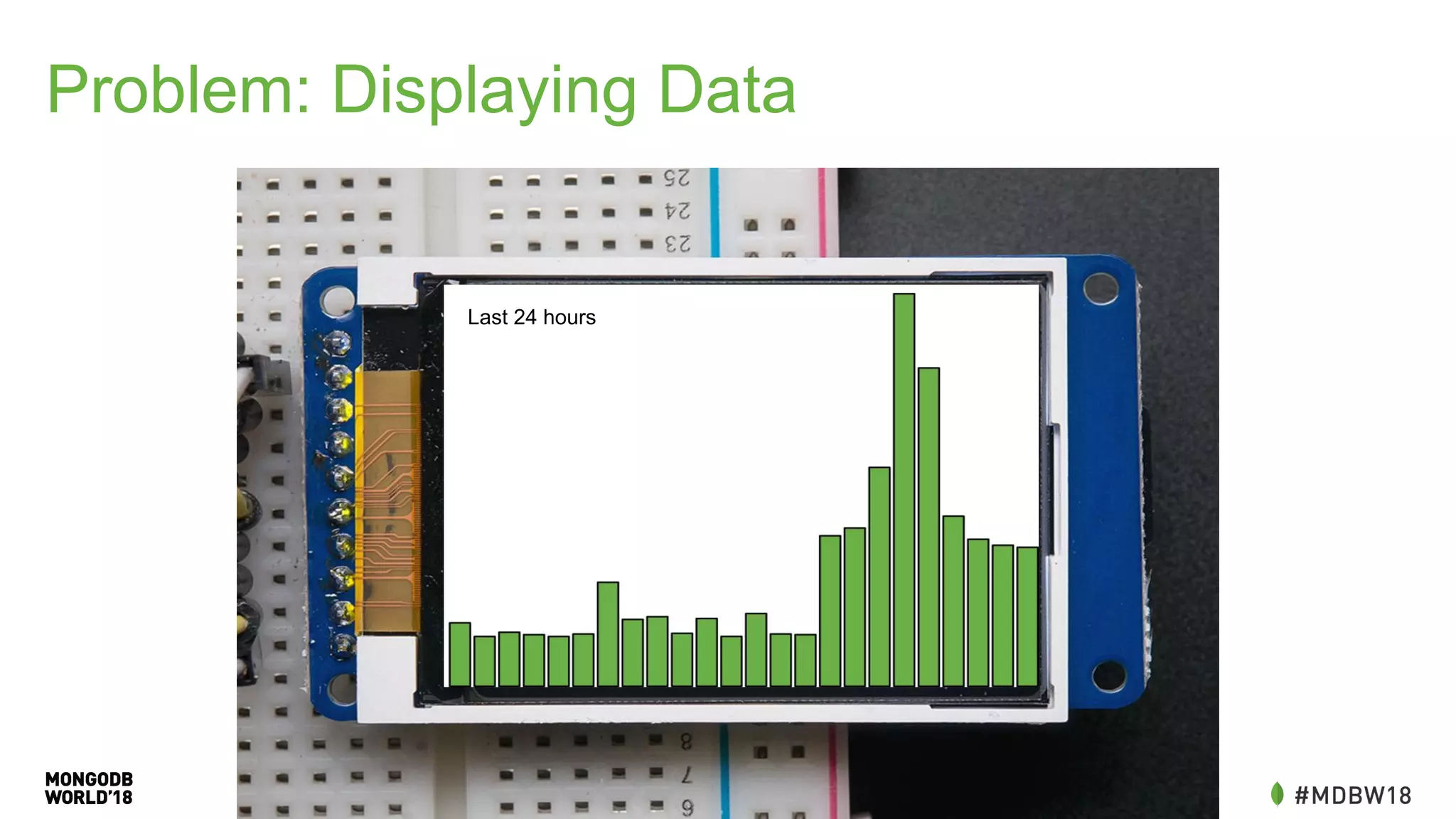
![Problem: Displaying Data
• Requires multiple calls to the
database
• Could be off by depending on
when we see readings
before =
db.getSiblingDB("meters").mine.find({scm.id:
myid, time:{'$lte':
begin}}).sort({time:-1}).limit(1).toArray()[0];
readings = db.getSiblingDB("meters").mine.find({
scm.id: myid,
time: {$gte: before.time})
