Python 및 JupyterNotebook 설치
1. Jupyter lab 설치하기 [Git blog]
2. Konlpy 에 필요한 내용 설치하기
3. pip install -r requirement.txt 로 모듈 추가
Python : https://www.python.org
14.
Python의 특징
1. 다양한기능의 Open Source 를 제공
2. 모듈에서 정하는 포맷을 맞추는 전처리 필요 (python 기본기!!)
3. 기타 연산 및 출력은 자동
Python : https://www.python.org
Stemming / Tagging의 구조적 한계
1. 독립된 개별 Token의 태그 값을 추출
2. 평문, 일반문의 경우 규격화된 결과를 출력
3. 강조문/ 도치문/ 압축문 등 문장 특성별 차이 구분은 어렵다
4. Token / Stemming / Tagging 기준이 별도로 존재
Konlpy
1. KKMA :서울대 이상구 교수 연구실
2. Hannanum : 카이스트 최기선 교수 연구실
3. Twitter : OpenKoreanText 오픈 소스 한국어 처리기
4. Eunjeon : 은전한닢 프로젝트 (윈도우 미지원) [링크]
5. KOMORAN : Junsoo Shin님의 코모란 v3.3.3
6. 빠른 분석이 중요할 때 : 트위터
7. 정확한 품사 정보가 필요할 때 : 꼬꼬마
8. 정확성, 시간 모두 중요할 때 : 코모란
44.
stem = True- 정규화 Corpus 활용여부 (Twitter 모듈)
cf) false는 Tokenize 작업 결과만 갖고서 Tag 출력
1. 문서의 내용을쉽게 벡터로 표현하는 고전적 방식
2. Term Frequency : 해당 문서내 Token 발생빈도
3. (문서 Token 출현빈도) / (문서 전체 Token 갯수)
4. Inverse Document Frequency : 문서 빈도의 역
5. log (전체 문서 수 / Token 포함 문서 수)
상대빈도분석 - Term Frequency
Inverse Document Frequency
CBOW - ContinuousBag-of-Words
1. 문장의 여러 단어들 가운데,
빈 단어를 채운다
2. 단어사이 적합한 내용을
예측하는 Network
출처 : http://hero4earth.com/blog/learning/2018/01/17/NLP_Basics_01/
121.
Skip Gram
1. 주어진1개 Token의 주변 단어를 예측
2. 예측 주변단어 수에 따라 연산이 다름
(다양한 기법이 가능)
3. CBOW와 비교하여 더 좋은 결과
pip install --upgradegensim
1. Why is Gensim Word2Vec so much faster than Keras GPU? [link]
2. 데이터와 모델 을 저장하고, 호출하는 방식을 잘 익히자
3. 주요한 기능을 메소드 함수로 제공
https://radimrehurek.com/gensim/install.html
임베딩 - 원시데이터(raw data)를 학습 후 축소된 숫자 목록으로 변환
1. Tf-idf : 벡터화에 바탕을 둔 용어빈도/ 역 문서 빈도 를 활용
2. Word2Vec : Mikolov가 고안한 방법으로 "주변 단어를 보면
그 단어를 알 수 있다" (John Firth) 에서 착안
3. One-hot Encoding : 단어를 고유한 숫자 인덱스로 치환
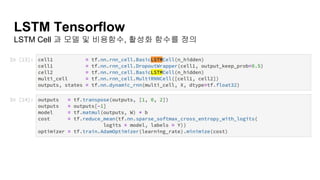
LSTM RNN CELL
RecurrentNeual Network
https://medium.com/@apiltamang/unmasking-a-vanilla-rnn-what-lies-beneath-912120f7e56c
recurrent connection allows
the network to remember
what it learned
in the previous step.
154.
LSTM 유닛구조
1. 유지게이트: 앞의 Cell에서 넘어온 정보 중, 오래된 삭제할
정보와 유지할 정보를 Sigmoid 뉴런으로 구분한다
2. 쓰기게이트 : 위에서 구분한 정보중 필요한 정보(tan h)를
판단 후 상태변환/유지 여부를 파악 후 처리를 한다
3. 출력게이트 : 쓰기게이트와 유사한 구조를 갖고서 최종
결과물을 판단, 처리를 한다
155.
LSTM 의 장점
1.Hidden값을 Gate로 통과하면서 Noise를 발생
2. 저장된 Noise로 위상차이(반복횟수)를 구분
3. Gate 통과 전 / 이후의 값의 차이로 다양한 시간차를 인식
4. Sequence(연속적) 데이터 학습에 용이하다
156.
>> 05-1.RNN-LSTM.ipynb
[실습Code] -어휘 단어예측
1. 전체 4개 알파벳을 학습하면서, 3개의 알파벳을 입력하면,
나머지 알파벳 1개를 예측하는 모델을 정의
2. 알파벳을 기본 요소로 LSTM graph를 활용한다
3. One hot - Encoding 데이터를 활용하는 만큼, 별도의
batch 사용자 함수를 정의해야 한다
seq 2 seq
1.2013년 구글에서 공개한 기계번역 신경망 모델이다
2. LSTM 인코더(A, B, C) 와 LSTM 디코더(W, X, Y,)를 연결
3. RNN의 재귀적 학습의 특성으로 인해, 특수함 심벌 ((1)
입력의 시작을 알림 (2) 디코더 출력이 끝남을 알림)을
필요로 한다
4. 대화형 챗봇, 번역 등 폭넓게 활용
165.
>> 05-2.Seq2Seq.ipynb
[실습Code] -번역봇
1. 영문과 이에 대응하는 한글을 학습
2. 객체들은 One-Hot Encoding을 활용
3. 한글 과 영문의 갯수는 정교한 학습을 위해 동일하게 한다
4. 글자수가 다른 내용을 학습 할 경우는 Padding 기호를
활용
챗봇의 실행 (질문예시)
넌누구야? // 이름이 뭐야? // 뭐하니?
독일의 수도는? // 달러 환율이 어떻게 되나요?
좋아하는 가수가 누구예요?
배가 너무 고플땐 어떻게 하나요?
출처 : https://blog.markgrowth.com/how-chat-bots-can-help-you-increase-conversion-6561ba0b8ab0
172.
챗봇의 한계
1. Endto End 방식으로 블랙박스모델 학습
2. 연산(생각) 은 숫자만 가능!!
3. 문자를 전처리 및 분석 (오타수정, 구분기호)
4. 성격에 맞는 방식으로 숫자 치환(임배딩) 한다
Review
1. Token 개념
2.Token의 정규화(Stemming), 형태소/ 문법 태그(Tagging)
3. StopWord / Tf-idf
4. N-gram 을 활용한 PMI 연어(collocation) 분석
5. 나이브베이즈, Word2Vec 머신러닝 이론 응용
6. LSTM, Seq2Seq 딥러닝 이론 응용
177.
자연어 작업과정
1. 음운론(Phonology): 말소리 연구 ex) 음성인식
2. 형태론(Morphology) : 단어 정규화/ 형태소
3. 통사론(Syntax) : 문법구조(Passing)
4. 의미론(Senmantics) : 의미차이 ex) 뉘앙스, 톤, 의도(긍/부정)
5. 추리론(Reasoning) : 도메인 특성 ex) 전문용어, 세대별 용어










