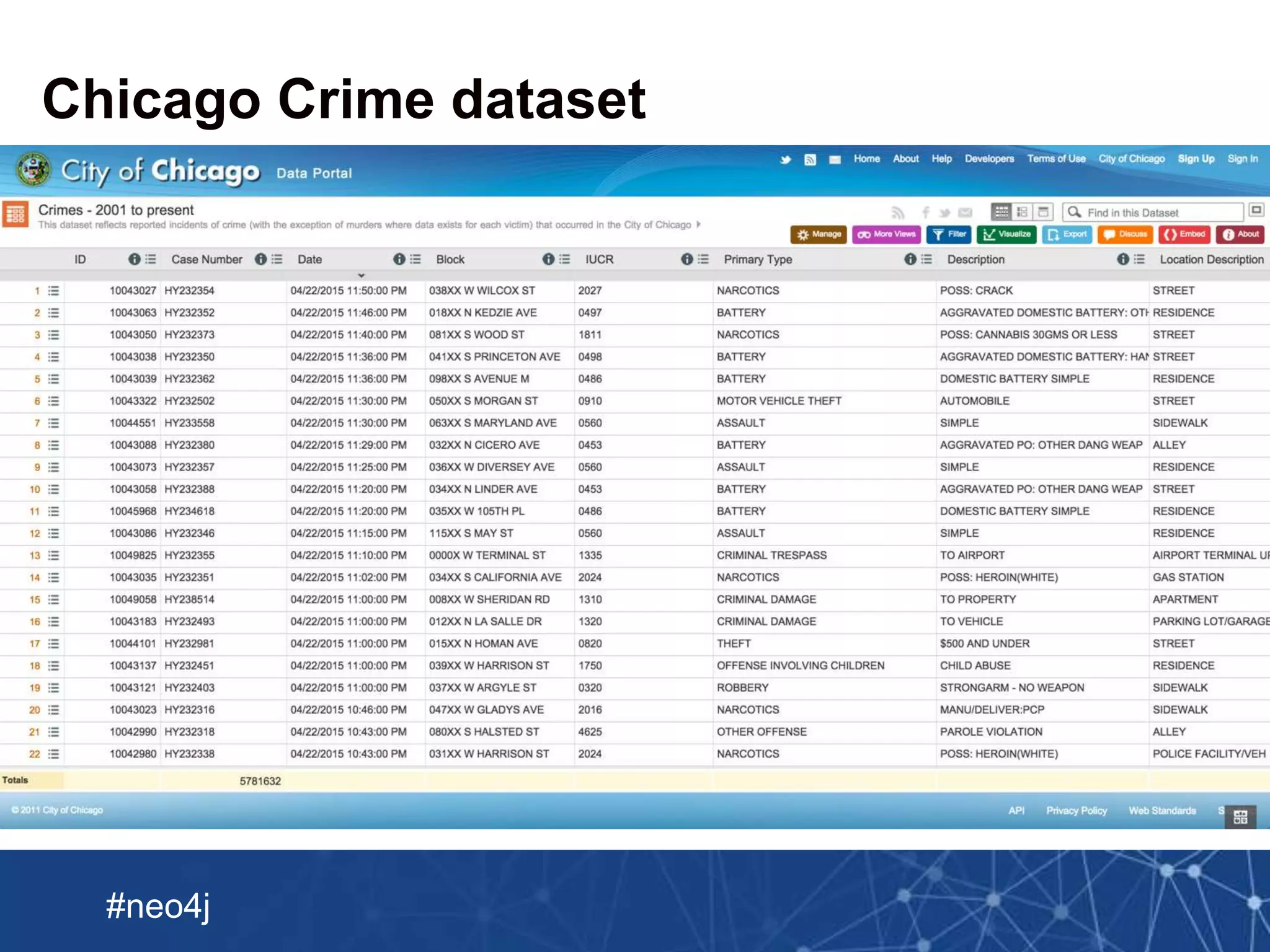
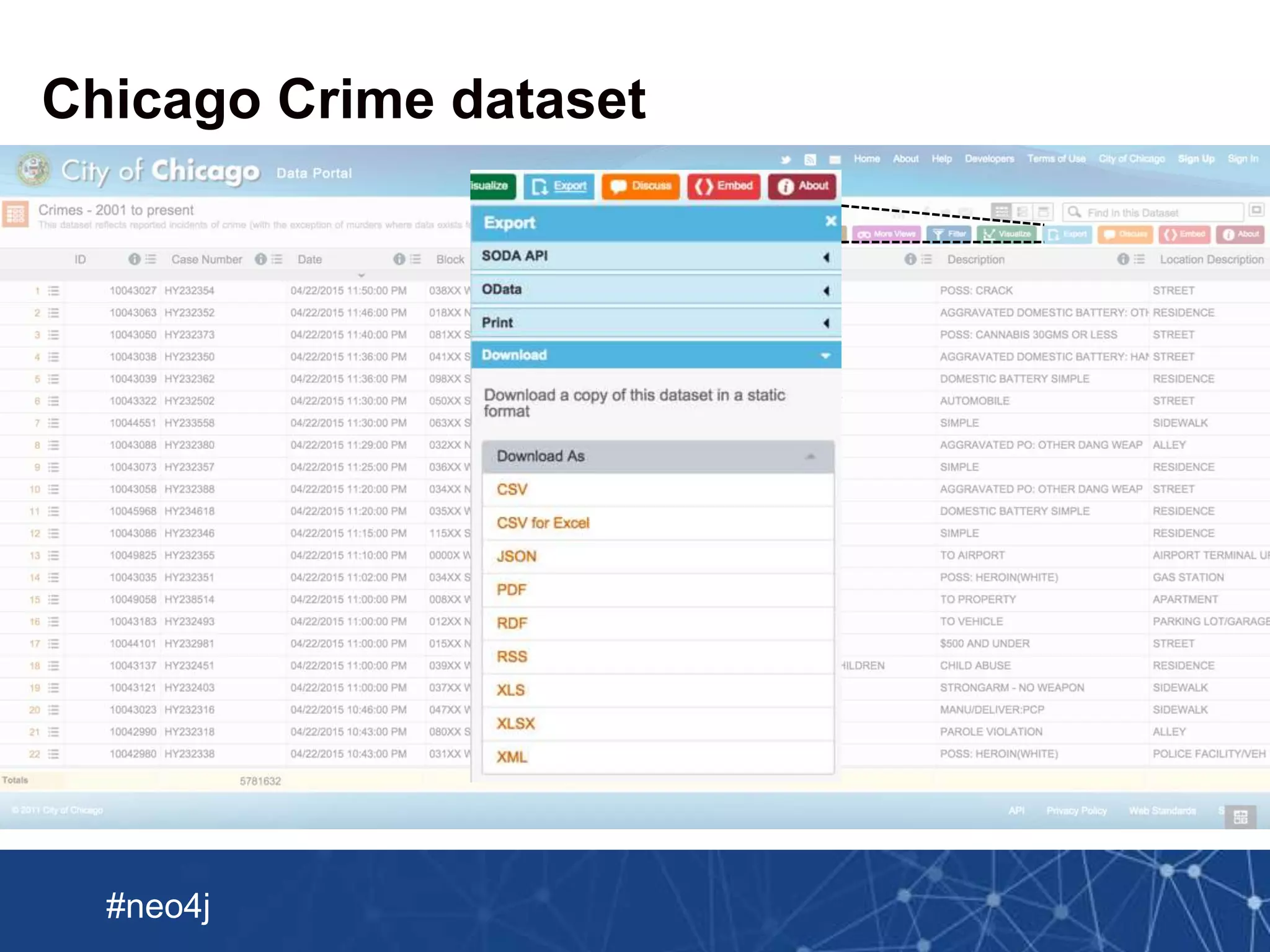
Downloaded 36 times








![Neo Technology, Inc Confidential
#neo4j
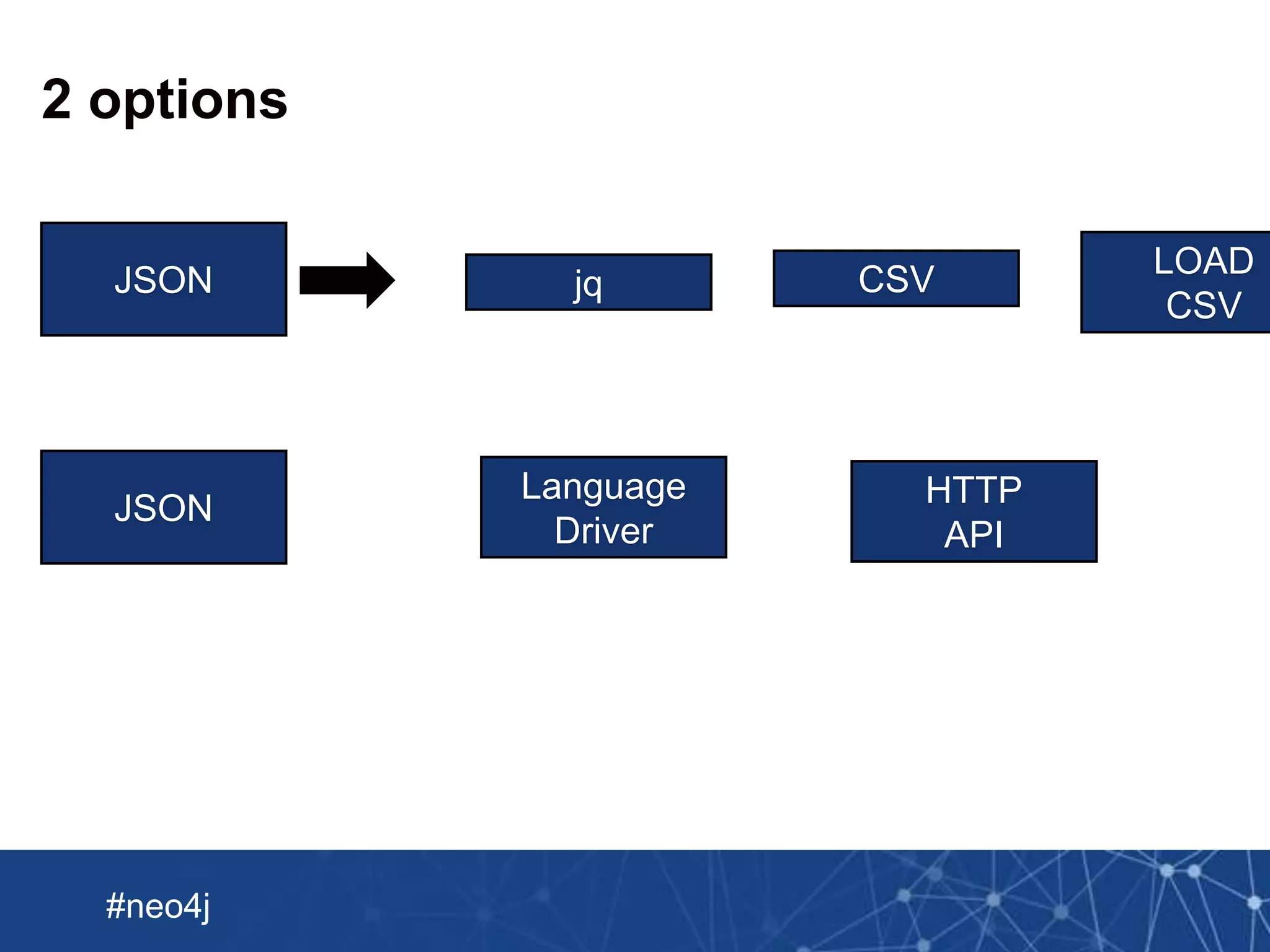
Import a sample: Crimes -> Crime Types
LOAD CSV WITH HEADERS FROM
"file:///Users/markneedham/projects/neo4j-spark-chicago/Crimes_-_2001_to
_present.csv"
AS row
