Natural Language Processing
•자연언어 vs 인공언어
• 자연언어는 인간이 가지는 고유한 정보 전달 수단
• 인공언어: 특정 목적을 위해 인위적으로 만든 프로그래밍 언어 등
• 자연언어처리란
• 컴퓨터를 통하여 인간의 언어를 이용하려는 학문 분야
• 언어를 이해하고 정보처리에 적용함으로써 빠르고 편리한 정보 획득
• 자연언어처리 응용 분야
• 정보검색, 질의응답 시스템, 기계번역
• 문서작성, 문서요약, 문서 분류
• 철자 오류 검색 및 수정, 문법 오류 검사 및 수정
3.
Word Embedding
• Why?
•컴퓨터를 통하여 인간의 언어를 이용하기 위해
• 인간의 언어를 컴퓨터가 이해할 수 있는 수치 데이터로 변환하는 것
• 거창한 표현으로는 “벡터 공간에 단어를 투영하는 기법”
• 어떻게 표현하는 것이 효과적일까?
• 컴퓨터에게 ‘사과’와 ‘초콜릿’ 이라는 두 단어를 보여주면 두 단어의 개념 차이
를 이해할 수 있을까?
• 컴퓨터는 단순히 두 단어를 유니코드의 집합으로만 취급할 것이다.
• NLP가 풀어야 할 고민을 함께하고 기술 발전 흐름을 이해해 보자!
4.
기존의 단어 표현방법
• one-hot representation
• 전통적인 자연어 처리 방법 중 가장 대표적이고 직관적인 표현 방법
• 전체 사전 개수와 동일한 크기의 벡터를 설정하고,
• 단어가 사전에 해당하는 위치의 element 값을 1, 나머지는 0으로 표현
• 음성 인식(20k), 기계 번역(50k), big vocab(500k), Google 1T(13M)
• Bag of Words
• 문서를 단어의 분포로 표현하는 방법
• 기계 학습을 함께 사용하여 문서나 이미지 분류 등에 적용
5.
Bag of Words벡터 표현
• 입력 문장
• Doc1: John likes to watch movies. Mary likes movies too.
• Doc2: John also likes to watch football games.
id 0 1 2 3 4 5 6 7 8 9
vocab John likes to watch movies Mary too also football games
John 1 0 0 0 0 0 0 0 0 0
…
Mary 0 0 0 0 0 1 0 0 0 0
…
Doc1 1 2 1 1 2 1 1 0 0 0
Doc2 1 1 1 1 0 0 0 1 1 1
0
0.5
1
1.5
2
2.5
John likes to watch movies Mary too also football games
Doc1 Doc2
6.
장점과 한계
• 문서를단어의 분포로 표현할 경우
• 단어의 순서나 관계 정보는 소실
• 단어 빈도 정보만으로도 문서 분류 등의 작업 가능
• 문서의 유사도 판단
• Document vector간 내적을 사용 가능
• 단어는?
• 내적을 사용한 단어 유사도는 어떤 단어끼리도 모두 0
•
인간은 직관적으로 특정 단어가 공통점을 가지는 것을 알고 있는데
어떻게하면 단어의 유사도를 컴퓨터가 처리할 수 있을까?
7.
Term-Doc Matrix를 사용한단어 표현
• Bag of Words가 문서를 단어의 분포로 표현했다면,
• Term-document matrix를 활용하는 방식은
• 단어(term)가 문서(Doc)에 출현한 빈도
• 예제
• Doc1: John likes to watch movies. Mary likes movies too.
• Doc2: John also likes to watch football games.
• Co-occurrence similarity or cosine similarity
• John & likes : 2 (documents)
• movies & also: 0 (documents)
id Doc1 Doc2
John 1 1
likes 2 1
to 1 0
watch 1 1
movies 2 0
Mary 1 0
too 1 0
also 0 1
football 0 1
games 0 1
8.
다른 형태의 Vector표현 방법
• Matrix factorization 기반 기법들
• Latent Semantic Indexing(LSI) - Singular vector representation
• 개념적으로 co-occurrence 정보를 활용
• Singular Value Decomposition을 사용해 sparse한 정보를 차원 축소
• A(t,d)=T(t,n) x S(n,n) x D(n,d)
T
• 100개의 term, 1만개의 doc라면 A는 100만개 element
• 차원 축소 후에는 n=10일 경우 1000+100+10만개 element로 표현 가능(참고)
• Nonnegative matrix factorization
• Probabilistic topic modeling 기반 기법들
• Probabilistic latent semantic indexing
• Latent Dirichlet allocation
9.
