word2vec의 정의
• 비지도방식의 단어 임베딩 접
근법
• 표현 벡터의 단일 요소와 대조
적으로 전체 표현 벡터의 활성
화 패턴에 의해 단어의 의미가
캡처되므로 분산 표현
3.
Wordnet
• wordnet은 프린스턴대학교에서 과거에 영어단어들에 대해서 구축한 일종의 온톨로지로, 단어간에 어떤 관계를 가지
고 있는지를 정리한 온톨로지다. 사전처럼 단어별로 개별적인 의미를 정리하는 것보다, 이렇게 단어간의 관계를 중심
으로 정리할 경우 그 활용도가 높아질 수 있다.
• 일반적으로 ‘온톨로지’는 특정 세계에 대해 잘 구축된 체계 정도로 번역할 수 있다(학술적으로 들어가면 좀 달라진다).
• 지속적으로 유지보수되어야 하는 문제점이 있기는 하지만, 현재 영단어에 대해서는 가장 잘 정의된 온톨로지 라고 할
수 있다.
• 국내에서도 부산대에서 비슷한 작업을 수행한 적이 있으나, 완전히 공개되지 않아서 접근성 등의 문제가 있음
• wordnet의 경우는 nltk에 통합되어 상대적으로 쉽게 쓸 수 있음
• 물론 최근에는 word-embedding 등을 사용해서 온톨로지 없이도 온톨로지와 비슷한 효과를 내고 있기 때문에, 이 라이
브러리가 반드시 필요한가?에 대해서는 현재는 의문이 있다.
• Word-embedding과 wordnet을 활용하면, 좀 더 재미있는 짓을 할 수 있지 않을까? 싶은데, 예를 들어서 1) 빠르게 학
습한다거나, 2)…..아무튼…
• wordnet에서 단어 간에 성립할 수 있는 관계는 대략 다음과 같은 정도로 표현된다.
워드넷에서 다음 네 가지를 어떻게 활용하는지 이후에 설명한다.
• synonym: 동의어
• antonym: 반의어
• hypernym: 상의어
• hyponym: 하위어
4.
TF-IDF
• TF(단어 빈도,term frequency)는 특정한 단어가 문서 내에 얼
마나 자주 등장하는지를 나타내는 값. 이 값이 높을수록 문서
에서 중요하다고 생각할 수 있다.
• 하지만 하나의 문서에서 많이 나오지 않고 다른 문서에서 자
주 등장하면 단어의 중요도는 낮아진다.
• DF(문서 빈도, document frequency)라고 하며, 이 값의 역수
를 IDF(역문서 빈도, inverse document frequency)라고 한다.
• TF-IDF는 TF와 IDF를 곱한 값으로 점수가 높은 단어일수록
다른 문서에는 많지 않고 해당 문서에서 자주 등장하는 단어
를 의미한다.
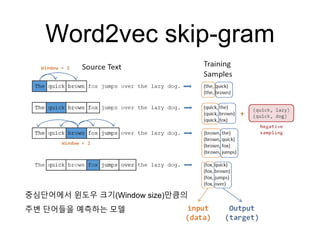
Word2vec skip-gram
• word2vec모델은 학습시간을 줄이기 위해 트릭을 쓰는
데, 바 로 네거티브 샘플링(negative sampling) 이다.
• 네거티브 샘플링은 앞의 그림에서 처럼 'Training
Sample'과 같은 단어 쌍들에 포함되어 있지 않는 가짜 단
어 쌍들을 만들어 낸다.
• 지정한 윈도우 사이즈 내에서 포함되지 않는 단어들을
포함시켜 단어 쌍들을 만들어 내는것이다.
• 예를 들어 위의 그림에서 두번째 줄에서 윈도우 사이즈
내에 포 함되지 않는 lazy라는 단어를 뽑아 (quick,
lazy)라는 단어쌍을 만드는 것이다.
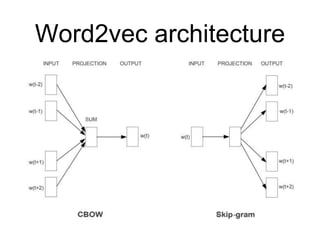
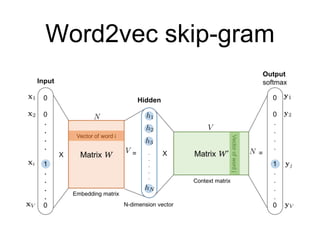
Word2vec CBOW
• 주어진단어에 대해 앞 뒤로 C/2개
씩 총 C개의 단어를 Input으로 사용
하여, 주어진 단어를 맞추기 위한
네트워크를 만든다.
• CBOW의 계산량
• C개의 단어를 Projection 하는 데에 C x N
• Projection Layer에서 Output Layer로 가는 데에 N x V









![[20190601] 직업훈련교사_수업의실행_교안](https://cdn.slidesharecdn.com/ss_thumbnails/planmockclass-190614020025-thumbnail.jpg?width=640&height=640&fit=bounds)






![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)