WITH row LIMIT 100
MATCH (crime:Crime {
id: row.ID,
description: row.Description})
MATCH (crimeType:CrimeType {
name: row.`Primary Type`})
MERGE (crime)-[:TYPE]->(crimeType);](https://image.slidesharecdn.com/import-webinar-160719184842/75/Neo4j-Import-Webinar-13-2048.jpg)










![Neo Technology, Inc Confidential
#neo4j
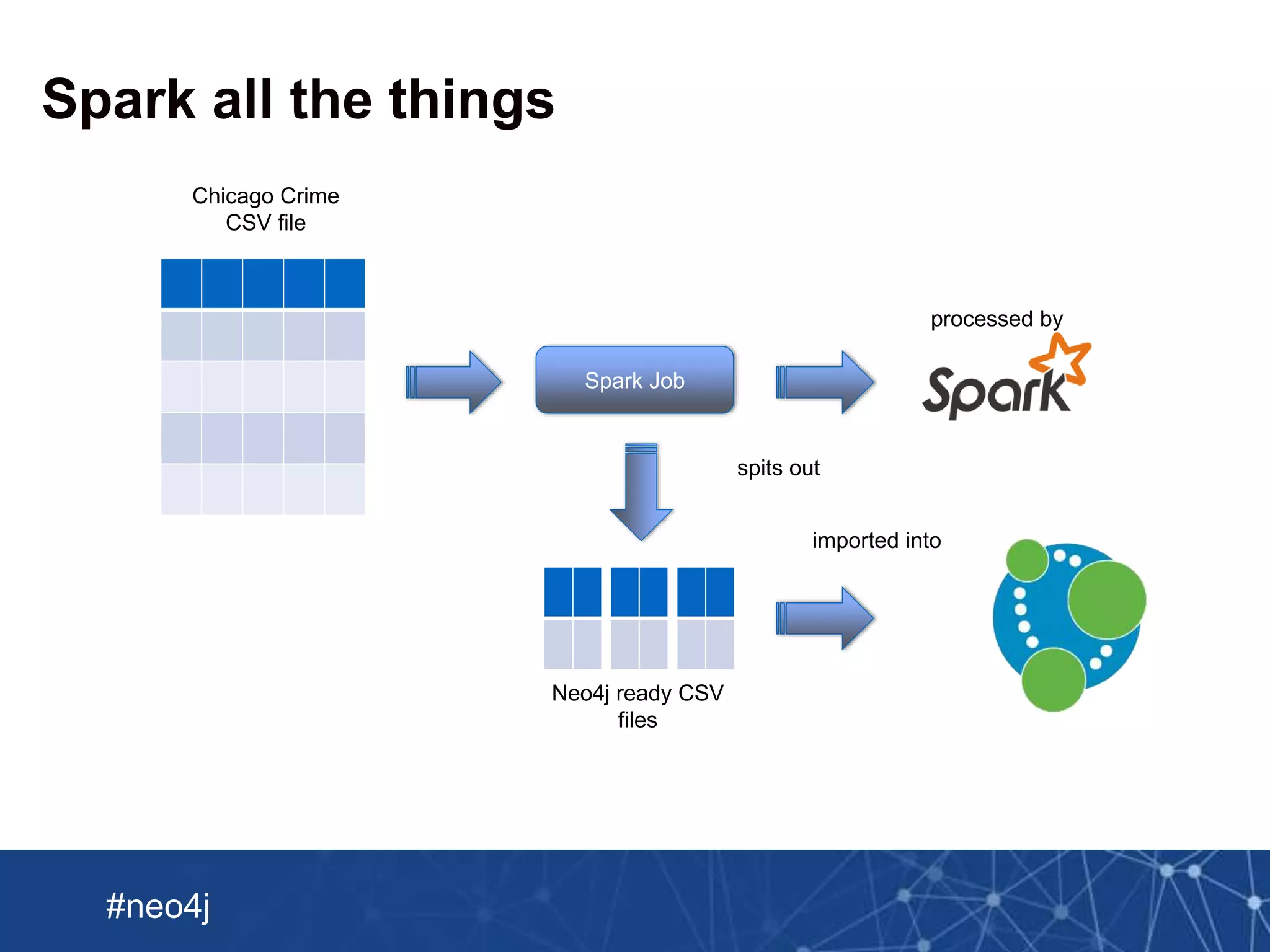
