• Word embedding
•Relation extraction
• Sentence classification
• Language model
# Media art
# Computer generated art
# Artificial general intelligence
3.
• 자연어 처리의종류와, 자연어 처리가 현업에서 적용된 예제를 소개한다
• BERT가 탄생하게 된 과정과, BERT에 적용된 메커니즘을 살펴본다
• BERT를 이용한 다양한 자연어 처리 실험 결과들을 소개한다
• Open source로 공개된 BERT 코드를 이용해 한국어 BERT를 학습해보고, 다양
한 자연어 처리 task를 직접 실습해본다
4.
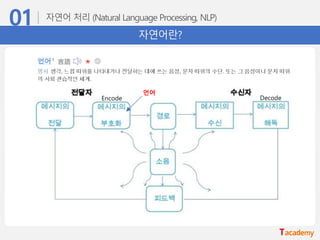
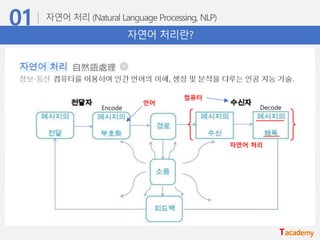
• 자연어 처리(Natural Language Processing, NLP)
• 자연어란?
• 다양한 자연어 처리
• Word embedding
• 언어 모델 (Language Model, LM)
• Markov 확률 모델
• RNN (Recurrent Neural Network) 모델
• Attention 모델
• Self-attention 모델
• Transformer 모델
• BERT 소개
• WordPiece tokenizing
• BERT 모델
• BERT의 적용 실험
• 한국어 BERT
• ETRI KorBERT
• BERT 실습
다양한 자연어 처리기술
• 자연어 처리란, ‘자연어를 컴퓨터가 해독하고 그 의미를 이해하는 기술’
Symbolic approach Statistical approach
• 규칙/지식 기반 접근법 • 확률/통계 기반 접근법
• TF-IDF를 이용한 키워드 추출
• TF (Term frequency): 단어가 문서에 등장한 개수
→ TF가 높을수록 중요한 단어
• DF (Document frequency): 해당 단어가 등장한 문
서의 개수
→ DF가 높을수록 중요하지 않은 단어
* sujin oh, 실생활에서 접하는 빅데이터 알고리즘
https://www.slideshare.net/osujin121/ss-44186451?from_action=save
10.
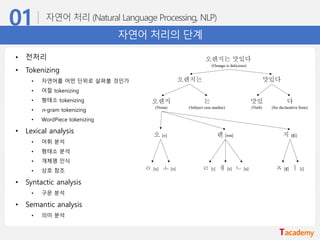
자연어 처리의 단계
•전처리
• 개행문자 제거
• 특수문자 제거
• 공백 제거
• 중복 표현 제어 (ㅋㅋㅋㅋㅋ, ㅠㅠㅠㅠ, …)
• 이메일, 링크 제거
• 제목 제거
• 불용어 (의미가 없는 용어) 제거
• 조사 제거
• 띄어쓰기, 문장분리 보정
• 사전 구축
• Tokenizing
• Lexical analysis
• Syntactic analysis
• Semantic analysis
의심한그득+. + 앞으로는 사람들 많을 퇴근시간 말구
미리 가서 사와야겠뜸٩( 'ù’ )ﻭ
맥주로 터진 입, 청포도와 고구뇽스틱으로 달래봅니당
막상 먹다보니 양이 부족하진 않았는데 괜히 ...
먹을 때 많이 먹자며 배 터지기 직전까지 냠냐미:D
식후땡 아슈크림۶ (>﹏ < ،)
브라우니쿠키 먹고 출근하세요 ♡
gs편의점에서 파는 진 - 한 브라우니 쿠키인데 JMTgr
11.
자연어 처리의 단계
•전처리
• Tokenizing
• 자연어를 어떤 단위로 살펴볼 것인가
• 어절 tokenizing
• 형태소 tokenizing
• n-gram tokenizing
• WordPiece tokenizing
• Lexical analysis
• 어휘 분석
• 형태소 분석
• 개체명 인식
• 상호 참조
• Syntactic analysis
• 구문 분석
• Semantic analysis
• 의미 분석
12.
다양한 자연어 처리Applications
• 문서 분류
• 문법, 오타 교정
• 정보 추출
• 음성 인식결과 보정
• 음성 합성 텍스트 보정
• 정보 검색
• 요약문 생성
• 기계 번역
• 질의 응답
• 기계 독해
• 챗봇
• 형태소 분석
• 개체명 분석
• 구문 분석
• 감성 분석
• 관계 추출
• 의도 파악
다양한 자연어 처리Applications
챗봇
+
음성 합성
+
감성 분류
+
개체명 인식
+
추천 시스템
+
기계 독해
+
지식 그래프
+
관계 추출
+
플러그인
자그마치 9개 이상의 NLP 기술이 합쳐진 컴비네이션
...
15.
다양한 자연어 처리Applications
• 형태소 분석, 문서 분류, 개체명 인식 등, 대부분의 자연어 처리 문제는 ‘분류’의 문제
의미 분석기 형태소 분석기 개체명 인식기구문 분석기 감성 분석기
최초의 컴퓨터
가 무엇이야?
질문 (98%)
요구 (0.5%)
거절 (0.025%)
승낙 (0.025%)
...
최초의 컴퓨터
가 무엇이야?
관형격 체언 (85%)
관형격 용언 (5%)
주격 체언 (5%)
부사격 체언(0.5%)
...
나 지금 너무
행복해
기쁨 (99%)
슬픔 (0.05%)
분노 (0.05%)
역겨움 (0.05%)
...
최초의 컴퓨터
가 무엇이야?
명사 (99%)
부사 (0.05%)
고유명사 (0.05%)
동사 (0.025%)
...
구글은 어떤
회사야?
기관 (95%)
직책 (0.05%)
사람 (0.05%)
직책 (0.025%)
...
16.
특징 추출과 분류
•‘분류’를 위해선 데이터를 수학적으로 표현
• 먼저, 분류 대상의 특징 (Feature)을 파악 (Feature extraction)
분류 대상
크기가 다양
다리의 개수가 다양
분류 대상의 특징
17.
특징 추출과 분류
•분류 대상의 특징 (Feature)를 기준으로, 분류 대상을 그래프 위에 표현 가능
• 분류 대상들의 경계를 수학적으로 나눌 수 있음 (Classification)
• 새로운 데이터 역시 특징를 기준으로 그래프에 표현하면, 어떤 그룹과 유사한지 파악 가능
다리 개수 (n)
몸크기(cm2)
새로운 데이터
18.
자연어에서의 특징 추출과분류
• 과거에는 사람이 직접 특징 (Feature)를 파악해서 분류
• 실제 복잡한 문제들에선 분류 대상의 특징을 사람이 파악하기 어려울 수 있음
• 이러한 특징을 컴퓨터가 스스로 찾고 (Feature extraction), 스스로 분류 (Classification)
하는 것이 ‘기계학습’의 핵심 기술
분류 대상
분류 대상의 특징
나는 대한민국에서 태어났다
이순신은 조선 중기의 무신이다
나 지금 너무 행복해
최초의 컴퓨터는 누가 만들었어?
지금 몇 시야?
아이유 노래 틀어줘
내일 날씨 알려줘
19.
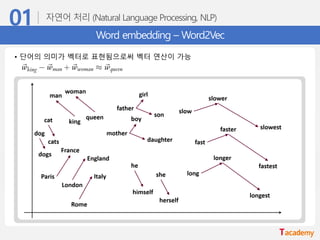
Word embedding –Word2Vec
• 자연어를 어떻게 좌표평면 위에 표현할 수 있을까?
• 가장 단순한 표현 방법은 one-hot encoding 방식 → Sparse representation
세상 모든 사람
단어 Vector
세상 [1, 0, 0]
모든 [0, 1, 0]
사람 [0, 0, 1]
x
y
z
세상
모든
사람
n개의 단어는 n차원의 벡터로 표현
단어 벡터가 sparse해서 단어가 가지는 ‘의미‘를 벡터 공간에 표현 불가능
20.
Word embedding –Word2Vec
• Word2vec (word to vector) 알고리즘: 자연어 (특히, 단어) 의 의미를 벡터 공간에 임베딩
• 한 단어의 주변 단어들을 통해, 그 단어의 의미를 파악
جرو
كلب
컴퓨터가 볼 때, 자연어는 우리가 보는 아랍어처럼 ‘기호'로만 보일 뿐!
21.
Word embedding –Word2Vec
• Word2vec (word to vector) 알고리즘: 자연어 (특히, 단어) 의 의미를 벡터 공간에 임베딩
• 한 단어의 주변 단어들을 통해, 그 단어의 의미를 파악
جرو
كلب
가 멍멍! 하고 짖었다.
가 멍멍! 하고 짖었다.
جرو와 كلب가 무슨 뜻인지는 모르겠지만, 주변 단어 형태가 비슷하니 의미도 비슷할 것이다!
(개)
(강아지)
22.
Word embedding –Word2Vec
• Word2vec 알고리즘은 주변부의 단어를 예측하는 방식으로 학습 (Skip-gram 방식)
• 단어에 대한 dense vector를 얻을 수 있음
“Duct tape may works anywhere”
“duct”
“may”
“tape”
“work”
“anywhere”
Word One-hot-vector
“duct” [1, 0, 0, 0, 0]
“tape” [0, 1, 0, 0, 0]
“may” [0, 0, 1, 0, 0]
“work” [0, 0, 0, 1, 0]
“anywhere” [0, 0, 0, 0, 1] tape의 word vector
1.0
0.0
0.0
0.0
0.0
0.0
23.
