




The document discusses the concept of platform observability in IT, emphasizing its role in understanding system states through data such as logs and metrics. It highlights challenges in current monitoring tools, the need for improved observability techniques, and the potential benefits such as faster issue resolution and reduced operational costs. Observability is framed as a crucial framework for enhancing operational efficiency and reliability in cloud and application environments.
An overview of Platform Observability, highlighting its significance in modern IT systems.
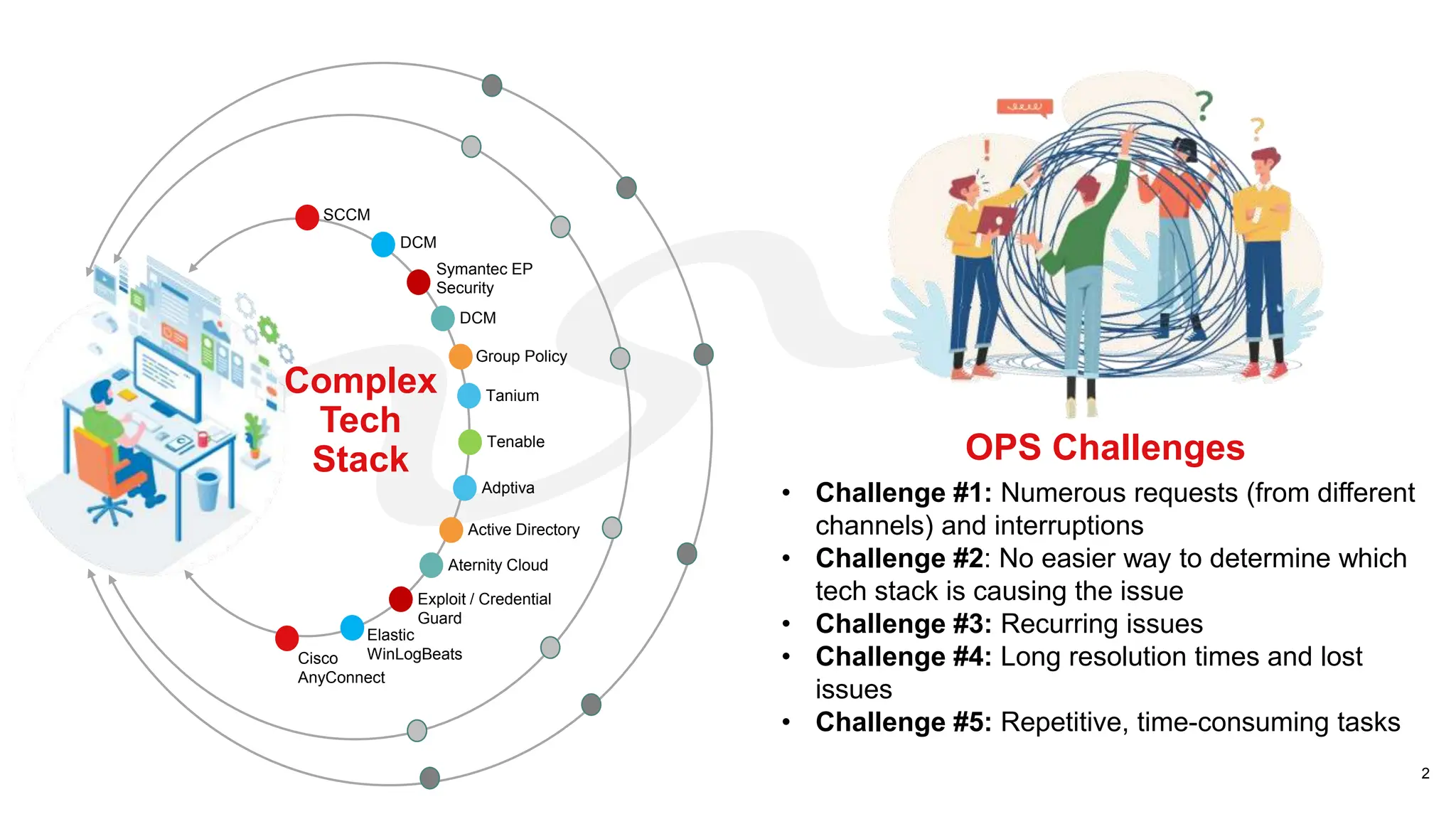
Identifies challenges such as numerous requests, long resolution times, and issues stemming from a complex tech stack.
