Downloaded 12 times


![Page 3
Objectives (1)
ONE Conference 2013 - 26th September 2013
3- Processing bursting
2- Dissemination peaks
1- ICT Costs savings
4- Collaboration platform
Cloud Computing
IaaS
SaaS
Hosting
(VPS, Rental)
CDN
PaaS
A model for enabling convenient, on-demand network
access to a shared pool of configurable computing
resources (e.g., networks, servers, storage, applications,
and services) that can be rapidly provisioned and
released with minimal management effort or service
provider interaction [NIST]](https://image.slidesharecdn.com/one2103-j-131009090533-phpapp02/75/Opening-the-Path-to-Technical-Excellence-3-2048.jpg)

![Page 5
Objectives (1)
ONE Conference 2013 - 26th September 2013
3- Processing bursting
2- Dissemination peaks
1- ICT Costs savings
4- Collaboration platform
Cloud Computing
IaaS
SaaS
Hosting
(VPS, Rental)
CDN
PaaS
A model for enabling convenient, on-demand network
access to a shared pool of configurable computing
resources (e.g., networks, servers, storage, applications,
and services) that can be rapidly provisioned and
released with minimal management effort or service
provider interaction [NIST]
5- Lead effective use of modern
computing infrastructures
by European industry](https://image.slidesharecdn.com/one2103-j-131009090533-phpapp02/75/Opening-the-Path-to-Technical-Excellence-5-2048.jpg)


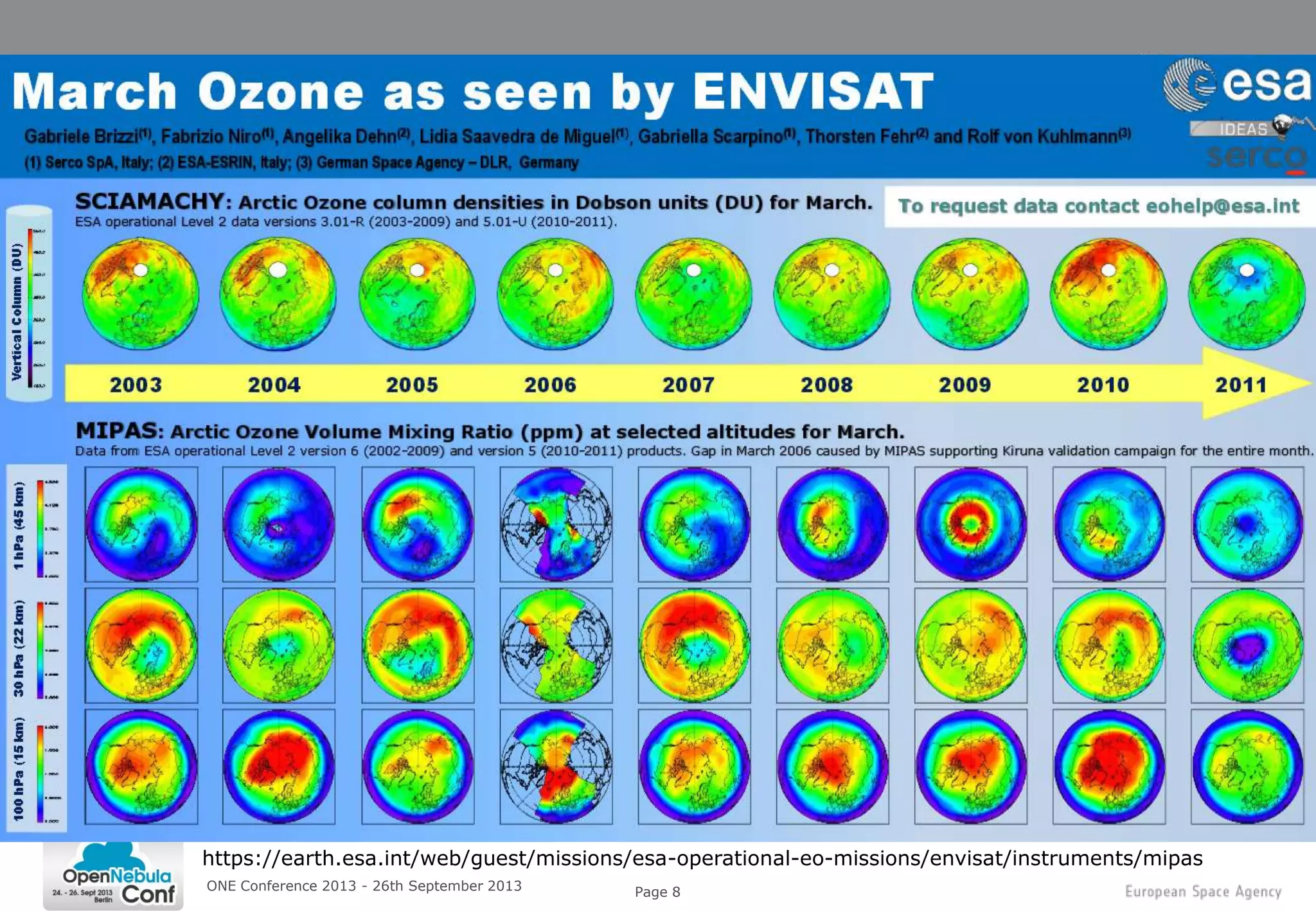
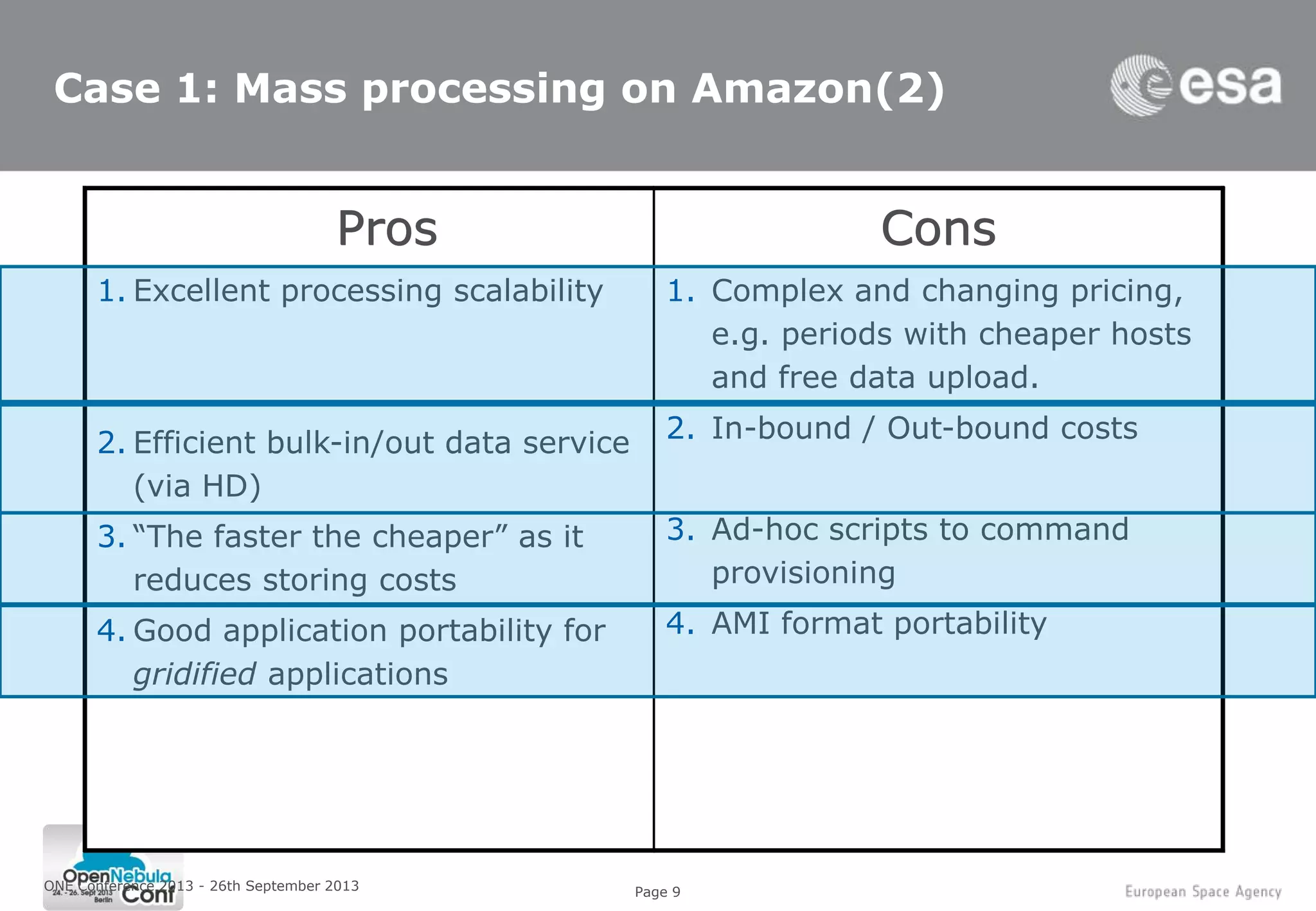


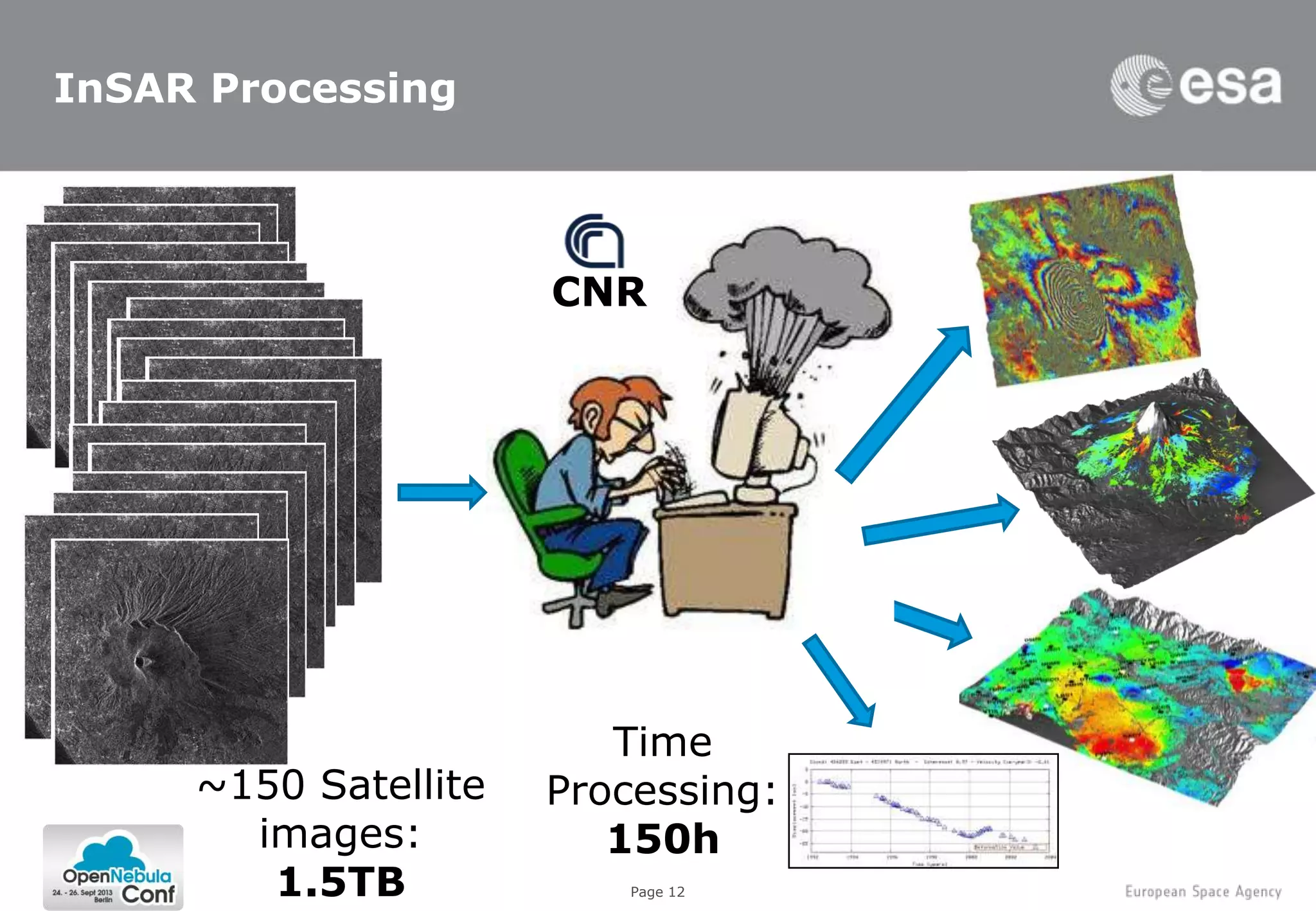
