Downloaded 136 times


![Graph-like power
Roman R.
MATCH (a:Actor),(m:Movie)
WHERE a.name ='Keanu Reeves'
AND m.title='The Matrix'
CREATE (actor)-[:ACTS_IN]->(movie)](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-2-320.jpg)







![Neo4j: Properties
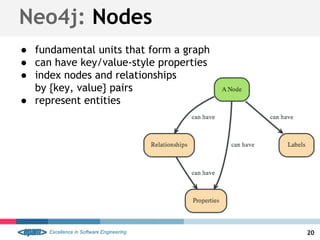
● nodes and relationships can have properties
● are key-value pairs
○ key is a string
○ values can be either a primitive or an array of
one primitive type
■ boolean, String, int, int[], etc
■ Java Language Specification
● entity attributes, rels qualities,
and metadata
23](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-25-320.jpg)





![Cypher patterns #2/2
34
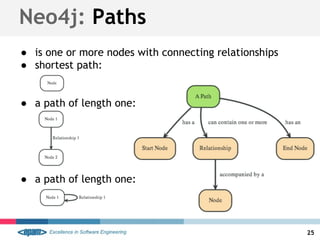
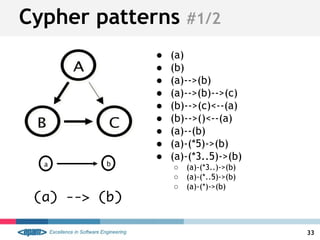
● (a:Label)-->(m)
● (a:User:Admin)-->(m)
● (a)--(m)
● (a)-[r]->(m)
● (a)-[ACTED_IN]->(m)
● (a)-[r:SOME|ELSE|WTH]->(m)](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-36-320.jpg)

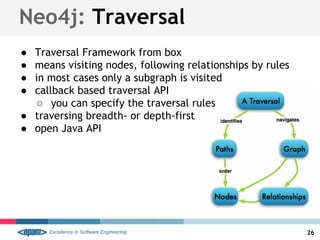
![Cypher: MATCH
● primary way of getting data from the database
● START <lookup> MATCH <pattern> RETURN <expr>
● OPTIONAL MATCH <lookup> RETURN <expr>
Examples:
● MATCH (n) RETURN count(n)
● MATCH (actor:Actor) RETURN actor.name;
● START me=node(0) MATCH (me)--(f) RETURN f.name
● MATCH (n)-[r]->(m) RETURN n AS FROM, r AS `->`, m AS TO
36](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-38-320.jpg)
![● creates nodes and relationships
● CREATE (<name>[:label] [properties,..])
● CREATE (<node-in>)-[<var>:RELATION [properties,..]]->(<node-out>);
● CREATE UNIQUE ...
Examples:
● CREATE (n:Actor { name:"Keanu Reeves" });
● CREATE (keanu)-[:ACTED_IN]->(matrix)
● MATCH (keanu {name:”..”}) SET keanu.age=49 RETURN
Cypher: CREATE / SET
37](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-39-320.jpg)






![Cypher: back to SQL #2/5
● SELECT “Email”.*
FROM Person
JOIN “Email” ON “Person”.id = “Email”.person_id
WHERE “Person”.name = “Benedikt”
● START person=node:Person(name=”Benedikt”)
MATCH person-[:email]->email
RETURN email
44](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-46-320.jpg)
![Cypher: back to SQL #3/5
● show me all people that are both actors and
directors
● SELECT name FROM Person
WHERE
person_id IN (SELECT person_id FROM Actor) AND
person_id IN (SELECT person_id FROM Director)
● START person=node:Person(“name:*”)
WHERE (person)-[:ACTS_IN]->()
AND (person)-[:DIRECTED]->()
RETURN person.name
45](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-47-320.jpg)
![Cypher: back to SQL #4/5
● show me all Tom Hanks’s co-actors
● SELECT DISTICT co_actor.name FROM Person tom
JOIN Movie a1 ON tom.person_in = a1.person_id
JOIN Actor a2 ON a1.movie_id = a2.movie_id
JOIN Person co_actor ON co_actor.person_id = a2.person_id
WHERE tom.name = “Tom Hanks”
● START tom=node:Person(name=”Tom Hanks”)
MATCH tom-[:ACTS_IN]->movie,
co_actor-[:ACTS_IN]->movie
RETURN DISTINCT co_actor.name
46](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-48-320.jpg)
![Cypher: back to SQL #5/5
● show me all Lucy’s favorite directors
● SELECT dir.name, count(*) FROM Person lucy
JOIN Actor on Person.person_id = Actor.person_id
JOIN Director ON Actor.movie_id = Director.movie_id
JOIN Person dir ON Director.person_id = dir.person_id
WHERE lucy.name = “Lucy Liu”
GROUP BY dir.name
ORDER BY count(*) DESC
● START lucy=node:Person(name=”Lucy Liu”)
MATCH lucy-[:ACTS_IN]->movie,
director-[:DIRECTED]->movie
RETURN director.name, count(*)
ORDER BY director.name, count(*) DESC
47](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-49-320.jpg)
![START
lucy = node:Person(name=”Lucy Lui”),
kevin = node:Person(name=”Kevin Bacon”)
MATCH
p = shortestPath( lucy-[:ACTS_IN*]-kevin )
RETURN
EXTRACT (n in NODES(p):
COALESCE(n.name?, n.title?))
48
Cypher: back to SQL #6/5](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-50-320.jpg)



![● graph traversal language
● scripting language
● Pipe & Filter (similar to jQuery)
● across different graph databases
● based on Groovy (limited to Java)
● not as stable in Neo4j
● XPath like
● ./outE[label=”family”]/inV/@name
● g.v(1).out('likes').in('likes').out('likes').groupCount(m)
● g.V.as('x').out.groupCount(m).loop('x'){c++ < 1000}
● g.v(1).in(‘LOVE_OF’).out(‘SOME_IN’).has(‘title’,’abc’).back(2)
Gremlin
52](https://image.slidesharecdn.com/neo4j-epam-140418083225-phpapp01/85/Neo4j-Graph-like-power-54-320.jpg)










This document provides an overview of graph databases and Neo4j. It defines what a graph is mathematically and in the context of databases. It describes the key components of Neo4j including nodes, relationships, properties, labels, paths, traversals, and indexes. It also discusses the Cypher query language, performance advantages of Neo4j over SQL databases, and basic requirements and licensing options.









![[DSC 2016] 系列活動:李泳泉 / 星火燎原 - Spark 機器學習初探](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmllib-161026052038-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[FRENCH] - Neo4j and Cypher - Remi Delhaye](https://cdn.slidesharecdn.com/ss_thumbnails/presentation-140424120458-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

























































