Download as PDF, PPTX






















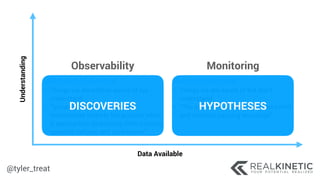
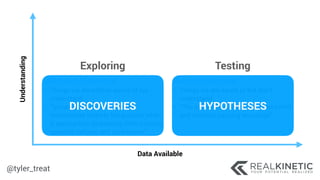

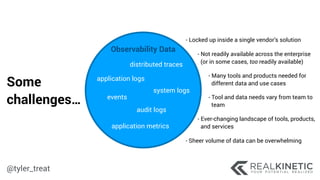
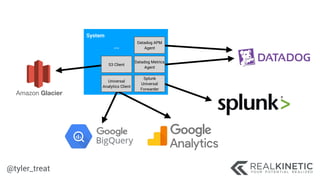







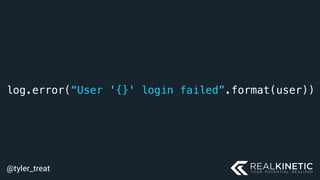
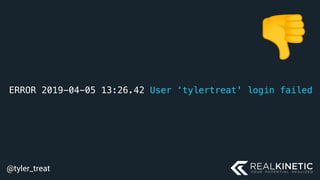
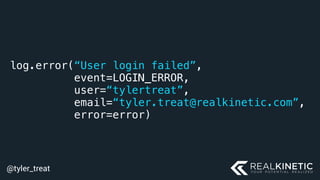
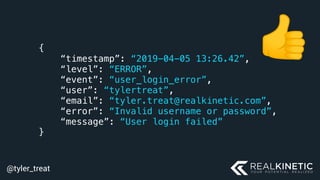


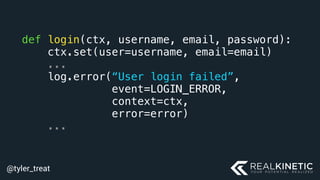
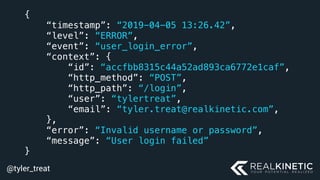
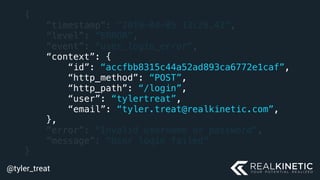


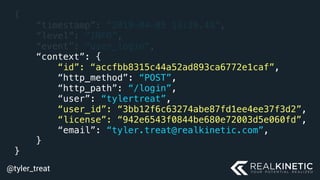














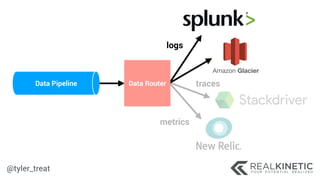
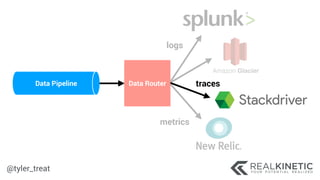
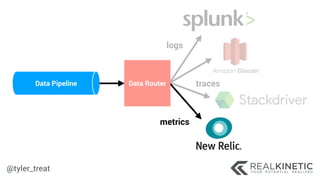



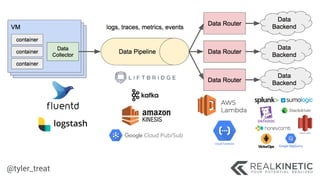


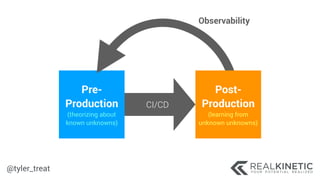

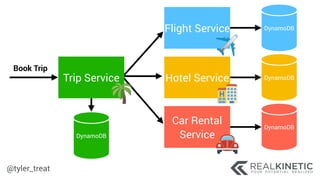







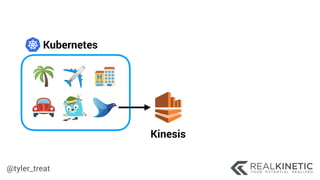

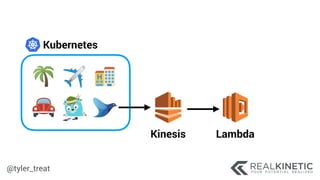
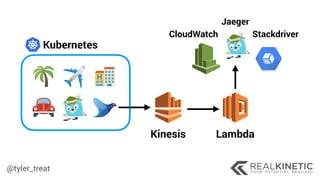


The document discusses cloud-native observability, emphasizing the importance of structured logging and data pipelines for effective monitoring and debugging in complex systems. It outlines challenges such as accessing observability data across different platforms, the necessity of standard specifications for data collection, and the implementation of an observability pipeline to handle data efficiently. Key components include structured logging, data collectors, and routers, which facilitate the seamless transfer and analysis of system behavior to enhance operational reliability.













































































