Downloaded 27 times





![Lemon - Example
: l e x i c o n a lemon : Lexicon ;
lemon : entry : Pizza , : T o r t i l l a .
: Pizza a lemon : LexicalEntry ;
lemon : sense [ lemon : r e f e r e n c e
http :// dbpedia . org / resource /Pizza ] .
: T o r t i l l a a lemon : LexicalEntry ;
lemon : sense [ lemon : r e f e r e n c e
http :// dbpedia . org / resource / T o r t i l l a ] .
Kontokostas et al. (ESWC2014) NLP Data Cleansing 2014-05-27 10 / 33](https://image.slidesharecdn.com/slides-140527081934-phpapp02/75/NLP-Data-Cleansing-Based-on-Linguistic-Ontology-Constraints-10-2048.jpg)
![Lemon - Example (Correct)
: l e x i c o n a lemon : Lexicon ;
lemon : language en ;
lemon : entry : Pizza , : T o r t i l l a .
: Pizza a lemon : LexicalEntry ;
lemon : canonicalForm [
lemon : writtenRep Pizza @en ] ;
lemon : sense [ lemon : r e f e r e n c e
http :// dbpedia . org / resource /Pizza ].
: T o r t i l l a a lemon : LexicalEntry ;
lemon : canonicalForm [
lemon : writtenRep T o r t i l l a @en ] ;
lemon : sense [ lemon : r e f e r e n c e
http :// dbpedia . org / resource / T o r t i l l a ].
Kontokostas et al. (ESWC2014) NLP Data Cleansing 2014-05-27 11 / 