Download to read offline



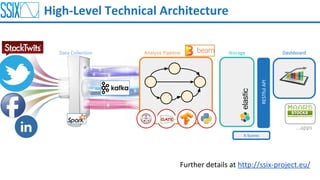











Moven is a framework for distributing machine learning models using Maven. It addresses the problems of managing model distribution and versioning as well as automating testing. Models are published as Maven artifacts and can then be retrieved and used from Java and Python. Moven provides model-agnostic publishing and retrieval of compressed models through Maven repositories and dependencies. It is currently being used in production at Redlink and the SSIX project.



























































