.sort({time:1})
var previous = readings.shift();
var count = 0;
var hourly = [];
readings.forEach(reading => {
if(hourly.length > 24) return;
if(reading.time.getHours() != previous.getHours()){
hourly.push(reading.consumption -
previous.consumption); previous = reading;
}
});](https://image.slidesharecdn.com/mdbw2018overnightto60secondskevinarhelger-180709191547/75/MongoDB-World-2018-Overnight-to-60-Seconds-An-IOT-ETL-Performance-Case-Study-29-2048.jpg)


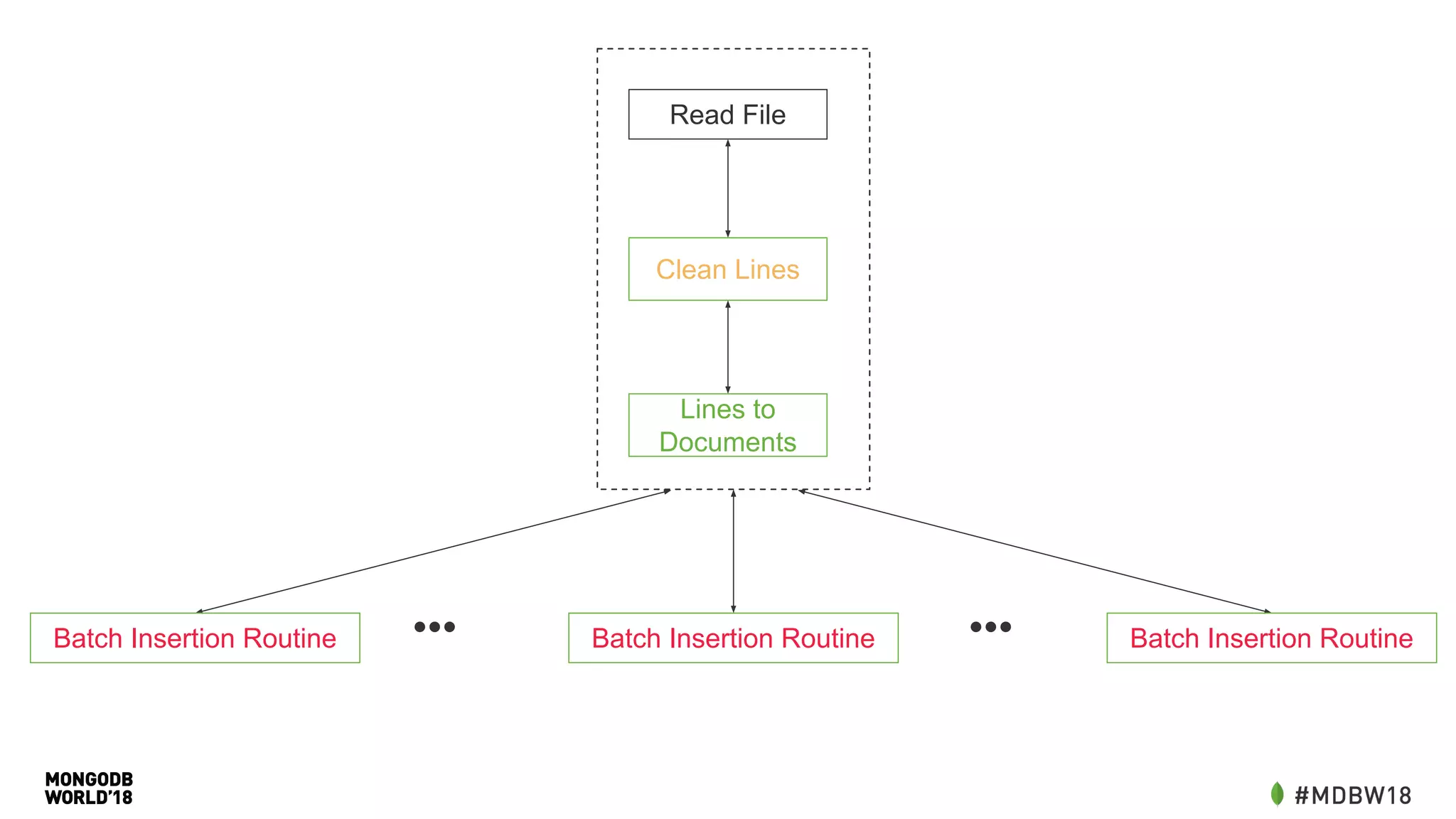
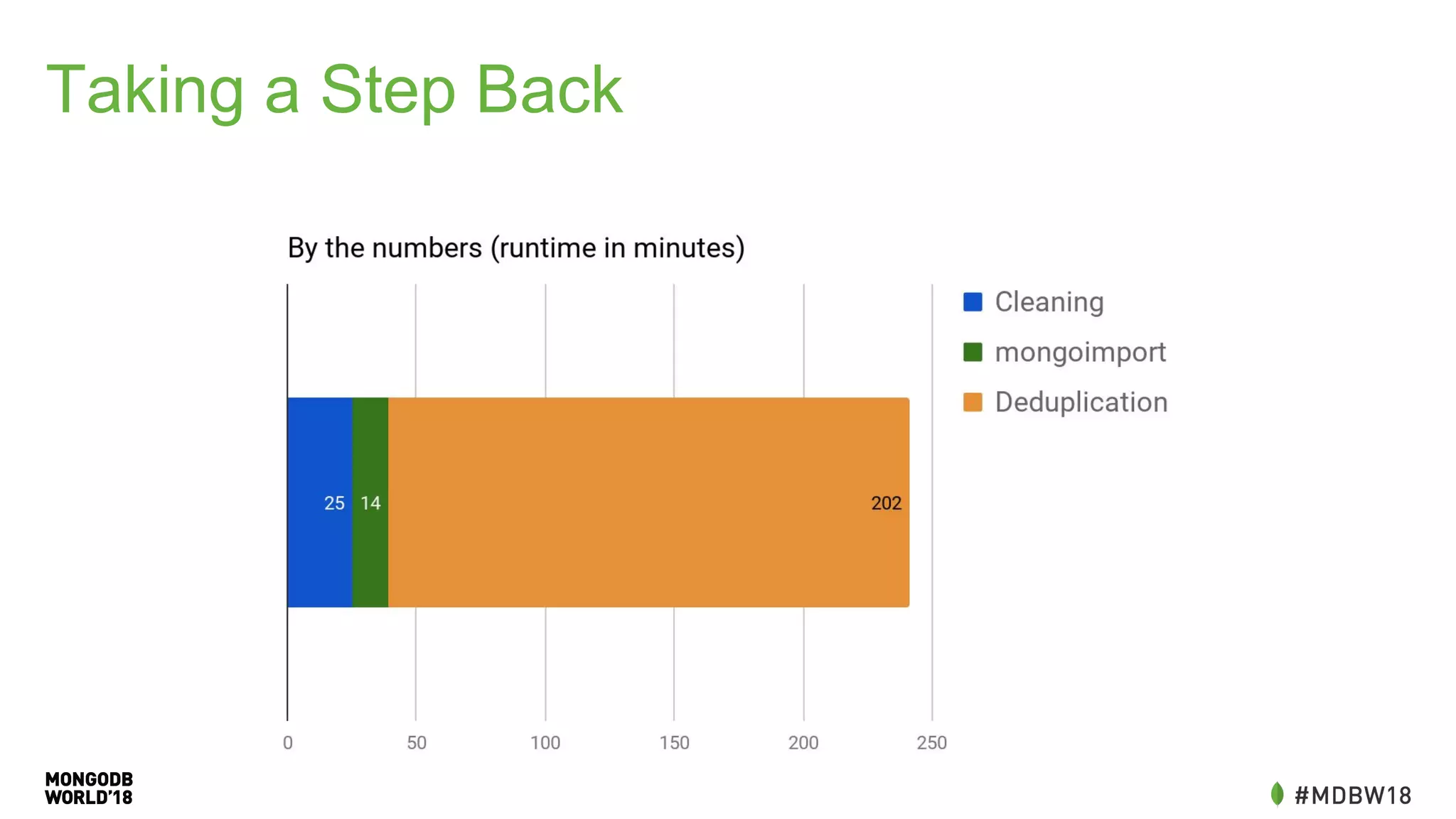
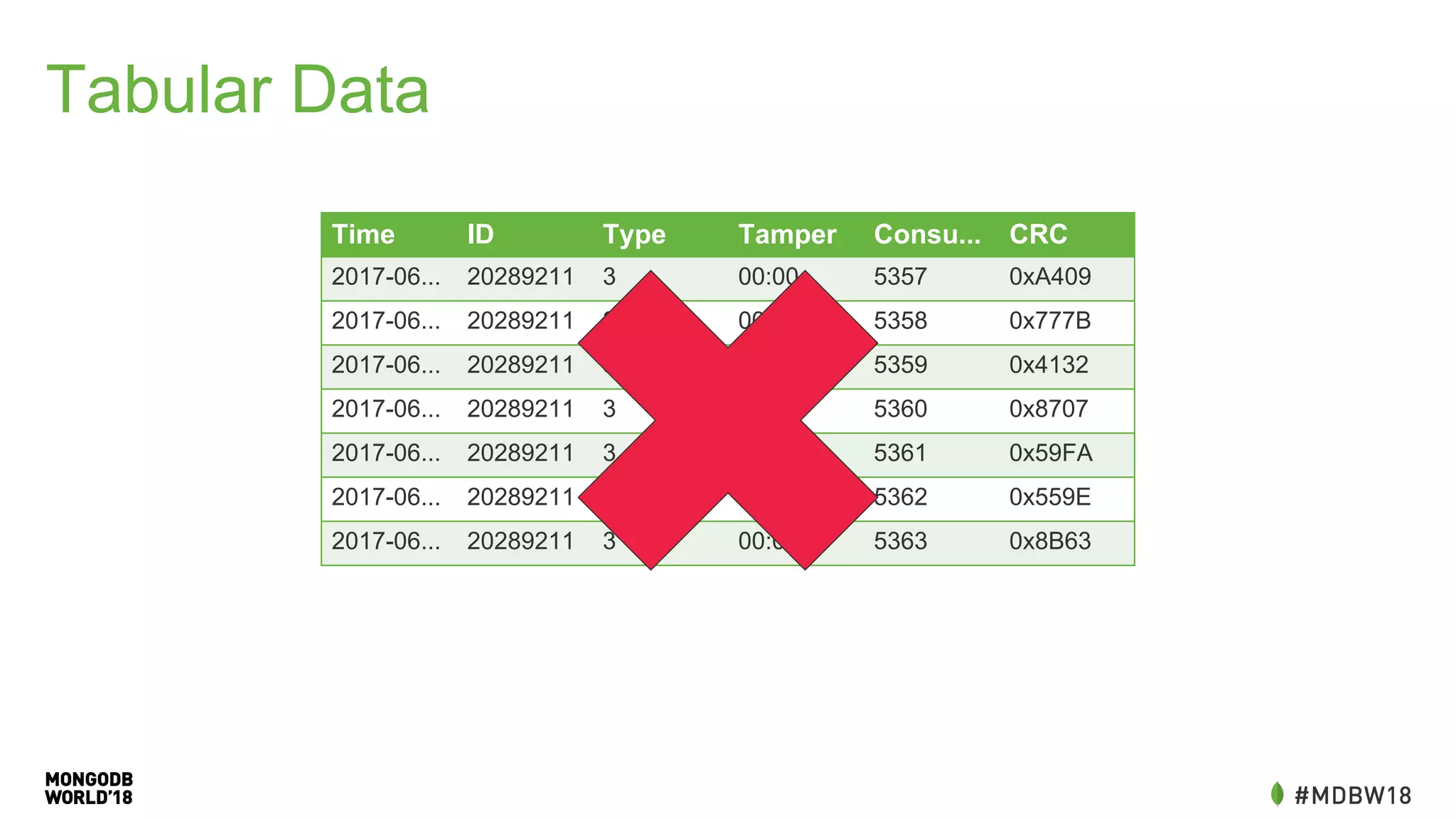


![New Schema
{
"_id" : ObjectId("54de8229791e4b133c000052"),
"meter" : 29026302,
"date" : new Date("2015-02-13T17:00:57"),
"hour" : 17,
"weekday" : 5,
"day" : 13,