Word embedding –Word2Vec
• Word embedding의 방법론에 따른 특징
Sparse representation Dense representation
• One-hot encoding
• n개의 단어에 대한 n차원의 벡터
• 단어가 커질 수록 무한대 차원의 벡터가 생성
• 주로 신경망의 입력단에 사용 (신경망이 임베
딩 과정을 대체. e.g. tf.layers.Embedding)
• 의미 유추 불가능
• 차원의 저주 (curse of dimensionality): 차원
이 무한대로 커지면 정보 추출이 어려워짐
• One-hot vector의 차원 축소를 통해 특징을
분류하고자 하는 접근도 있음
• Word embedding
• 한정된 차원으로 표현 가능
• 의미 관계 유추 가능
• 비지도 학습으로 단어의 의미 학습 가능
Word embedding –Word2Vec
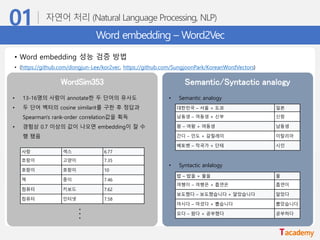
• Word embedding 성능 검증 방법
• (https://github.com/dongjun-Lee/kor2vec, https://github.com/SungjoonPark/KoreanWordVectors)
WordSim353 Semantic/Syntactic analogy
사랑 섹스 6.77
호랑이 고양이 7.35
호랑이 호랑이 10
책 종이 7.46
컴퓨터 키보드 7.62
컴퓨터 인터넷 7.58
• 13-16명의 사람이 annotate한 두 단어의 유사도
• 두 단어 벡터의 cosine similarit를 구한 후 정답과
Spearman's rank-order correlation값을 획득
• 경험상 0.7 이상의 값이 나오면 embedding이 잘 수
행 됐음
...
• Semantic analogy
• Syntactic anlalogy
대한민국 – 서울 + 도쿄 일본
남동생 – 여동생 + 신부 신랑
왕 – 여왕 + 여동생 남동생
간디 – 인도 + 갈릴레이 이탈리아
베토벤 – 작곡가 + 단테 시인
밥 – 밥을 + 물을 물
여행이 – 여행은 + 흡연은 흡연이
보도했다 – 보도했습니다 + 알았습니다 알았다
마시다 – 마셨다 + 뽑습니다 뽑았습니다
오다 – 왔다 + 공부했다 공부하다
Word embedding –Word2Vec
• 단어의 subword information 무시 (e.g. 서울 vs 서울시 vs 고양시)
• Our of vocabulary (OOV)에서 적용 불가능
• 단어간의 유사도 측정에 용이
• 단어간의 관계 파악에 용이
• 벡터 연산을 통한 추론이 가능 (e.g. 한국 – 서울 + 도쿄 = ?)
장점
단점
• 단어가 가지는 의미 자체를 다차원 공간에
‘벡터화’하는 것
• 중심 단어의 주변 단어들을 이용해 중심단
어를 추론하는 방식으로 학습
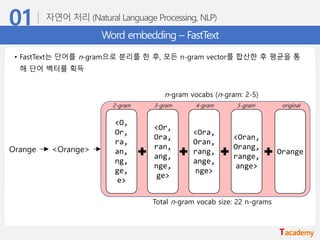
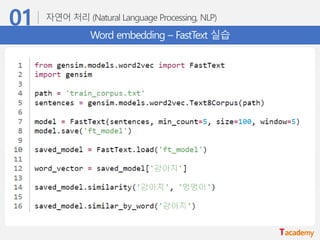
Word embedding –FastText
• 기존의 word2vec과 유사하나, 단어를 n-gram으로 나누어 학습을 수행
• n-gram의 범위가 2-5일 때, 단어를 다음과 같이 분리하여 학습함
“assumption” = {as, ss, su, ….., ass, ssu, sum, ump, mpt,….., ption, assumption}
• 이 때, n-gram으로 나눠진 단어는 사전에 들어가지 않으며, 별도의 n-gram vector를 형성함
Training
• 입력 단어가 vocabulary에 있을 경우, word2vec과 마찬가지로 해당 단어의 word vector를 return함
• 만약 OOV일 경우, 입력 단어의 n-gram vector들의 합산을 return함
Testing
• Facebook research에서 공개한 open source library
(https://research.fb.com/fasttext/, fasttext.cc)
• C++11
Fasttext
31.
Word embedding –FastText
Orange <Orange>
n-gram vocabs (n-gram: 2-5)
<O,
Or,
ra,
an,
ng,
ge,
e>
<Or,
Ora,
ran,
ang,
nge,
ge>
<Ora,
Oran,
rang,
ange,
nge>
<Oran,
Orang,
range,
ange>
Orange
2-gram 3-gram 4-gram 5-gram original
Total n-gram vocab size: 22 n-grams
• FastText는 단어를 n-gram으로 분리를 한 후, 모든 n-gram vector를 합산한 후 평균을 통
해 단어 벡터를 획득
32.
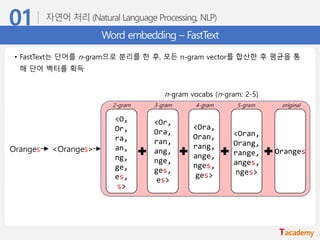
Word embedding –FastText
• FastText는 단어를 n-gram으로 분리를 한 후, 모든 n-gram vector를 합산한 후 평균을 통
해 단어 벡터를 획득
Oranges <Oranges>
n-gram vocabs (n-gram: 2-5)
<O,
Or,
ra,
an,
ng,
ge,
es,
s>
<Or,
Ora,
ran,
ang,
nge,
ges,
es>
<Ora,
Oran,
rang,
ange,
nges,
ges>
<Oran,
Orang,
range,
anges,
nges>
Oranges
2-gram 3-gram 4-gram 5-gram original
33.
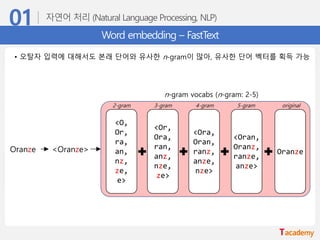
Word embedding –FastText
• 오탈자 입력에 대해서도 본래 단어와 유사한 n-gram이 많아, 유사한 단어 벡터를 획득 가능
Oranze <Oranze>
n-gram vocabs (n-gram: 2-5)
<O,
Or,
ra,
an,
nz,
ze,
e>
<Or,
Ora,
ran,
anz,
nze,
ze>
<Ora,
Oran,
ranz,
anze,
nze>
<Oran,
Oranz,
ranze,
anze>
Oranze
2-gram 3-gram 4-gram 5-gram original
34.
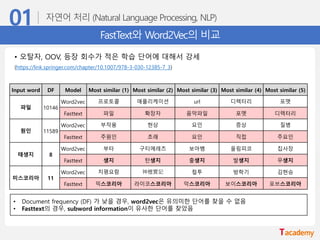
FastText와 Word2Vec의 비교
Inputword DF Model Most similar (1) Most similar (2) Most similar (3) Most similar (4) Most similar (5)
파일 10146
Word2vec 프로토콜 애플리케이션 url 디렉터리 포맷
Fasttext 파일 확장자 음악파일 포멧 디렉터리
원인 11589
Word2vec 부작용 현상 요인 증상 질병
Fasttext 주원인 초래 요인 직접 주요인
태생지 8
Word2vec 부타 구티에레즈 보아뱀 올림피코 집사장
Fasttext 생지 탄생지 출생지 발생지 무생지
미스코리아 11
Word2vec 치평요람 神檀實記 컬투 방학기 김현승
Fasttext 믹스코리아 라이코스코리아 악스코리아 보이스코리아 포브스코리아
• Document frequency (DF) 가 낮을 경우, word2vec은 유의미한 단어를 찾을 수 없음
• Fasttext의 경우, subword information이 유사한 단어를 찾았음
• 오탈자, OOV, 등장 회수가 적은 학습 단어에 대해서 강세
(https://link.springer.com/chapter/10.1007/978-3-030-12385-7_3)
35.
Advanced FastText 모델
•오탈자, OOV, 등장 회수가 적은 학습 단어에 대해서 강세
(https://link.springer.com/chapter/10.1007/978-3-030-12385-7_3)
Input word FastText Model Most similar words in range of top 3
페날티
(Penalty)
OOV word
Baseline
리날디
(Rinaldi)
페레티
(Ferretti)
마셰티
(Machete)
Jamo-advanced
페널티골
(Penalty goal)
페널티
(Penalty)
드록바
(Drogba)
나푸탈렌
(Naphthalene)
OOV word
Baseline
야렌
(Yaren)
콜루바라
(Kolubara)
몽클로아아라바카
(Moncloa-Aravaca)
Jamo-advanced
나프탈렌
(Naphthalene)
테레프탈산
(Terephthalic acid)
아디프산
(Adipic acid)
스태이크
(Steak)
OOV word
Baseline
스태너프
(Stanhope)
스태너드
(Stannard)
화이트스네이크
(White Snake)
Jamo-advanced
롱테이크
(Long take)
비프스테이크
(Beefsteak)
스테이크
(Steak)
Word embedding의 활용
•다른 자연어처리 모델의 입력으로 사용
(e.g. 학습 데이터의 양이 매우 적은 감성분석을 수행할 경우, 학습 데이터만으로는 특성 추출 불가능)
• 토픽 키워드 (https://www.adams.ai/apiPage?deeptopicrank)
BERT 관련 토픽 키워드 추출
38.
Word embedding 방식의한계점
• Word2Vec이나 FastText와 같은 word embedding 방식은 동형어, 다의어 등에 대해선
embedding 성능이 좋지 못하다는 단점이 있음
• 주변 단어를 통해 학습이 이루어지기 때문에, ‘문맥’을 고려할 수 없음
Account
1) I account him to be my friend ~라고 생각하다
2) He is angry on account of being excluded from the invitation 이유, 근거
3) I have an account with the First Nationa Bank ~때문에
4) The police wrote an account of the accident 보고서
5) Your check has been propertly credicted, and your account in now full? 계좌
모델이란?
