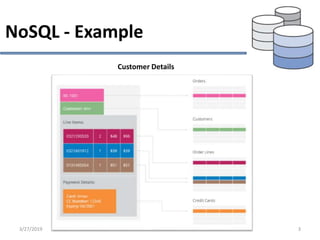
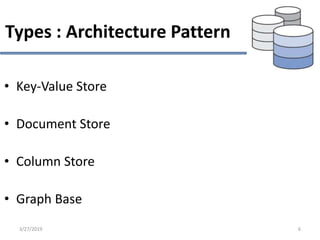
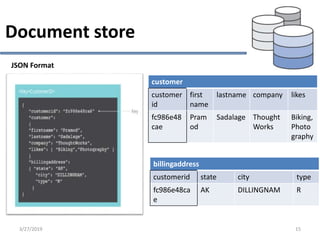
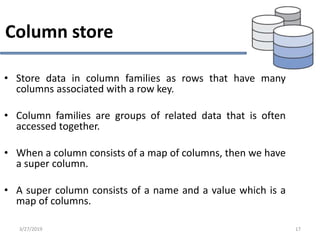
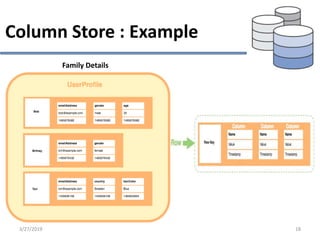
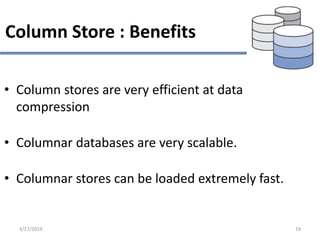
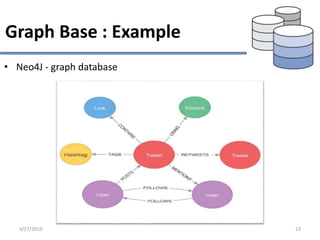
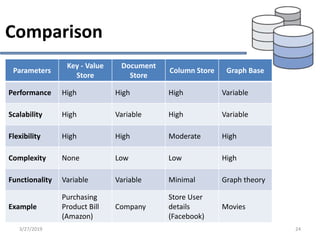
This document provides an overview of NoSQL database types including key-value stores, document stores, column stores, and graph databases. It describes their main characteristics such as schema flexibility, performance, scalability, and examples of popular databases for each type. Key-value stores provide simple get, put, delete functionality and are very fast and scalable. Document stores store semi-structured data like JSON and support complex queries. Column stores optimize data storage by column and are efficient for analytics. Graph databases specialize in storing network-like relationships between entities.





























































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)