"month" : 2,
"year" : 2015,
"consumption" : 5.526729939432698,
"begin" : 50480.575901639124,
"end" : 50486.10263157856,
"before" : {...},
"after" : {...},
"readings" : [ ... ]
}](https://image.slidesharecdn.com/mdbw2018overnightto60secondskevinarhelger-180709191547/75/MongoDB-World-2018-Overnight-to-60-Seconds-An-IOT-ETL-Performance-Case-Study-37-2048.jpg)




![Queries: Daily Consumption
• Grab the convenient fields
• Sum the consumption
daily =
db.getSiblingDB("meters").mine.aggregate([{
$match: {
meter: myid
year: 2018
month: 8
day: 26
}},
{$group: {“_id”: 1, total: {“$sum” :
consumption}}])[0].consumption](https://image.slidesharecdn.com/mdbw2018overnightto60secondskevinarhelger-180709191547/75/MongoDB-World-2018-Overnight-to-60-Seconds-An-IOT-ETL-Performance-Case-Study-43-2048.jpg)


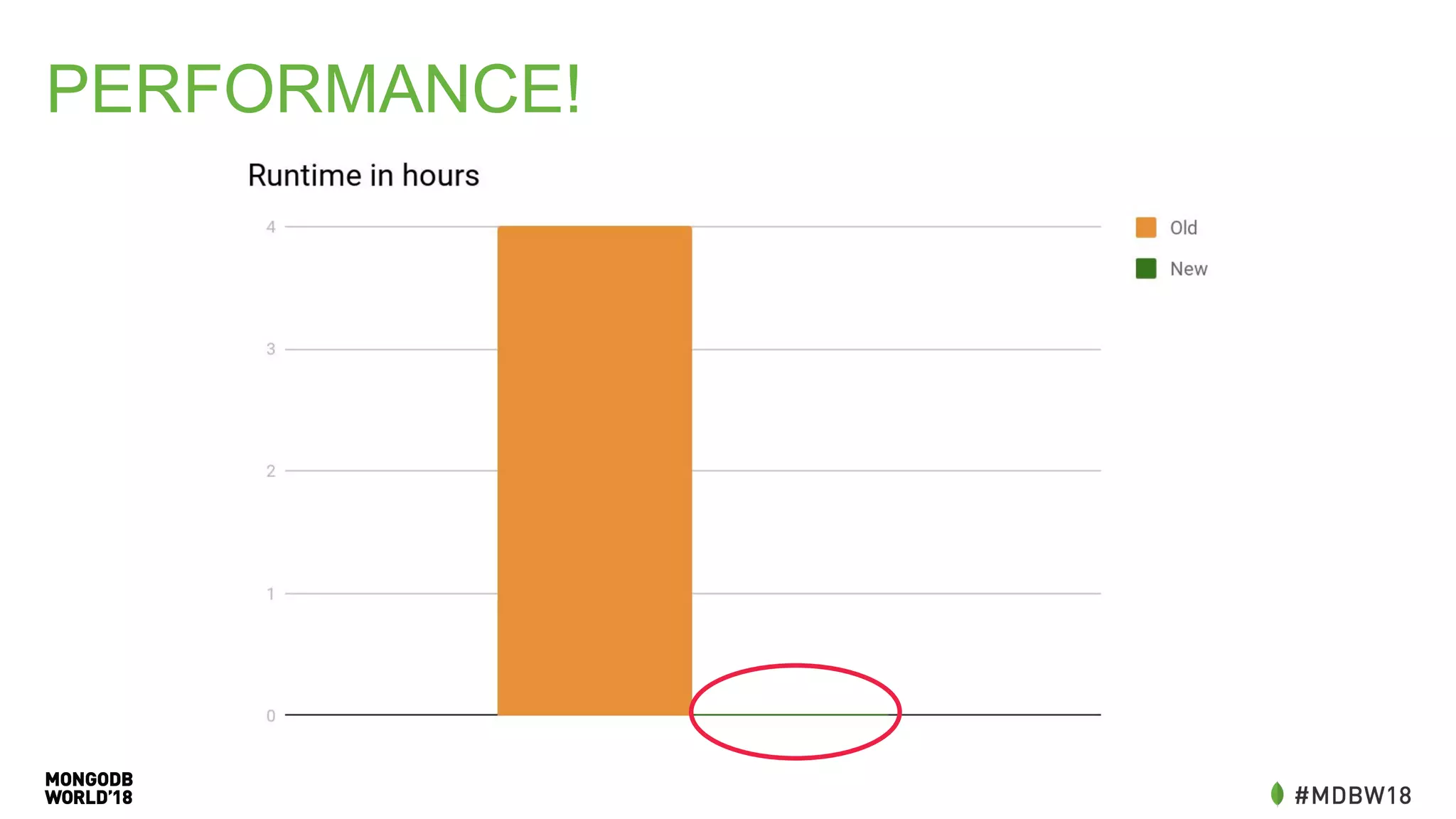



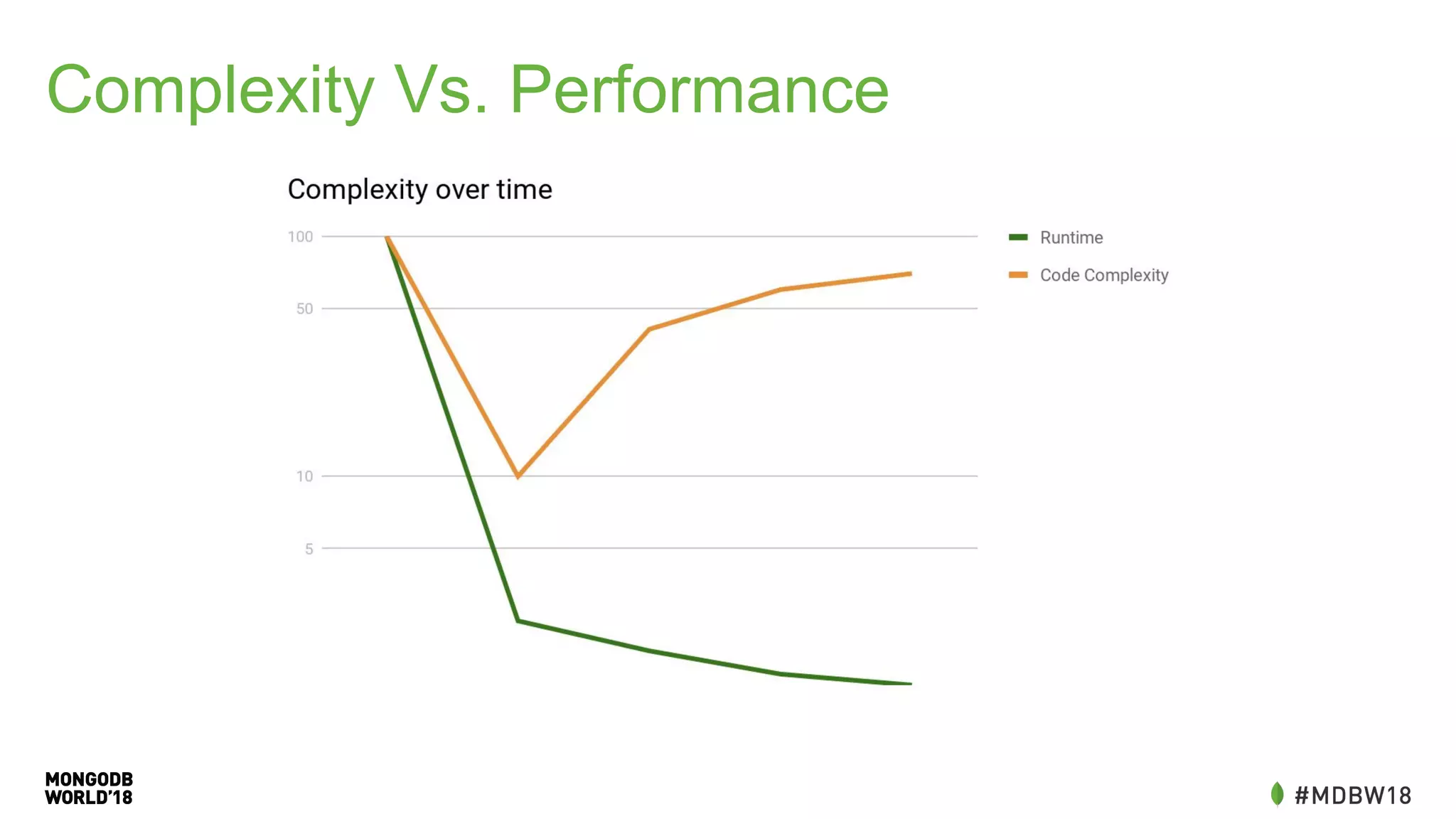
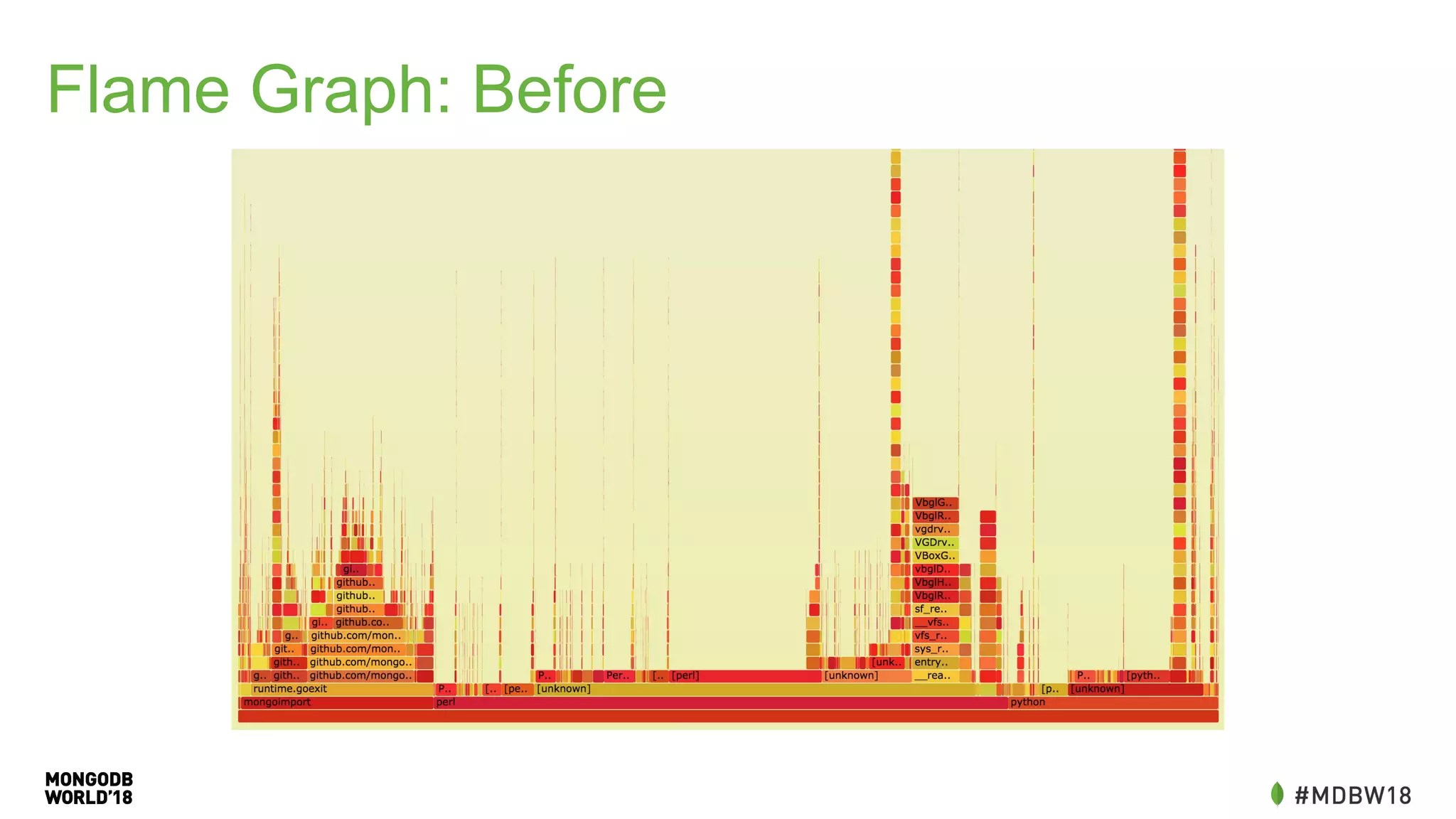
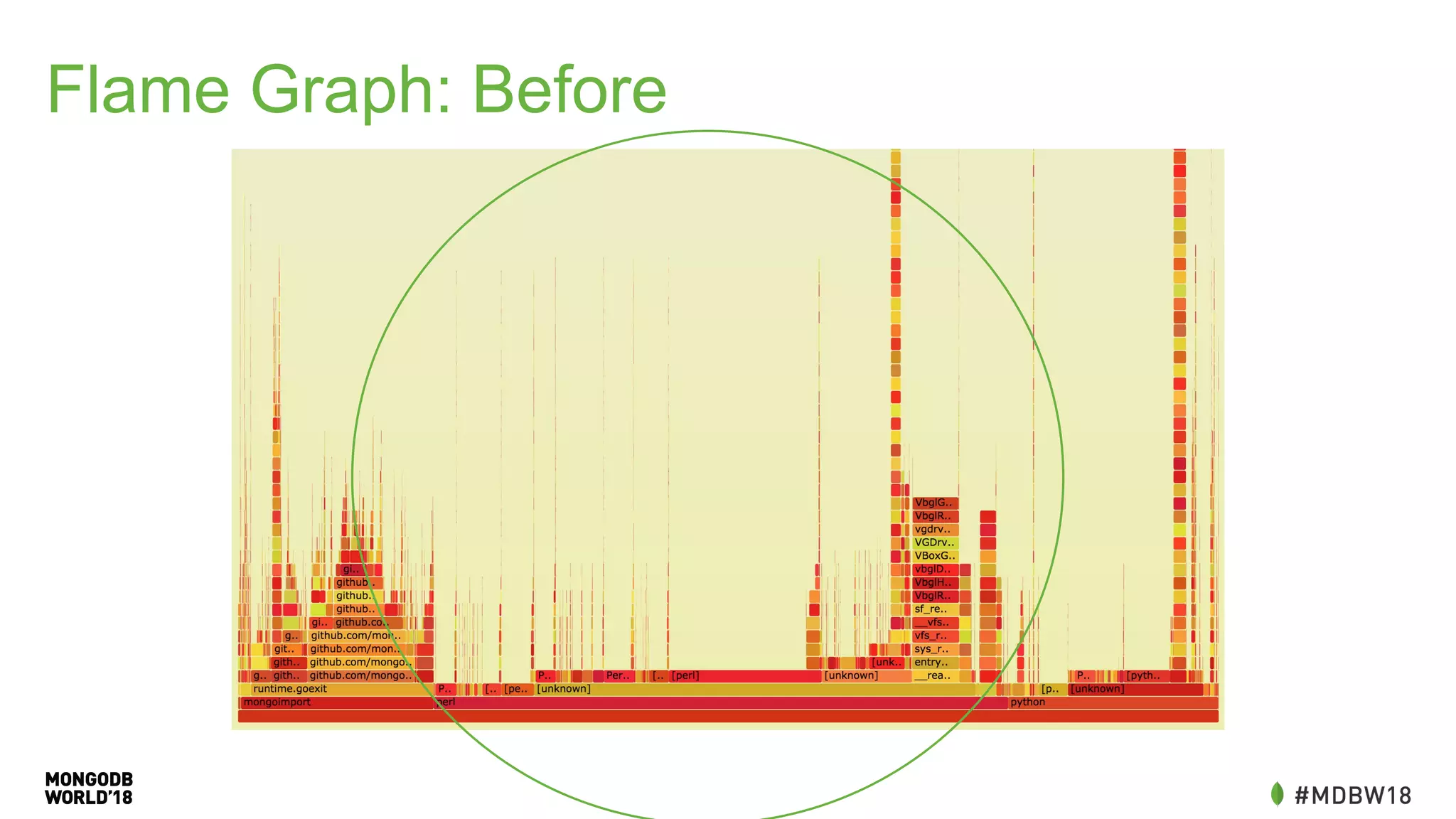
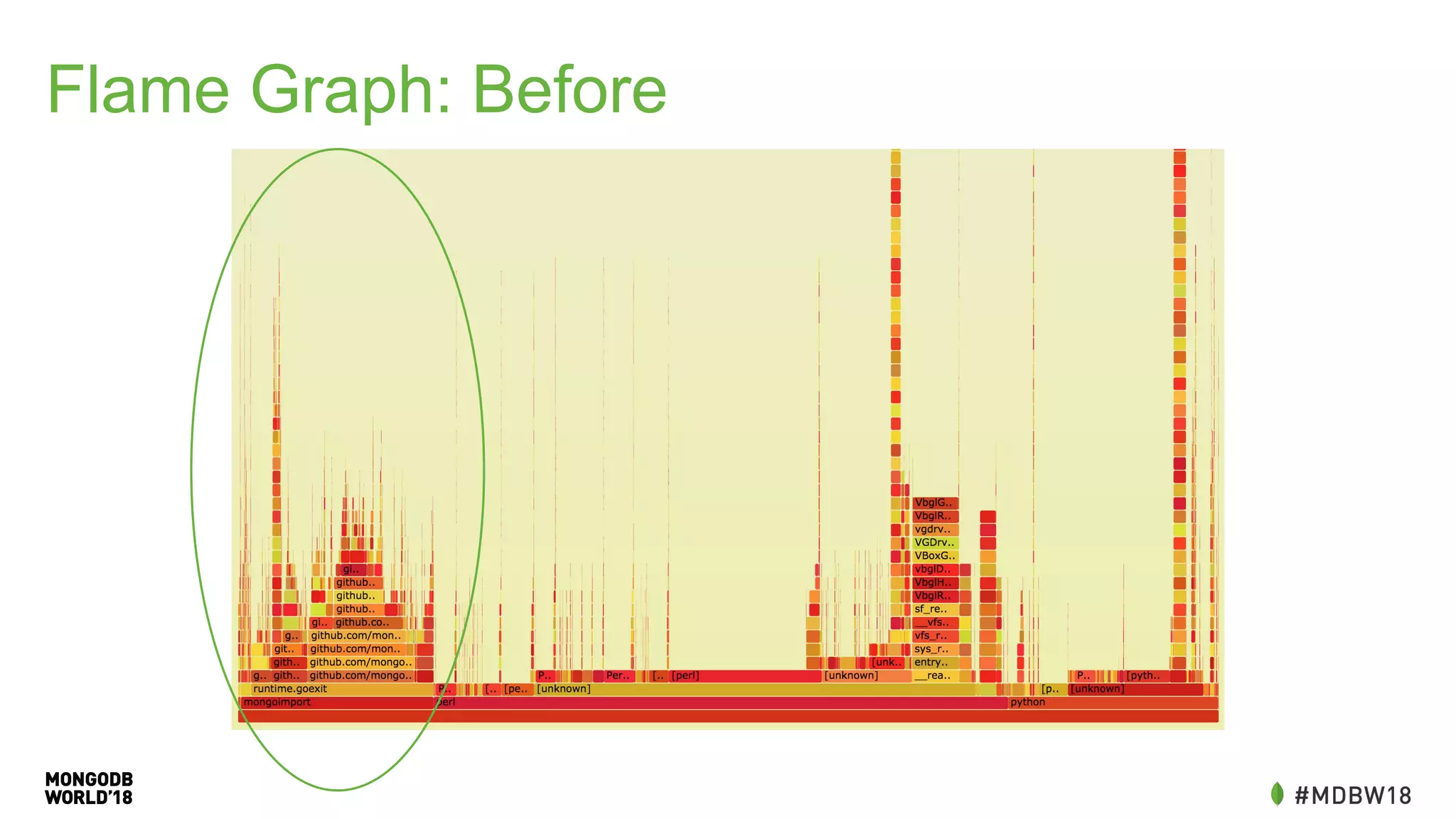
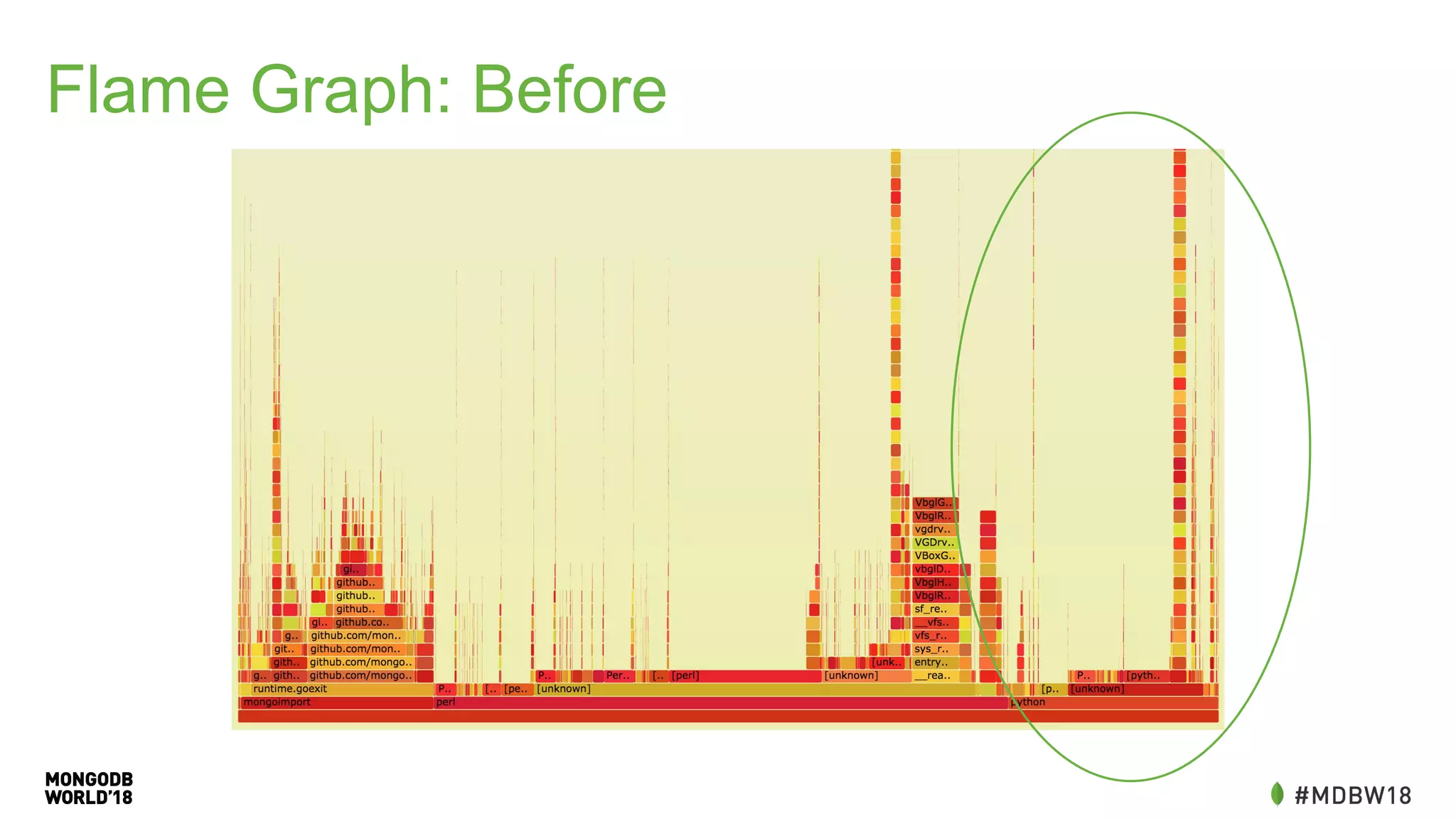
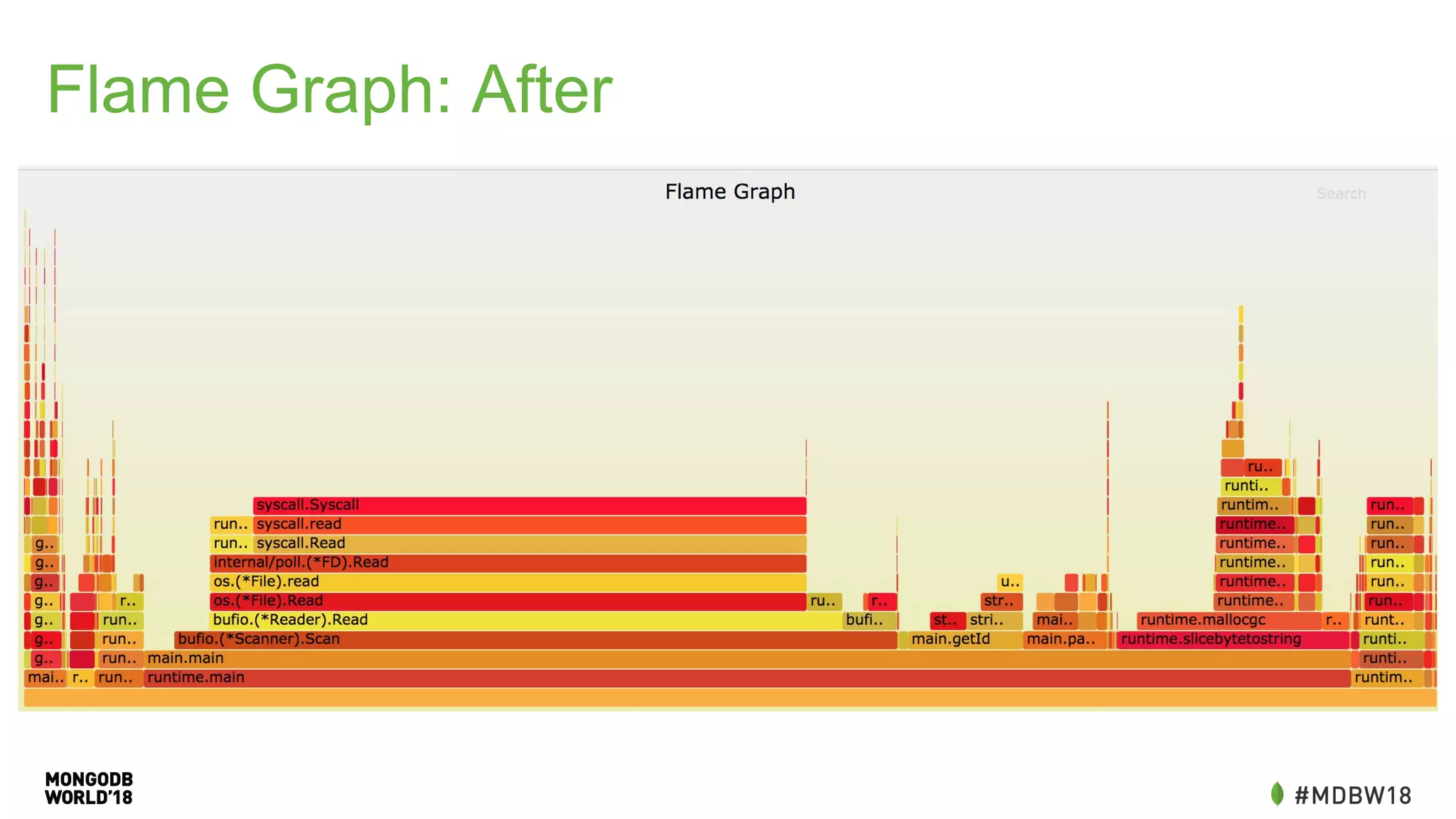
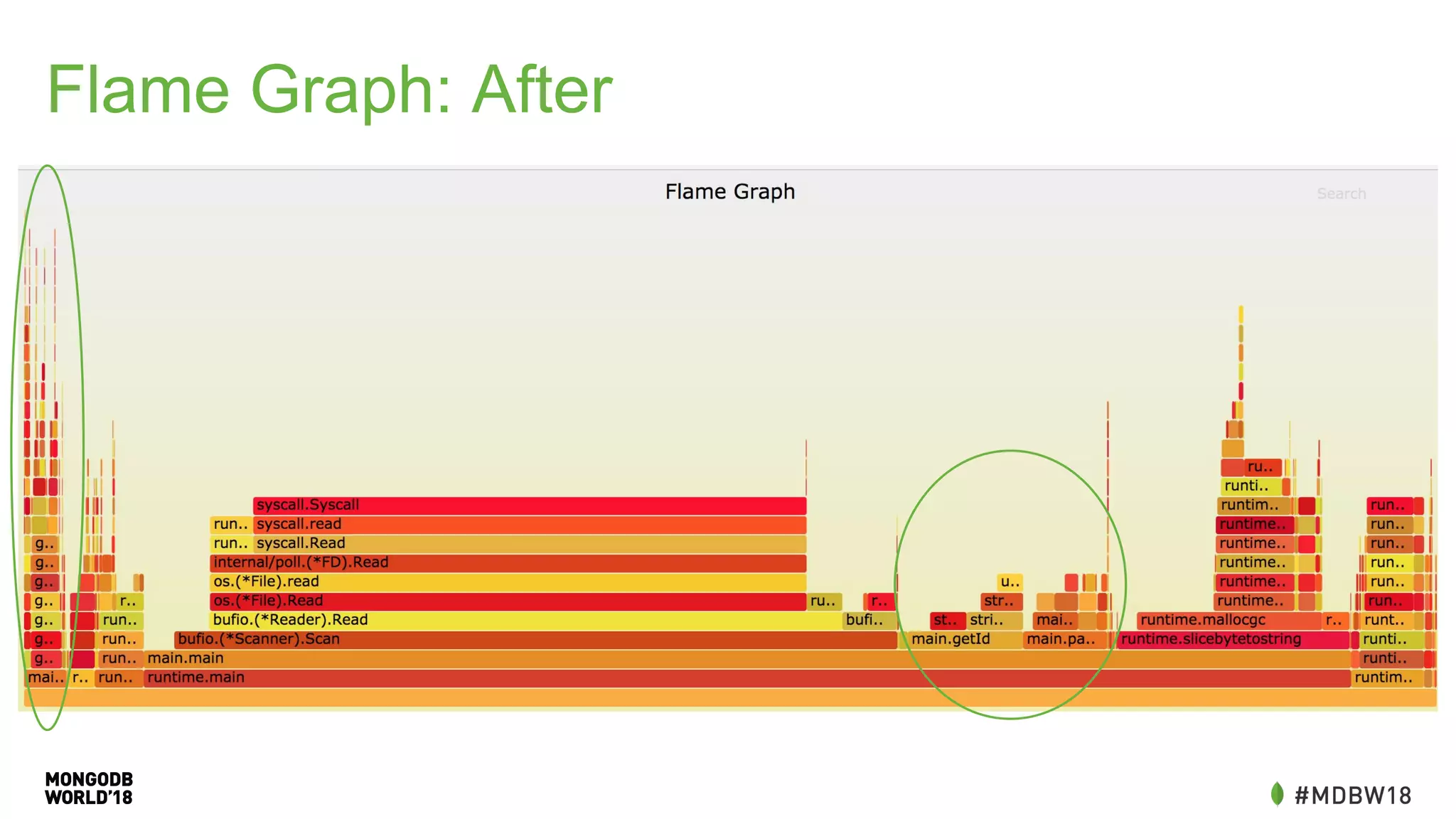