• 모델의 종류
•일기예보 모델, 데이터 모델, 비즈니스 모델, 물리 모델, 분자 모델 등
• 모델의 특징
• 자연 법칙을 컴퓨터로 모사함으로써 시뮬레이션이 가능
• 이전 state를 기반으로 미래의 state를 예측할 수 있음
(e.g. 습도와 바람 세기 등으로 내일 날씨 예측)
• 즉, 미래의 state를 올바르게 예측하는 방식으로 모델 학습이 가능함
41.
언어 모델
• ‘자연어’의법칙을 컴퓨터로 모사한 모델 → 언어 ‘모델’
• 주어진 단어들로부터 그 다음에 등장한 단어의 확률을 예측하는 방식으로 학습 (이전 state로 미래 state를 예측)
• 다음의 등장할 단어를 잘 예측하는 모델은 그 언어의 특성이 잘 반영된 모델이자, 문맥을 잘 계산하는 좋은 언어 모델
42.
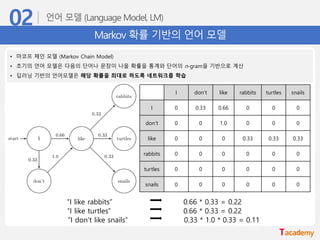
Markov 확률 기반의언어 모델
• 마코프 체인 모델 (Markov Chain Model)
• 초기의 언어 모델은 다음의 단어나 문장이 나올 확률을 통계와 단어의 n-gram을 기반으로 계산
• 딥러닝 기반의 언어모델은 해당 확률을 최대로 하도록 네트워크를 학습
I don’t like rabbits turtles snails
I 0 0.33 0.66 0 0 0
don’t 0 0 1.0 0 0 0
like 0 0 0 0.33 0.33 0.33
rabbits 0 0 0 0 0 0
turtles 0 0 0 0 0 0
snails 0 0 0 0 0 0
“I like rabbits”
“I like turtles”
“I don’t like snails”
0.66 * 0.33 = 0.22
0.66 * 0.33 = 0.22
0.33 * 1.0 * 0.33 = 0.11
43.
Recurrent Neural Network(RNN) 기반의 언어 모델
• RNN은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이루는(directed cycle) 인공신경망의 한 종류
• 이전 state 정보가 다음 state를 예측하는데 사용됨으로써, 시계열 데이터 처리에 특화
Current step input
Predicted next step
output
Current step
hidden layer
Previous step
hidden layer
One-hot-vector
기본적인 RNN의 구조 다음 문자를 학습하는 RNN encoder
* RNN와 LSTM을 이해해보자!
(https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/)
44.
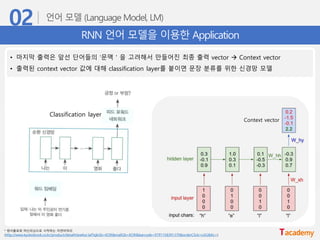
RNN 언어 모델을이용한 Application
• 마지막 출력은 앞선 단어들의 ‘문맥'을 고려해서 만들어진 최종 출력 vector → Context vector
• 출력된 context vector 값에 대해 classification layer를 붙이면 문장 분류를 위한 신경망 모델
Classification layer
Context vector
* 텐서플로와 머신러닝으로 시작하는 자연어처리
(http://www.kyobobook.co.kr/product/detailViewKor.laf?ejkGb=KOR&mallGb=KOR&barcode=9791158391379&orderClick=LAG&Kc=)
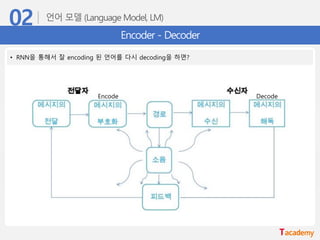
RNN 모델 기반의Seq2Seq
• Seq2Seq (Sequence to Sequence)
• Encoder layer: RNN 구조를 통해 Context vector 를 획득
• Decoder layer: 획득된 Context vector를 입력으로 출력을 예측
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
47.
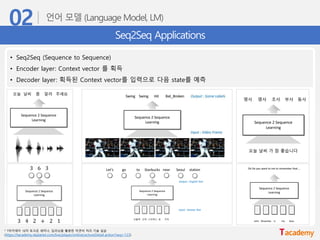
Seq2Seq Applications
• Seq2Seq(Sequence to Sequence)
• Encoder layer: Context vector 를 획득
• Decoder layer: 획득된 Context vector를 입력으로 다음 state를 예측
* T아카데미 16차 토크온 세미나, 딥러닝을 활용한 자연어 처리 기술 실습
(https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=123)
RNN 의 구조적문제점
• 입력 sequence의 길이가 매우 긴 경우, 처음에 나온 token에 대한 정보가 희석
• 고정된 context vector 사이즈로 인해 긴 sequence에 대한 정보를 함축하기 어려움
• 모든 token이 영향을 미치니, 중요하지 않은 token도 영향을 줌
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
Attention의 탄생!
50.
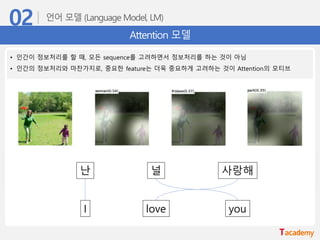
Attention 모델
• 인간이정보처리를 할 때, 모든 sequence를 고려하면서 정보처리를 하는 것이 아님
• 인간의 정보처리와 마찬가지로, 중요한 feature는 더욱 중요하게 고려하는 것이 Attention의 모티브
love
널
you
사랑해
I
난
51.
Attention 모델
• 기존Seq2Seq에서는 RNN의 최종 output인 Context vector만을 활용
• Attention에서는 인코더 RNN 셀의 각각 output을 활용
• Decoder에서는 매 step마다 RNN 셀의 output을 이용해 dynamic하게 Context vector를 생성
이 정보를
활용하자!
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
52.
Attention 모델
* [딥러닝기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• 기존 RNN 모델에서 시작
53.
Attention 모델
* [딥러닝기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• 기존 RNN 모델에서 시작
• RNN 셀의 각 output들을 입력으로 하는 Feed forward fully connected layer
• 해당 layer의 output을 각 RNN 셀의 Score로 결정
Feed forward
Fully connected layer
Score
54.
Attention 모델
* [딥러닝기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• 출력된 score에 Softmax를 취함으로써 0-1 사이의 값으로 변환
• 해당 값을 Attention weight로 결정
Feed forward
Fully connected layer
55.
Attention 모델
* [딥러닝기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• 출력된 score에 Softmax를 취함으로써 0-1 사이의 값으로 변환
• 해당 값을 Attention weight로 결정
• Attention weight와 hidden state를 곱해서 Context vector 획득
56.
Attention 모델
* [딥러닝기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• Decoder의 hidden state가 attention weight 계산에 영향을 줌
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Query인 ‘난’ 과 ‘I’, ‘love’, ‘you’와의 상관관계 조정 필요
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
Key, Value
Query
57.
Attention 모델
* [딥러닝기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• Decoder의 hidden state가 attention weight 계산에 영향을 줌
58.
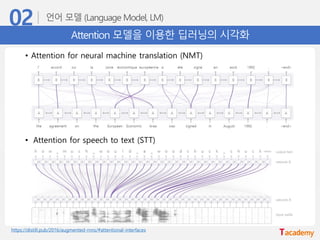
Attention 모델을 이용한딥러닝의 시각화
• Attention for neural machine translation (NMT)
• Attention for speech to text (STT)
https://distill.pub/2016/augmented-rnns/#attentional-interfaces
59.
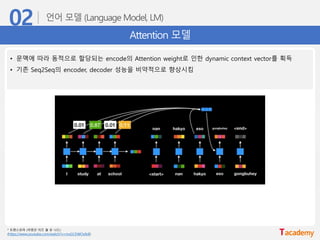
Attention 모델
• 문맥에따라 동적으로 할당되는 encode의 Attention weight로 인한 dynamic context vector를 획득
• 기존 Seq2Seq의 encoder, decoder 성능을 비약적으로 향상시킴
* 트랜스포머 (어텐션 이즈 올 유 니드)
(https://www.youtube.com/watch?v=mxGCEWOxfe8)
60.
Attention 모델
• 문맥에따라 동적으로 할당되는 encode의 Attention weight로 인한 dynamic context vector를 획득
• 기존 Seq2Seq의 encoder, decoder 성능을 비약적으로 향상시킴
• 하지만, 여전히 RNN이 순차적으로 연산이 이뤄짐에 따라 연산 속도가 느림
그냥 RNN을 없애는건 어떨까?
* 트랜스포머 (어텐션 이즈 올 유 니드)
(https://www.youtube.com/watch?v=mxGCEWOxfe8)
61.
Self-attention 모델
• Attentionis all you need!
• RNN을 encoder와 decoder에서 제거
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
62.
Self-attention 모델
• Attentionis all you need!
• RNN을 encoder와 decoder에서 제거
RNN + attention에 적용 된 attention은 decoder가
해석하기에 가장 적합한 weight를 찾고자 노력
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
63.
Self-attention 모델
• Attentionis all you need!
• RNN을 encoder와 decoder에서 제거
RNN + attention에 적용 된 attention은 decoder가
해석하기에 가장 적합한 weight를 찾고자 노력
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
Attention이 decoder가 아니라, input인 값을
가장 잘 표현할 수 있도록 학습하면?
→ 자기 자신을 가장 잘 표현할 수 있는 좋은 embedding
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
64.
Self-attention 모델
• Attentionis all you need!
• RNN을 encoder와 decoder에서 제거
RNN + attention에 적용 된 attention은 decoder가
해석하기에 가장 적합한 weight를 찾고자 노력
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
Attention이 decoder가 아니라, input인 값을
가장 잘 표현할 수 있도록 학습하면?