![Documents
1. 평양 남북정상회담 대국민 보고문 (2018.09.18)
2. 분기별 영문 보고서 [Web Site] (2015~2017)
3. 연도별 경영 보고서 [지속가능경영 보고서] (2015~2018)
4. 네이버 영화 긍정/ 부정 리뷰 15만개
5. 영화 대본 [살인의 추억]
6. 일반 대화문 예시 (Chat Bot)](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-11-320.jpg)

![Python 및 Jupyter Notebook 설치
1. Jupyter lab 설치하기 [Git blog]
2. Konlpy 에 필요한 내용 설치하기
3. pip install -r requirement.txt 로 모듈 추가
Python : https://www.python.org](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-13-320.jpg)





























![Konlpy
1. KKMA : 서울대 이상구 교수 연구실
2. Hannanum : 카이스트 최기선 교수 연구실
3. Twitter : OpenKoreanText 오픈 소스 한국어 처리기
4. Eunjeon : 은전한닢 프로젝트 (윈도우 미지원) [링크]
5. KOMORAN : Junsoo Shin님의 코모란 v3.3.3
6. 빠른 분석이 중요할 때 : 트위터
7. 정확한 품사 정보가 필요할 때 : 꼬꼬마
8. 정확성, 시간 모두 중요할 때 : 코모란](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-43-320.jpg)














![삼성전자
지속가능경영보고서 [2018 PDF]
- 지속경영보고서 2015, 2016, 2017, 2018 -
>> Project1-Stopword.ipynb](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-58-320.jpg)





































![Pickle [stackoverflow]](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-96-320.jpg)














![Word 2 Vec
- 100차원 ~ 300차원 의 데이터 -
[ x좌표, y좌표, z좌표]
[ 인덱스1, 인덱스2,
인덱스3, 인덱스4, …..]](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-111-320.jpg)
![Vector
[ x축 3개, y축 3개, z축 3개]
- 3개 vector의 Network -
[ 1번방 3개 Token,
2번방 3개 Token,
3번방 3개 Token ]
- 9개 Token의 Network -](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-112-320.jpg)










![pip install --upgrade gensim
1. Why is Gensim Word2Vec so much faster than Keras GPU? [link]
2. 데이터와 모델 을 저장하고, 호출하는 방식을 잘 익히자
3. 주요한 기능을 메소드 함수로 제공
https://radimrehurek.com/gensim/install.html](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-123-320.jpg)















![CNN을 활용한 자연어 분석
1. 전방향 합성곱 신경망
2. 방대한 데이터 중 특징적인 부분을 추출하는 기법
3. Text 분류를 CNN을 사용하여 훈련모델을 생성 [Blog]](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-139-320.jpg)
















![>> 05-1.RNN-LSTM.ipynb
[실습Code] - 어휘 단어예측
1. 전체 4개 알파벳을 학습하면서, 3개의 알파벳을 입력하면,
나머지 알파벳 1개를 예측하는 모델을 정의
2. 알파벳을 기본 요소로 LSTM graph를 활용한다
3. One hot - Encoding 데이터를 활용하는 만큼, 별도의
batch 사용자 함수를 정의해야 한다](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-156-320.jpg)







![>> 05-2.Seq2Seq.ipynb
[실습Code] - 번역봇
1. 영문과 이에 대응하는 한글을 학습
2. 객체들은 One-Hot Encoding을 활용
3. 한글 과 영문의 갯수는 정교한 학습을 위해 동일하게 한다
4. 글자수가 다른 내용을 학습 할 경우는 Padding 기호를
활용](https://image.slidesharecdn.com/nltktutorial-181004023512/85/slide-165-320.jpg)























![[211] 네이버 검색과 데이터마이닝](https://cdn.slidesharecdn.com/ss_thumbnails/211-150915001301-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)
























