The document provides an overview of automatic music transcription (AMT), detailing its definition, goals, historical context, and various research areas such as multi-pitch analysis and semi-automatic transcription. It discusses both early research developments and current challenges in achieving accurate transcription, as well as future directions in the field. The document emphasizes the limitations of current AMT systems compared to human transcription capabilities and highlights the importance of combining computational techniques with human insights for improved accuracy.




![• Melograph [Metfessel, 1928]
• Special-purpose hardware device that makes a
graph of the pitch of the input waveform with time
Early days in AMT research](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-6-320.jpg)
![• Segmentation and analysis of continuous musical sound
by digital computer [Moorer, 1975]
• First paper to discuss automatic transcription in signal
processing view (especially filter theory)
• Optimum comb method is used to detect F0
Early days in AMT research](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-7-320.jpg)
![• Blackboard system [Martin, 1996]
• Various forms of knowledge integrated for specific purpose
• human physiology, acoustics, musical practice etc.
• Blackboard workspace is arranged in a
hierarchy of five hypothesis becoming
abstract as going upward
• Tracks, Partials, Notes, Intervals, Chords
Early days in AMT research](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-8-320.jpg)

![• Connectionist approach [Marolt, 2004]
• Resembles human perception of pitch
• Auditory-model based partial tracking
• Networks of adaptive oscillators inspired from hair cells of cochlea
• Note recognition based on neural network
Early days in AMT research](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-10-320.jpg)


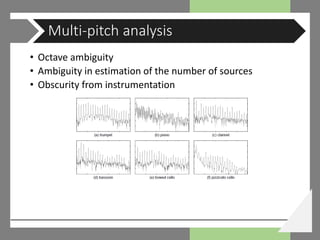

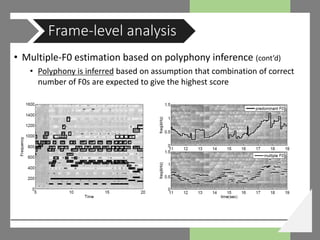
![• Multiple-F0 estimation based on polyphony inference [Yeh, 2008]
• Goal : extract multiple-F0 from STFT frame of harmonic instrument
• Noise model / Source model / Source interaction model
• Noise model distinguish unnecessary components for harmonic analysis
• Non-harmonically related F0s (NHRF0s)
• Abbreviation in computation for proper F0 candidate selection
• Hypothetical partial sequence (HPS)
Frame-level analysis
Extraction of a HRF0 F0c from
the HPS of a NHRF0 F0a](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-16-320.jpg)

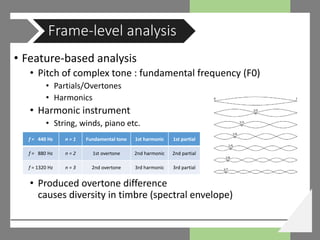
![• Statistical model-based analysis
• Multi-pitch estimation using
new probabilistic spectral
smoothness principle [Emiya, 2010]
• Given an observed frame x and a set
𝑪𝑪 of all possible fundamental
frequency combinations, multi-pitch
detection function 𝐶𝐶̂ can be written
(Maximum a posteriori)
Frame-level analysis
𝐶𝐶̂ = 𝑃𝑃 𝐶𝐶 𝑋𝑋𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎
𝐶𝐶 ∈ 𝑪𝑪
=
𝑃𝑃 𝐶𝐶 𝑋𝑋 𝑃𝑃(𝐶𝐶)
𝑃𝑃(𝑋𝑋)
𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎
𝐶𝐶 ∈ 𝑪𝑪](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-19-320.jpg)
![• Spectrogram decomposition-based analysis
• Nonnegative matrix factorization [Smaragdis, 2003]
• NMF model decomposes an input spectrogram 𝑋𝑋 with 𝐾𝐾 frequency
bins and 𝑁𝑁 frames into 𝑋𝑋 ≈ 𝑊𝑊𝑊𝑊
• For number of pitch bases R ≪ 𝑁𝑁, 𝐾𝐾; 𝑊𝑊 contains the spectral bases
for each of the 𝑅𝑅 pitch components, and 𝐻𝐻 is the pitch activity matrix
across time
Frame-level analysis](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-20-320.jpg)
![• Time-pitch computation must be further processed to
detect note events with
• Discrete pitch value
• An onset time and offset time (duration)
• Minimum duration pruning [Dessein, 2010]
• Simple and fast solution
• Applied after thresholding
• Note events which have a
duration smaller than a
pre-defined value are removed from the final score
Note-level analysis](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-21-320.jpg)
![• Hidden Markov models [Ryynanen, 2005]
• Model each note with a 3-state note event HMM
• 3 states : attack, sustain, noise states of each sound
• Musicological model was used for estimating musical key and note
transition probabilities
• Observation :
• Pitch deviation
• Pitch salience
• Onset strength
• Model silence with a 1-state
silence HMM
Note-level analysis](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-22-320.jpg)
![• Efficient convolutional sparse coding [Wohlberg, 2014]
• Note tracking from audio directly
𝑠𝑠[𝑡𝑡] : monaural, polyphonic audio recording of a piano piece
𝑑𝑑 𝑚𝑚[𝑡𝑡] : dictionary element representing notes of piano
𝑥𝑥 𝑚𝑚 𝑡𝑡 : activation vectors
• Nonzero value at index 𝑡𝑡 of 𝑥𝑥 𝑚𝑚[𝑡𝑡] represent activation of note
𝑚𝑚 at sample 𝑡𝑡
Note-level analysis
𝑠𝑠 𝑡𝑡 ≅ � 𝑑𝑑 𝑚𝑚 𝑡𝑡 ∗ 𝑥𝑥 𝑚𝑚[𝑡𝑡]
𝑚𝑚](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-23-320.jpg)

![• Spectrogram decomposition-based analysis
• Probabilistic latent component analysis [Smaragdis, 2007]
• For N-dim random variable 𝑥𝑥 and latent variable 𝑧𝑧,
• Estimation of marginals 𝑃𝑃(𝑥𝑥 𝑗𝑗
|𝑧𝑧) is performed using EM algorithm
• In source separation, magnitude spectrogram is expressed as
that decomposition will result into two sets of marginals
Timbre tracking](https://image.slidesharecdn.com/warnikchowamtoverview-181017044707/85/AMT-overview-25-320.jpg)


































![[Tutorial] Computational Approaches to Melodic Analysis of Indian Art Music](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialmelodicanalysis-170910111235-thumbnail.jpg?width=640&height=640&fit=bounds)









![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)