→ 자기 자신을 가장 잘 표현할 수 있는 좋은 embedding
Self-attention 모델의 탄생!
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
65.
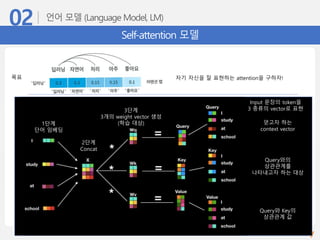
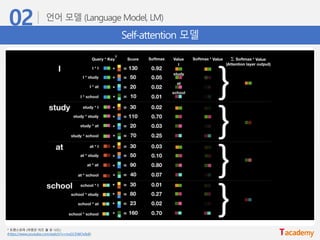
Self-attention 모델
자기 자신을잘 표현하는 attention을 구하자!목표
1단계
단어 임베딩
2단계
Concat
3단계
3개의 weight vector 생성
(학습 대상) 얻고자 하는
context vector
Query와의
상관관계를
나타내고자 하는 대상
Query와 Key의
상관관계 값
Input 문장의 token을
3 종류의 vector로 표현
66.
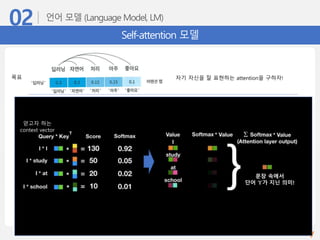
Self-attention 모델
자기 자신을잘 표현하는 attention을 구하자!목표
얻고자 하는
context vector
Input 문장의 token을
3 종류의 vector로 표현
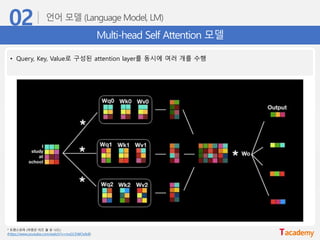
Multi-head Self Attention모델
• Query, Key, Value로 구성된 attention layer를 동시에 여러 개를 수행
* 트랜스포머 (어텐션 이즈 올 유 니드)
(https://www.youtube.com/watch?v=mxGCEWOxfe8)
70.
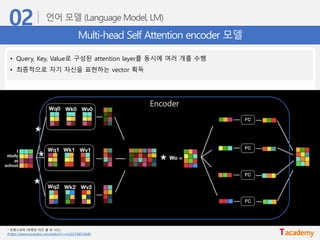
Multi-head Self Attentionencoder 모델
• Query, Key, Value로 구성된 attention layer를 동시에 여러 개를 수행
• 최종적으로 자기 자신을 표현하는 vector 획득
Encoder
* 트랜스포머 (어텐션 이즈 올 유 니드)
(https://www.youtube.com/watch?v=mxGCEWOxfe8)
71.
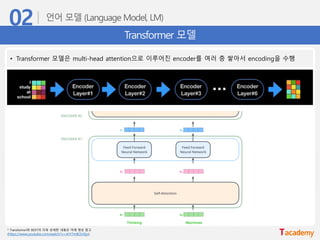
Transformer 모델
• Transformer모델은 multi-head attention으로 이루어진 encoder를 여러 층 쌓아서 encoding을 수행
* Transformer와 BERT의 더욱 상세한 내용은 아래 영상 참고
(https://www.youtube.com/watch?v=xhY7m8QVKjo)
Bi-directional Encoder Representationsfrom Transformers
• BERT는 bi-directional Transformer로 이루어진 언어모델
• 잘 만들어진 BERT 언어모델 위에 1개의 classification layer만 부착하여 다양한 NLP task를 수행
• 영어권에서 11개의 NLP task에 대해 state-of-the-art (SOTA) 달성
….
James Marshall "Jimi" Hendrix
was an American rock guitarist,
singer, and songwriter.
….
Who is Jimi Hendrix?
Pre-trained BERT
1 classification layer for Fine-turning
"Jimi" Hendrix was an American rock guitarist, singer, and
songwriter. SQuAD v1.1 dataset leaderboard
74.
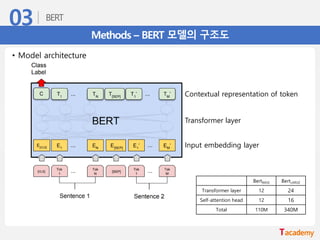
Methods – BERT모델의 구조도
Input embedding layer
Transformer layer
Contextual representation of token
• Model architecture
BertBASE BertLARGE
Transformer layer 12 24
Self-attention head 12 16
Total 110M 340M
75.
Methods – BERT모델 학습 데이터
• 학습 코퍼스 데이터
• BooksCorpus (800M words)
• English Wikipedia (2,500M words without lists, tables and headers)
• 30,000 token vocabulary
• 데이터의 tokenizing
• WordPiece tokenizing
He likes playing → He likes play ##ing
• 입력 문장을 tokenizing하고, 그 token들로 ‘token sequence’를 만들어 학습에 사용
• 2개의 token sequence가 학습에 사용
Example of two sentences token sequence
Classification
label token
Next sentence or Random chosen sentence (50%)
76.
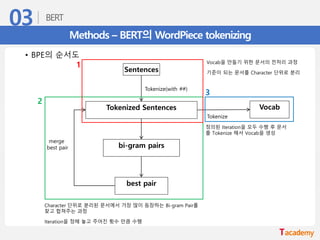
Methods – BERT의WordPiece tokenizing
• Byte Pair Encoding (BPE) 알고리즘 이용
• 빈도수에 기반해 단어를 의미 있는 패턴(Subword)으로 잘라서 tokenizing
W2V vocabs
고양경찰서
고양시
종로경찰서
경찰
경찰서
경찰관
경찰청
...
BPE vocabs
...
고양 ##경찰 ##서
##시
종로 ##경찰 ##서
경찰
경찰 ##서
경찰 ##관
경찰 ##청
...
고양
##경찰
##서
##시
경찰
##관
##청
wordPiece와 BPE의 차이점
(https://ai-information.blogspot.com/2019/02/word-piece-embedding.html)
77.
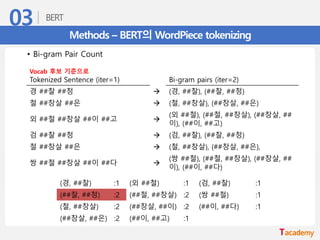
Methods – BERT의WordPiece tokenizing
• BPE의 순서도
Tokenized Sentences
bi-gram pairs
Sentences
Tokenize(with ##)
best pair
merge
best pair
Vocab
Tokenize
1
2
3
Vocab을 만들기 위한 문서의 전처리 과정
기준이 되는 문서를 Character 단위로 분리
Character 단위로 분리된 문서에서 가장 많이 등장하는 Bi-gram Pair를
찾고 합쳐주는 과정
Iteration을 정해 놓고 주어진 횟수 만큼 수행
정의된 Iteration을 모두 수행 후 문서
를 Tokenize 해서 Vocab을 생성
78.
Methods – BERT의WordPiece tokenizing
Sentence Tokenized Sentence (iter=0)
경찰청 →경 찰 청 → 경 ##찰 ##청
철창살은 →철 창 살 은 → 철 ##창 ##살 ##은
외철창살이고 →외 철 창 살 이 고 → 외 ##철 ##창 ##살 ##이 ##고
검찰청 →검 찰 청 → 검 ##찰 ##청
철창살은 →철 창 살 은 → 철 ##창 ##살 ##은
쌍철창살이다 →쌍 철 창 살 이 다 → 쌍 ##철 ##창 ##살 ##이 ##다
• Tokenize
경찰청 철창살은 외철창살이고 검찰청 철창살은 쌍철창살이다
• 같은 글자라고 맨 앞에 나오는 것과 아닌 것에는 차이가 있다고 가정
• BERT의 경우 뒷단어에 ‘##’을 붙여서 구별 e.g.) ‘철’ ≠ ‘##철’ , ‘철창살’ ≠ ‘##철창살’
79.
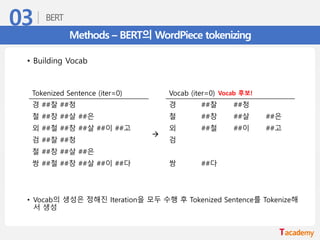
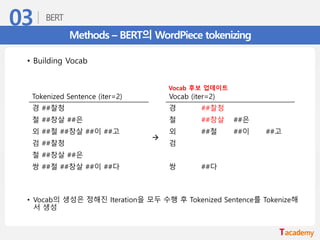
Methods – BERT의WordPiece tokenizing
• Building Vocab
• Vocab의 생성은 정해진 Iteration을 모두 수행 후 Tokenized Sentence를 Tokenize해
서 생성
Tokenized Sentence (iter=0) Vocab (iter=0)
경 ##찰 ##청
→
경 ##찰 ##청
철 ##창 ##살 ##은 철 ##창 ##살 ##은
외 ##철 ##창 ##살 ##이 ##고 외 ##철 ##이 ##고
검 ##찰 ##청 검
철 ##창 ##살 ##은
쌍 ##철 ##창 ##살 ##이 ##다 쌍 ##다
Vocab 후보!
