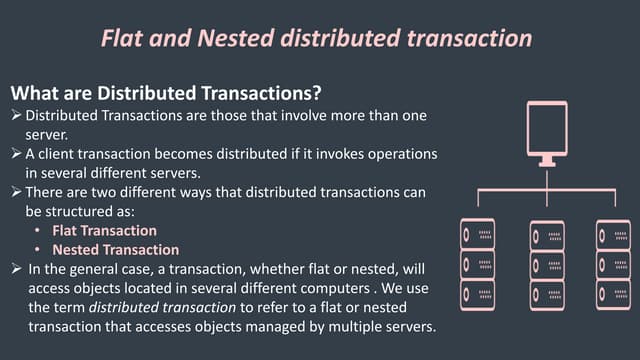
The document discusses various algorithms for distributed coordination and agreement between processes. It begins by introducing concepts like mutual exclusion, elections, and failure detection. It then summarizes several mutual exclusion algorithms like the centralized server algorithm, ring-based algorithm, and Ricart-Agrawala's multicast algorithm. It also covers the bully election algorithm. The document analyzes the performance and properties of these algorithms, discussing aspects like safety, liveness, bandwidth usage, and fault tolerance.






























































![Variants
• Obvious problem with sequencer-based approach is
that the sequencer may become bottleneck.
• Variants
– Chang and Maxemchuk [1994] [1991]
– Kaashoek et al. [1989]
• Kaashoek et al. [1989] uses hardware-based multicast–
For example, available on Ethernet.
• In their simplest variant, processes send the message to be
multicast to the sequencer, one-to-one. The sequencer
multicasts the message itself, as well as the identifier and
sequence number.
63](https://image.slidesharecdn.com/coordinationandagreement1-230213103151-b7e39442/75/Coordination-and-Agreement-ppt-63-2048.jpg)




![Implementing Casual Ordering
(Birman et al. [1991])
• Non-overlapping closed groups can have casually
ordered multicasts using vector timestamps
• This algorithm only orders happened-before caused by
multicasts only, and ignores one-to-one messages
between processes.
• Each process updates its vector timestamp before
delivering a message to maintain the count of
precedent messages.
• Co-multicast and co-deliver
68](https://image.slidesharecdn.com/coordinationandagreement1-230213103151-b7e39442/75/Coordination-and-Agreement-ppt-68-2048.jpg)
![Implementing Casual Ordering
(Birman et al. [1991])
• Logic
• When a process pi B-delivers a message from pj, it must
place it in hold-back queue before it can CO-deliver it:
until it is assured that it has delivered any messages
that casually preceded it. To establish this, Pi waits until:
– (a) it has delivered any earlier message sent by pj, and
– (b) it has delivered any message that pj had delivered at the
time it multicast the message.
• Both of these conditions can be detected by examining
the vector timestamps
69](https://image.slidesharecdn.com/coordinationandagreement1-230213103151-b7e39442/75/Coordination-and-Agreement-ppt-69-2048.jpg)