33](https://image.slidesharecdn.com/slides-140527081934-phpapp02/75/NLP-Data-Cleansing-Based-on-Linguistic-Ontology-Constraints-11-2048.jpg)











![Example of manual NIF test case
Ensure that nif:beginIndex nif:endIndex index are correct
SELECT DISTINCT ? s WHERE {
? s n i f : anchorOf ? anchorOf ;
n i f : beginIndex ? beginIndex ;
n i f : endIndex ? endIndex ;
n i f : referenceContext
[ n i f : i s S t r i n g ? r e f e r e n c e S t r i n g ] .
BIND (SUBSTR(? r e f e r e n c e S t r i n g ,
? beginIndex ,
(? endIndex − ? beginIndex ) ) AS ? t e s t ) .
FILTER ( s t r (? t e s t ) != s t r (? anchorOf ) ) . }
Kontokostas et al. (ESWC2014) NLP Data Cleansing 2014-05-27 29 / 33](https://image.slidesharecdn.com/slides-140527081934-phpapp02/75/NLP-Data-Cleansing-Based-on-Linguistic-Ontology-Constraints-29-2048.jpg)
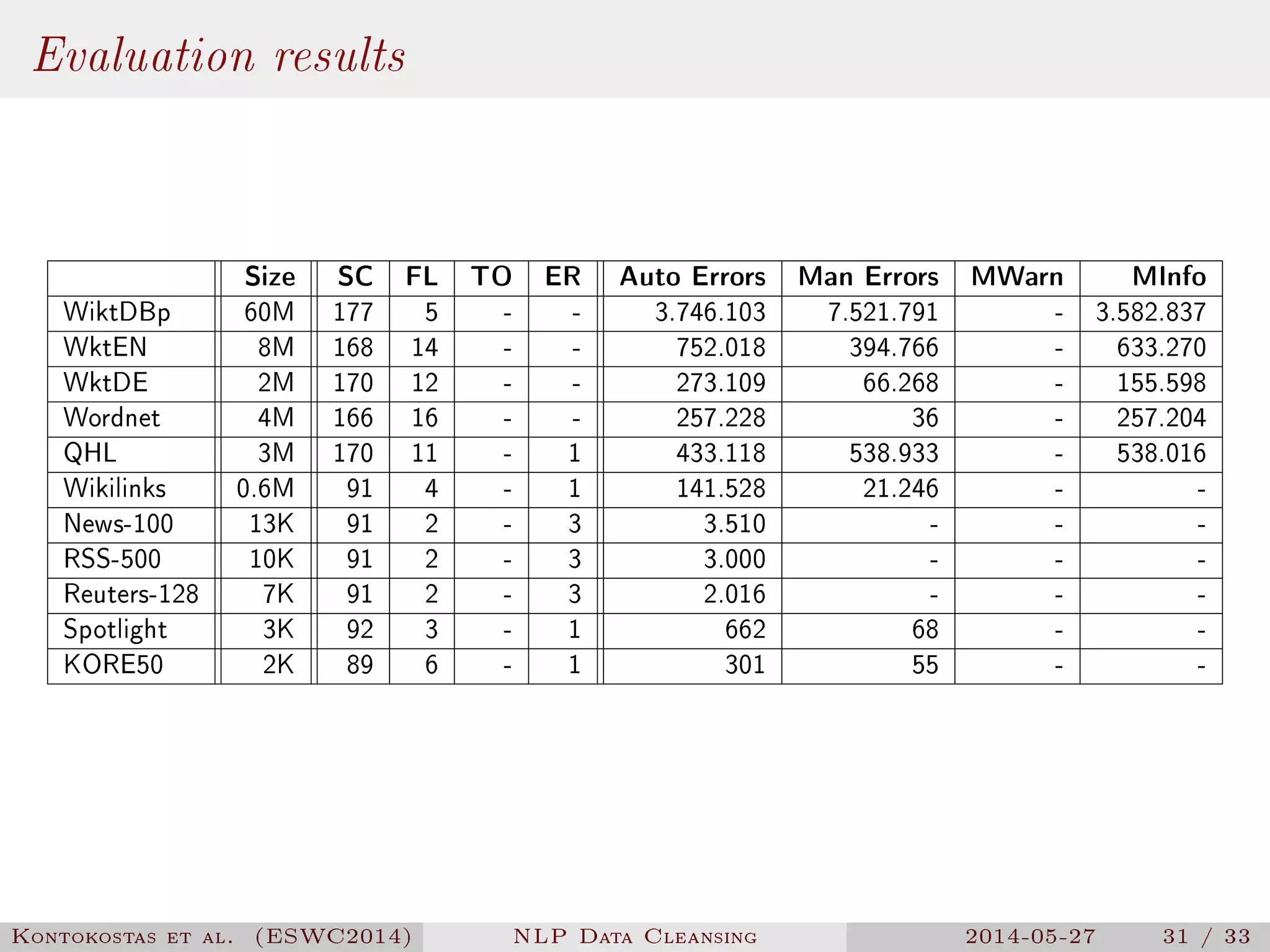



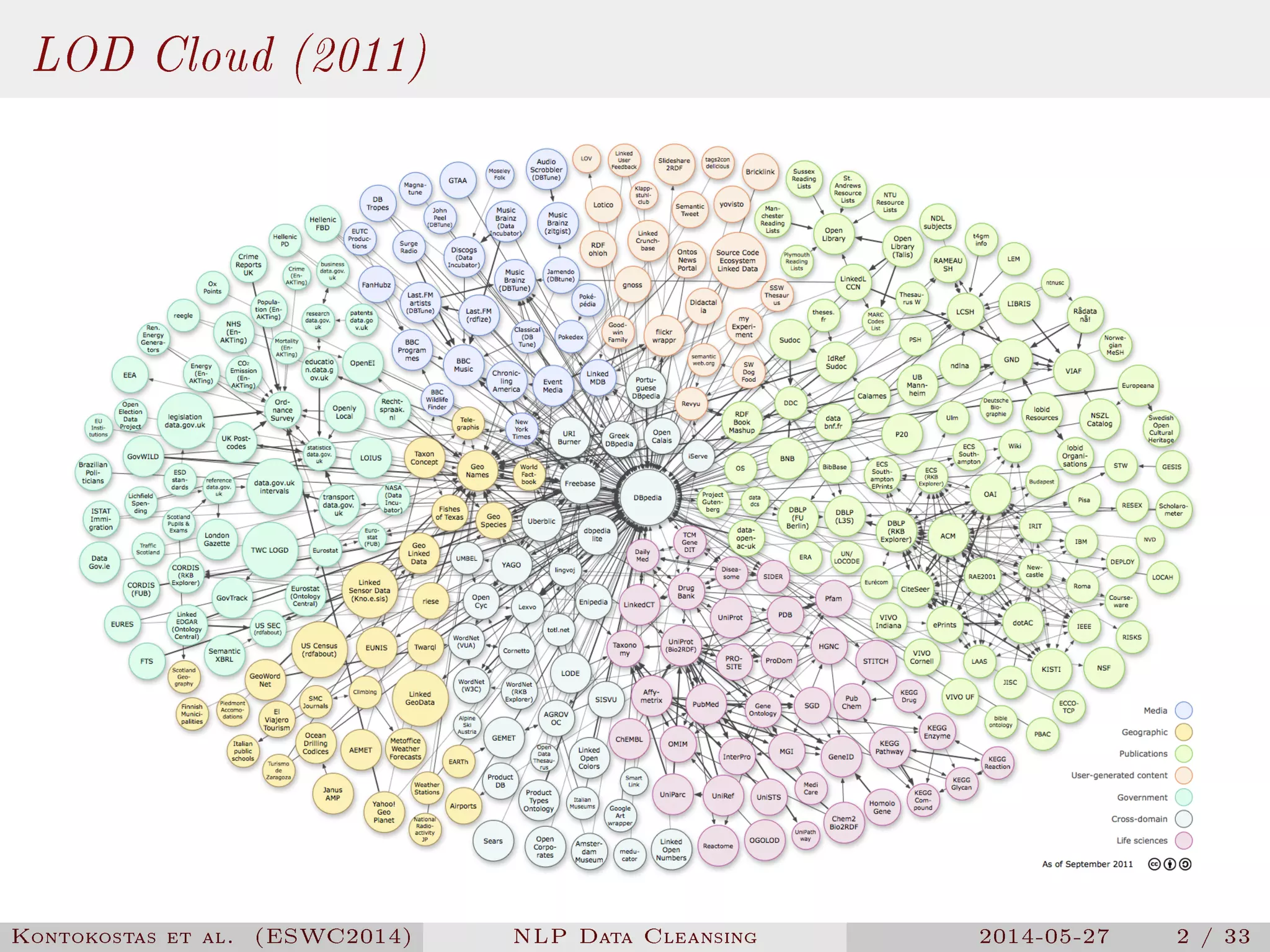
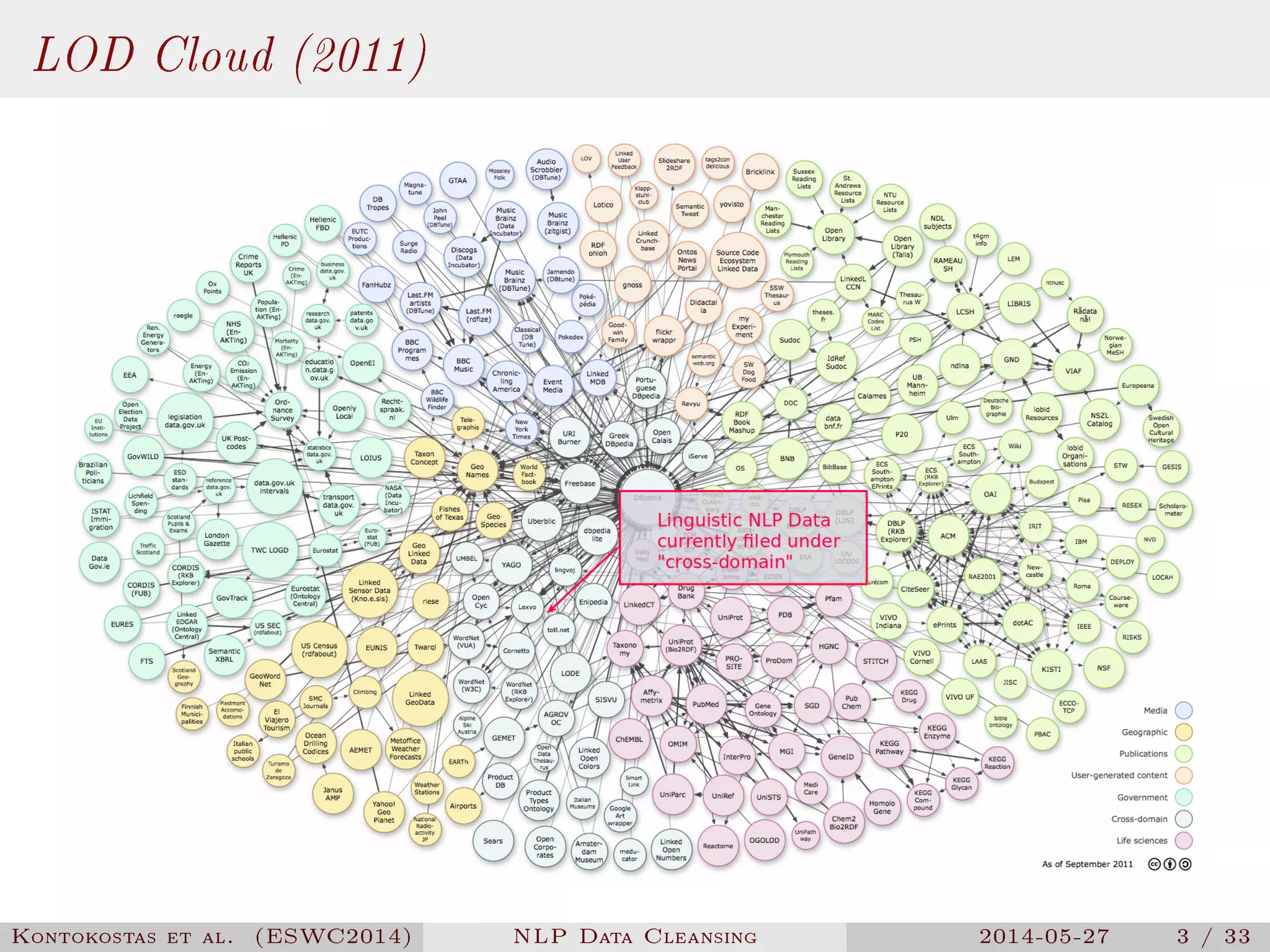
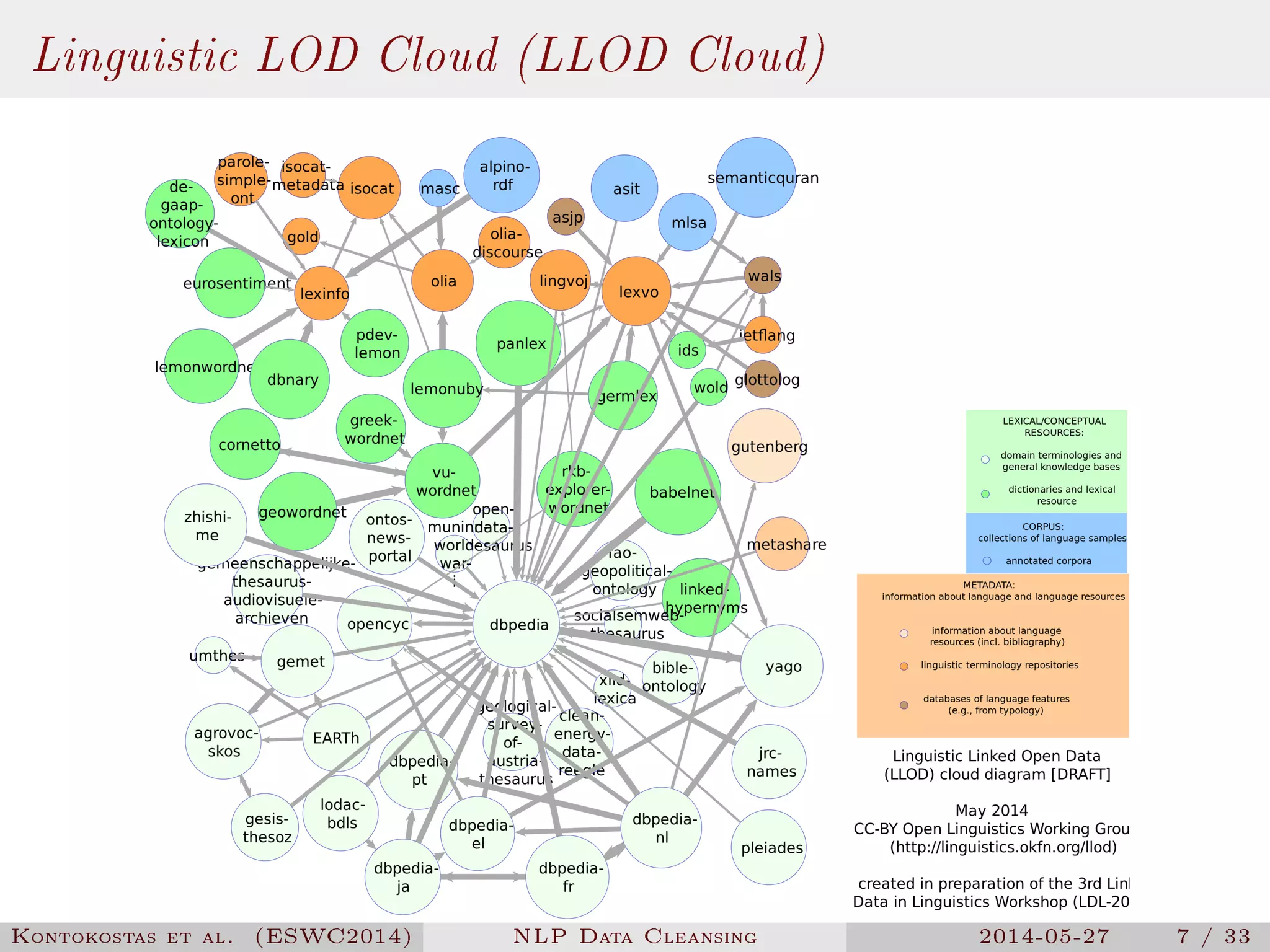
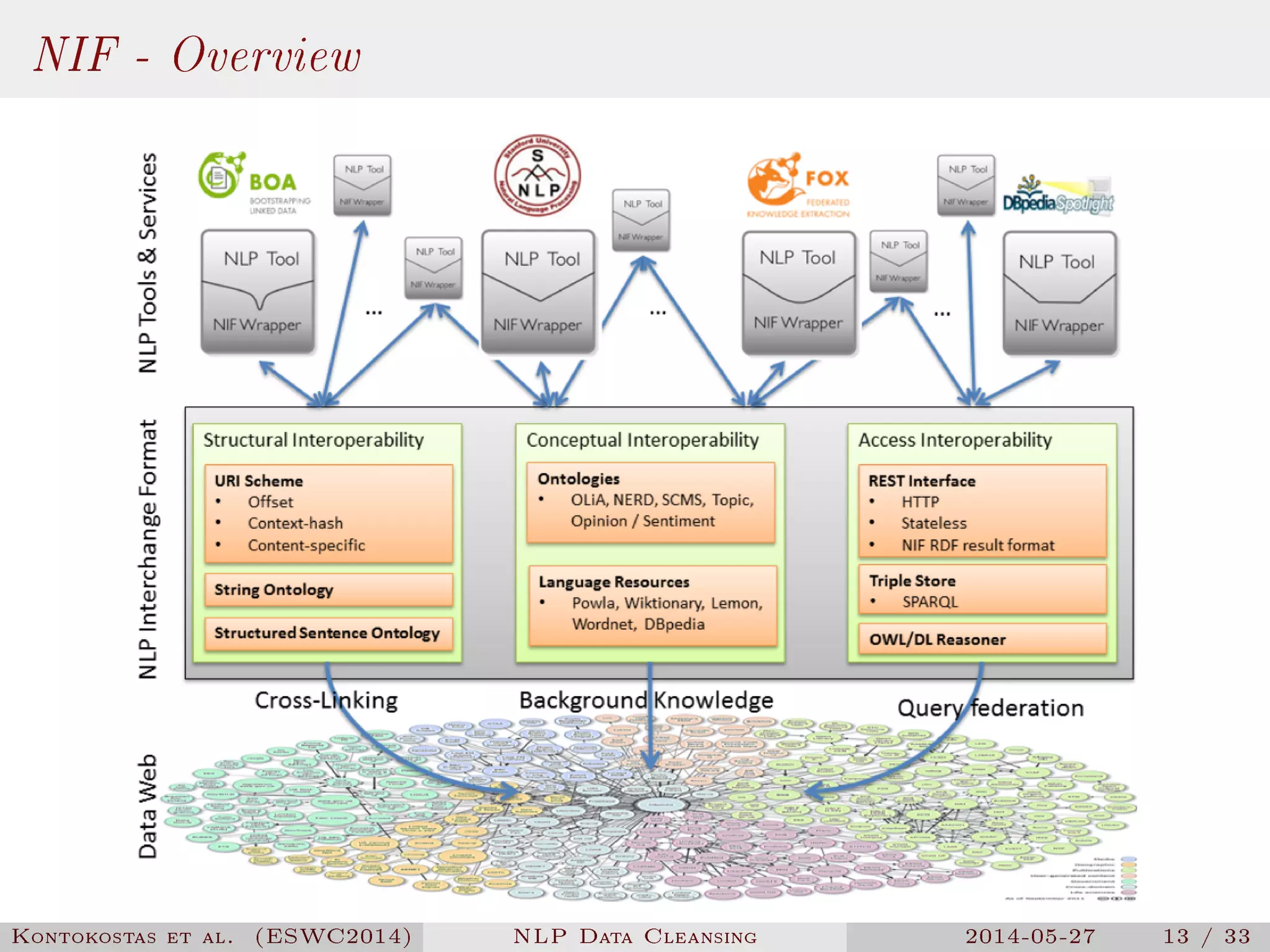
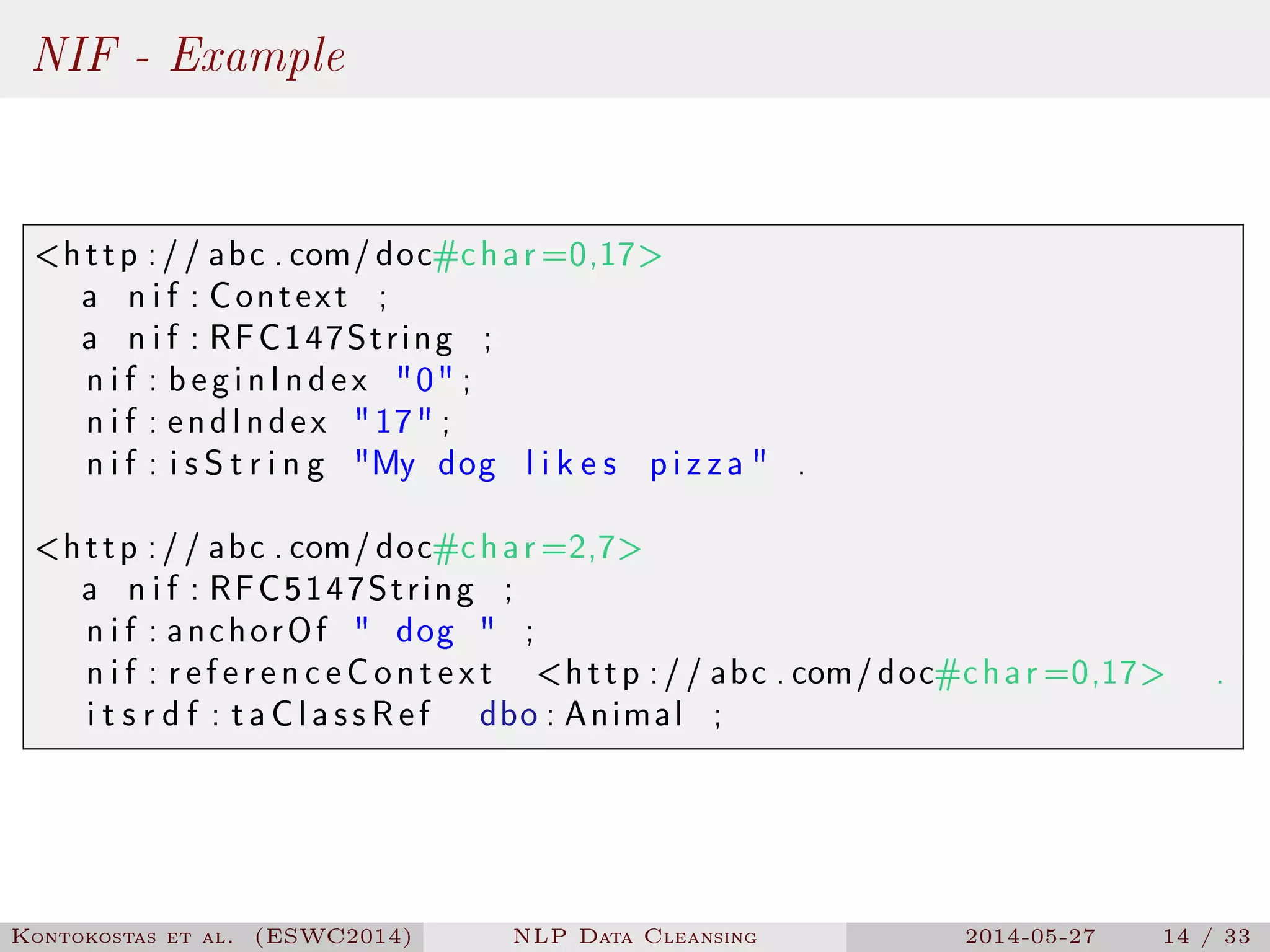
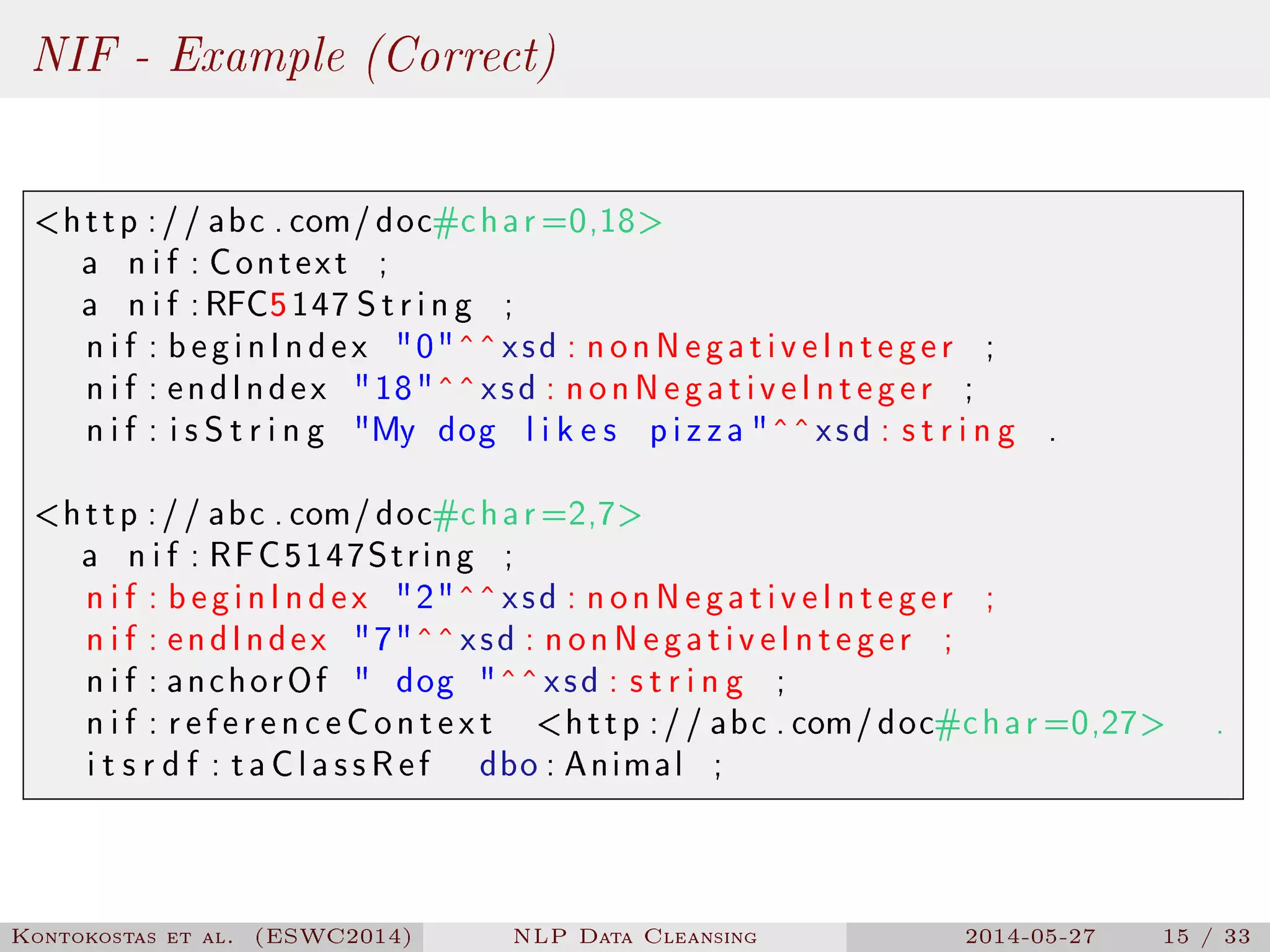
The document presents a methodology for natural language processing (NLP) data cleansing based on linguistic ontology constraints, focusing on two main vocabularies: LEMon and NIF. It highlights the challenges and common errors in existing NLP datasets, proposes a test-driven evaluation approach to enhance data quality, and provides examples of successful test cases. The findings indicate a substantial number of errors in current datasets and suggest future work to extend methodologies to additional NLP ontologies.