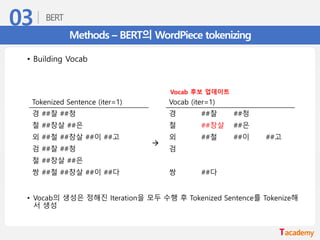
Methods – BERT의WordPiece tokenizing
• Building Vocab
• Vocab의 생성은 정해진 Iteration을 모두 수행 후 Tokenized Sentence를 Tokenize해
서 생성
Tokenized Sentence (iter=1) Vocab (iter=1)
경 ##찰 ##청
→
경 ##찰 ##청
철 ##창살 ##은 철 ##창살 ##은
외 ##철 ##창살 ##이 ##고 외 ##철 ##이 ##고
검 ##찰 ##청 검
철 ##창살 ##은
쌍 ##철 ##창살 ##이 ##다 쌍 ##다
Vocab 후보 업데이트
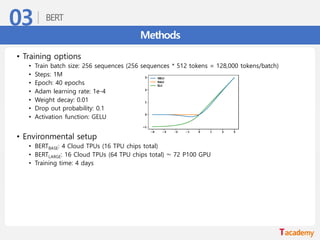
Methods – BERT의WordPiece tokenizing
• Merge Best pair
• Best pair가 여러 개여도 하나만 선택
Best Pair: ##찰 ##청 → ##찰청
Tokenized Sentence (iter=1) Tokenized Sentence (iter=2)
경 ##찰 ##청 → 경 ##찰청
철 ##창살 ##은 → 철 ##창살 ##은
외 ##철 ##창살 ##이 ##고 → 외 ##철 ##창살 ##이 ##고
검 ##찰 ##청 → 검 ##찰청
철 ##창살 ##은 → 철 ##창살 ##은
쌍 ##철 ##창살 ##이 ##다 → 쌍 ##철 ##창살 ##이 ##다
85.
Methods – BERT의WordPiece tokenizing
• Building Vocab
• Vocab의 생성은 정해진 Iteration을 모두 수행 후 Tokenized Sentence를 Tokenize해
서 생성
Tokenized Sentence (iter=2) Vocab (iter=2)
경 ##찰청
→
경 ##찰청
철 ##창살 ##은 철 ##창살 ##은
외 ##철 ##창살 ##이 ##고 외 ##철 ##이 ##고
검 ##찰청 검
철 ##창살 ##은
쌍 ##철 ##창살 ##이 ##다 쌍 ##다
Vocab 후보 업데이트
Methods – BERT의WordPiece tokenizing
• Merge Best pair
• 3 글자 이상의 패턴도 Iteration이 진행되면서 나타날 수 있음
Best Pair: 철 ##창살 → 철창살
Tokenized Sentence (iter=2) Tokenized Sentence (iter=3)
경 ##찰 ##청 → 경 ##찰청
철 ##창살 ##은 → 철창살 ##은
외 ##철 ##창살 ##이 ##고 → 외 ##철 ##창살 ##이 ##고
검 ##찰 ##청 → 검 ##찰청
철 ##창살 ##은 → 철창살 ##은
쌍 ##철 ##창살 ##이 ##다 → 쌍 ##철 ##창살 ##이 ##다
88.
Methods – BERT의WordPiece tokenizing
• Building Vocab
• Vocab의 생성은 정해진 Iteration을 모두 수행 후 Tokenized Sentence를 Tokenize해
서 생성(매 iteration 마다 Vocab을 생성하는 것이 아님)
Tokenized Sentence (iter=3) Vocab (iter=3)
경 ##찰청
→
경
##찰
청
철창살 ##은 철창살 ##은
외 ##철 ##창살 ##이 ##고 외 ##철
##창
살
##이 ##고
검 ##찰청 검
철창살 ##은
쌍 ##철 ##창살 ##이 ##다 쌍 ##다
Vocab에 저장!
89.
Methods – BERT의WordPiece tokenizing
• BERT tokenization 예시
• BPE로 subword로 분리했음에도 불구하고 vocab에 존재하지 않는 단어는 [UNK] 토큰으로 변환
90.
Methods – Masking기법
• 데이터의 tokenizing
• Masked language model (MLM): input token을 일정 확률로 masking
Original token sequence
Randomly chosen token (15%)
Masking
[MASK]
Randomly replacing
hairy
Unchanging
80% 10% 10%
Example of two sentences token sequence
[MASK]
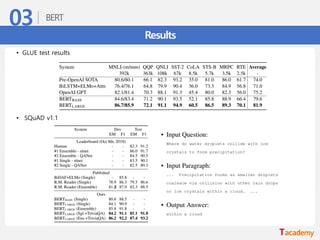
BERT 적용 실험– 감성 분석
• 네이버 영화 리뷰 코퍼스 (https://github.com/e9t/nsmc) 로 감성 분석 진행
• 학습: 150,000 문장 / 평가: 50,000 문장 (긍정: 1, 부정: 0)
label sentence
0 뭐야 이 평점들은.... 나쁘진 않지만 10점 짜리는 더더욱 아니잖아
0 지루하지는 않은데 완전 막장임... 돈주고 보기에는....
0 3D만 아니었어도 별 다섯 개 줬을텐데.. 왜 3D로 나와서 제 심기를 불편하게 하죠??
1 음악이 주가 된, 최고의 음악영화
0 진정한 쓰레기
0 마치 미국애니에서 튀어나온듯한 창의력없는 로봇디자인부터가,고개를 젖게한다
...
모델 Accuracy
KoNLPy + DenseNet (Keras) 85.3
Kakao BERT-Kor + khaiii 88.8
BERT Multi-lingual pretrained model 88.3
98.
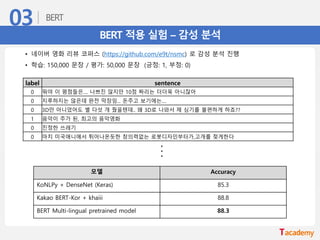
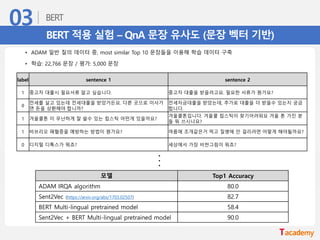
BERT 적용 실험– QnA 문장 유사도 (이진 분류 기반)
• 디지털 동반자 패러프레이징 질의 문장 데이터를 이용하여 질문-질문 데이터 생성 및 학습
• 학습: 3,401 문장 쌍 (유사 X: 1,700개, 유사 O: 1,701개)
• 평가: 1,001 문장 쌍 (유사 X: 500개, 유사 O: 501개)
모델 Accuracy
BERT Multi-lingual pretrained model 98.3
label sentence 1 sentence 2
0 포화지방산이 많은 음식은?
아토피 피부염이 있는 아기를 씻길 때 좋은 비누는 무엇인
가요?
1 임신 29주 태아의 신장은 어떻습니까? 임신 29주일 때 태아의 크기는?
0
산모가 술을 마셨을 경우 모유 수유는 언제 하는 것이 좋
은가요?
임산부가 입덧을 할 때 비타민B6을 왜 먹나요?...
99.
BERT 적용 실험– QnA 문장 유사도 (이진 분류 기반)
• Saltlux ADAM 일반 질의 데이터를 이용해 IRQA 모사 데이터 구축
• 500 문장에 대한 BERT semantic search (https://github.com/hanxiao/bert-as-service)
중고차 대출시 필요서류 알고 싶습니다.
[0.2132, 0.1544, 0.8163 …. ] 768차원
전세자금대출을 받았는데, 추가로 대출을 더 받을수 있는지 궁금합니다.
겨울쿨톤입니다. 겨울쿨 립스틱이 찾기어려워요 겨울 톤 가진 분
들 뭐 쓰시나요?
여름에 조개같은거 먹고 질병에 안 걸리려면 어떻게 해야될까요?
중고차 대출을 받을려고요. 필요한 서류가 뭔가요?
...
1만 문장과 비교
...
500 문장 테스트
모델 Top1 Accuracy
ADAM IRQA algorithm 80.0
Sent2Vec (https://arxiv.org/abs/1703.02507) 82.7
BERT Multi-lingual pretrained model 58.4
100.
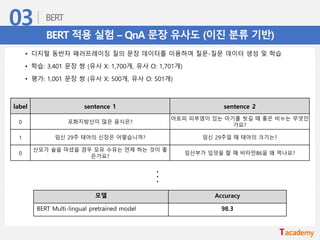
BERT 적용 실험– QnA 문장 유사도 (문장 벡터 기반)
• Sent2Vec 이용, 500개 입력 문장과 가장 유사한 10개의 문장 후보 추출 (top 10개 이내 98% 존재)
• 10개 문장과 입력 문장을 BERT로 유사 유/무 비교 (이진 분류)
입력 문장 유사 문장 Cos similarity
무협소설 추천좀 해주세요
판타지소설 추천좀 해주세요 0.80263
고전문학 소설 추천해주세요 0.658433
현대문학 소설 추천해주세요 0.645056
대표적인 무협소설 뭐 있을까요? 0.634835
처음읽는데도 거부감이없고 흥미로운 무협소설 추천바
랍니다
0.632528
요새 재미있는 무협소설 뭐 있나요? 0.631053
PC게임 추천좀 해주세염 0.61363
고전문학 소설 읽을만한 소설 소개좀 해주세요 0.594516
현대문학 소설 읽을만한 소설 소개좀 해주세요 0.59369
패션잡지 추천 좀 해주세요 0.573995
101.
BERT 적용 실험– QnA 문장 유사도 (문장 벡터 기반)
• ADAM 일반 질의 데이터 중, most similar Top 10 문장들을 이용해 학습 데이터 구축
• 학습: 22,766 문장 / 평가: 5,000 문장
label sentence 1 sentence 2
1 중고차 대출시 필요서류 알고 싶습니다. 중고차 대출을 받을려고요. 필요한 서류가 뭔가요?
0
전세를 살고 있는데 전세대출을 받았거든요. 다른 곳으로 이사가
면 돈을 상환해야 합니까?
전세자금대출을 받았는데, 추가로 대출을 더 받을수 있는지 궁금
합니다.
1 겨울쿨톤 이 무난하게 잘 쓸수 있는 립스틱 어떤게 있을까요?
겨울쿨톤입니다. 겨울쿨 립스틱이 찾기어려워요 겨울 톤 가진 분
들 뭐 쓰시나요?
1 비브리오 패혈증을 예방하는 방법이 뭔가요? 여름에 조개같은거 먹고 질병에 안 걸리려면 어떻게 해야될까요?
0 디지털 디톡스가 뭐죠? 세상에서 가장 비싼그림이 뭐죠?
...
