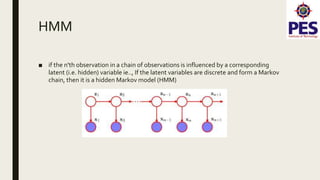
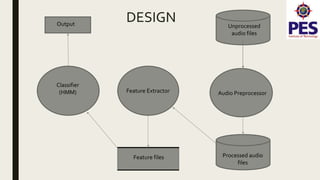
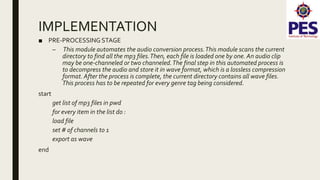
The document provides a survey on music genre detection, detailing the waveform audio file format, the extraction of Mel-frequency cepstral coefficients (MFCCs), and the application of Hidden Markov Models (HMM) in classifying music into genres such as jazz, blues, rock, and classical. It outlines the methodology, dataset collection, and preprocessing involved in training classifiers, as well as the challenges related to genre similarities affecting classification accuracy. The conclusion notes an efficiency of around 72% in genre classification when utilizing a larger dataset, with suggestions for future work including GUI implementation and expanding genre categories.
















![REFERENCES
[1] Molau, Pitz, Schlueter, Ney :Computing Mel- Frequency Cepstral Coefficients
on the Power Spectrum, RWTH Aachen – University ofTechnology, 52056
Aachen,Germany. IEEETransactions on Communications 26 (6)
[2] Frigo, M.; Johnson, S. G. (2005). "The Design and Implementation of FFTW3"
(PDF). Proceedings of the IEEE 93: 216–231. 10.1109/jproc.2004.840301
[3] Narasimha, M.; Peterson, A. (June 1978). "On the Computation of the
Discrete CosineTransform". IEEETransactions on Communications 26 (6): 934–
936. 10.1109/TCOM.1978.1094144](https://image.slidesharecdn.com/musicgenredetectionusinghiddenmarkovmodels-180611133440/85/Music-genre-detection-using-hidden-markov-models-19-320.jpg)
![[4] S. B. Kotsiantis : Supervised Machine Learning:A Review of Classification
Techniques, 2007, University of Peloponnesse,Greece
[5] DavidA. Freedman (2009). Statistical Models:Theory and Practice.
Cambridge University Press. p. 128.
[6] Musical genre classification of audio signals, Speech and Audio Processing,
IEEETransactions on (Volume:10 , Issue: 5 ), 293-302, November 2002,
http://dspace.library.uvic.ca:8080/bitstream/handle/1828/1344/tsap02gtzan.pdf](https://image.slidesharecdn.com/musicgenredetectionusinghiddenmarkovmodels-180611133440/85/Music-genre-detection-using-hidden-markov-models-20-320.jpg)
![■ WEB LINKSAND OTHER RESOURCES
[7] http://willdrevo.com/fingerprinting-and-audio-recognition-with-python/
[8] en.wikipedia.org/wiki/Hidden_Markov_Model
[9] en.wikipedia.org/wiki/Mel_Frequency_Ceptral
[10] en.wikipedia.org/wiki/Window_function
[11] http://practicalcryptography.com/miscellaneous/machine-learning/guide-
mel-frequency-cepstral-coefficients-mfccs/](https://image.slidesharecdn.com/musicgenredetectionusinghiddenmarkovmodels-180611133440/85/Music-genre-detection-using-hidden-markov-models-21-320.jpg)




































































