
















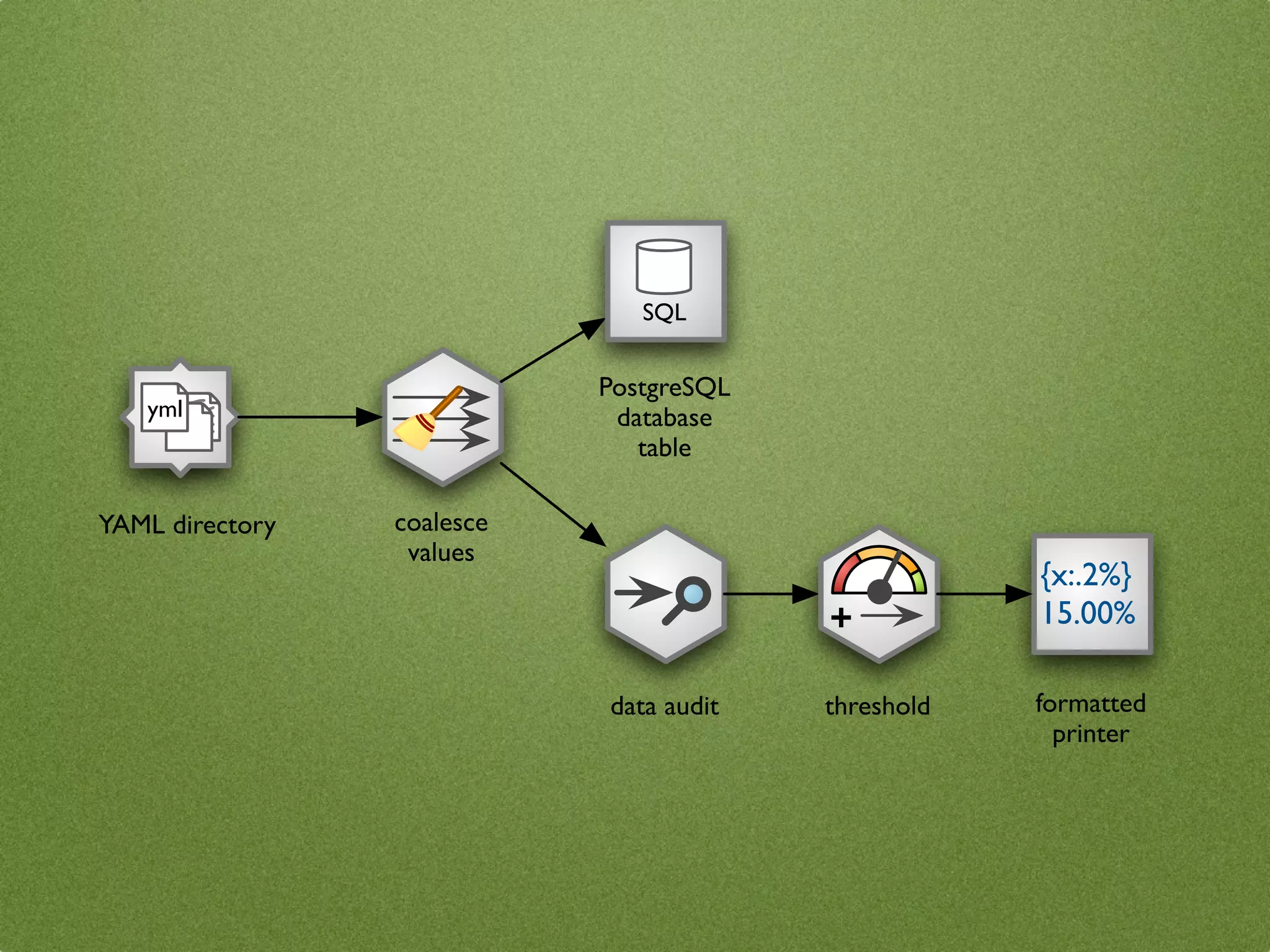

























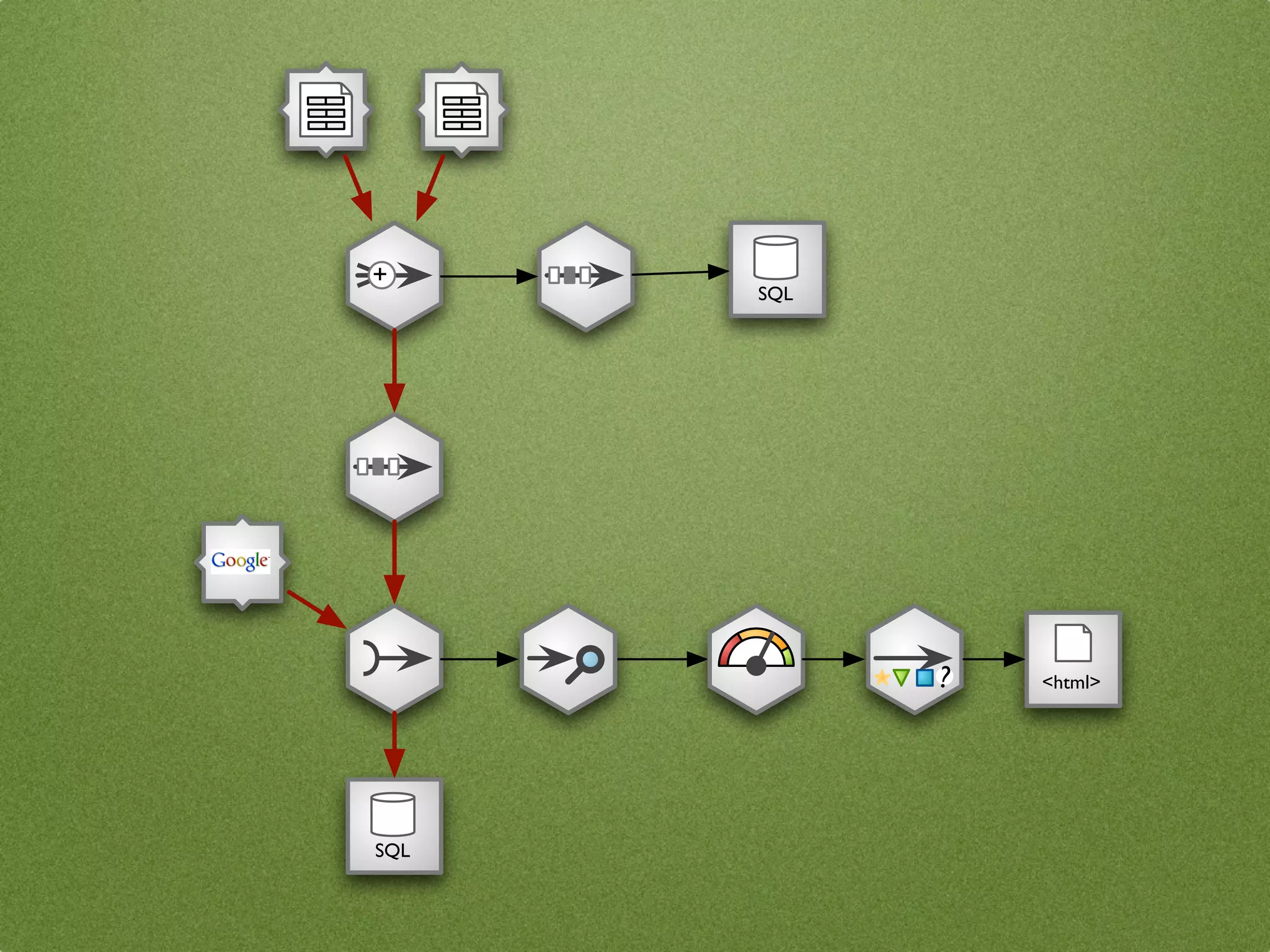
![yml nodes = {
"source": CSVSourceNode(...),
"clean": CoalesceValueToTypeNode(),
"output": DatabaseTableTargetNode(...),
"audit": AuditNode(...),