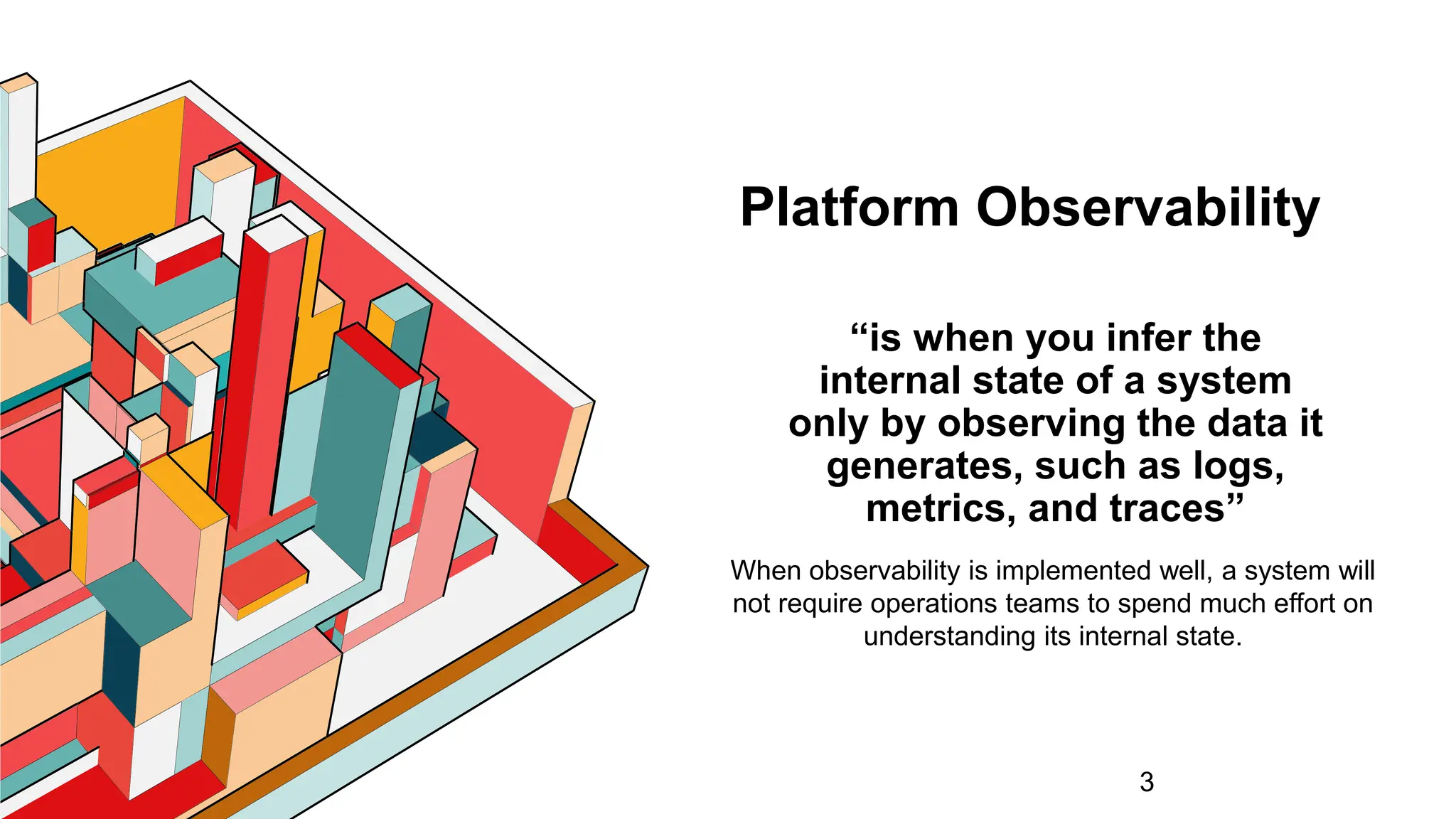
Defines observability, contrasting it with monitoring, explaining its importance in understanding system behavior.
