





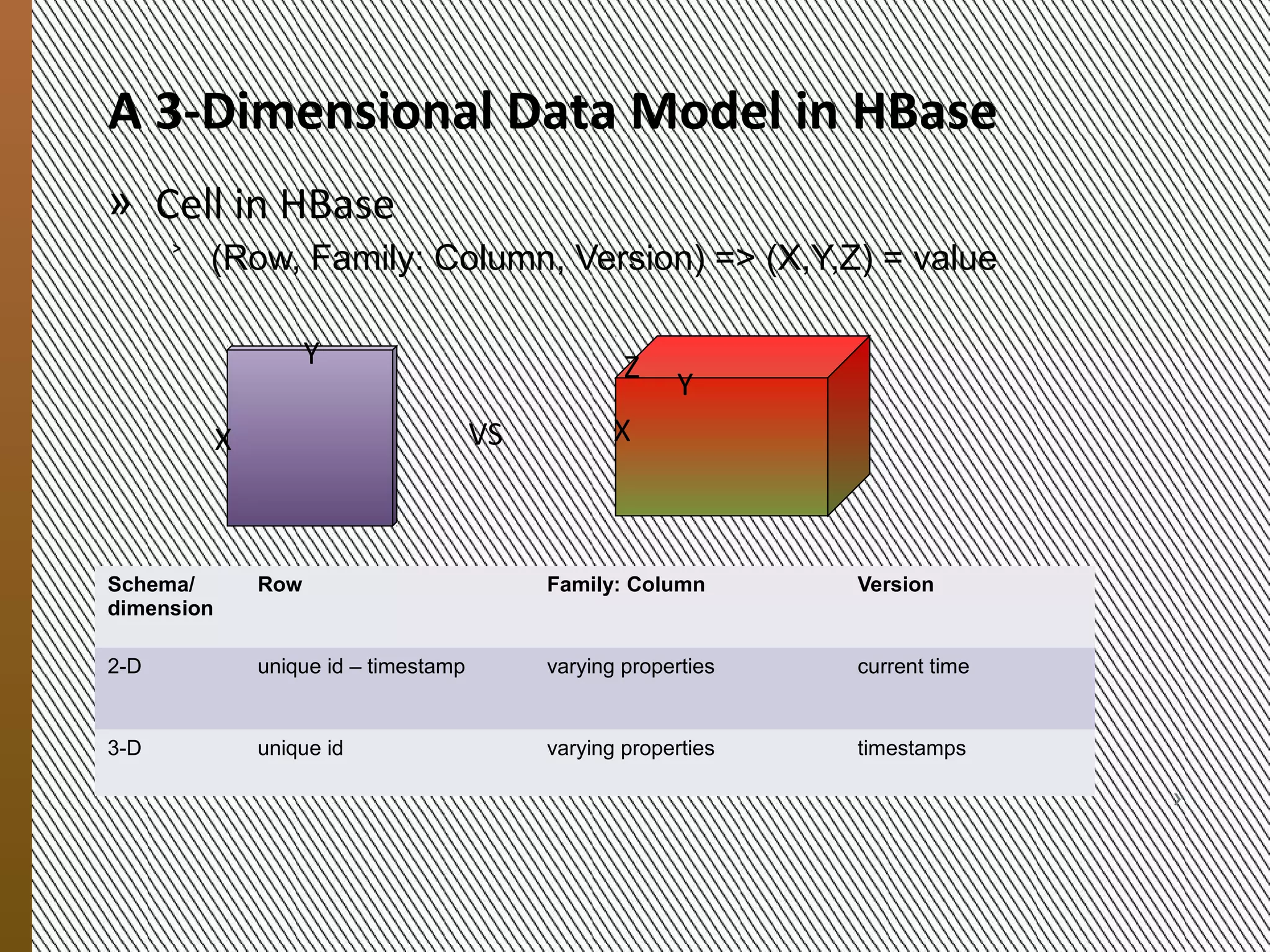

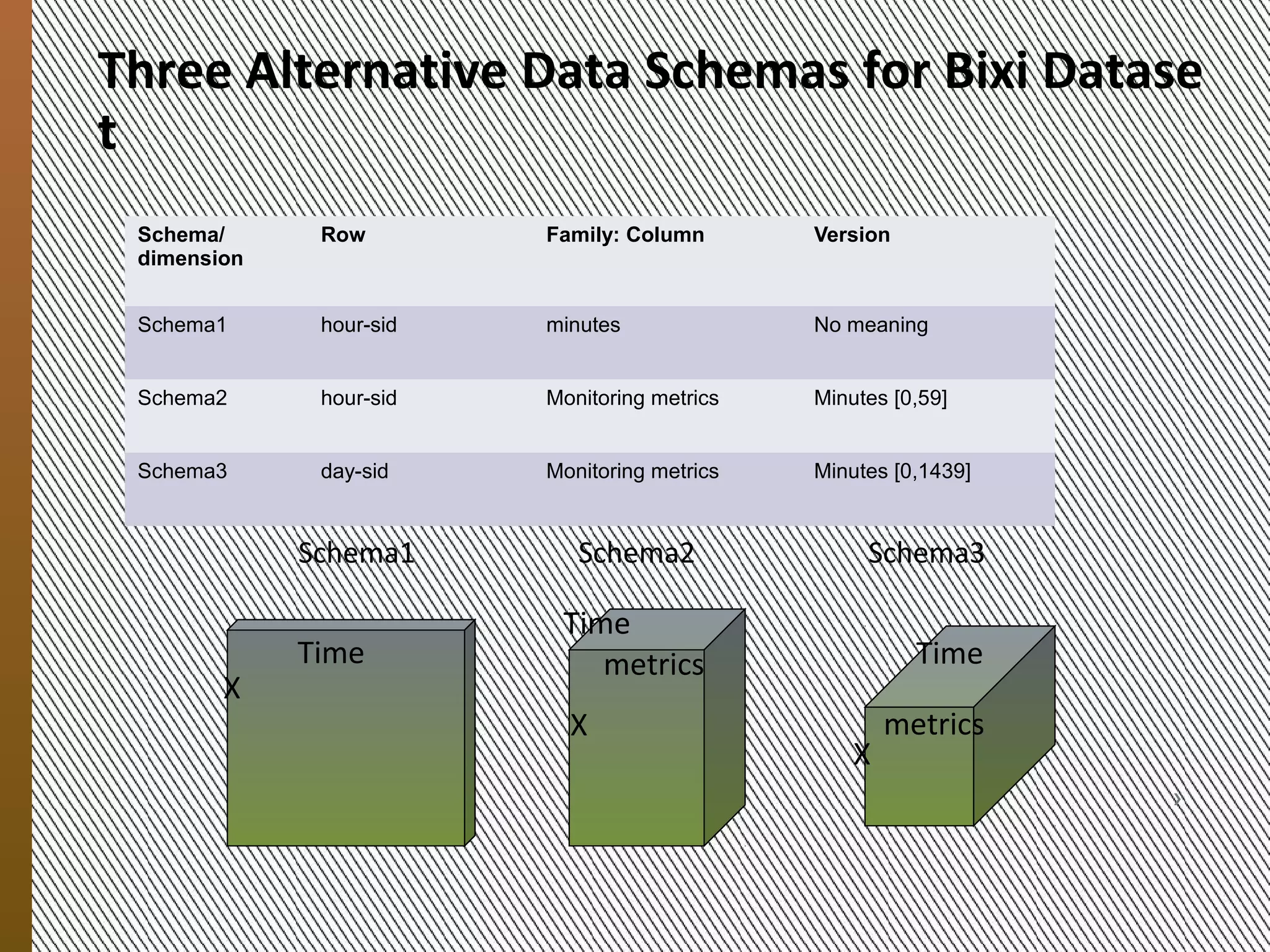
![Three Schemas
for the Bixi Dataset
Schema/ Row Family: Column Version
dimension
Schema1 hour-sid minutes[0,59] no meaning
Schema2 hour-sid monitoring metrics minutes [0,59]
Schema3 day-sid monitoring metrics minutes [0,1439]
Schema1 Schema2 Schema3
Time
Time metrics Time
X
X metrics
9/20/2012
X
MESOCA 2012 11](https://image.slidesharecdn.com/a3-dimensionaldatamodelinhbaseforlargetime-seriesdataset-20120915-120915133944-phpapp01/75/A-3-dimensional-data-model-in-hbase-for-large-time-series-dataset-20120915-11-2048.jpg)