모델 Top1 Accuracy
ADAM IRQA algorithm 80.0
Sent2Vec (https://arxiv.org/abs/1703.02507) 82.7
BERT Multi-lingual pretrained model 58.4
Sent2Vec + BERT Multi-lingual pretrained model 90.0
102.
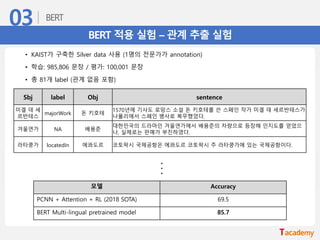
BERT 적용 실험– 관계 추출 실험
• KAIST가 구축한 Silver data 사용 (1명의 전문가가 annotation)
• 학습: 985,806 문장 / 평가: 100,001 문장
• 총 81개 label (관계 없음 포함)
Sbj label Obj sentence
미겔 데 세
르반테스
majorWork 돈 키호테
1570년에 기사도 로망스 소설 돈 키호테를 쓴 스페인 작가 미겔 데 세르반테스가
나폴리에서 스페인 병사로 복무했었다.
겨울연가 NA 배용준
대한민국의 드라마인 겨울연가에서 배용준의 차량으로 등장해 인지도를 얻었으
나, 실제로는 판매가 부진하였다.
라타쿵가 locatedIn 에콰도르 코토팍시 국제공항은 에콰도르 코토팍시 주 라타쿵가에 있는 국제공항이다.
...
모델 Accuracy
PCNN + Attention + RL (2018 SOTA) 69.5
BERT Multi-lingual pretrained model 85.7
103.
BERT 적용 실험– 개체명 인식
• 버트 모델에서 맨 마지막에 sequence tagging을 위한 layer를 쌓아서 구현
• 공개된 다국어 모델 활용, 음절 단위로 입력을 하도록 구현 (https://github.com/kyzhouhzau/BERT-NER)
<증권거래소:OG>에 주식을 상장하였다
증 ##권 ##거 ##래 ##소 ##에 주 ##식 ##을 상 ##장 ##하 ##였 ##다
B-OG I-OG I-OG I-OG I-OG O O O O O O O O O
104.
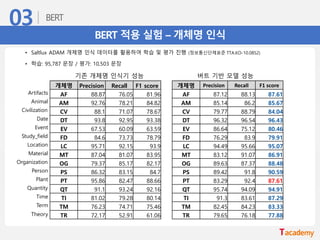
BERT 적용 실험– 개체명 인식
• Saltlux ADAM 개체명 인식 데이터를 활용하여 학습 및 평가 진행 (정보통신단체표준 TTA.KO-10.0852)
• 학습: 95,787 문장 / 평가: 10,503 문장
개체명 Precision Recall F1 score
AF 88.87 76.05 81.96
AM 92.76 78.21 84.82
CV 88.1 71.07 78.67
DT 93.8 92.95 93.38
EV 67.53 60.09 63.59
FD 84.6 73.73 78.79
LC 95.71 92.15 93.9
MT 87.04 81.07 83.95
OG 79.37 85.17 82.17
PS 86.32 83.15 84.7
PT 95.86 82.47 88.66
QT 91.1 93.24 92.16
TI 81.02 79.28 80.14
TM 76.23 74.71 75.46
TR 72.17 52.91 61.06
개체명 Precision Recall F1 score
AF 87.12 88.13 87.61
AM 85.14 86.2 85.67
CV 79.77 88.79 84.04
DT 96.32 96.54 96.43
EV 86.64 75.12 80.46
FD 76.29 83.9 79.91
LC 94.49 95.66 95.07
MT 83.12 91.07 86.91
OG 89.63 87.37 88.48
PS 89.42 91.8 90.59
PT 83.29 92.4 87.61
QT 95.74 94.09 94.91
TI 91.3 83.61 87.29
TM 82.45 84.23 83.33
TR 79.65 76.18 77.88
기존 개체명 인식기 성능 버트 기반 모델 성능
Artifacts
Animal
Civilization
Date
Event
Study_field
Location
Material
Organization
Person
Plant
Quantity
Time
Term
Theory
105.
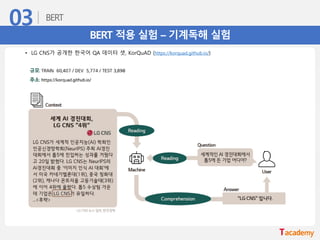
BERT 적용 실험– 기계독해 실험
• LG CNS가 공개한 한국어 QA 데이터 셋, KorQuAD (https://korquad.github.io/)
106.
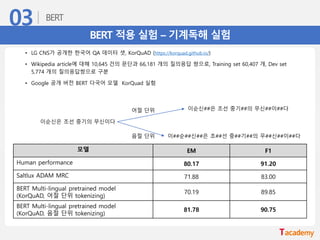
BERT 적용 실험– 기계독해 실험
• LG CNS가 공개한 한국어 QA 데이터 셋, KorQuAD (https://korquad.github.io/)
• Wikipedia article에 대해 10,645 건의 문단과 66,181 개의 질의응답 쌍으로, Training set 60,407 개, Dev set
5,774 개의 질의응답쌍으로 구분
• Google 공개 버전 BERT 다국어 모델 KorQuad 실험
모델 EM F1
Human performance 80.17 91.20
Saltlux ADAM MRC 71.88 83.00
BERT Multi-lingual pretrained model
(KorQuAD, 어절 단위 tokenizing)
70.19 89.85
BERT Multi-lingual pretrained model
(KorQuAD, 음절 단위 tokenizing)
81.78 90.75
이순신은 조선 중기의 무신이다
이순신##은 조선 중기##의 무신##이##다
이##순##신##은 조##선 중##기##의 무##신##이##다
어절 단위
음절 단위
107.
BERT 적용 실험– TOEIC 문제 풀이
https://github.com/graykode/toeicbert?fbclid=IwAR2hoCQE02CaR00m-
RZCHwQM_kYd1LgxxMSrucYSTtA52ZUhtvq5i_G2tFk
한국어 BERT 학습
•대용량 코퍼스 확보
• Dump wiki + news 색인 데이터 (30GB)
• 실험 장비
• V100 GPU
• 32GB
• 112TFLOPS
• 예상 소요시간: 약 8주
• Google 단일 TPU
• 64GB
• 180 TFLOPS
• V100 1대 속도의 약 8배
• 시간당 $4.50
• 예상 소요시간: 약 2주
모델 어절 수
Google 영어 BERT model 약 3.3억 어절
한국어 BERT 실험 약 3.4억 어절
114.
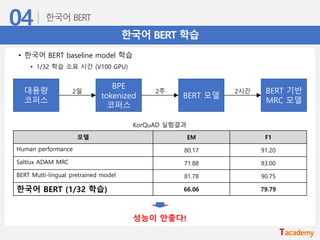
한국어 BERT 학습
•한국어 BERT baseline model 학습
• 1/32 학습 소요 시간 (V100 GPU)
KorQuAD 실험결과
모델 EM F1
Human performance 80.17 91.20
Saltlux ADAM MRC 71.88 83.00
BERT Multi-lingual pretrained model 81.78 90.75
한국어 BERT (1/32 학습) 66.06 79.79
대용량
코퍼스
BPE
tokenized
코퍼스
BERT 모델
BERT 기반
MRC 모델
2일 2주 2시간
성능이 안좋다!
115.
한국어 BERT 학습
•BERT 성능에 영향을 미치는 요인
• Corpus 사이즈
• Corpus 도메인
• Corpus tokenizing (어절, BPE, 형태소)
• Vocab 사이즈 (영어 model: 30,522 vocabs, 다국어 model: 119,547 vocabs)
모델 예제
어절
+ BPE (22만 vocab)
멕시코 ##부터 브라질 ##까지 그리고 카리브 해 섬 지역에서 발견된다 ##.
8 ##종으로 이루어져 있다.
날 ##씬 ##한 박쥐 ##류로 특이하게 ##도 긴 꼬리와 이름이 함 ##축하 ##는 바와 같이 깔 ##때
##기 모양의 귀를 갖고 있다.
어절
+ BPE (4만 vocab)
형태소 분리
멕시코 부터 브라질 까지 그리고 카리브 해 섬 지역 에서 발견 된 다 .
8 종 으로 이루어져 있 다 .
형태소 분리
+ 형태소 tag
멕시코/NNP 부터/JX 브라질/NNP 까지/JX 그리고/MAJ 카리브/NNP 해/NNG 섬/NNG 지역/NNG
에서/JKB 발견/NNG 된/XSV 다/EF ./SF
8/SN 종/NNG 으로/JKB 이루어져/VV 있/VX 다/EF ./SF
형태소 분리
+ 원형 복원
멕시코 부터 브라질 까지 그리고 카리브 해 섬 지역 에서 발견 되 ㄴ다 .
8 종 으로 이루어지 어 있 다 .
형태소 분리
+ 동사 원형 복원
멕시코 부터 브라질 까지 그리고 카리브 해 섬 지역 에서 발견 되다 .
8 종 으로 이루다 지다 있다.
116.
한국어 BERT 학습
•BERT 성능에 영향을 미치는 요인
• Corpus 사이즈
• Corpus 도메인
• Corpus tokenizing (어절, BPE, 형태소)
• Vocab 사이즈 (영어 model: 30,522 vocabs, 다국어 model: 119,547 vocabs)
모델 예제
어절
+ BPE (22만 vocab)
멕시코 ##부터 브라질 ##까지 그리고 카리브 해 섬 지역에서 발견된다 ##.
8 ##종으로 이루어져 있다.
날 ##씬 ##한 박쥐 ##류로 특이하게 ##도 긴 꼬리와 이름이 함 ##축하 ##는 바와 같이 깔 ##때
##기 모양의 귀를 갖고 있다.
어절
+ BPE (4만 vocab)
형태소 분리
멕시코 부터 브라질 까지 그리고 카리브 해 섬 지역 에서 발견 된 다 .