"threshold": ValueThresholdNode(),
"print": FormattedPrinterNode()
}
connections = [
("source", "clean"),
("clean", "output"),
SQL
("clean", "audit"),
("audit", "threshold"),
("threshold", "print")
]
+ ... # configure nodes here
stream = Stream(nodes, connections)
stream.initialize()
{x:.2%} stream.run()
15.00%](https://image.slidesharecdn.com/datacleansing-110403132829-phpapp02/75/Data-Cleansing-introduction-for-BigClean-Prague-2011-64-2048.jpg)

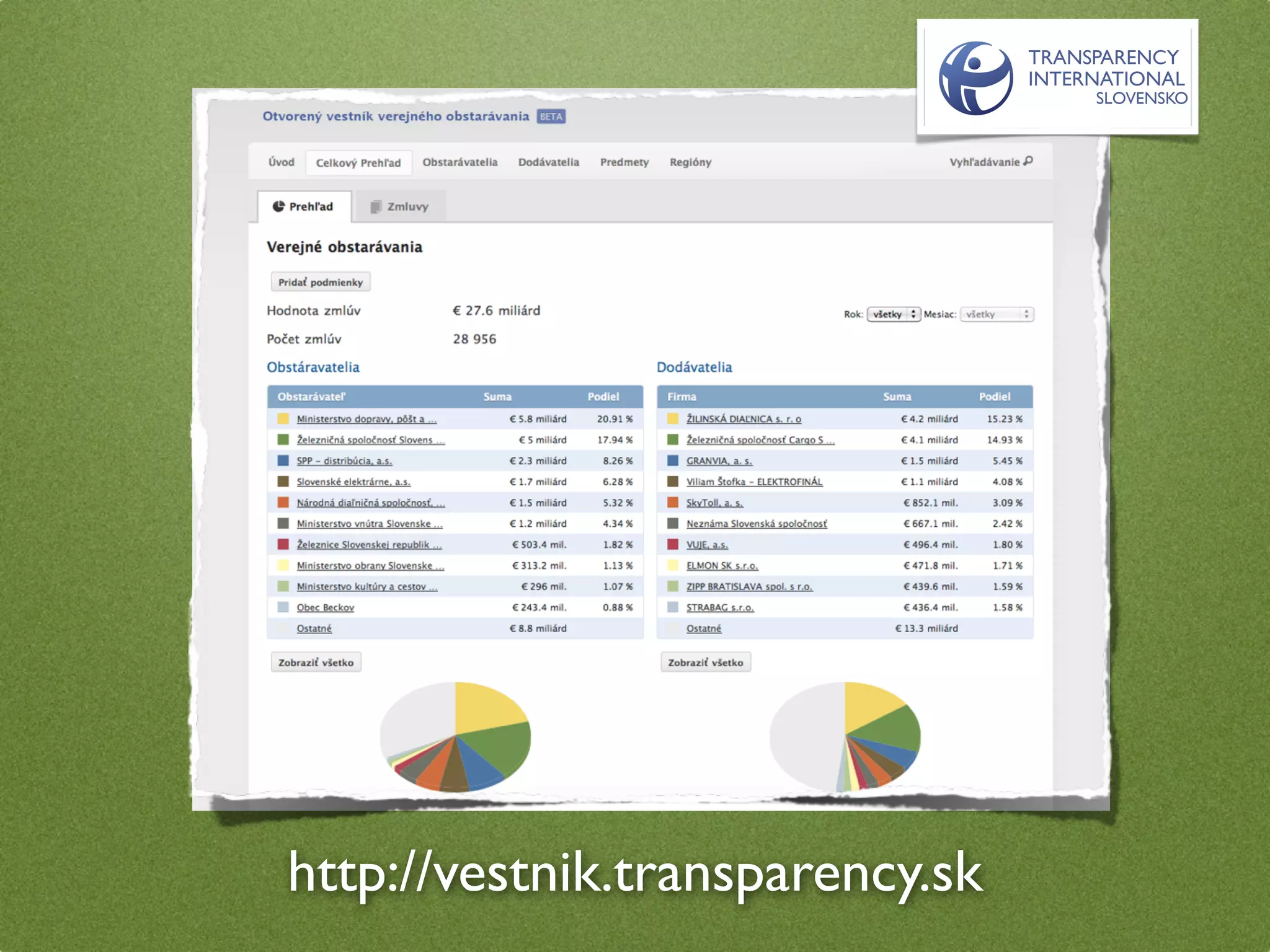
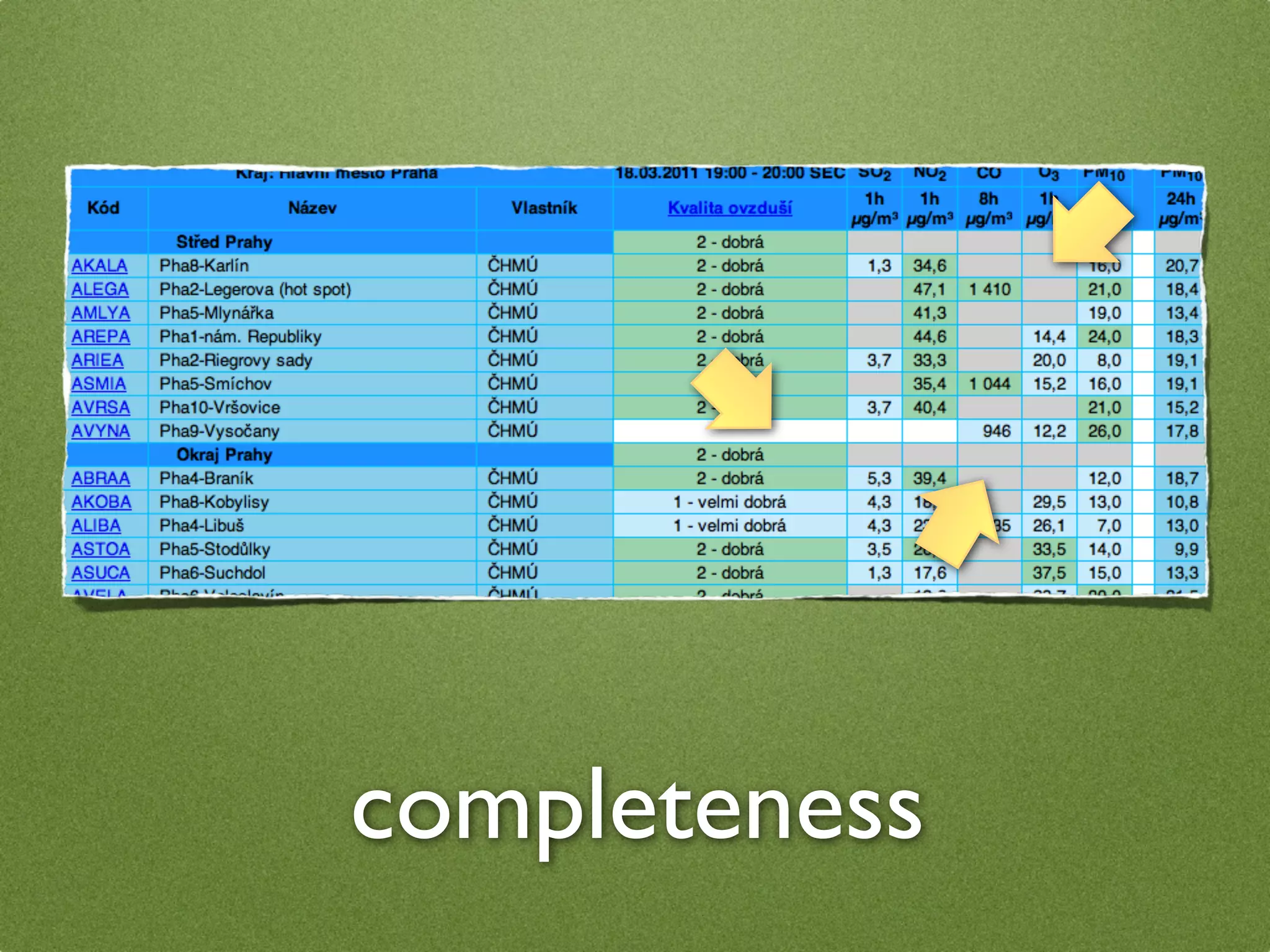