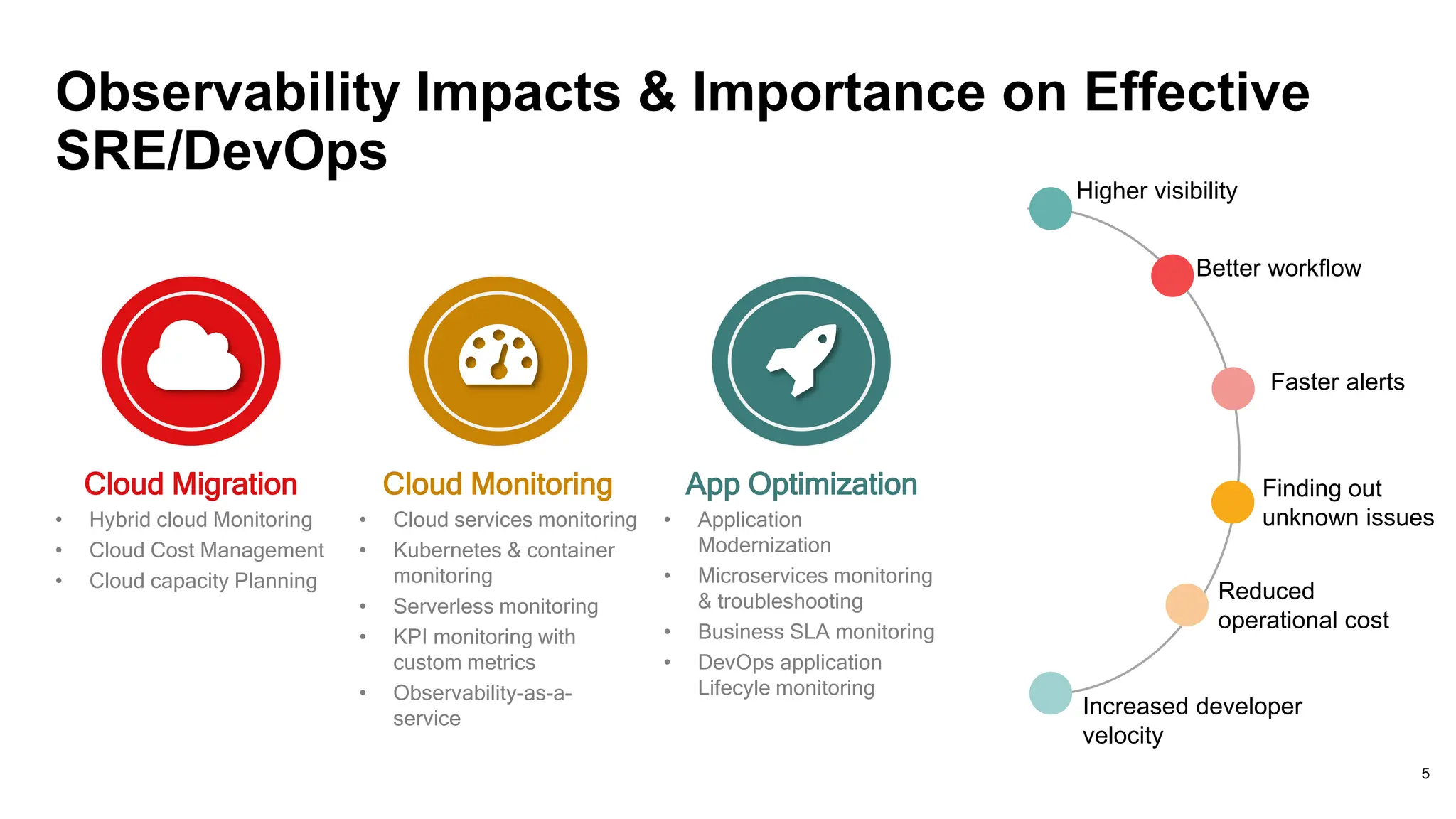
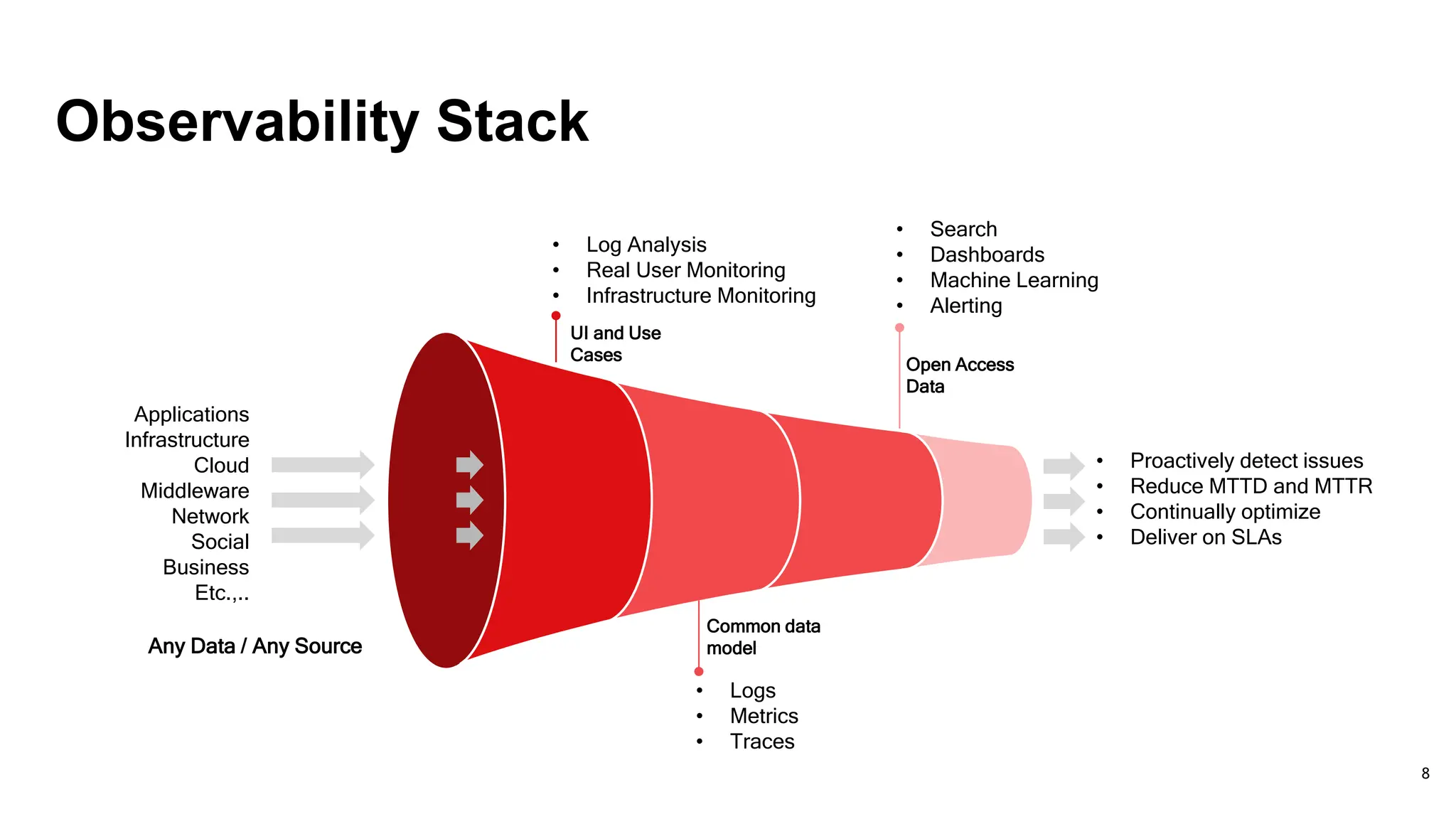
Describes how observability enhances cloud migration, app optimization, and operational cost reductions.
