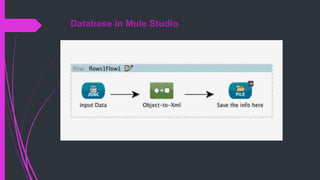
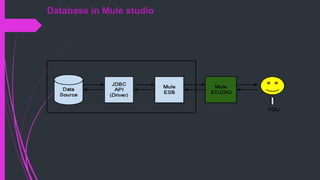
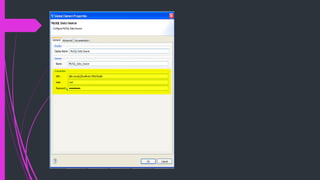
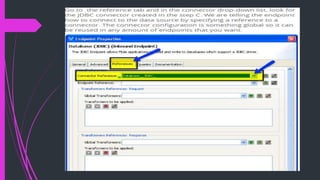
The document discusses how to connect to and query databases using JDBC and Mule Studio. It provides steps to import database drivers, create a MySQL data source configuration, configure a JDBC connector to use that data source, and create inbound or outbound JDBC endpoints in a Mule flow to execute SQL queries and statements.


































































![Java Web Programming [3/9] : Servlet Advanced](https://cdn.slidesharecdn.com/ss_thumbnails/javaweb-module3-130106070352-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