Submitting the Spark Job
./spark-1.3.0-bin-hadoop1/bin/spark-submit
--driver-memory 5g
--class GenerateCSVFiles
--master local[8]
target/scala-2.10/playground_2.10-1.0.jar
real 1m25.506s
user 8m2.183s
sys 0m24.267s](https://image.slidesharecdn.com/import-webinar-160719184842/75/Neo4j-Import-Webinar-27-2048.jpg)
![Neo Technology, Inc Confidential
#neo4j
Submitting the Spark Job
./spark-1.3.0-bin-hadoop1/bin/spark-submit
--driver-memory 5g
--class GenerateCSVFiles
--master local[8]
target/scala-2.10/playground_2.10-1.0.jar
real 1m25.506s
user 8m2.183s
sys 0m24.267s](https://image.slidesharecdn.com/import-webinar-160719184842/75/Neo4j-Import-Webinar-28-2048.jpg)




![Neo Technology, Inc Confidential
#neo4j
Using py2neo to load JSON into Neo4j
import json
from py2neo import Graph, authenticate
authenticate("localhost:7474", "neo4j", "foobar")
graph = Graph()
with open('categories.json') as data_file:
json = json.load(data_file)
query = """
WITH {json} AS document
UNWIND document.categories AS category
UNWIND category.sub_categories AS subCategory