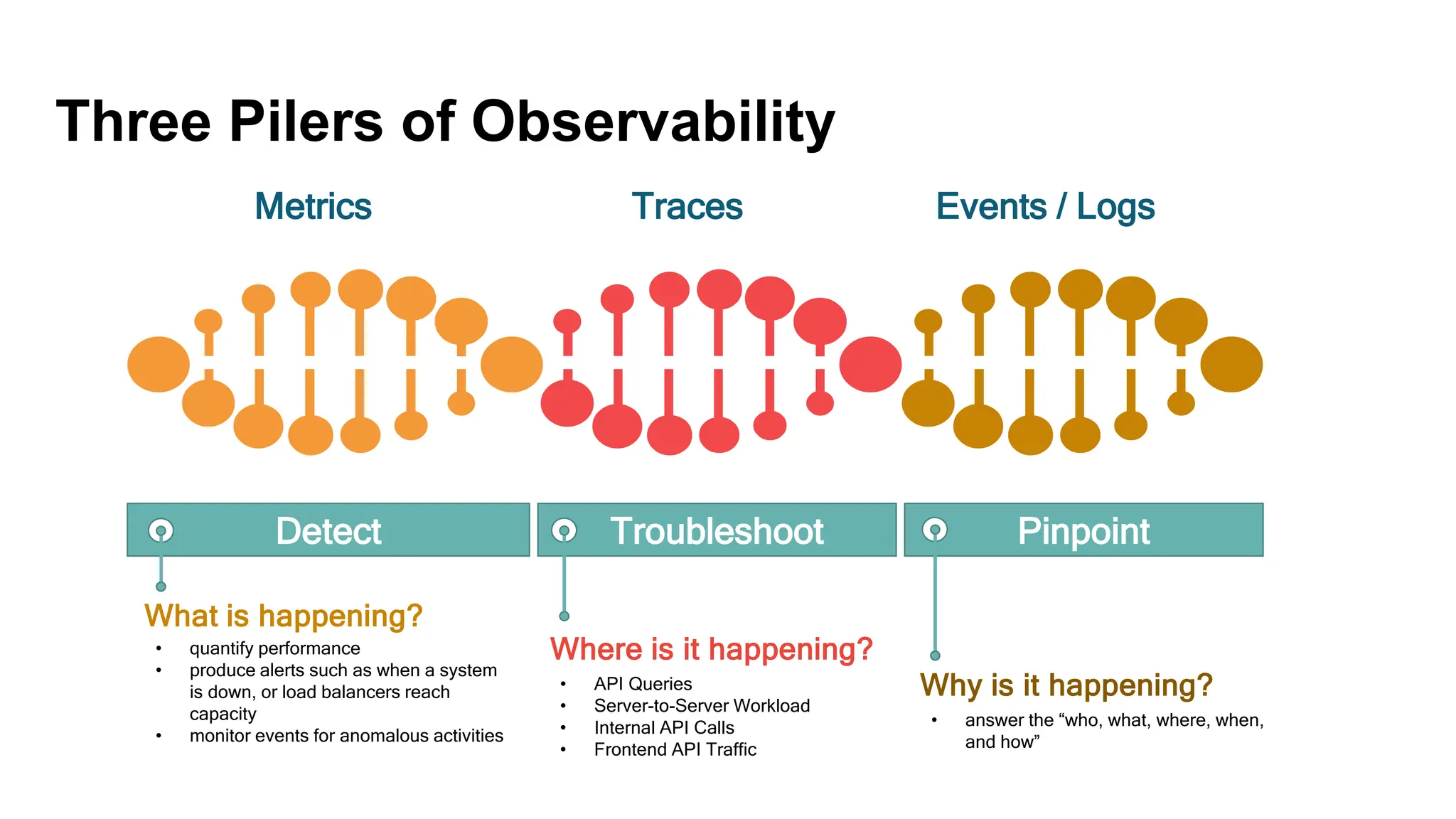
Discusses metrics, traces, and events/logs as foundational elements for detecting and troubleshooting issues.
Highlights benefits such as faster issue resolution, improved reliability, and future growth of observability adoption.
Explains the components involved in observability including monitoring, analysis, and proactive issue detection.