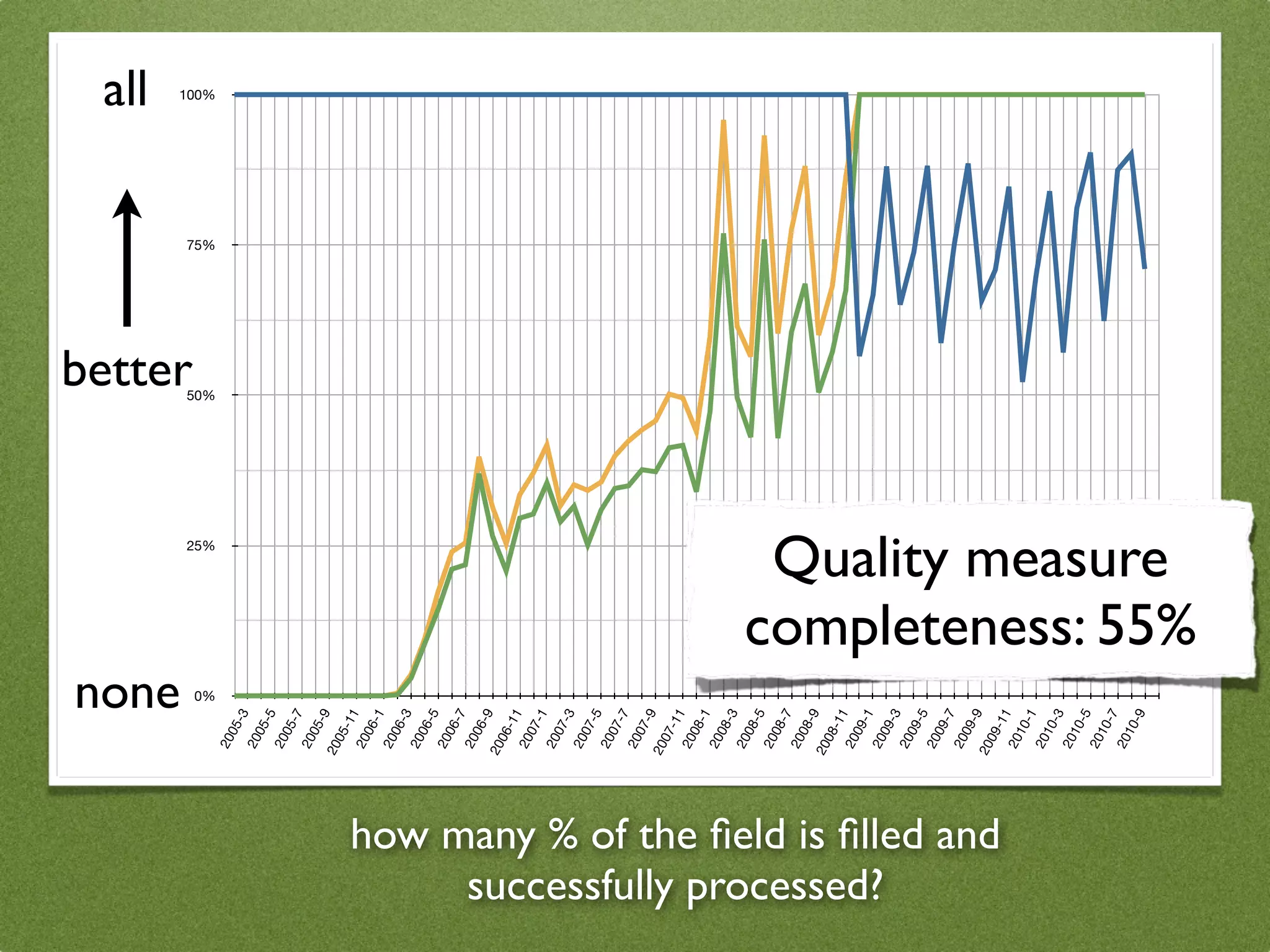
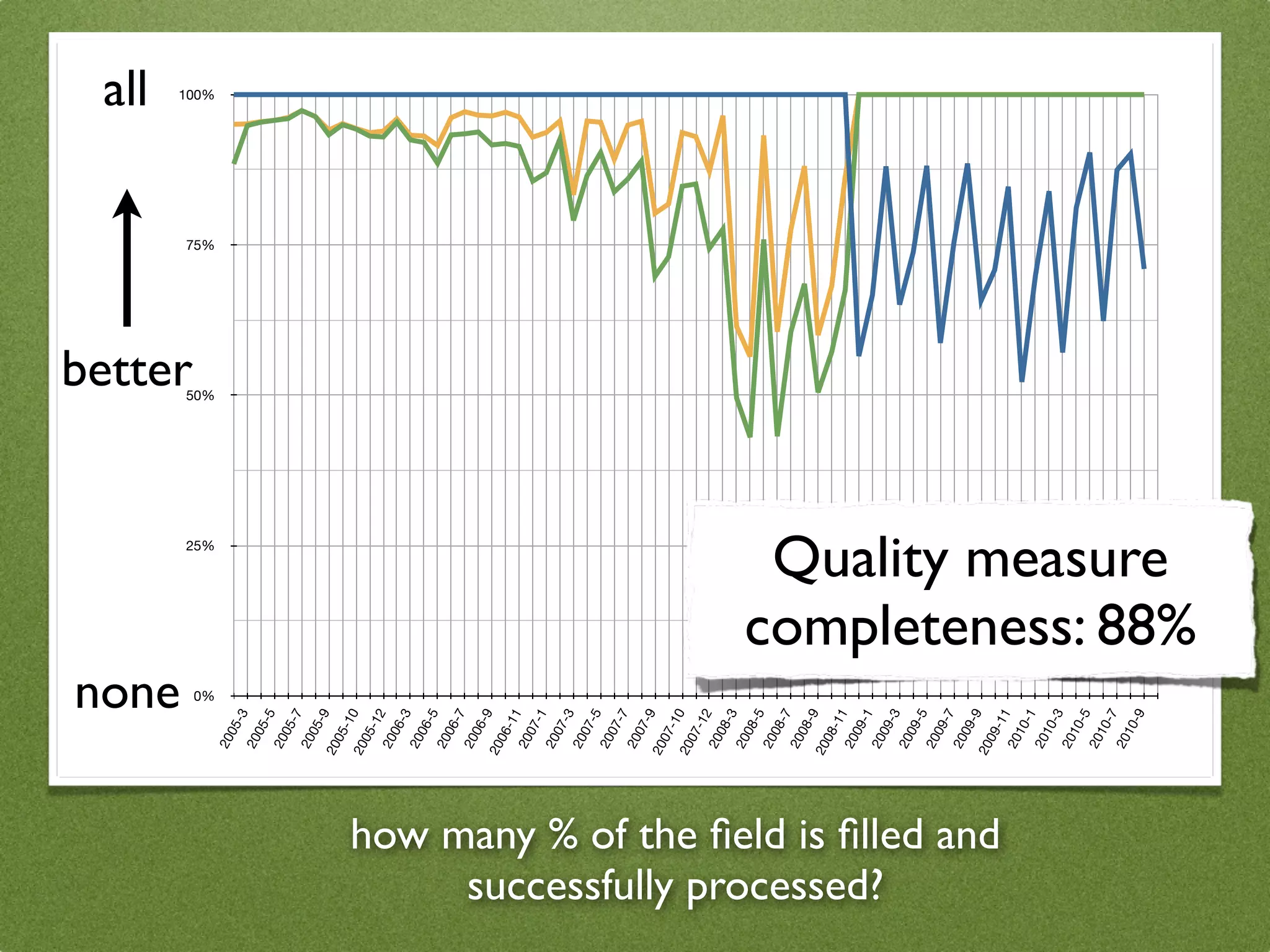
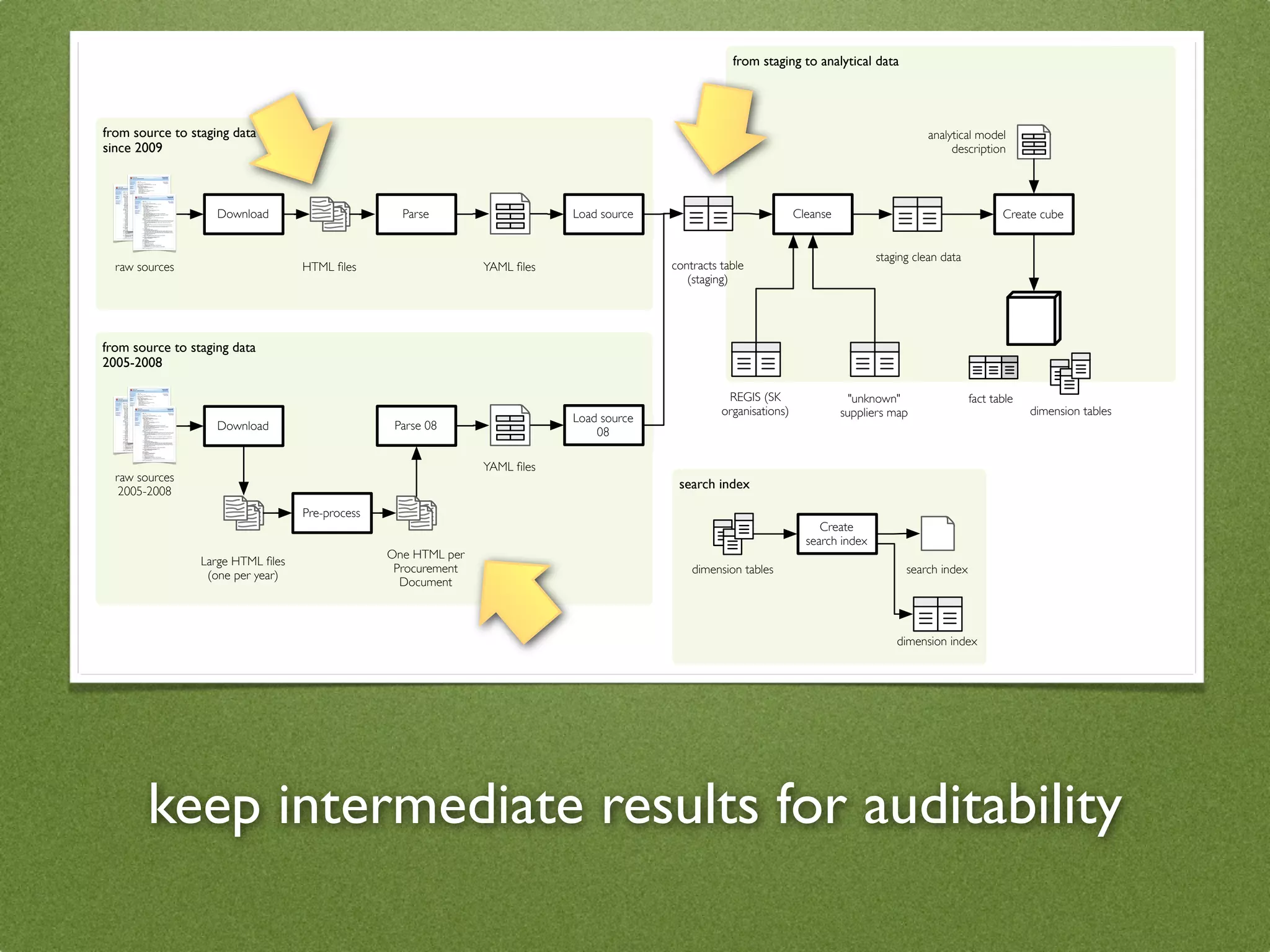
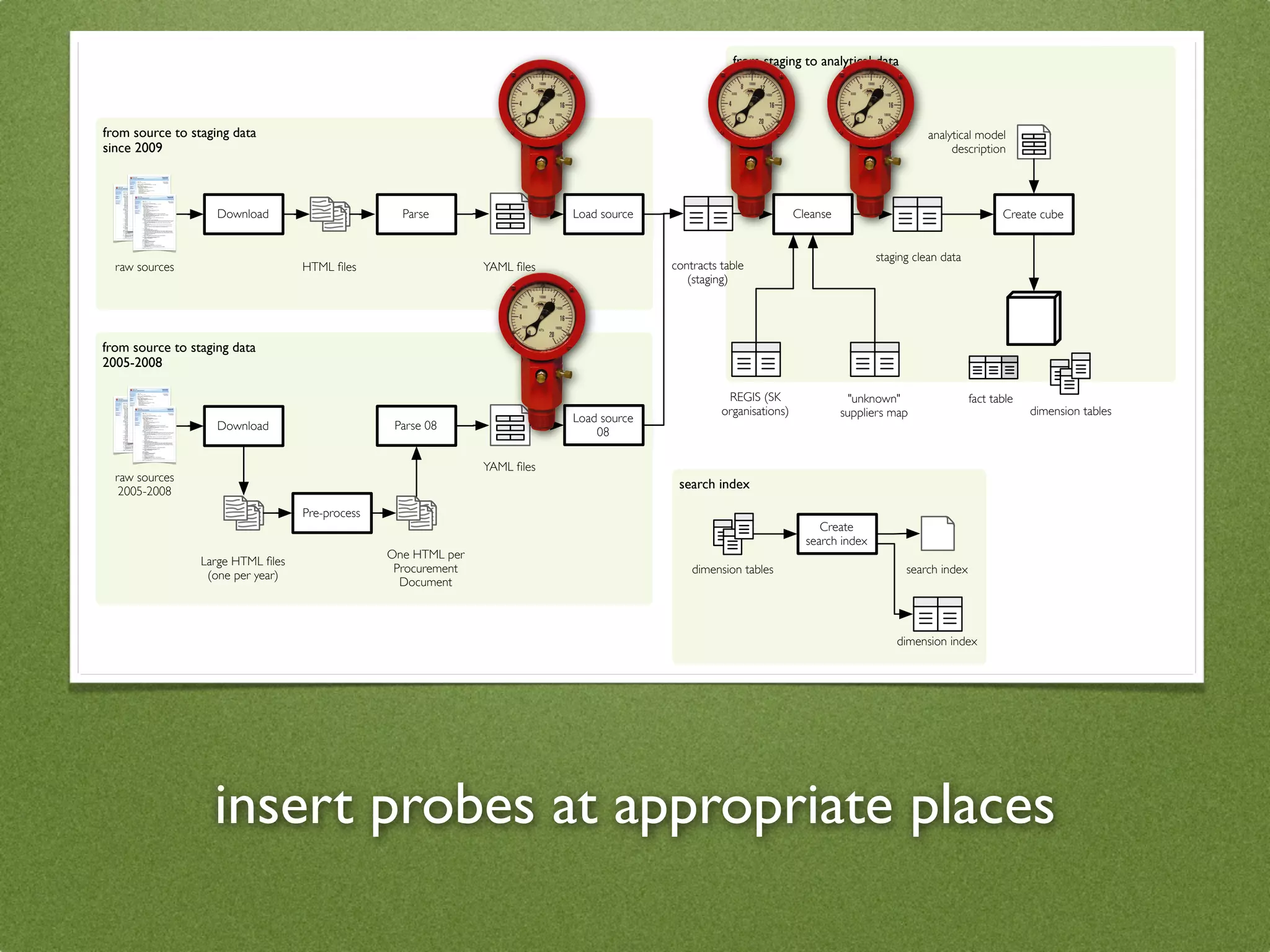
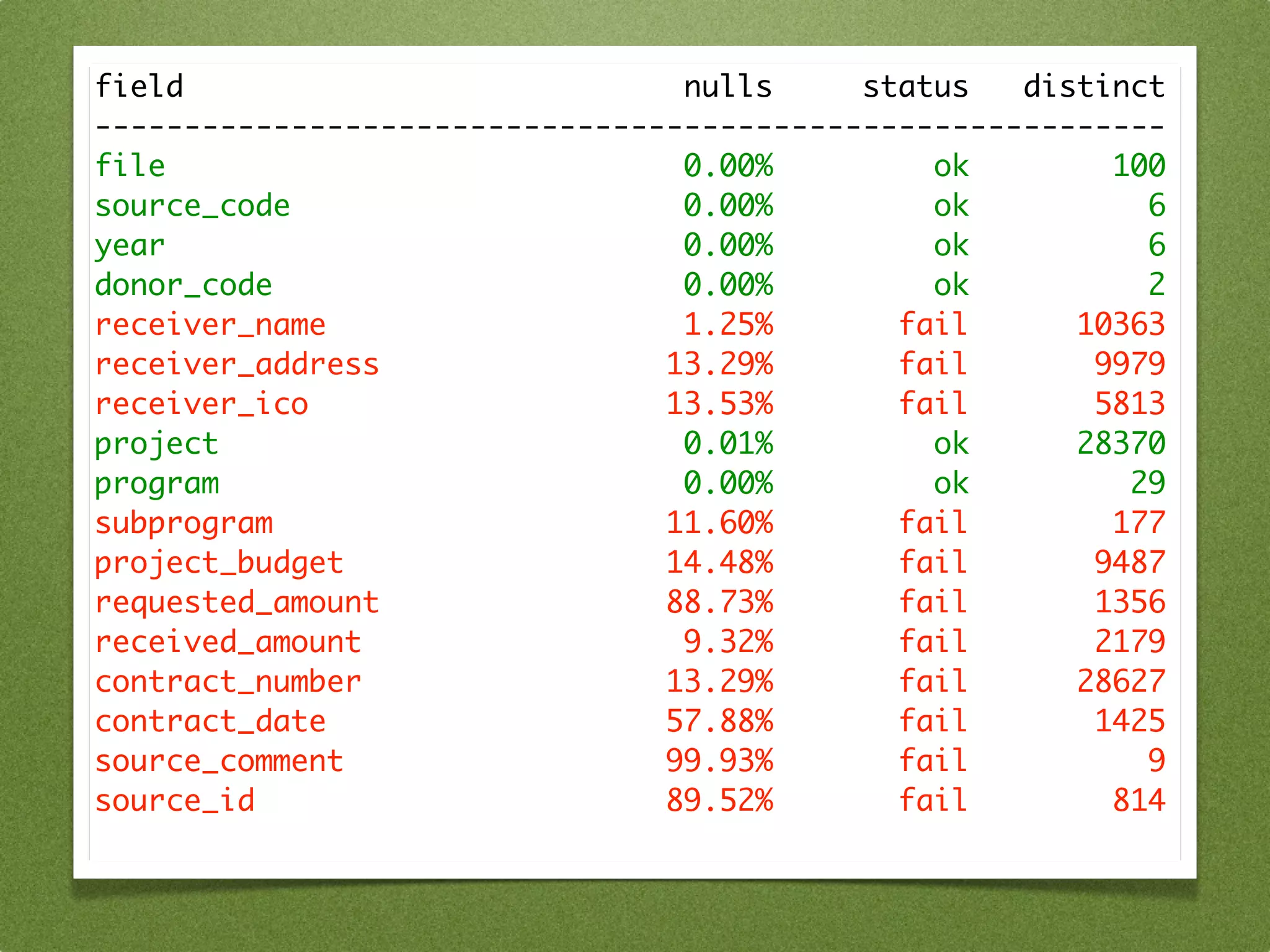
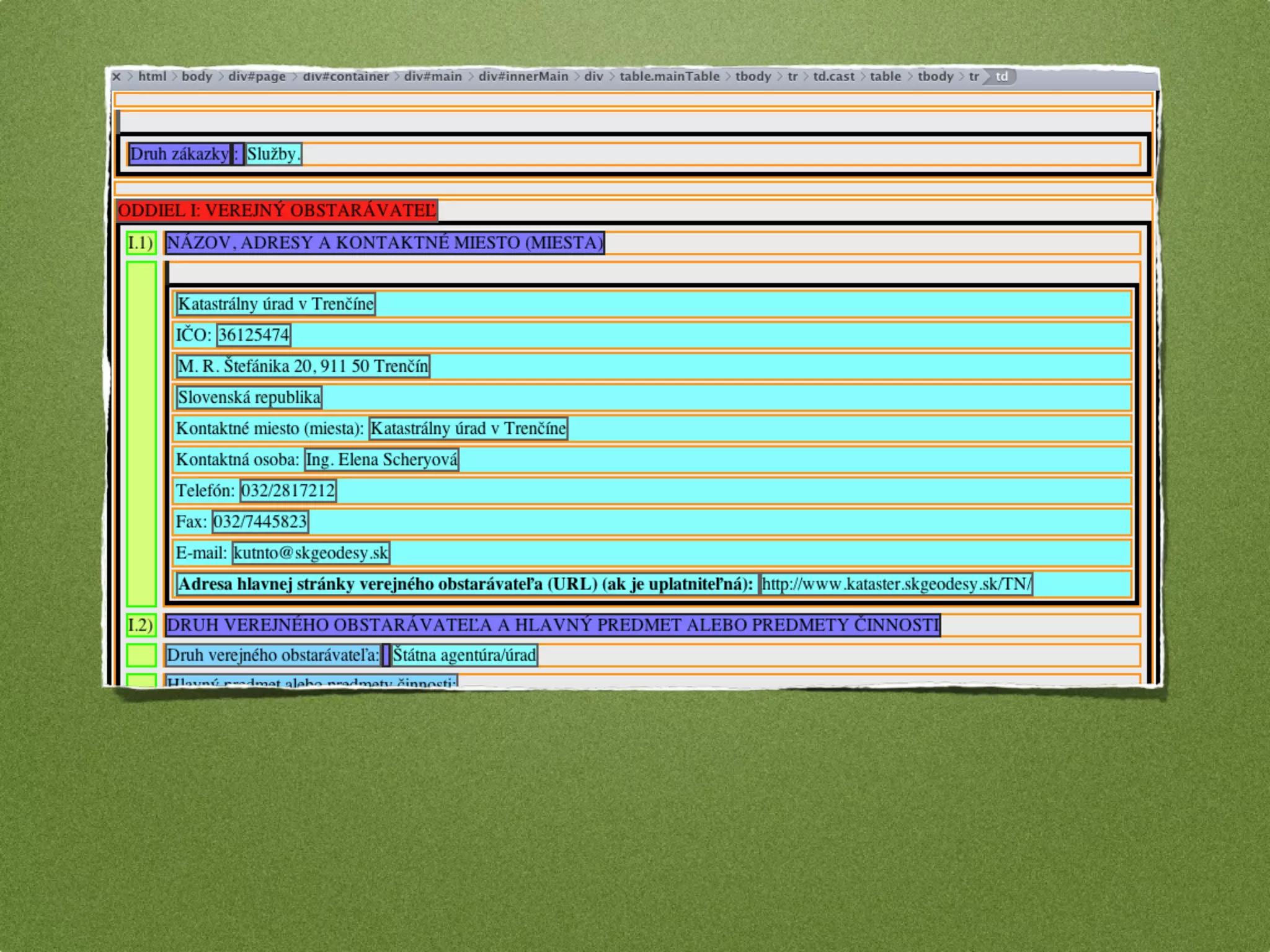