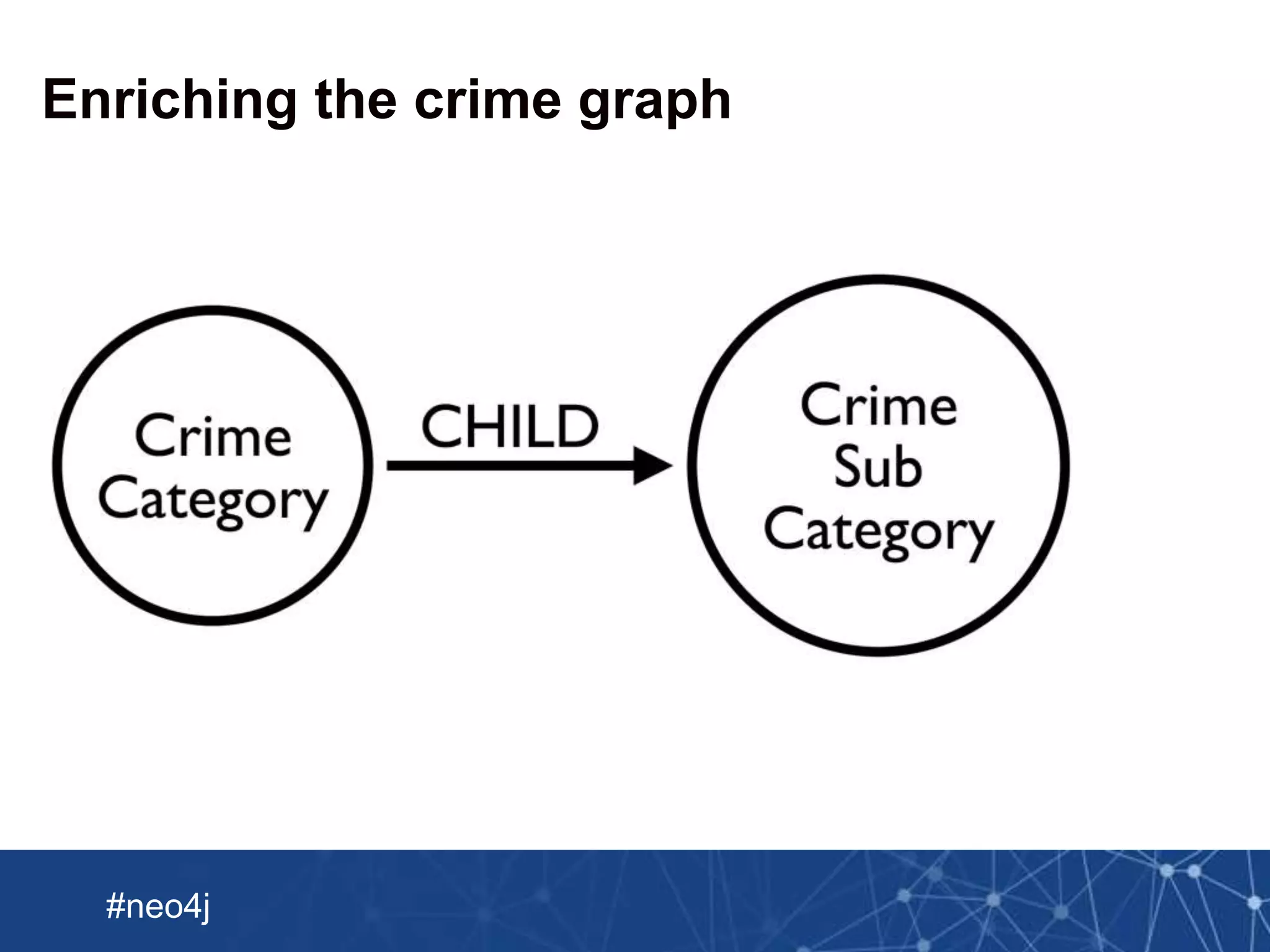
MERGE (c:CrimeCategory {name: category.name})
MERGE (sc:SubCategory {code: subCategory.code})
ON CREATE SET sc.description = subCategory.description
MERGE (c)-[:CHILD]->(sc)
"""
print graph.cypher.execute(query, json = json)](https://image.slidesharecdn.com/import-webinar-160719184842/75/Neo4j-Import-Webinar-35-2048.jpg)