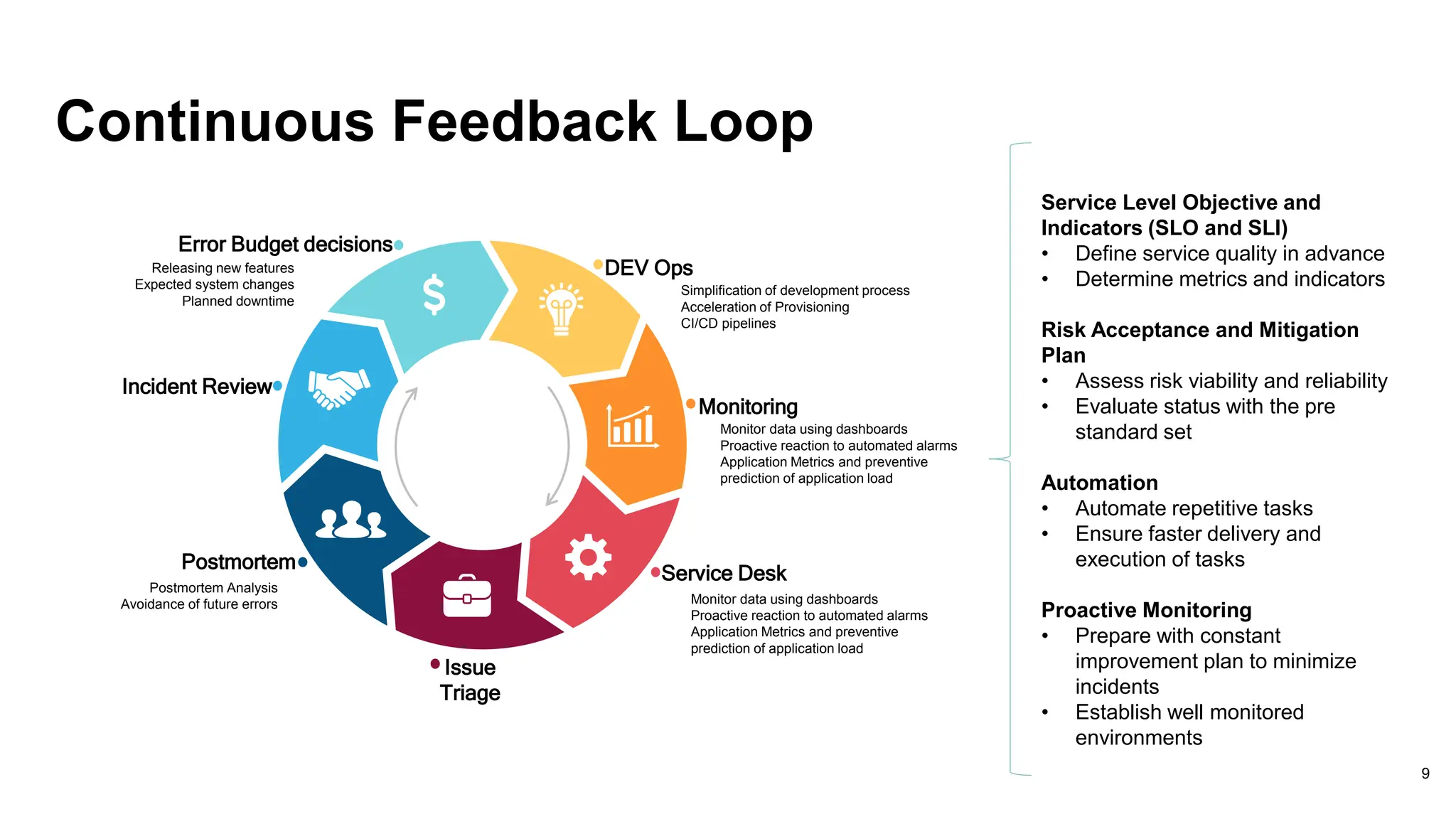
Details the integration of monitoring and proactive actions in development processes for improved efficiencies.
Defines observability as a framework, emphasizing its role in data-driven insights and operational transparency.
Presents insights from industry leaders on the differences and relevance of observability compared to monitoring.














































































