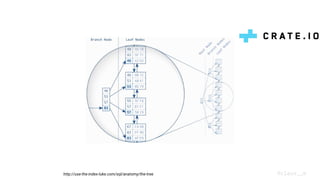
CrateDB and PostgreSQL are discussed. PostgreSQL uses a multi-process architecture with B-tree indexes and ACID transactions, while CrateDB uses a distributed, multi-threaded architecture with Lucene indexes and eventual consistency. PostgreSQL excels for transactions and SQL features on a single node but struggles with distribution. CrateDB handles distribution naturally with high ingest speeds but lacks some SQL features and ACID transactions. PostgreSQL is suited for transactional workloads and small datasets, while CrateDB works well for analytics, machine learning, and fulltext search on large datasets.
































































![[EPPG] Oracle to PostgreSQL, Challenges to Opportunity](https://cdn.slidesharecdn.com/ss_thumbnails/eppg-oracletopostgresqlchallengestoopportunity-190409033058-thumbnail.jpg?width=640&height=640&fit=bounds)
