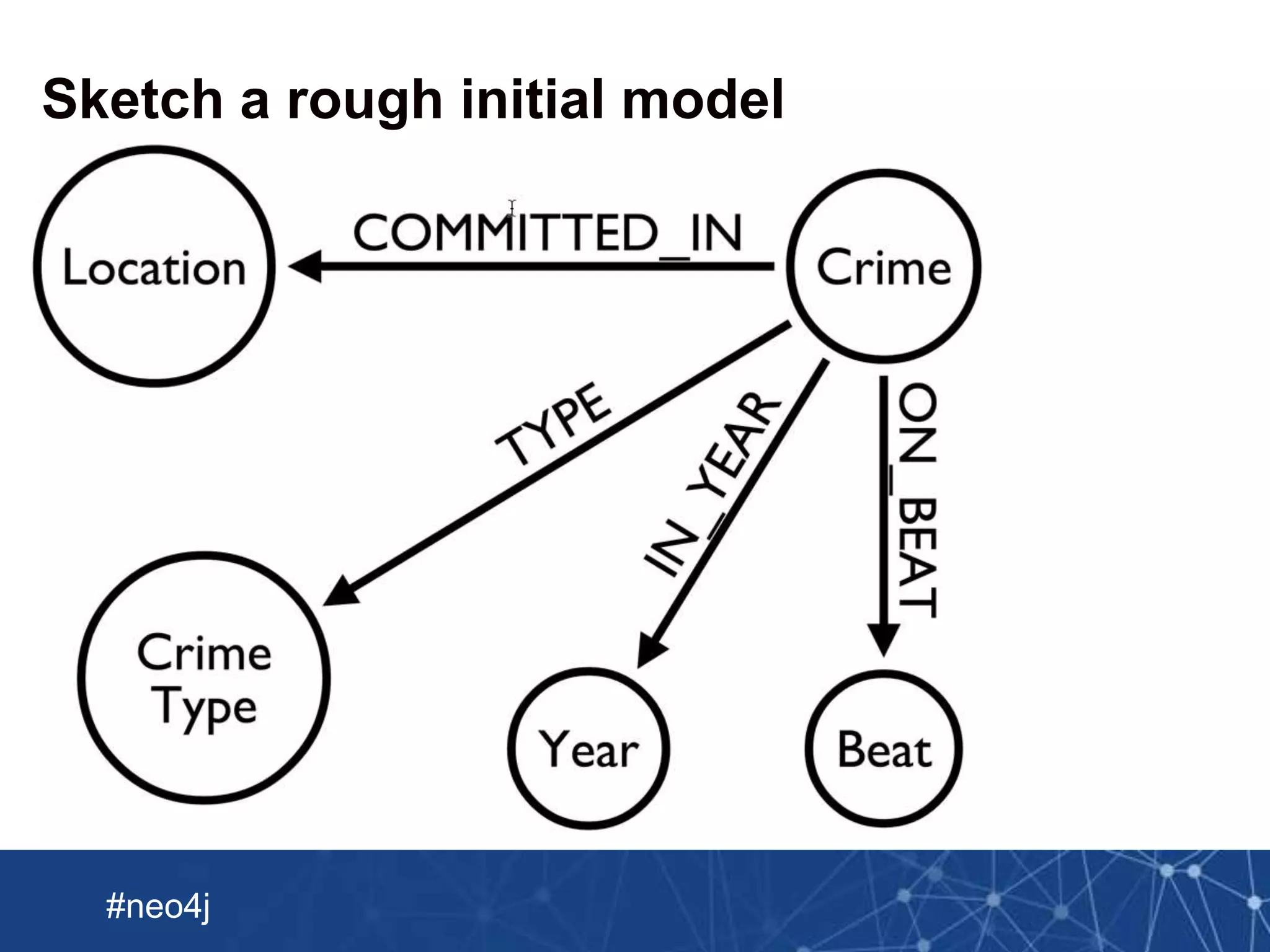
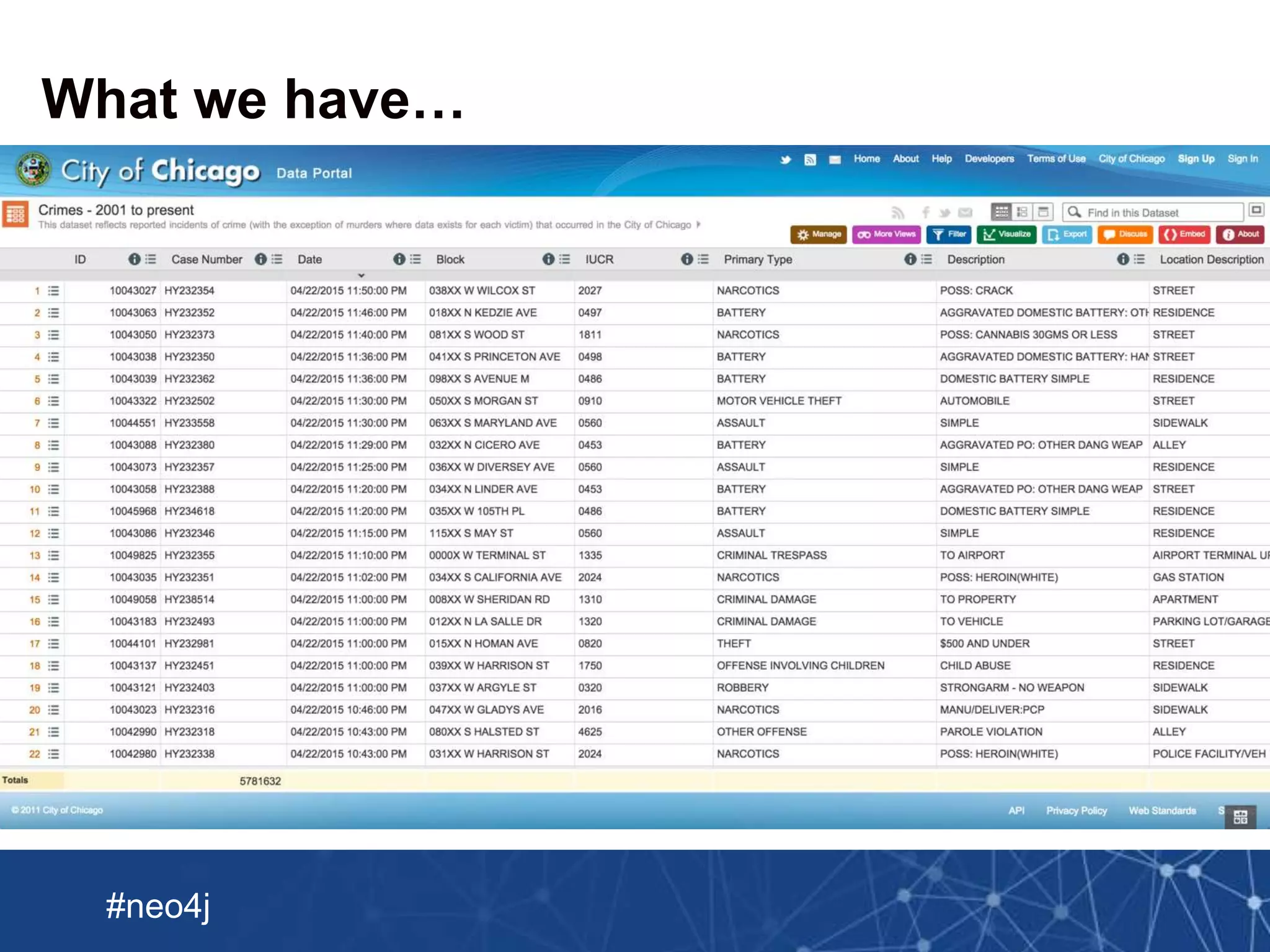
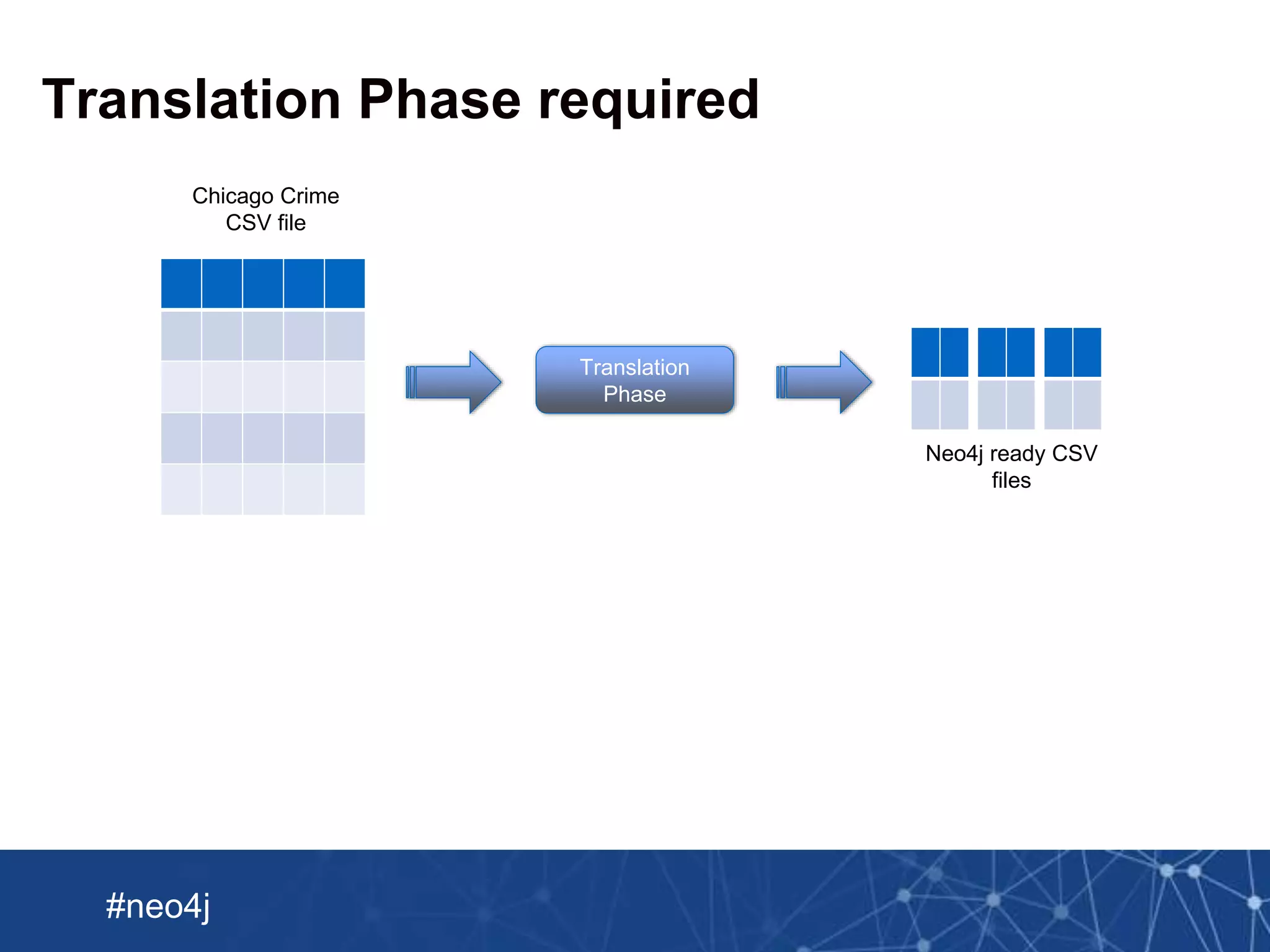
This document summarizes a webinar about importing crime data from Chicago into Neo4j. It discusses loading a CSV file of crime data into Neo4j using LOAD CSV and creating nodes and relationships. It also describes using Spark to preprocess the CSV into multiple Neo4j-formatted files and bulk loading them using the Neo4j Import tool. The document then covers enriching the graph with additional crime data from JSON and updating the graph with new crimes.
































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