How do werepresent the meaning of a word?
• Definition: meaning (Webster dictionary)
• the idea that is represented by a word, phrase, etc.
• the idea that a person wants to express by using words, signs, etc.
• 친구를 보면 그 사람을 알 수 있다.
• You shall know a word by the company it keeps(J. R. Firth 1957)
• 주변에 등장하는 단어의 확률 분포 학습을 통해 벡터 임베딩
• The meaning of “cat” is captured by the probability distribution P(w|cat).
• One of the most successful ideas of modern statistical NLP!(cs224n)
10.
Neural Network LanguageModel
• NNLM은 예측 기반 모델을 활용한 벡터화 방법
• Yoshua Bengio 교수에 의해 제시되었으며
• 이전 단어로 현재 타겟 단어를 예측함으로써
• 단어가 자주 인접해 출현하면 두 단어의 벡터 값이 유사하도록 학습
• 이 방식은 단어를 의미 있는 벡터로 임베딩하는 데 성공적
• 학습셋의 단어 수에 비례해 학습 속도가 매우 느린 문제
• Word2Vec은 주변 단어의 관계를 활용한 최초의 개념은 아님
• 다만 Negative Sampling이나 Hierarchical Softmax를 사용해
• 학습 속도가 비약적으로 개선되고 정밀도가 높은 성공적인 방식
11.
Word2Vec
• 주변 단어를사용해 해당 단어를 예측하도록 학습
• 주변에 자주 등장한다면 단어의 의미가 더 비슷할 것이다
• “아이스크림을 사 먹었는데, ___ 시려서 먹기가 힘들었다”에서
