Downloaded 43 times








![A template to describe use cases (I)
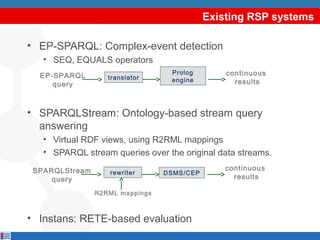
•
Streaming Information
•
•
•
•
•
•
Type: Environmental data: temperatures, pressures, salinity, acidity, fluid
velocities etc,
Nature:
• Relational Stream: yes
• Text stream: no
Origin: Data is produced by sensors in oil wells and on oil and gas
platforms equipments. Each oil platform has an average of 400.000.
Frequency of update:
• from sub-second to minutes
• In triples/minute: [10000-10] t/min
Quality: It varies, due to instrument/sensor issues
Management /access
• Technology in use: Dedicated (relational and proprietary) stores
• Problems: The ability of users to access data from different sources is
limited by an insufficient description of the context
• Means of improvement: Add context (metadata) to the data so it
become meaningful and use reasoning techniques to process that
metadata
<<Texto libre: proyecto, speaker, etc.>>
11](https://image.slidesharecdn.com/20131022ordringkeynote-131030055840-phpapp01/85/OrdRing-2013-keynote-On-the-need-for-a-W3C-community-group-on-RDF-Stream-Processing-11-320.jpg)
![A template to describe use cases (II)
•
[optional] Static Information required to interpret the streaming
information
•
•
•
•
•
Type: Topology of the sensor network, position of each sensor, the
descriptions of the oil platform
Origin: Oil and gas production operations
Dimension:
• 100s of MB as PostGIS dump
• In triples: 10^8
Quality: Good
Management / access
• Technology in use: RDBMS, proprietary technologies
• Available Ontologies and Vocabularies: Reference Semantic Model
(RSM), based on ISO 15926
<<Texto libre: proyecto, speaker, etc.>>
12](https://image.slidesharecdn.com/20131022ordringkeynote-131030055840-phpapp01/85/OrdRing-2013-keynote-On-the-need-for-a-W3C-community-group-on-RDF-Stream-Processing-12-320.jpg)







![Output: relation
• Case 1: the output is a set of timestamped mappings
a … ?b… [t1]
a … ?b…
SELECT ?a ?b …
FROM ….
WHERE ….
queries
CONSTRUCT {?a :prop ?b }
FROM ….
WHERE ….
a … ?b… [t3]
a … ?b… [t5]
RS
P
a … ?b… [t7]
bindings
<… :prop … > [t1]
<… :prop … >
<… :prop … > [t3]
<… :prop … > [t5]
<… :prop … > [t7]
triples](https://image.slidesharecdn.com/20131022ordringkeynote-131030055840-phpapp01/85/OrdRing-2013-keynote-On-the-need-for-a-W3C-community-group-on-RDF-Stream-Processing-24-320.jpg)
![Output: stream
• Case 2: the output is a stream
• R2S operators
CONSTRUCT RSTREAM {?a :prop ?b }
FROM ….
WHERE ….
query
RS
P
stream
…
<… :prop … > [t1]
<… :prop … > [t1]
<… :prop … > [t3]
<… :prop … > [t5]
< …:prop … > [t7]
…
ISTREAM: stream out data in the last step that wasn’t on the previous step
DSTREAM: stream out data in the previous step that isn’t in the last step
RSTREAM: stream out all data in the last step](https://image.slidesharecdn.com/20131022ordringkeynote-131030055840-phpapp01/85/OrdRing-2013-keynote-On-the-need-for-a-W3C-community-group-on-RDF-Stream-Processing-25-320.jpg)


![Operational Semantics
Where are both alice and bob in the last 5s?
hall
:hall
sIn :
:i
isIn
e
:
:alic
:bob
S
e
:alic
hen
:kitc
:isIn
S1
S2
S3
S4
1
3
6
:bob
hen
:kitc
:isIn
9
System 1:
System 2:
:hall [5]
:hall [3]
t
:kitchen [10]
:kitchen [9]
Both correct?
ISWC 2013 evaluation track for "On Correctness in RDF stream
processor benchmarking" by Daniele Dell’Aglio, Jean-Paul
Calbimonte, Marco Balduini, Oscar Corcho and Emanuele Della Valle](https://image.slidesharecdn.com/20131022ordringkeynote-131030055840-phpapp01/85/OrdRing-2013-keynote-On-the-need-for-a-W3C-community-group-on-RDF-Stream-Processing-31-320.jpg)



The document discusses the necessity of establishing a W3C community group focused on RDF stream processing, addressing the heterogeneity in RDF stream models, query languages, and implementation approaches. It highlights the mission of the group to create a unified framework for producing, transmitting, and continuously querying RDF streams while accommodating the dynamic nature of graph-based data. Additionally, the document outlines the importance of collaboration and input from the community in defining use cases and enhancing semantic stream processing capabilities.























































