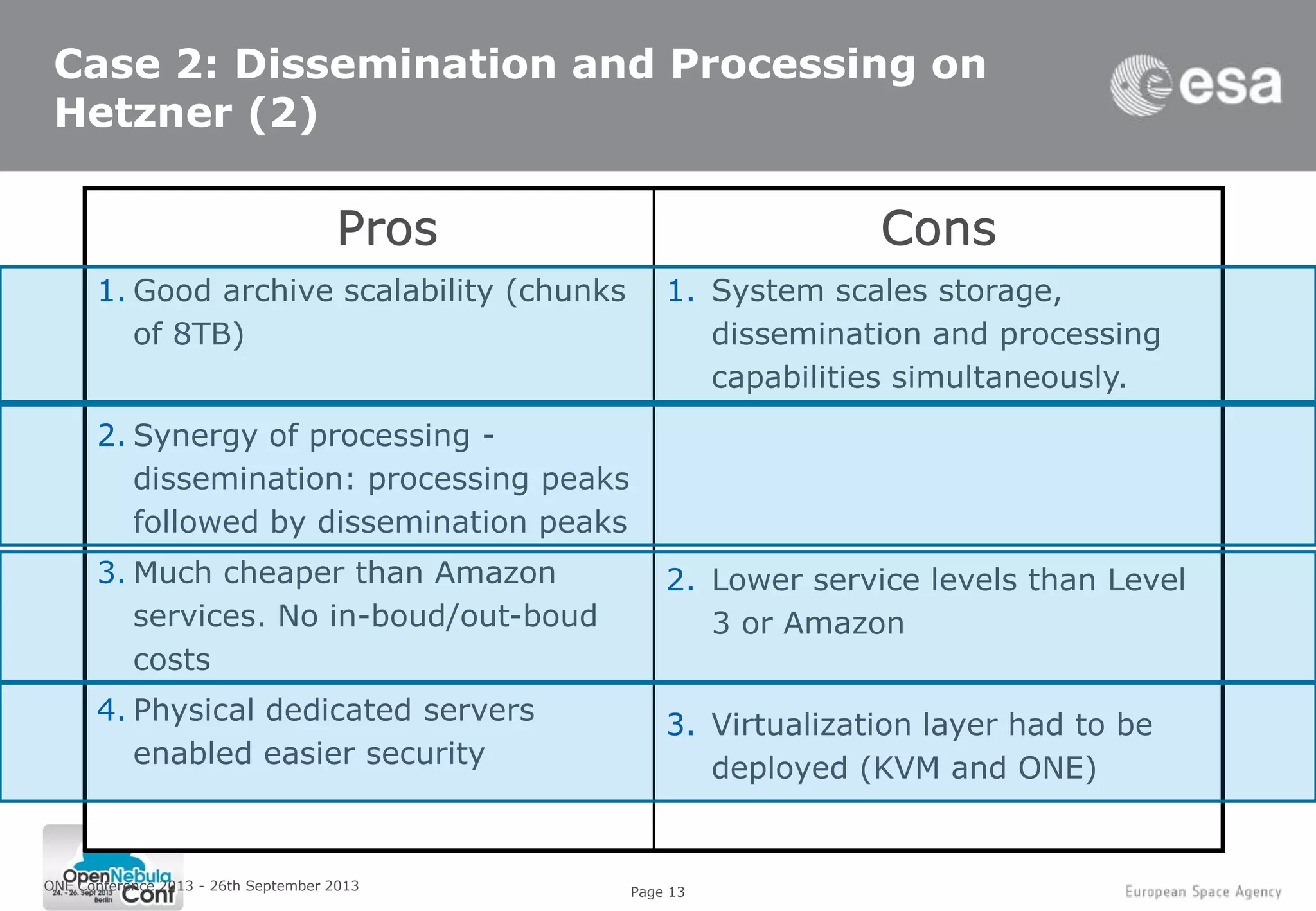


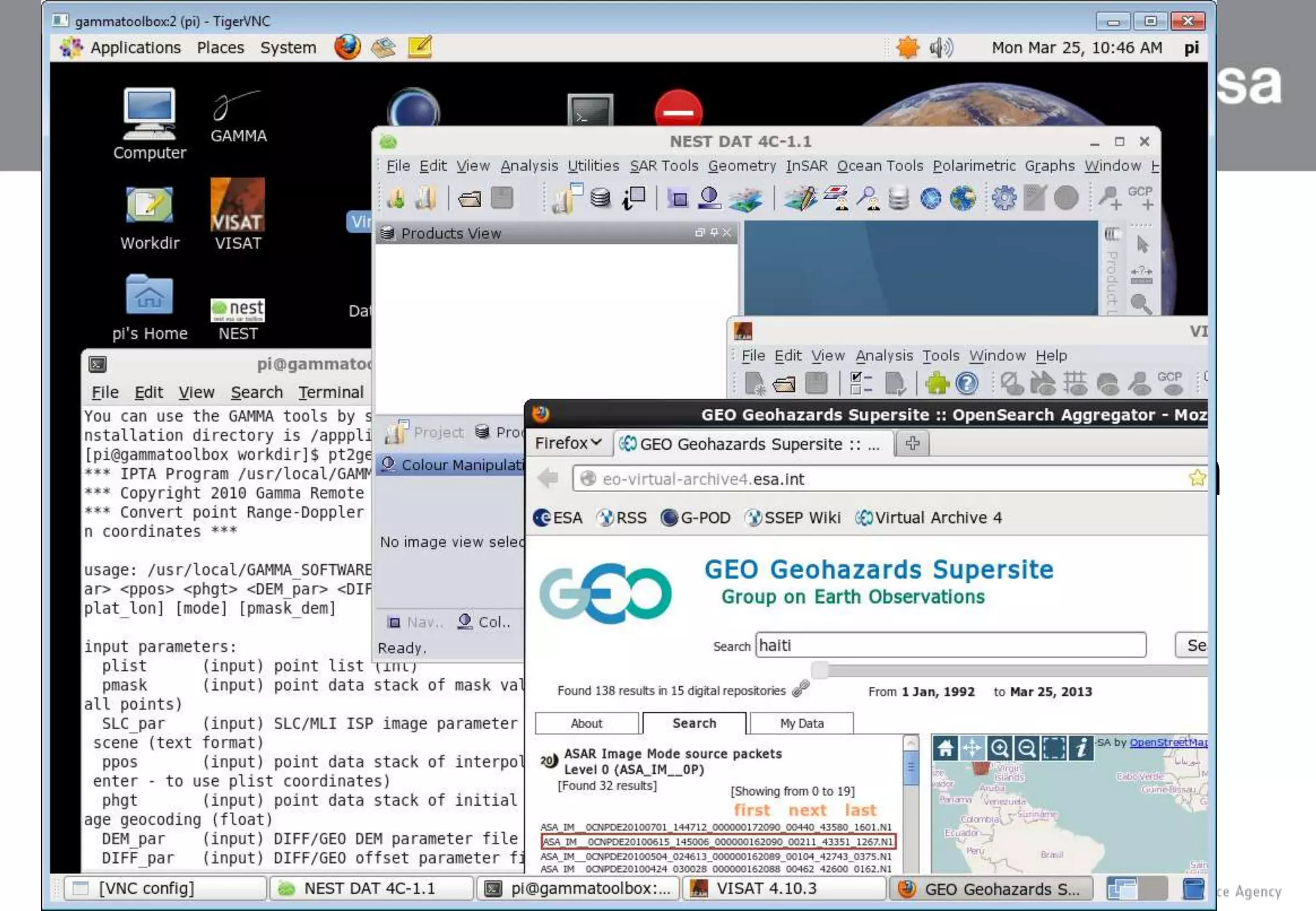



















This document summarizes a presentation given at the ONE Conference 2013 about using cloud computing for Earth observation ground segments. It describes four cases where the European Space Agency used cloud computing: 1. Mass re-processing of satellite data on Amazon Web Services for validation purposes, allowing processing of 30,000 products in 5 weeks. 2. Coupling large data dissemination and processing capabilities on dedicated servers from Hetzner for analyzing 38,000 satellite images and serving 3,000 users. 3. A collaborative exploitation platform using multiple cloud providers through Helix Nebula for exploiting Earth observation data from various sources and making it available to over 200 users. 4. Plans for a sandbox service providing researchers and service providers





























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















