Download to read offline




![Question from 2013 S7 Paper
There are monkeys living on 2 very high rocks. The
northern monkeys live on the northern rock that provides
water but no food. Conversely, the southern monkeys
live on the southern rock that provides food but no water.
However, both the northern and southern monkeys have
to eat and to drink!
There is a small rope between the 2 rocks. The rope can
carry up to MaxOnRope monkeys. Concurrent crossing
in both directions is not possible.
1. What type of a solution would you recommend for this
problem? Briefly explain. [3 marks]
2. Provide a pueudocode to solve the problem. [5 marks]
5](https://image.slidesharecdn.com/10-mutualexclusioninds-240108065859-f83ecd14/85/Mutual-Exclusion-in-Distributed-Memory-Systems-5-320.jpg)
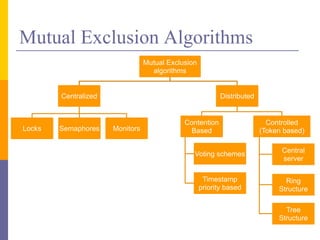

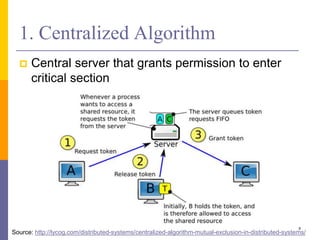


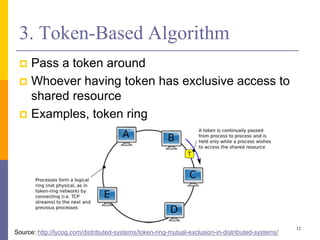







The document discusses mutual exclusion in distributed memory systems, focusing on synchronization between threads and the challenges posed by distributed environments lacking shared memory. It outlines various algorithms for achieving mutual exclusion, including centralized, decentralized, token-based, and distributed algorithms, while addressing their properties and limitations. The document also poses a problem related to resource sharing among two groups and suggests the development of a solution and pseudocode for it.

















































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)