8 종 으로 이루어져 있 다 .
형태소 분리
+ 형태소 tag
멕시코/NNP 부터/JX 브라질/NNP 까지/JX 그리고/MAJ 카리브/NNP 해/NNG 섬/NNG 지역/NNG
에서/JKB 발견/NNG 된/XSV 다/EF ./SF
8/SN 종/NNG 으로/JKB 이루어져/VV 있/VX 다/EF ./SF
형태소 분리
+ 원형 복원
멕시코 부터 브라질 까지 그리고 카리브 해 섬 지역 에서 발견 되 ㄴ다 .
8 종 으로 이루어지 어 있 다 .
형태소 분리
+ 동사 원형 복원
멕시코 부터 브라질 까지 그리고 카리브 해 섬 지역 에서 발견 되다 .
8 종 으로 이루다 지다 있다.
BERT 논문
XLNet 논문
117.
BERT
실습
• 한국어 wikidump data를 이용해서 한국어
BERT를 직접 학습해보고, 학습된 모델을 이
용해 다양한 자연어처리를 실습해봅니다
118.
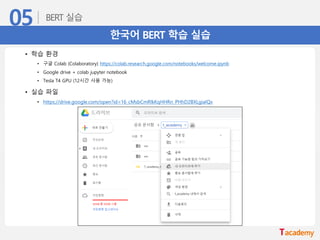
한국어 BERT 학습실습
• 학습 환경
• 구글 Colab (Colaboratory) https://colab.research.google.com/notebooks/welcome.ipynb
• Google drive + colab jupyter notebook
• Tesla T4 GPU (12시간 사용 가능)
• 실습 파일
• https://drive.google.com/open?id=16_cMsbCmRlkKqHHRn_PHhD2BXLgiaIQx
119.
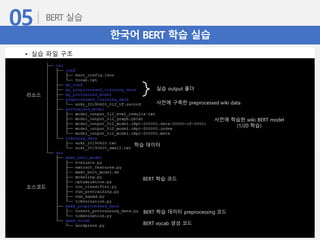
한국어 BERT 학습실습
• 실습 파일 구조
리소스
소스코드
실습 output 폴더
사전에 구축한 preprocessed wiki data
사전에 학습한 wiki BERT model
(1/20 학습)
학습 데이터
BERT 학습 코드
BERT 학습 데이터 preprocessing 코드
BERT vocab 생성 코드
120.
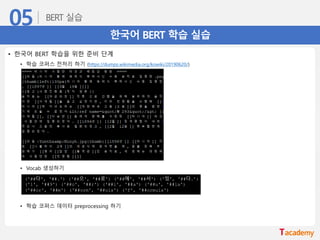
한국어 BERT 학습실습
• 한국어 BERT 학습을 위한 준비 단계
• 학습 코퍼스 전처리 하기 (https://dumps.wikimedia.org/kowiki/20190620/)
• Vocab 생성하기
• 학습 코퍼스 데이터 preprocessing 하기
('##다', '##.') ('##으', '##로') ('##에', '##서') ('있', '##다.’)
('1', '##9') ('##o', '##r') ('##l', '##a') ('##u', '##la')
('##or', '##m') ('##orm', '##ula') ('f', '##ormula')
한국어 BERT 학습실습
• 학습된 한국어 BERT로 KorQuAD 및 감성 데이터 학습 테스트
123.
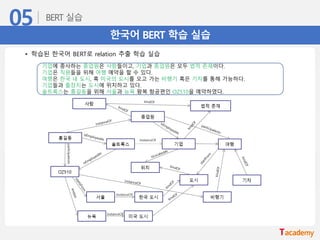
한국어 BERT 학습실습
• 학습된 한국어 BERT로 relation 추출 학습 실습
기업에 종사하는 종업원은 사람들이고, 기업과 종업원은 모두 법적 존재이다.
기업은 직원들을 위해 여행 예약을 할 수 있다.
여행은 한국 내 도시, 혹 미국의 도시를 오고 가는 비행기 혹은 기차를 통해 가능하다.
기업들과 출장지는 도시에 위치하고 있다.
솔트룩스는 홍길동을 위해 서울과 뉴욕 왕복 항공편인 OZ510을 예약하였다.














![Word embedding – Word2Vec
• 자연어를 어떻게 좌표평면 위에 표현할 수 있을까?
• 가장 단순한 표현 방법은 one-hot encoding 방식 → Sparse representation
세상 모든 사람
단어 Vector
세상 [1, 0, 0]
모든 [0, 1, 0]
사람 [0, 0, 1]
x
y
z
세상
모든
사람
n개의 단어는 n차원의 벡터로 표현
단어 벡터가 sparse해서 단어가 가지는 ‘의미‘를 벡터 공간에 표현 불가능](https://image.slidesharecdn.com/bert-200511073637/85/BERT-19-320.jpg)


![Word embedding – Word2Vec
• Word2vec 알고리즘은 주변부의 단어를 예측하는 방식으로 학습 (Skip-gram 방식)
• 단어에 대한 dense vector를 얻을 수 있음
“Duct tape may works anywhere”
“duct”
“may”
“tape”
“work”
“anywhere”
Word One-hot-vector
“duct” [1, 0, 0, 0, 0]
“tape” [0, 1, 0, 0, 0]
“may” [0, 0, 1, 0, 0]
“work” [0, 0, 0, 1, 0]
“anywhere” [0, 0, 0, 0, 1] tape의 word vector
1.0
0.0
0.0
0.0
0.0
0.0](https://image.slidesharecdn.com/bert-200511073637/85/BERT-22-320.jpg)

![Word embedding – Word2Vec
• 재미로 보는 Word2Vec analogy test (https://blog.naver.com/saltluxmarketing/221607368769)
[할아버지 - 할머니 + 농구] = [배구]
[할아버지 - 할머니 + 노트북] = [태블릿]
[할아버지 - 할머니 + 선풍기] = [청소기]
[할아버지 - 할머니 + 바다] = [숲]
[할아버지 - 할머니 + 연필] = [볼펜]
[할아버지 - 할머니 + 파도] = [안개]
[할아버지 - 할머니 + 물] = [기름]
[할아버지 - 할머니 + 버스] = [택시]
[할아버지 - 할머니 + 겨울] = [여름]
[할아버지 - 할머니 + 신] = [환상]
[할아버지 - 할머니 + 커피] = [와인]
[할아버지 - 할머니 + 밥] = [키스]
[할아버지 - 할머니 + 사탕] = [과자]
[할아버지 - 할머니 + 소고기] = [닭고기]
[할아버지 - 할머니 + 치킨] = [피자]
[할아버지 - 할머니 + 손] = [주먹]
[할아버지 - 할머니 + 초록색] = [노란색]
[할아버지 - 할머니 + 기업] = [투자]
[할아버지 - 할머니 + 사랑] = [행복]
[할아버지 - 할머니 + 컴퓨터] = [개발자]
[할아버지 - 할머니 + 시간] = [매일]
[할아버지 - 할머니 + 공부] = [수업]
[할아버지 - 할머니 + 인생] = [추억]
[할아버지 - 할머니 + 기쁨] = [장난]
[할아버지 - 할머니 + 분노] = [절망]
[할아버지 - 할머니 + 점심] = [배달]
[할아버지 - 할머니 + 회의] = [선점]
[할아버지 - 할머니 + 그림] = [jpg]
[건물 - 콘크리트 + 사람] = [냄새]
[건물 - 콘크리트 + 컴퓨터] = [인터페이스]
[건물 - 콘크리트 + 사랑] = [언제나]
[건물 - 콘크리트 + 바다] = [모래]
[건물 - 콘크리트 + 물] = [녹]
[건물 - 콘크리트 + 시간] = [속도]
[건물 - 콘크리트 + 공부] = [적응]
[건물 - 콘크리트 + 인생] = [미소]
[건물 - 콘크리트 + 손] = [감]
[건물 - 콘크리트 + 지식] = [구현]
[건물 - 콘크리트 + 우정] = [목소리]
[건물 - 콘크리트 + 세계] = [사이클]
[건물 - 콘크리트 + 분노] = [상처]
[건물 - 콘크리트 + 힙합] = [리듬]
[건물 - 콘크리트 + 배고픔] = [방전]
[건물 - 콘크리트 + 태양] = [빛]
[건물 - 콘크리트 + 쾌락] = [공명]
[건물 - 콘크리트 + 데이터] = [프로토콜]
[건물 - 콘크리트 + 구름] = [얼음]
[건물 - 콘크리트 + 초록색] = [황색]
[건물 - 콘크리트 + 자유] = [도파민]
[여름 - 더위 + 겨울] = [마름]
[여름 - 더위 + 인간] = [욕구]
[여름 - 더위 + 바다] = [플랑크톤]
[여름 - 더위 + 재미] = [자질]
[선풍기 - 바람 + 눈] = [눈물]
[사람 - 지능 + 컴퓨터] = [소프트웨어]
[인생 - 사람 + 컴퓨터] = [관리자]
[그림 - 연필 + 영화] = [스타]
[오케스트라 - 바이올린 + 인간] = [육체]
[손 - 박수 + 발] = [달리기]
[삼겹살 - 소주 + 맥주] = [햄]](https://image.slidesharecdn.com/bert-200511073637/85/BERT-26-320.jpg)








![RNN 모델 기반의 Seq2Seq
• Seq2Seq (Sequence to Sequence)
• Encoder layer: RNN 구조를 통해 Context vector 를 획득
• Decoder layer: 획득된 Context vector를 입력으로 출력을 예측
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)](https://image.slidesharecdn.com/bert-200511073637/85/BERT-46-320.jpg)
![RNN 의 구조적 문제점
• 입력 sequence의 길이가 매우 긴 경우, 처음에 나온 token에 대한 정보가 희석
• 고정된 context vector 사이즈로 인해 긴 sequence에 대한 정보를 함축하기 어려움
• 모든 token이 영향을 미치니, 중요하지 않은 token도 영향을 줌
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
Attention의 탄생!](https://image.slidesharecdn.com/bert-200511073637/85/BERT-49-320.jpg)
![Attention 모델
• 기존 Seq2Seq에서는 RNN의 최종 output인 Context vector만을 활용
• Attention에서는 인코더 RNN 셀의 각각 output을 활용
• Decoder에서는 매 step마다 RNN 셀의 output을 이용해 dynamic하게 Context vector를 생성
이 정보를
활용하자!