• [사, 먹었는데, 시려서, 먹기가] 등을 입력으로 ‘이가’를 예측하거나
• ‘이가’를 입력으로 주변 단어를 예측하도록 학습 가능
NNLP는 이전 단어만 사용해 다음 단어를 예측한 것과 차별화
12.
Two models ofWord2Vec
• Skip-gram
• 중심 단어로 주변에 등장하는 단어를 예측
• Semantic task에 장점을 보이며, 학습이 느림
• CBOW
• 주변 단어로 중심 단어를 예측
• Syntactic task에 장점
• 학습이 상대적으로 빠름
13.
모델의 특징
• 학습을통해 단어가 벡터 공간에 임베딩
• 벡터 포인트 간의 관계가 해당 단어들 간의 관계를 나타냄.
• How it works?
14.
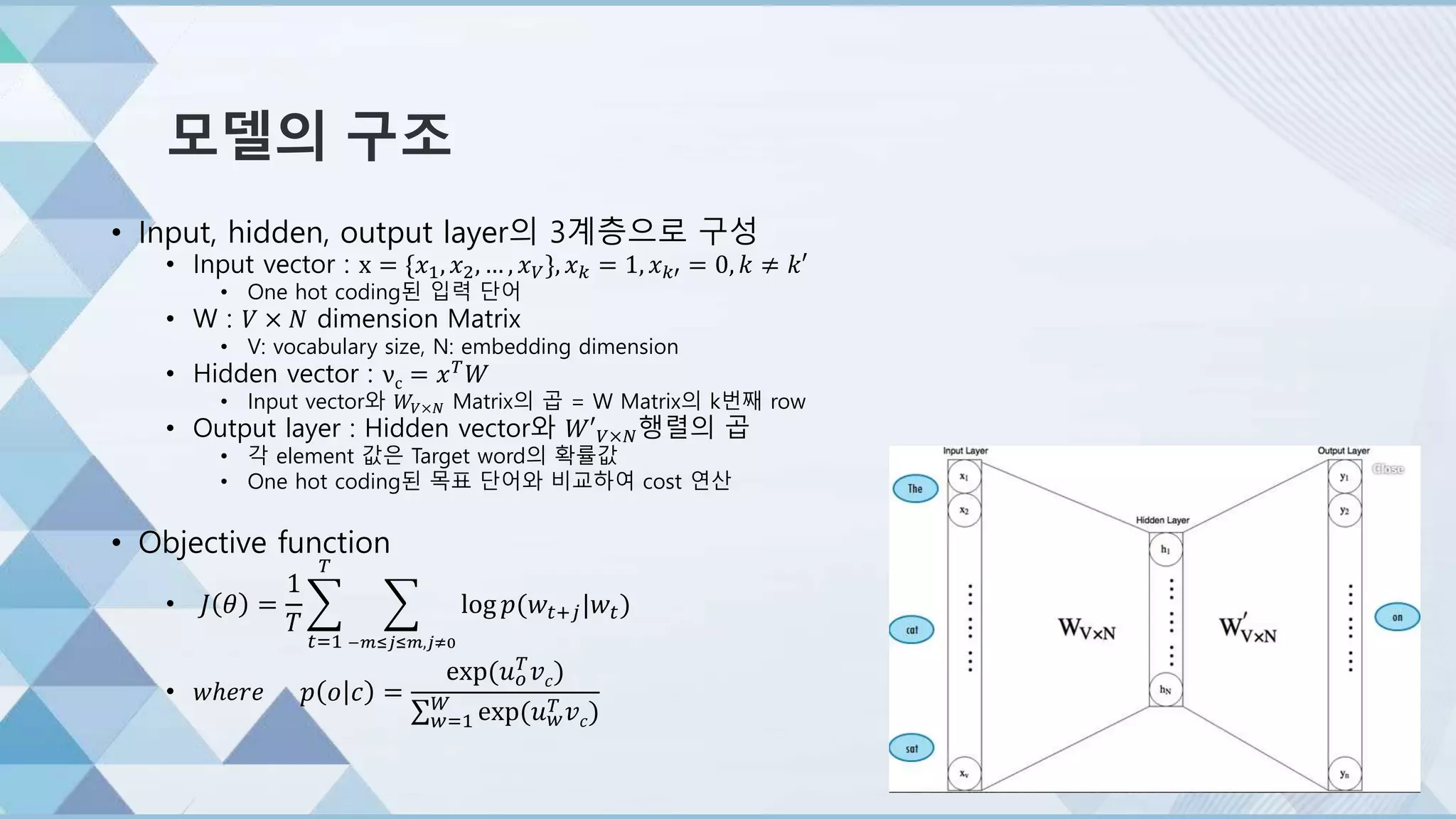
모델의 구조
• Input,hidden, output layer의 3계층으로 구성
• Input vector : x = {𝑥1, 𝑥2, … , 𝑥 𝑉}, 𝑥 𝑘 = 1, 𝑥 𝑘′ = 0, 𝑘 ≠ 𝑘′
• One hot coding된 입력 단어
• W : 𝑉 × 𝑁 dimension Matrix
• V: vocabulary size, N: embedding dimension
• Hidden vector : νc = 𝑥 𝑇
𝑊
• Input vector와 𝑊𝑉×𝑁 Matrix의 곱 = W Matrix의 k번째 row
• Output layer : Hidden vector와 𝑊′ 𝑉×𝑁행렬의 곱
• 각 element 값은 Target word의 확률값
• One hot coding된 목표 단어와 비교하여 cost 연산
• Objective function
•
• 𝑤ℎ𝑒𝑟𝑒
𝐽 𝜃 =
1
𝑇
𝑡=1
𝑇
−𝑚≤𝑗≤𝑚,𝑗≠0
log 𝑝(𝑤𝑡+𝑗|𝑤𝑡)
𝑝 𝑜 𝑐 =
exp(𝑢 𝑜
𝑇 𝑣 𝑐)
𝑤=1
𝑊
exp(𝑢 𝑤
𝑇 𝑣 𝑐)
15.
Word2Vec Algorithm works