![Query1 of Cosmology Dataset
» Get all the particles of a type: star
» in a single snapshot
» with a given property: tform
» whose property matches the expression
˃ [>0.01;84]
˃ [>0.08;128]
˃ [>0.05;128]
˃ [>0.08;216]
˃ [>0.08;512]
9/20/2012
MESOCA 2012 14](https://image.slidesharecdn.com/a3-dimensionaldatamodelinhbaseforlargetime-seriesdataset-20120915-120915133944-phpapp01/75/A-3-dimensional-data-model-in-hbase-for-large-time-series-dataset-20120915-14-2048.jpg)
![Query2 of Cosmology Dataset
» Get all the particles added/destroyed
» between s1 and s2
˃ [29;24]
˃ [60;24]
˃ [84;24]
˃ [128;24]
˃ [216;128]
˃ [216;24]
˃ [512;24]
˃ [512;128]
˃ [512;216]
9/20/2012
MESOCA 2012 16](https://image.slidesharecdn.com/a3-dimensionaldatamodelinhbaseforlargetime-seriesdataset-20120915-120915133944-phpapp01/75/A-3-dimensional-data-model-in-hbase-for-large-time-series-dataset-20120915-15-2048.jpg)
![Query3 of Cosmology Dataset
» Get the values of a property
» for a set of particle IDs
» across the selected snapshots
˃10;[24]
˃10; [24,512],
˃10;[24,60,128,512]
˃10;[24,29,60,84,128,512]
˃10;[24,36,45,60,84,128,216,512]
˃50;[24,29,84,512]
˃50;[24,29,36,45,60,84,128,216,512]
˃100;[24,29,36,45,60,84,128,216,512]
9/20/2012
˃150;[24,29,36,45,60,84,128,216,512
MESOCA 2012 18](https://image.slidesharecdn.com/a3-dimensionaldatamodelinhbaseforlargetime-seriesdataset-20120915-120915133944-phpapp01/75/A-3-dimensional-data-model-in-hbase-for-large-time-series-dataset-20120915-16-2048.jpg)
![Query3 of Cosmology Dataset
» Get the values of a property: star:eps
» for a set of particle IDs: a continuous range particle IDs
» across the selected snapshots
˃ 10;[24]
˃ 10; [24,512],
˃ 10;[24,60,128,512]
˃ 10;[24,29,60,84,128,512]
˃ 10;[24,36,45,60,84,128,216,512]
˃ 50;[24,29,84,512]
˃ 50;[24,29,36,45,60,84,128,216,512]
˃ 100;[24,29,36,45,60,84,128,216,512]
9/20/2012
˃ 150;[24,29,36,45,60,84,128,216,512]
MESOCA 2012 19](https://image.slidesharecdn.com/a3-dimensionaldatamodelinhbaseforlargetime-seriesdataset-20120915-120915133944-phpapp01/75/A-3-dimensional-data-model-in-hbase-for-large-time-series-dataset-20120915-17-2048.jpg)
![Bixi Query
» For a given list of stations: 200 stations
» get average bike usage in a given period
˃ [1day]
˃ [2day]
˃ [4day]
˃ [8day]
˃ [16day]
9/20/2012
MESOCA 2012 21](https://image.slidesharecdn.com/a3-dimensionaldatamodelinhbaseforlargetime-seriesdataset-20120915-120915133944-phpapp01/75/A-3-dimensional-data-model-in-hbase-for-large-time-series-dataset-20120915-18-2048.jpg)






This document outlines a study on migrating relational database content to NoSQL storage systems like HBase. It discusses challenges in migration and the need for design patterns for HBase schemas. A 3-dimensional data model in HBase is proposed and evaluated using cosmology and bike rental datasets. Experiment results show the 3D model improves performance for queries that use HBase's version dimension. Future work includes further evaluation of the model's scalability and designing models for other dataset types.






















![[FOSS4G KOREA 2014]Hadoop 상에서 MapReduce를 이용한 Spatial Big Data 집계와 시스템 구축](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2014hadoop-geohash-v02-140829035316-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)








