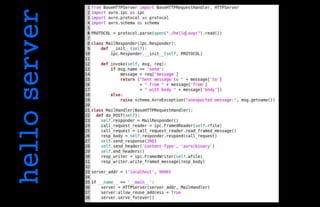
Apache Avro is a data serialization system that is compact, fast, and provides support for RPC mechanisms and data evolution. It uses JSON schemas and efficient binary encoding. Avro is built for large datasets and supports features like schema validation, dynamic typing, sorting, and protocol definitions for language-independent RPCs.









![aschema
{
"namespace": "com.example",
"protocol": "HelloWorld",
"doc": "Protocol Greetings",
"types": [
{"name": "Greeting", "type": "record", "fields": [
{"name": "message", "type": "string"}]},
{"name": "Curse", "type": "error", "fields": [
{"name": "message", "type": "string"}]}
],
"messages": {
"hello": {
"doc": "Say hello.",
"request": [{"name": "greeting", "type": "Greeting" }],
"response": "Greeting",
"errors": ["Curse"]
}
}
}](https://image.slidesharecdn.com/avrointro-140528101158-phpapp01/85/Avro-intro-10-320.jpg)
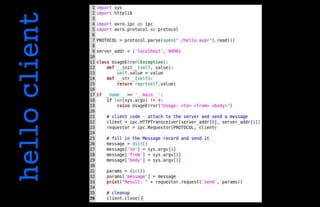
![• Schemas must always be present
• Therefore when using Protocols:
– The client must send the request schema to the server
– The server must send the response and error schema to the client
• Stateless transports
require a schema
handshake before
each request
• Stateful transports
can maintain a
schema cache
eliminating the
schema exchange
on successive calls
• Handshakes use a
hash of the schema
to avoid sending
schemas which are
already consistent on
both sides
handshakes
{
"type": "record",
"name": "HandshakeRequest", "namespace":"org.apache.avro.ipc",
"fields": [
{"name": "clientHash",
"type": {"type": "fixed", "name": "MD5", "size": 16}},
{"name": "clientProtocol", "type": ["null", "string"]},
{"name": "serverHash", "type": "MD5"},
{"name": "meta", "type": ["null", {"type": "map", "values": "bytes"}]}
]
}
{
"type": "record",
"name": "HandshakeResponse", "namespace": "org.apache.avro.ipc",
"fields": [
{"name": "match",
"type": {"type": "enum", "name": "HandshakeMatch",
"symbols": ["BOTH", "CLIENT", "NONE"]}},
{"name": "serverProtocol",
"type": ["null", "string"]},
{"name": "serverHash",
"type": ["null", {"type": "fixed", "name": "MD5", "size": 16}]},
{"name": "meta",
"type": ["null", {"type": "map", "values": "bytes"}]}
]
}
Apache Avro Handshake Records](https://image.slidesharecdn.com/avrointro-140528101158-phpapp01/85/Avro-intro-11-320.jpg)
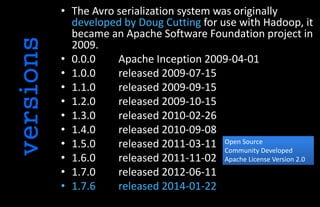
![protocol
session
$ sudo apt-get install libsnappy-dev
…
$ sudo apt-get install python-pip python-dev build-essential
…
$ sudo pip install python-snappy
…
$ sudo pip install avro
…
$ cat hello.avpr
{
"namespace": "com.example",
"protocol": "HelloWorld",
"doc": "Protocol Greetings",
"types": [
{"name": "Message", "type": "record",
"fields": [
{"name": "to", "type": "string"},
{"name": "from", "type": "string"},
{"name": "body", "type": "string"}
]
}
],
"messages": {
"send": {
"request": [{"name": "message", "type": "Message"}],
"response": "string"
}
}
}
$ python server.py
127.0.0.1 - - [28/May/2014 06:27:31] "POST / HTTP/1.1" 200 -
https://github.com/phunt/avro-rpc-quickstart
$ python client.py Thurston_Howell Ginger "Hello Avro"
Result: Sent message to Thurston_Howell from Ginger with body Hello Avro](https://image.slidesharecdn.com/avrointro-140528101158-phpapp01/85/Avro-intro-12-320.jpg)
![avro
resources
• Web
– avro.apache.org
– github.com/apache/avro
• Mail
– Users: user@avro.apache.org
– Developers: dev@avro.apache.org
• Chat
– #avro
• Book
– White (2012), Hadoop, The Definitive Guide,
O’Reilly Media Inc. [http://www.oreilly.com]
– Features 20 pages of Apache Avro coverage
Randy Abernethy
ra@apache.org](https://image.slidesharecdn.com/avrointro-140528101158-phpapp01/85/Avro-intro-16-320.jpg)




![Apache Avro in LivePerson [Hebrew]](https://cdn.slidesharecdn.com/ss_thumbnails/apacheavroinliveperson2014-141027092641-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)