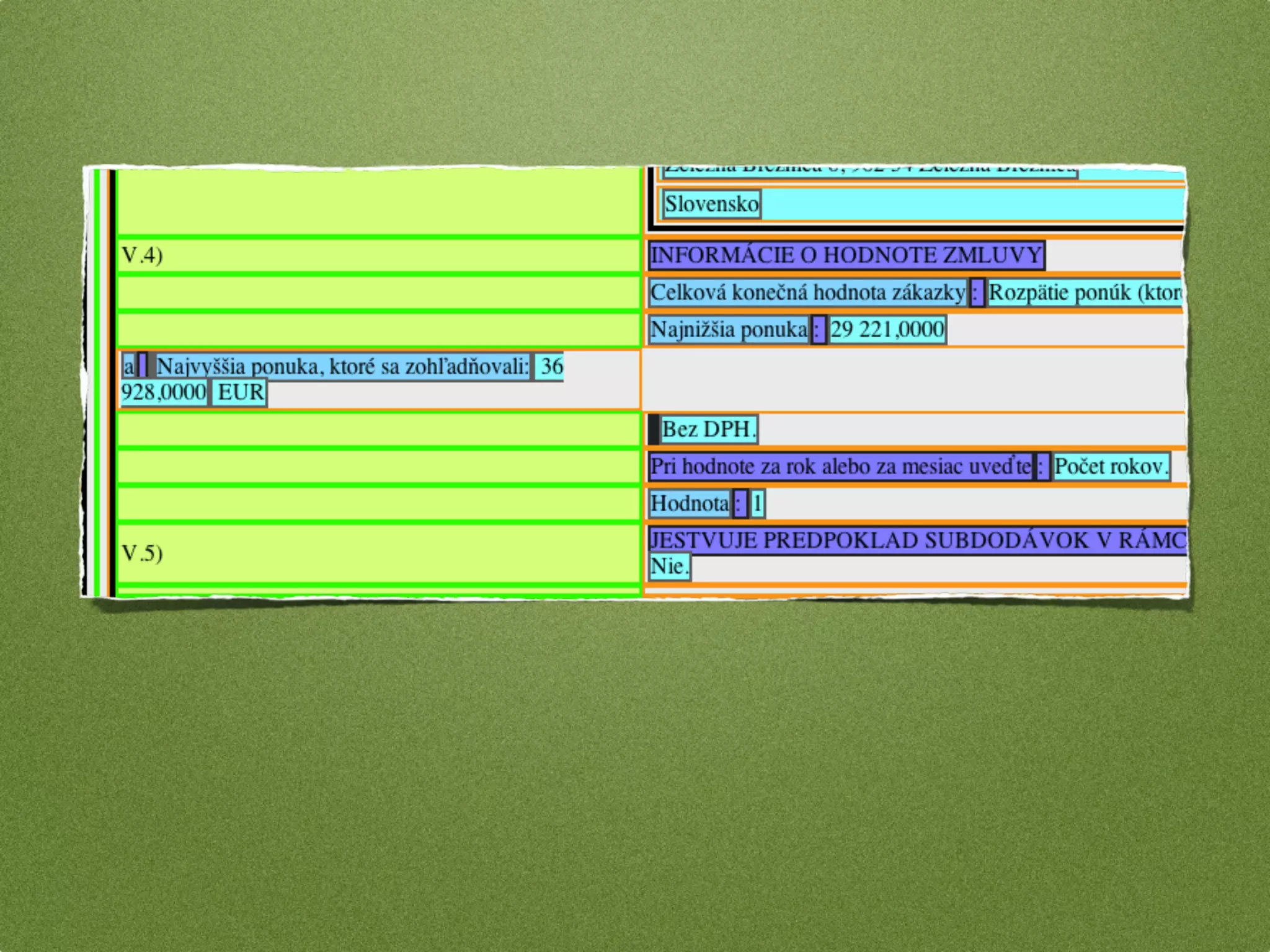
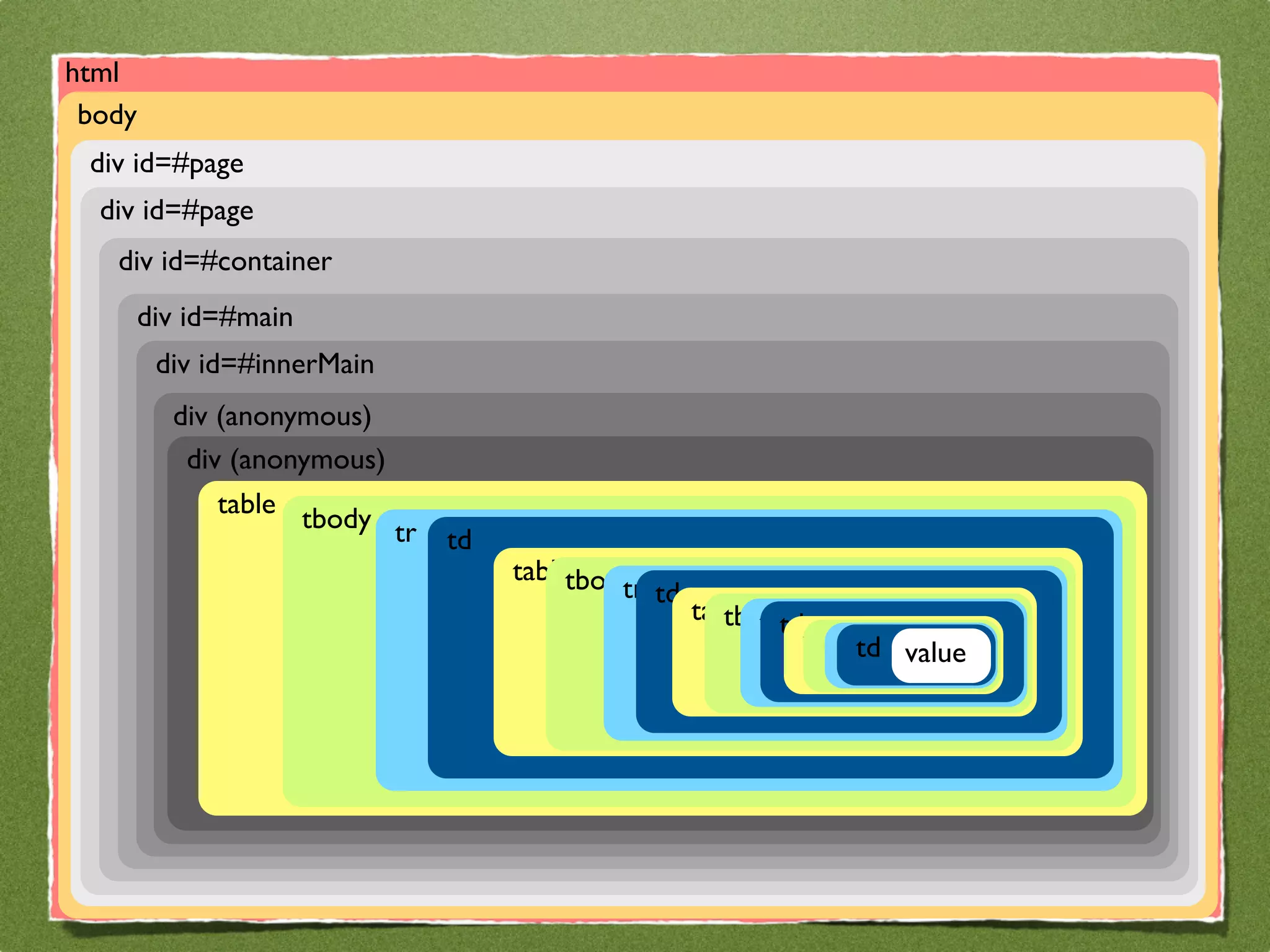
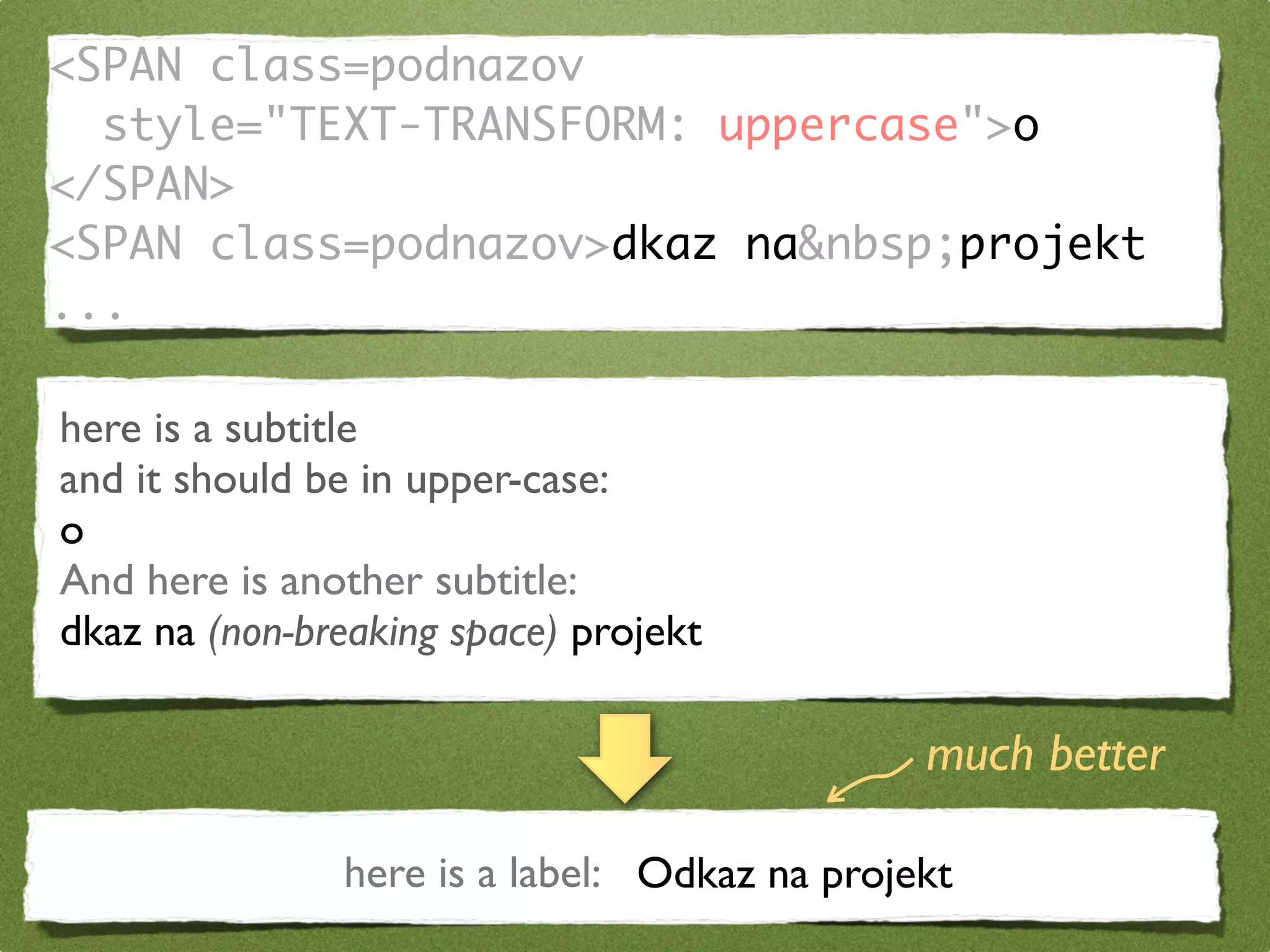
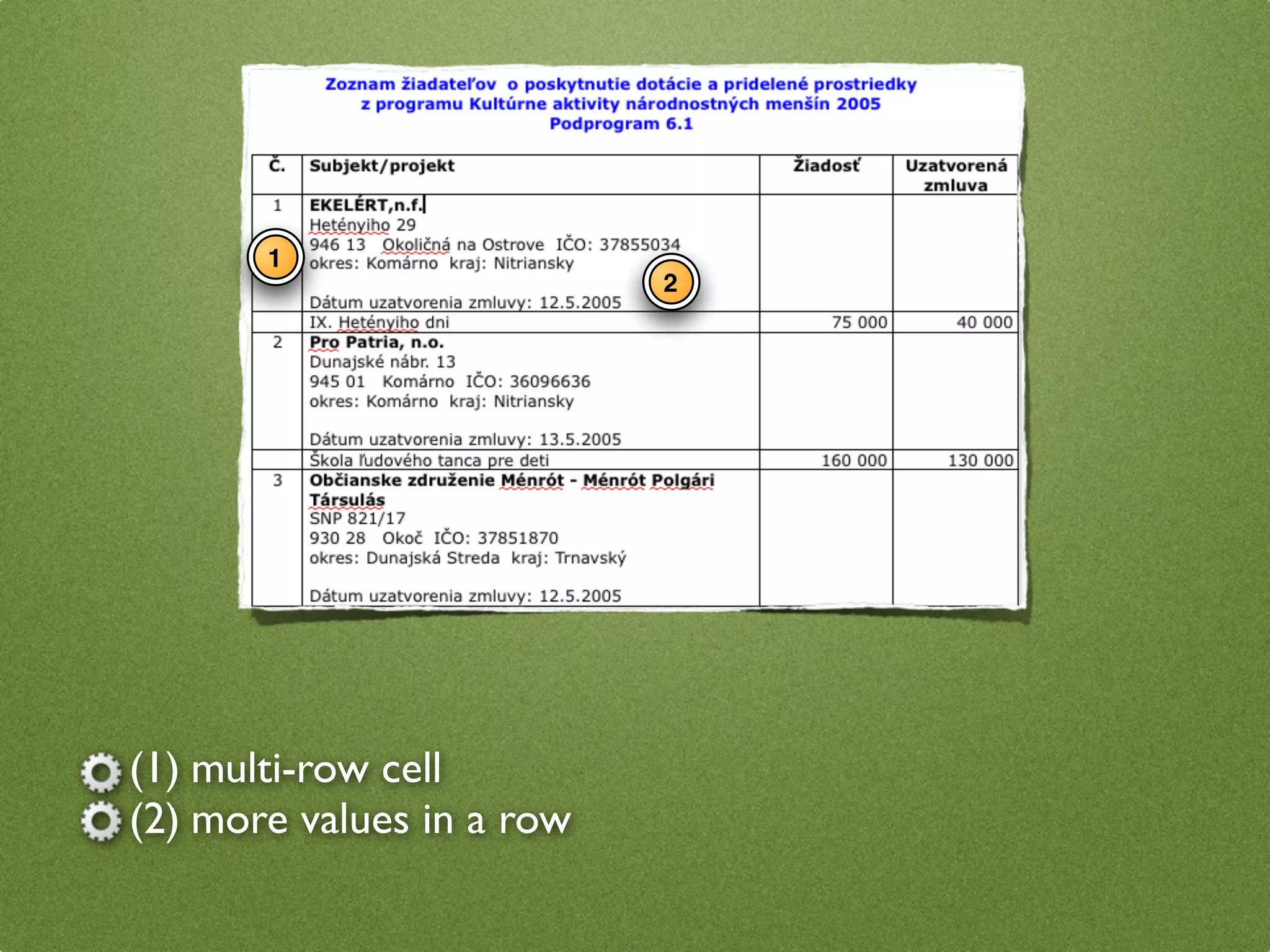
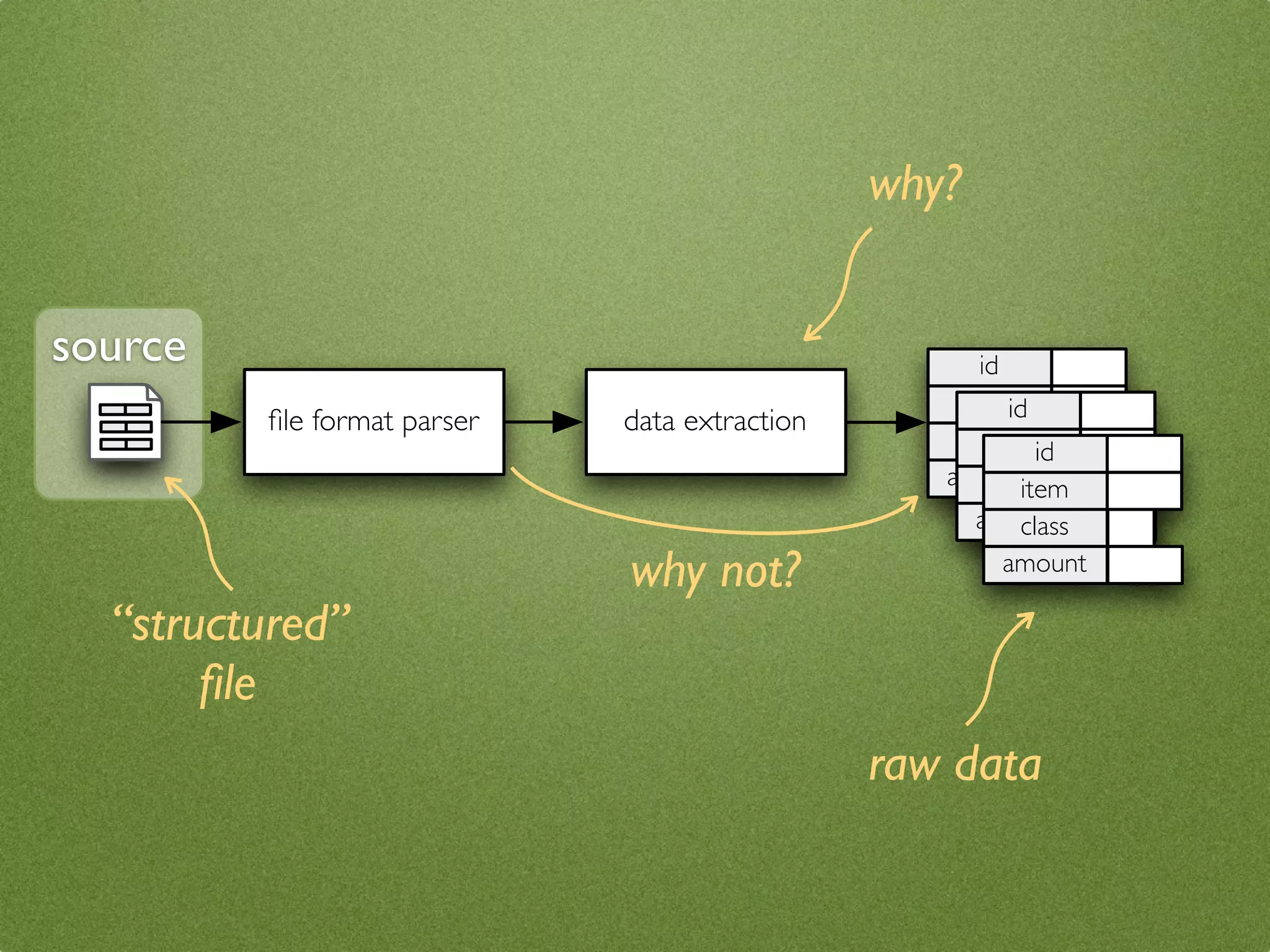
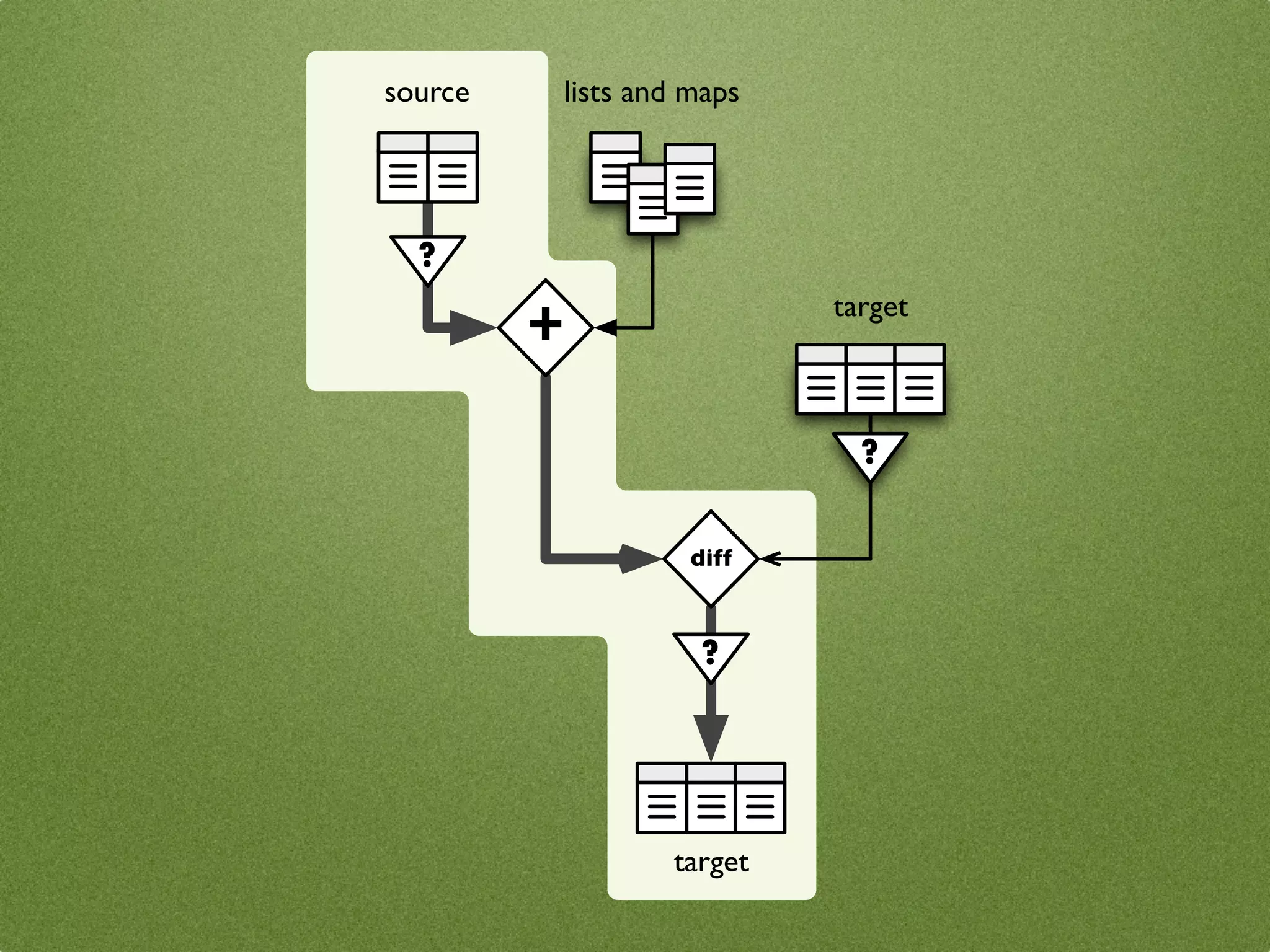