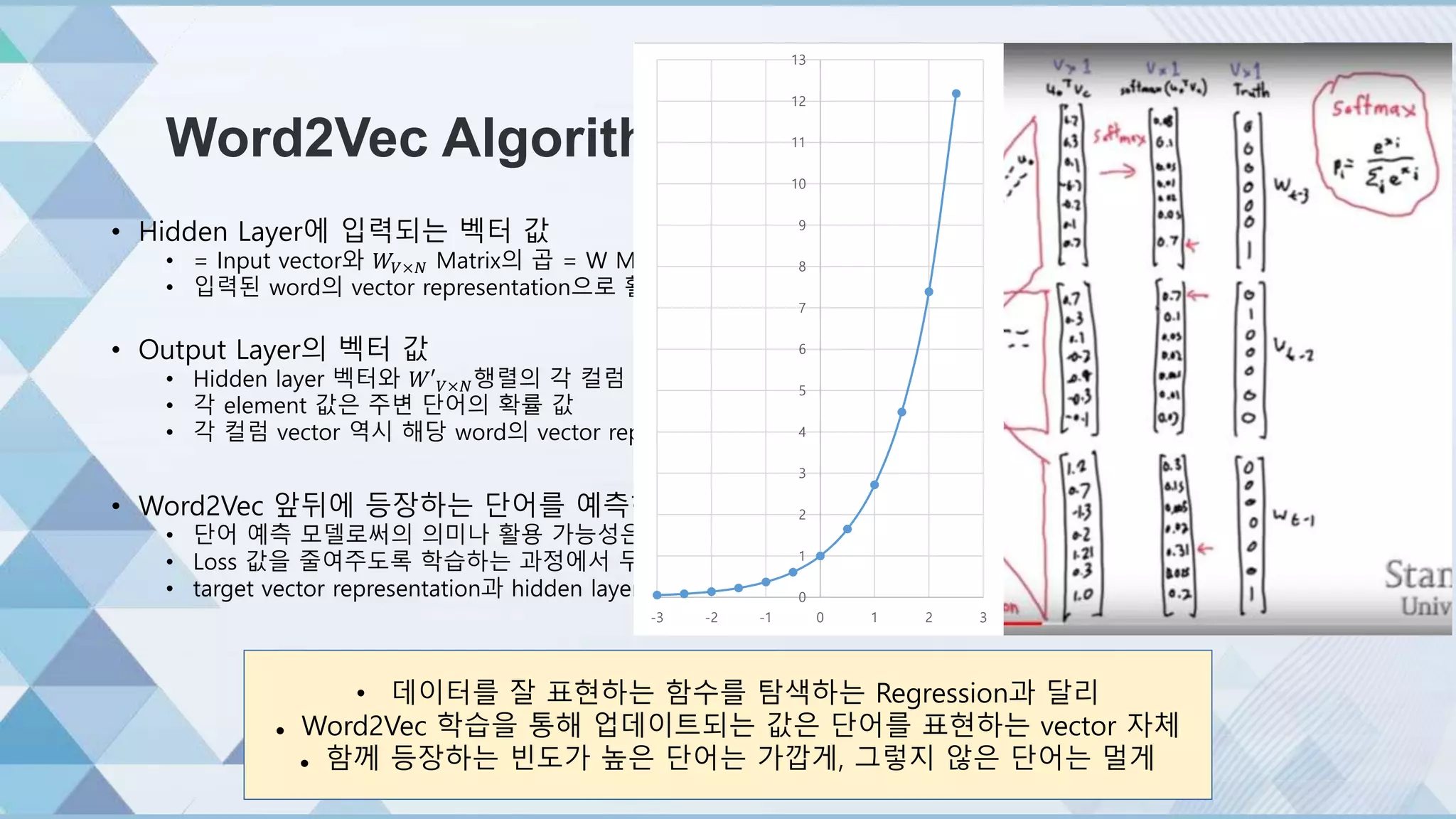
•Hidden Layer에 입력되는 벡터 값
• = Input vector와 𝑊𝑉×𝑁 Matrix의 곱 = W Matrix의 k번째 row
• 입력된 word의 vector representation으로 활용 가능
• Output Layer의 벡터 값
• Hidden layer 벡터와 𝑊′ 𝑉×𝑁행렬의 각 컬럼 vector와의 Dot Product
• 각 element 값은 주변 단어의 확률 값
• 각 컬럼 vector 역시 해당 word의 vector representation으로 활용 가능
• Word2Vec 앞뒤에 등장하는 단어를 예측하도록 학습하지만
• 단어 예측 모델로써의 의미나 활용 가능성은 높지 않음!!!
• Loss 값을 줄여주도록 학습하는 과정에서 두 Matrix가 업데이트되면서
• target vector representation과 hidden layer vector값이 유사해 짐
• 데이터를 잘 표현하는 함수를 탐색하는 Regression과 달리
Word2Vec 학습을 통해 업데이트되는 값은 단어를 표현하는 vector 자체
함께 등장하는 빈도가 높은 단어는 가깝게, 그렇지 않은 단어는 멀게
0.4
0.5
0.1
-1.5
3.7
…
0.1
0.5
1.6
0
0
0
.
.
.
1
.
.
.
0
0
0.4
0.5
0.1
-1.5
3.7
…
0.1
0.5
1.6
Input
V x 1
Embedding Matrix (V x N)
K-th row
𝑣 𝑐 (N X 1)
0.4
0.5
0.1
-1.5
3.7
…
0.1
0.5
1.6
Projection Matrix
(N X V)
12
8
23
.
.
.
41
.
.
.
22
4
Output
0.1 -1.5 3.7 … 0.1 0.5 15
0
0
0
1
.
.
.
.
.
.
0
0
Target
e12
e8
e23
.
.
.
e41
.
.
