Download as PDF, PPTX



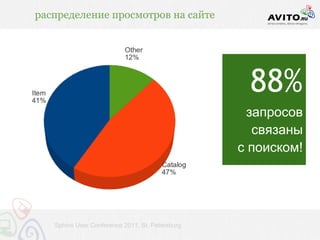
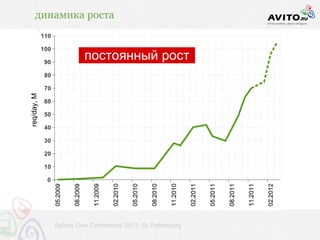


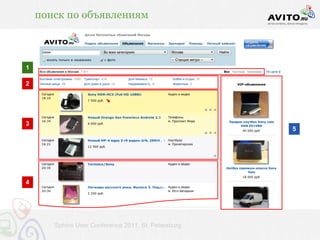
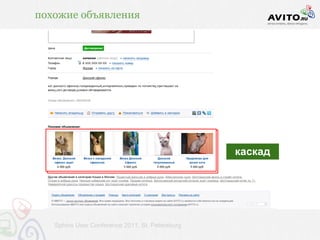




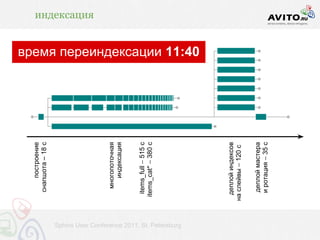







![индексация / время построения и чтения
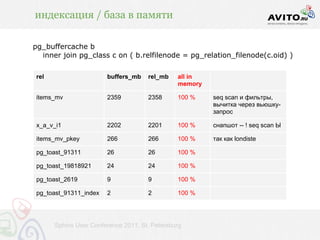
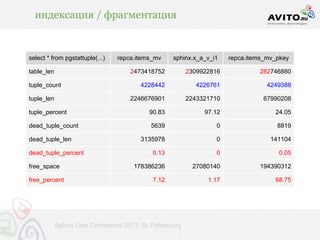
• psql ... -c 'begin; [строим_снапшот]; end;' (18 с)
• в 9.2 не надо будет строить таблицу в принципе
• можно будет из сессии экспортировать
транзакционный снапшот из mvcc
Sphinx User Conference 2011, St. Petersburg](https://image.slidesharecdn.com/avito-sphinxconf20111-111204171112-phpapp01/85/Sphinx-26-320.jpg)

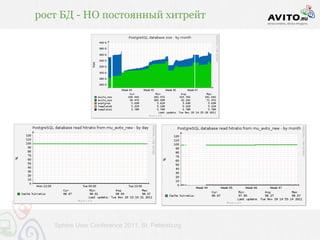
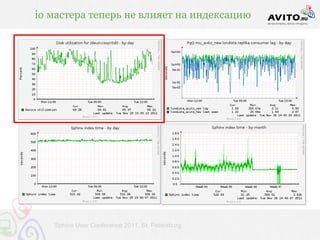





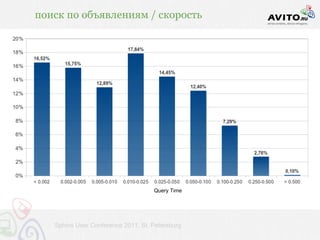
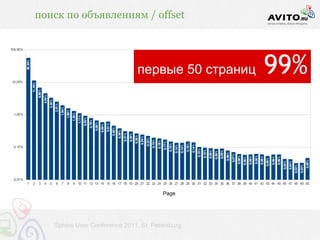
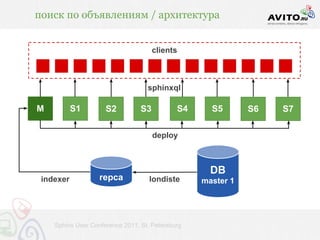
Документ описывает мощную архитектуру поисковой системы, используемой в Avito, с акцентом на обработку 60 миллионов запросов в сутки и динамическое управление активными объявлениями. Приведены технические детали, включая используемые технологии (nginx, php-fpm, postgresql, redis и др.) и методы индексирования, обеспечивающие высокую скорость выдачи. Также речь идет о внедрении автодополнения и оптимизации запросов для улучшения пользовательского опыта.






















