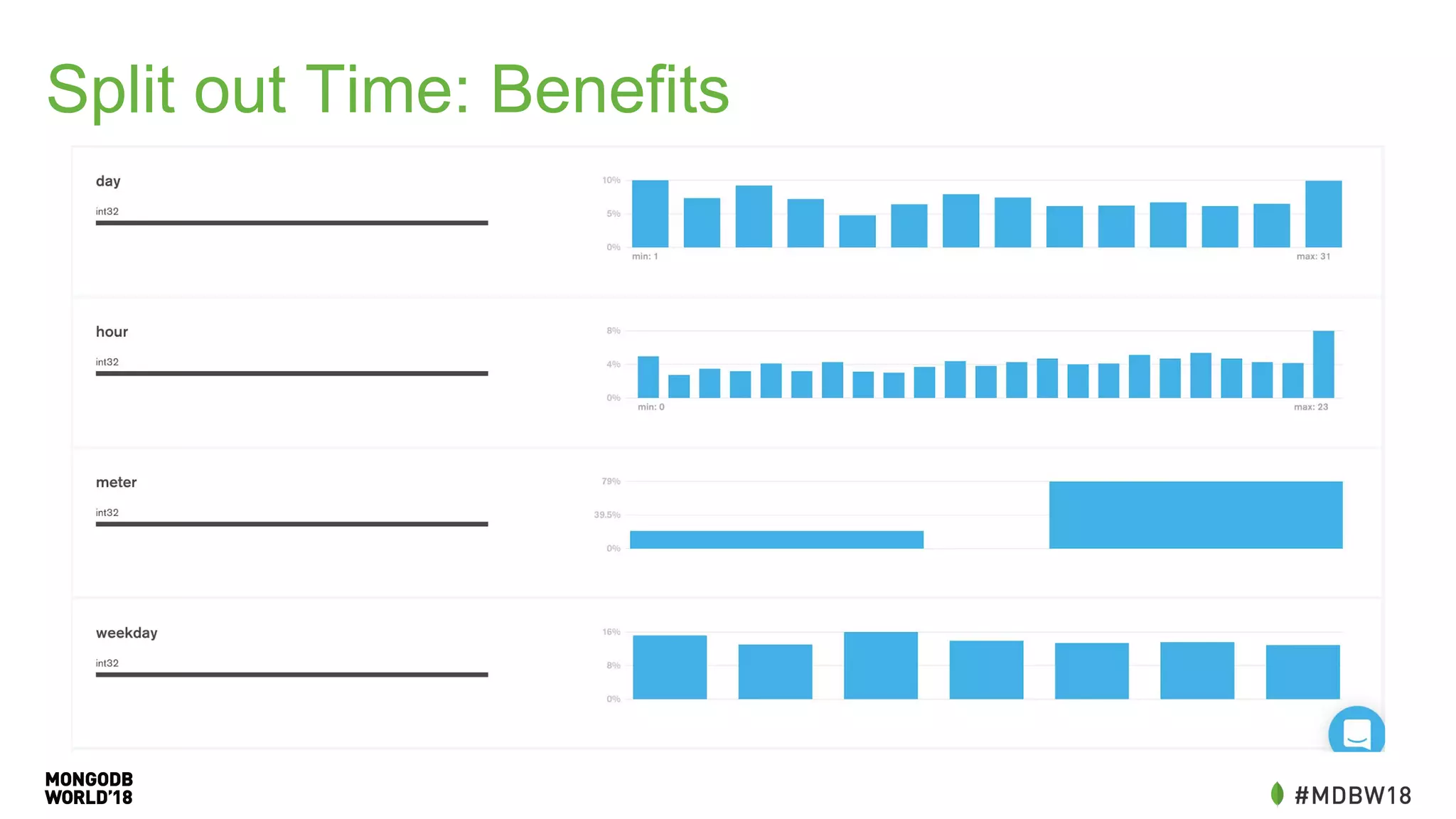
The document summarizes an IOT ETL performance case study where the author collected water and electric meter data and loaded it into a database. The initial load of over 90 million documents from a 10GB file into a MongoDB database took over 4 hours. The author then redesigned the data schema, splitting it into hourly documents to improve query performance. This reduced the processing time to just 3 minutes and the data size to 13MB. The key lessons were that changing the data schema and using batch writes with multiple workers can dramatically improve ETL and query performance.






















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