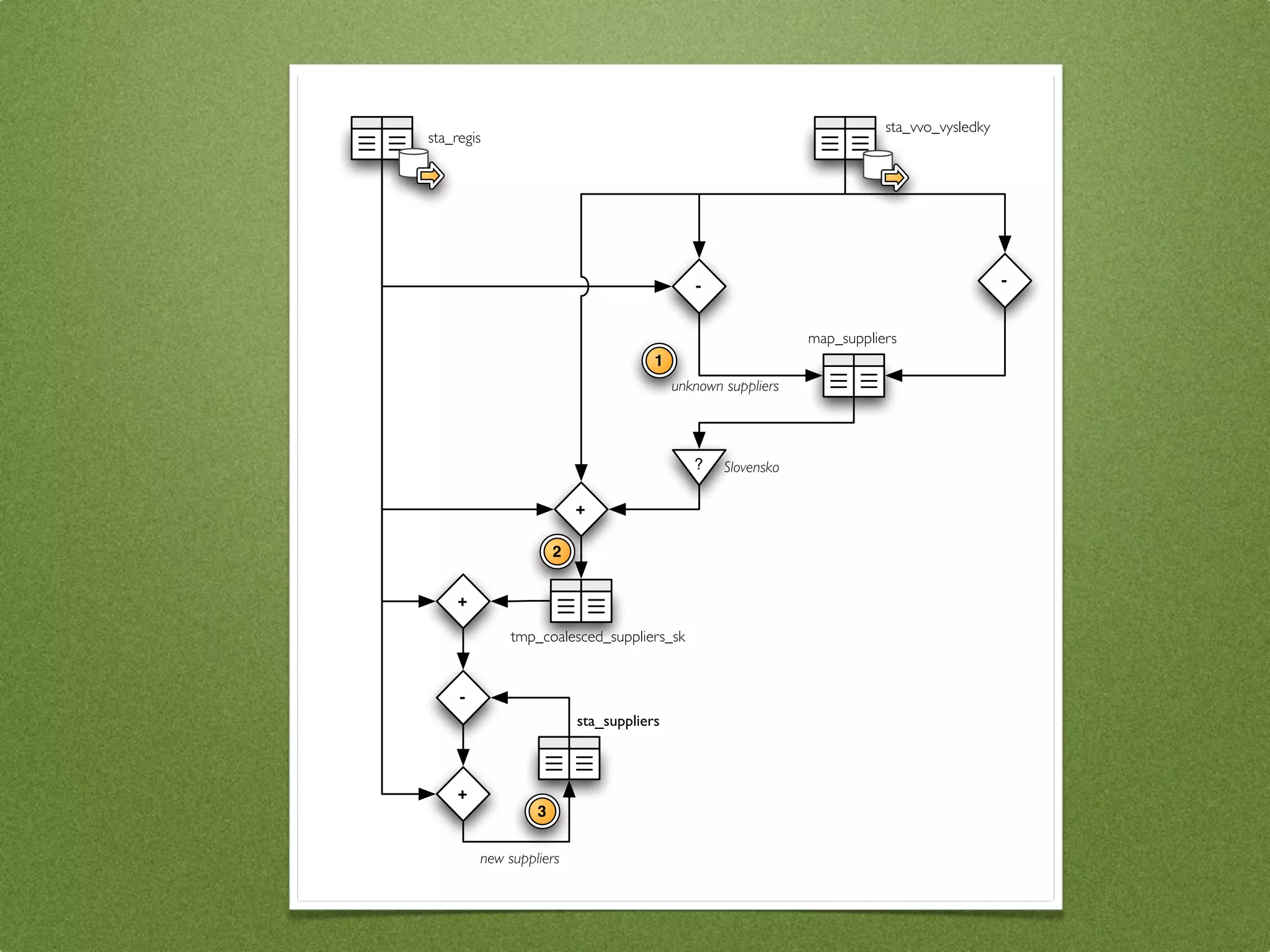
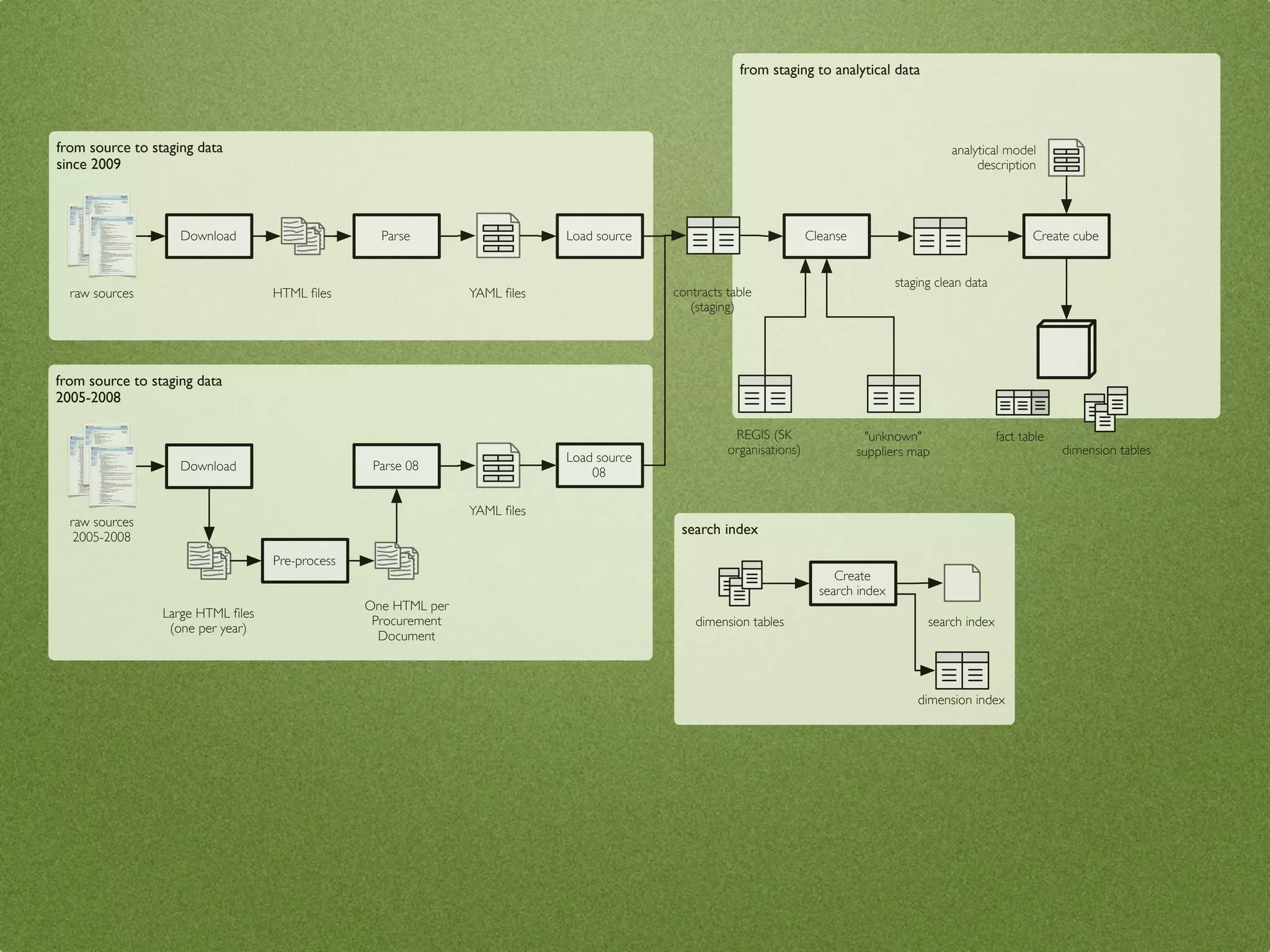
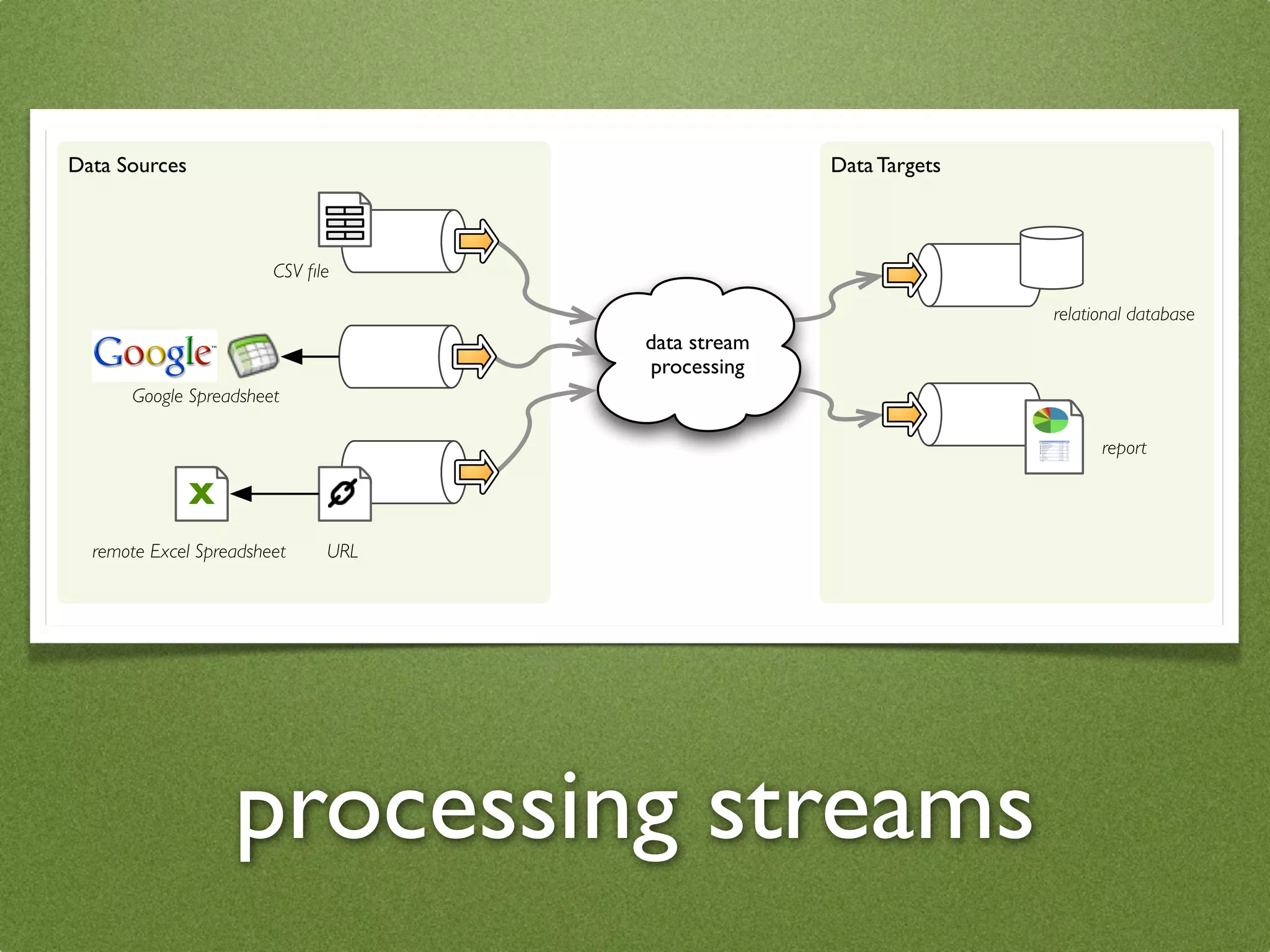
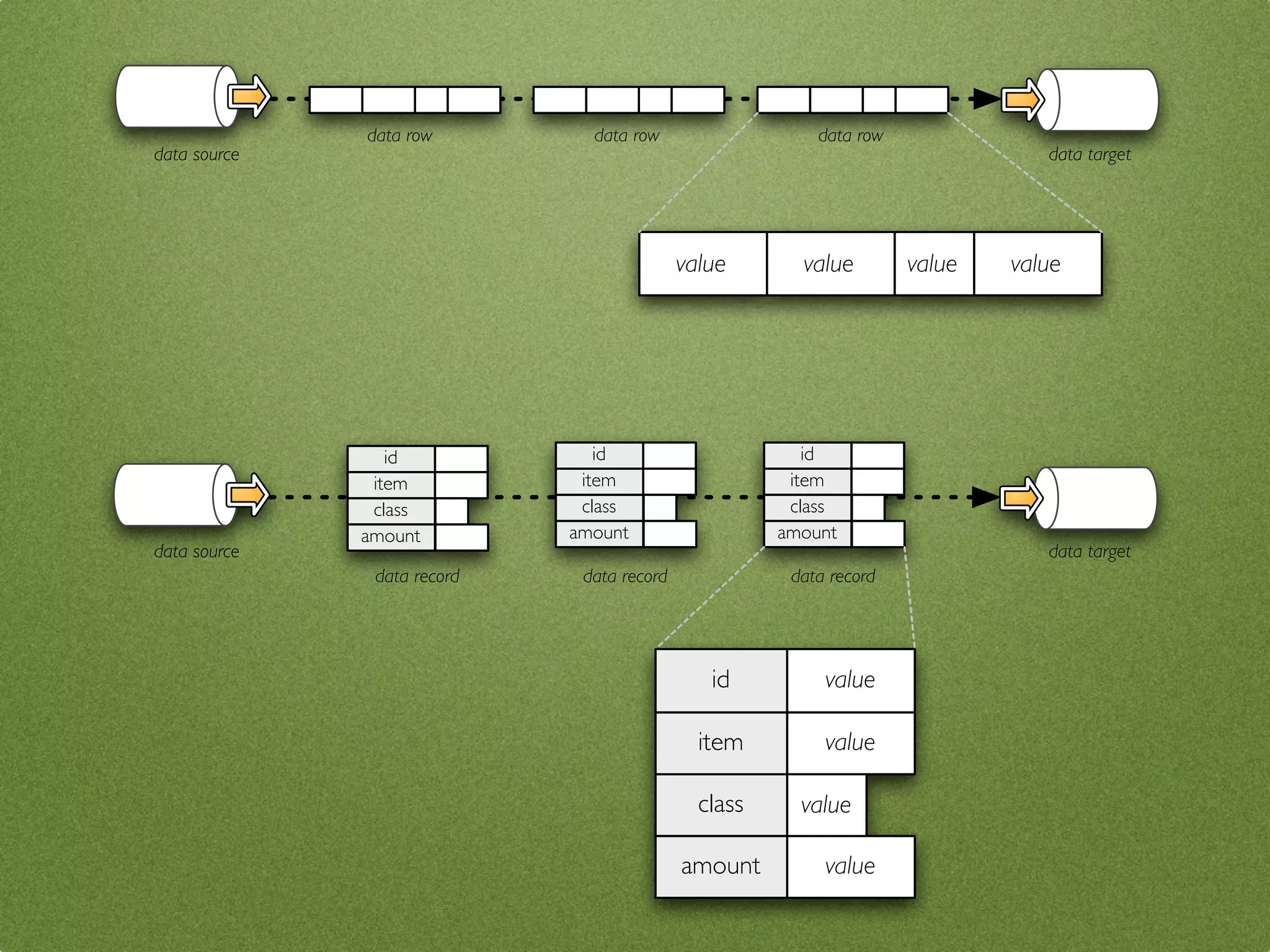
The document by Stefan Urbanek discusses data quality, defining dimensions such as completeness, accuracy, credibility, timeliness, consistency, and integrity. It highlights the importance of measuring data quality throughout the data lifecycle, including extraction, transformation, and loading (ETL) processes. Additionally, it presents methods for data cleansing and the use of structured data formats to improve data processing and reporting strengths.























































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)












![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)