Downloaded 11 times


















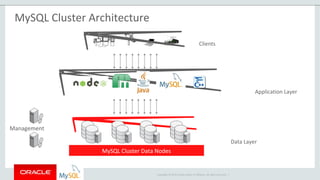
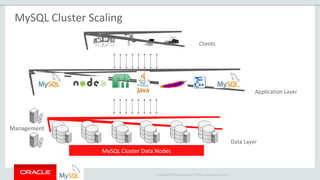
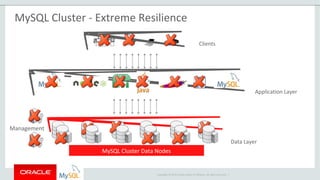





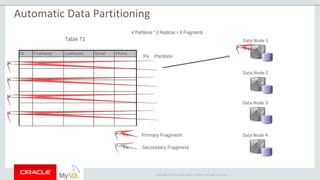

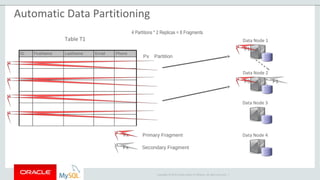
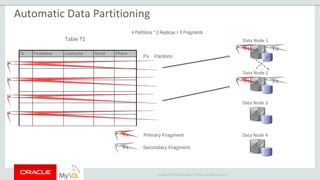
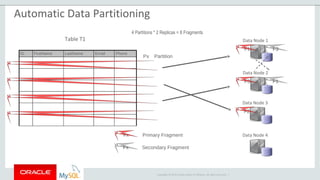
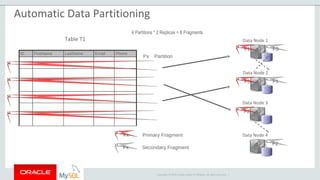
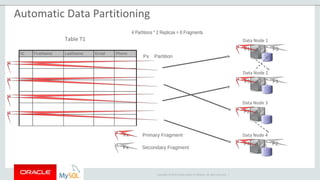
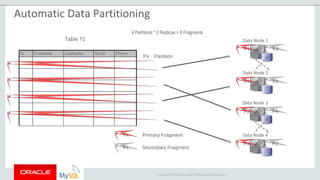
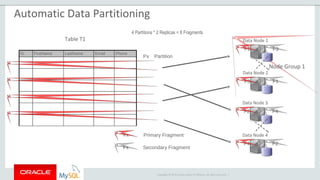
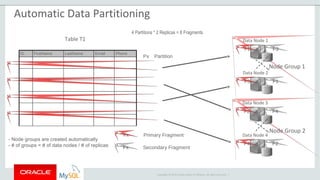
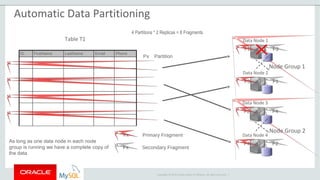
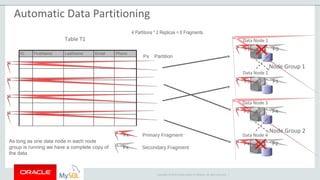
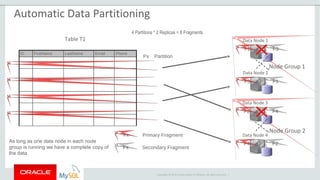
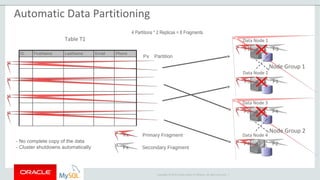