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)](https://image.slidesharecdn.com/bert-200511073637/85/BERT-51-320.jpg)
![Attention 모델
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• 기존 RNN 모델에서 시작](https://image.slidesharecdn.com/bert-200511073637/85/BERT-52-320.jpg)
![Attention 모델
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• 기존 RNN 모델에서 시작
• RNN 셀의 각 output들을 입력으로 하는 Feed forward fully connected layer
• 해당 layer의 output을 각 RNN 셀의 Score로 결정
Feed forward
Fully connected layer
Score](https://image.slidesharecdn.com/bert-200511073637/85/BERT-53-320.jpg)
![Attention 모델
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• 출력된 score에 Softmax를 취함으로써 0-1 사이의 값으로 변환
• 해당 값을 Attention weight로 결정
Feed forward
Fully connected layer](https://image.slidesharecdn.com/bert-200511073637/85/BERT-54-320.jpg)
![Attention 모델
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• 출력된 score에 Softmax를 취함으로써 0-1 사이의 값으로 변환
• 해당 값을 Attention weight로 결정
• Attention weight와 hidden state를 곱해서 Context vector 획득](https://image.slidesharecdn.com/bert-200511073637/85/BERT-55-320.jpg)
![Attention 모델
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• Decoder의 hidden state가 attention weight 계산에 영향을 줌
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Query인 ‘난’ 과 ‘I’, ‘love’, ‘you’와의 상관관계 조정 필요
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
Key, Value
Query](https://image.slidesharecdn.com/bert-200511073637/85/BERT-56-320.jpg)
![Attention 모델
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)
• Decoder의 hidden state가 attention weight 계산에 영향을 줌](https://image.slidesharecdn.com/bert-200511073637/85/BERT-57-320.jpg)

![Self-attention 모델
• Attention is all you need!
• RNN을 encoder와 decoder에서 제거
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)](https://image.slidesharecdn.com/bert-200511073637/85/BERT-61-320.jpg)
![Self-attention 모델
• Attention is all you need!
• RNN을 encoder와 decoder에서 제거
RNN + attention에 적용 된 attention은 decoder가
해석하기에 가장 적합한 weight를 찾고자 노력
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)](https://image.slidesharecdn.com/bert-200511073637/85/BERT-62-320.jpg)
![Self-attention 모델
• Attention is all you need!
• RNN을 encoder와 decoder에서 제거
RNN + attention에 적용 된 attention은 decoder가
해석하기에 가장 적합한 weight를 찾고자 노력
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
Attention이 decoder가 아니라, input인 값을
가장 잘 표현할 수 있도록 학습하면?
→ 자기 자신을 가장 잘 표현할 수 있는 좋은 embedding
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)](https://image.slidesharecdn.com/bert-200511073637/85/BERT-63-320.jpg)
![Self-attention 모델
• Attention is all you need!
• RNN을 encoder와 decoder에서 제거
RNN + attention에 적용 된 attention은 decoder가
해석하기에 가장 적합한 weight를 찾고자 노력
학습
Decoder 결과가 정답과 많이 다르다
좋지 못한 context vector → 좋지 못한 attention weight
Fully connected feed forward network에서 score를 조정
s1-s3가 조정됨에 따라 Attention weight도 조정
Attention이 decoder가 아니라, input인 값을
가장 잘 표현할 수 있도록 학습하면?
→ 자기 자신을 가장 잘 표현할 수 있는 좋은 embedding
Self-attention 모델의 탄생!
* [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델
(https://www.youtube.com/watch?v=WsQLdu2JMgI)](https://image.slidesharecdn.com/bert-200511073637/85/BERT-64-320.jpg)












![Methods – BERT의 WordPiece tokenizing
• BERT tokenization 예시
• BPE로 subword로 분리했음에도 불구하고 vocab에 존재하지 않는 단어는 [UNK] 토큰으로 변환](https://image.slidesharecdn.com/bert-200511073637/85/BERT-89-320.jpg)
![Methods – Masking 기법
• 데이터의 tokenizing
• Masked language model (MLM): input token을 일정 확률로 masking
Original token sequence
Randomly chosen token (15%)
Masking
[MASK]
Randomly replacing
hairy
Unchanging
80% 10% 10%
Example of two sentences token sequence
[MASK]](https://image.slidesharecdn.com/bert-200511073637/85/BERT-90-320.jpg)
![Methods – Masking 기법
[MASK]
512. . .
= IsNext or NotNext](https://image.slidesharecdn.com/bert-200511073637/85/BERT-91-320.jpg)


![BERT 적용 실험 – QnA 문장 유사도 (이진 분류 기반)
• Saltlux ADAM 일반 질의 데이터를 이용해 IRQA 모사 데이터 구축
• 500 문장에 대한 BERT semantic search (https://github.com/hanxiao/bert-as-service)
중고차 대출시 필요서류 알고 싶습니다.
[0.2132, 0.1544, 0.8163 …. ] 768차원
전세자금대출을 받았는데, 추가로 대출을 더 받을수 있는지 궁금합니다.
겨울쿨톤입니다. 겨울쿨 립스틱이 찾기어려워요 겨울 톤 가진 분
들 뭐 쓰시나요?
여름에 조개같은거 먹고 질병에 안 걸리려면 어떻게 해야될까요?
중고차 대출을 받을려고요. 필요한 서류가 뭔가요?
...
1만 문장과 비교
...
500 문장 테스트
모델 Top1 Accuracy
ADAM IRQA algorithm 80.0
Sent2Vec (https://arxiv.org/abs/1703.02507) 82.7
BERT Multi-lingual pretrained model 58.4](https://image.slidesharecdn.com/bert-200511073637/85/BERT-99-320.jpg)






![한국어 BERT 학습 실습
• 한국어 BERT 학습
• 만들어진 preprocessed 학습 데이터를 이용해 한국어 BERT 학습하기
2019-08-04 16:08:39.650069: I tensorflow/stream_executor/platform/default/dso_loader.cc:42]
Successfully opened dynamic library libcublas.so.10.0 I0804 16:08:56.036216 140318809827200
tpu_estimator.py:2159] global_step/sec: 0.0686212 I0804 16:08:56.037184 140318809827200
tpu_estimator.py:2160] examples/sec: 0.274485 I0804 16:08:57.091719 140318809827200
tpu_estimator.py:2159] global_step/sec: 0.947431 I0804 16:08:57.092249 140318809827200
tpu_estimator.py:2160] examples/sec: 3.78972 I0804 16:08:58.154702 140318809827200
tpu_estimator.py:2159] global_step/sec: 0.940709 I0804 16:08:58.155161 140318809827200
tpu_estimator.py:2160] examples/sec: 3.76283 I0804 16:08:59.377439 140318809827200
basic_session_run_hooks.py:606] Saving checkpoints for 5 into drive/My
Drive/bert_for_practics/t_academy/rsc/my_pretrained_model/model.ckpt. I0804 16:09:16.114013
140318809827200 tpu_estimator.py:2159] global_step/sec: 0.0556816 I0804 16:09:16.114295
140318809827200 tpu_estimator.py:2160] examples/sec: 0.222727 I0804 16:09:17.310117
140318809827200 tpu_estimator.py:2159] global_step/sec: 0.836007 I0804 16:09:17.310341
140318809827200 tpu_estimator.py:2160] examples/sec: 3.34403 I0804 16:09:18.371519
140318809827200 tpu_estimator.py:2159] global_step/sec: 0.9422 I0804 16:09:18.372129
140318809827200 tpu_estimator.py:2160] examples/sec: 3.7688 I0804 16:09:19.444218
140318809827200 tpu_estimator.py:2159] global_step/sec: 0.932237 I0804 16:09:19.444792
140318809827200 tpu_estimator.py:2160] examples/sec: 3.72895 I0804 16:09:20.585207
140318809827200 tpu_estimator.py:2159] global_step/sec: 0.87643 I0804 16:09:20.585602
140318809827200 tpu_estimator.py:2160] examples/sec: 3.50572
. . .
I0804 16:10:43.500593 140318809827200 run_pretraining.py:486] ***** Eval results *****
I0804 16:10:43.500724 140318809827200 run_pretraining.py:488] global_step = 10
I0804 16:10:43.505882 140318809827200 run_pretraining.py:488] loss = 11.629292
I0804 16:10:43.506028 140318809827200 run_pretraining.py:488] masked_lm_accuracy = 0.0
I0804 16:10:43.506148 140318809827200 run_pretraining.py:488] masked_lm_loss = 10.944028
I0804 16:10:43.506258 140318809827200 run_pretraining.py:488] next_sentence_accuracy = 0.5725
I0804 16:10:43.506380 140318809827200 run_pretraining.py:488] next_sentence_loss = 0.68523407](https://image.slidesharecdn.com/bert-200511073637/85/BERT-121-320.jpg)


![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[論文紹介] LSTM (LONG SHORT-TERM MEMORY)](https://cdn.slidesharecdn.com/ss_thumbnails/2018-181019021803-thumbnail.jpg?width=640&height=640&fit=bounds)






![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)




