.
e22
e4
Softmax
e15
𝑣 𝑐
𝑢 𝑜
0.000000000
0.000000000
0.000000015
0.000000000
.
.
0.999999979
.
.
.
0.000000006
0.000000000
Softmax
0
1
2
3
4
5
6
7
8
9
10
11
12
13
-3 -2 -1 0 1 2 3
16.
Softmax – EfficientSolution
• Softmax 연산 후 loss를 줄이는 과정
• vocabulary 수 만큼 추가적인 연산량 과다
• Hierarchical Softmax
• 각 단어를 leaves로 가지는 Binary(Huffman) Tree 활용
• Negative Sampling
• 일부 단어(K개)만 뽑아서 Softmax 계산함으로써
• 계산량이 𝑁 × 𝑉에서 𝑁 × 𝐾 만큼 감소
• Target 단어는 반드시 계산하되, 나머지만 선별하기 때문에 Negative sampling
17.
WEVI : WordEmbedding Visual Inspector
• Word Embedding 과정을 visualization
• 학습데이터, hyperparameter를 수정하며 관찰 가능
• 링크 : https://ronxin.github.io/wevi/
• 단어의 중의성은 어떠한 벡터 표현 특징을 가질까?
• 동음이의어를 활용한 간단한 실험을 해보자
• King and Queen 텍스트에서 woman과 King은 상반된 주변단어 확률을 가질 것
• 만약 woman이라는 단어가 없고, king이 woman 대신에 사용되기도 한다면?
18.
참고자료
• 자연언어처리
• http://cs.kangwon.ac.kr/~leeck/NLP/01_intro.pdf
•Word embedding이란?
• https://shuuki4.wordpress.com/2016/01/27/word2vec-%EA%B4%80%EB%A0%A8-%EC%9D%B4%EB%A1%A0-%EC%A0%95%EB%A6%AC/
• 기존의 단어 표현 방법, NNLM
• https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/29/NNLM/
• SVD
• http://sragent.tistory.com/entry/Latent-Semantic-AnalysisLSA
• http://darkpgmr.tistory.com/106
• Word2Vec
• CS224N/Ling284(https://www.youtube.com/watch?v=ERibwqs9p38)
• https://www.quora.com/How-does-word2vec-work-Can-someone-walk-through-a-specific-example
• https://stats.stackexchange.com/questions/263284/what-exactly-are-input-and-output-word-representations
• https://www.quora.com/How-does-doc2vec-represent-feature-vector-of-a-document-Can-anyone-explain-mathematically-how-the-process-is-done
• How exactly does word2vec work? (David Meyer)
• 다의어의 통사•의미적 활용과 분석(양용준, 제주대학교)
• Word2Vec 학습 과정 시각화
• https://ronxin.github.io/wevi/










![Word2Vec
• 주변 단어를 사용해 해당 단어를 예측하도록 학습
• 주변에 자주 등장한다면 단어의 의미가 더 비슷할 것이다
• “아이스크림을 사 먹었는데, ___ 시려서 먹기가 힘들었다”에서
• [사, 먹었는데, 시려서, 먹기가] 등을 입력으로 ‘이가’를 예측하거나
• ‘이가’를 입력으로 주변 단어를 예측하도록 학습 가능
NNLP는 이전 단어만 사용해 다음 단어를 예측한 것과 차별화](https://image.slidesharecdn.com/word2vec20180125-180122083113/75/Brief-hystory-of-NLP-and-Word2Vec-11-2048.jpg)






















![[226]대용량 텍스트마이닝 기술 하정우](https://cdn.slidesharecdn.com/ss_thumbnails/226-161025031656-thumbnail.jpg?width=640&height=640&fit=bounds)

![[221] 딥러닝을 이용한 지역 컨텍스트 검색 김진호](https://cdn.slidesharecdn.com/ss_thumbnails/221-161025004534-thumbnail.jpg?width=640&height=640&fit=bounds)

![[214]베이지안토픽모형 강병엽](https://cdn.slidesharecdn.com/ss_thumbnails/214-161025025057-thumbnail.jpg?width=640&height=640&fit=bounds)


![[F2]자연어처리를 위한 기계학습 소개](https://cdn.slidesharecdn.com/ss_thumbnails/f2-120919022113-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)










![[study] character aware neural language models](https://cdn.slidesharecdn.com/ss_thumbnails/181114characterawareneurallanguagemodels-190321063423-thumbnail.jpg?width=640&height=640&fit=bounds)