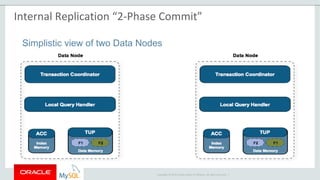
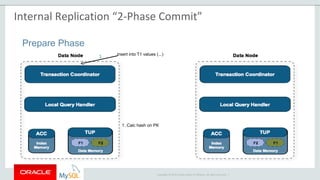
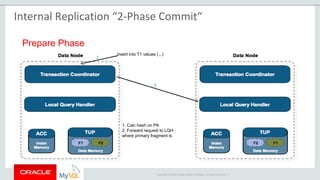
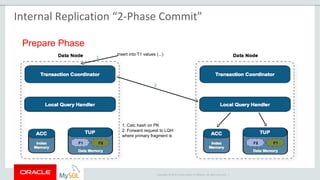
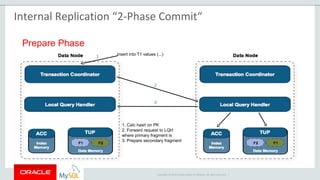
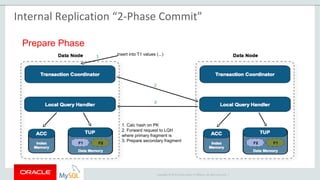
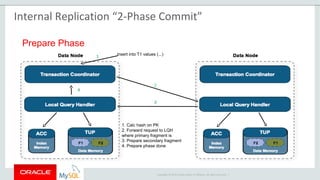
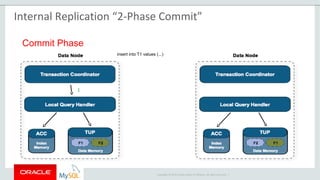
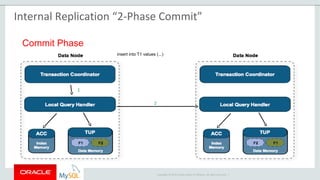
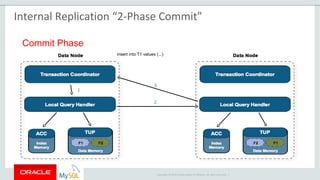
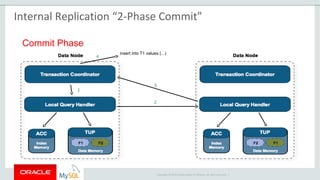



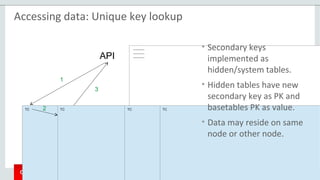
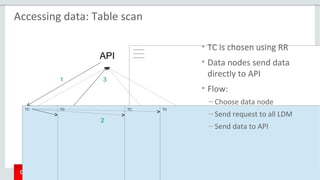







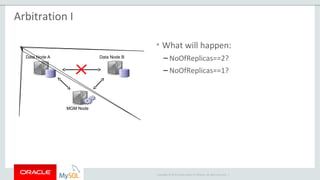
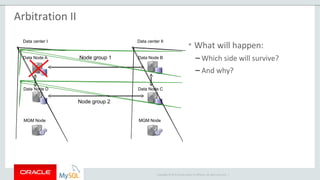
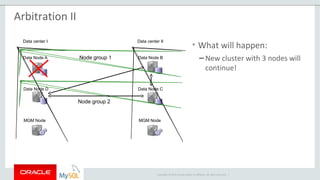
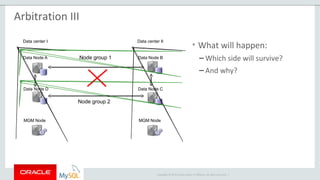
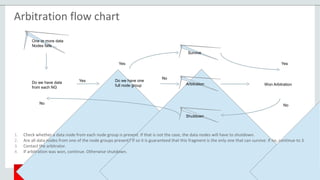



The document provides an overview of MySQL Cluster, including its history, architecture, components, and data partitioning. MySQL Cluster was originally developed by Ericsson in the late 1990s to provide highly reliable, real-time performance for telecommunications databases. It has since been acquired and maintained by Oracle. MySQL Cluster uses multiple data nodes to store and replicate data fragments across the cluster, providing high availability and linear scalability.



































































