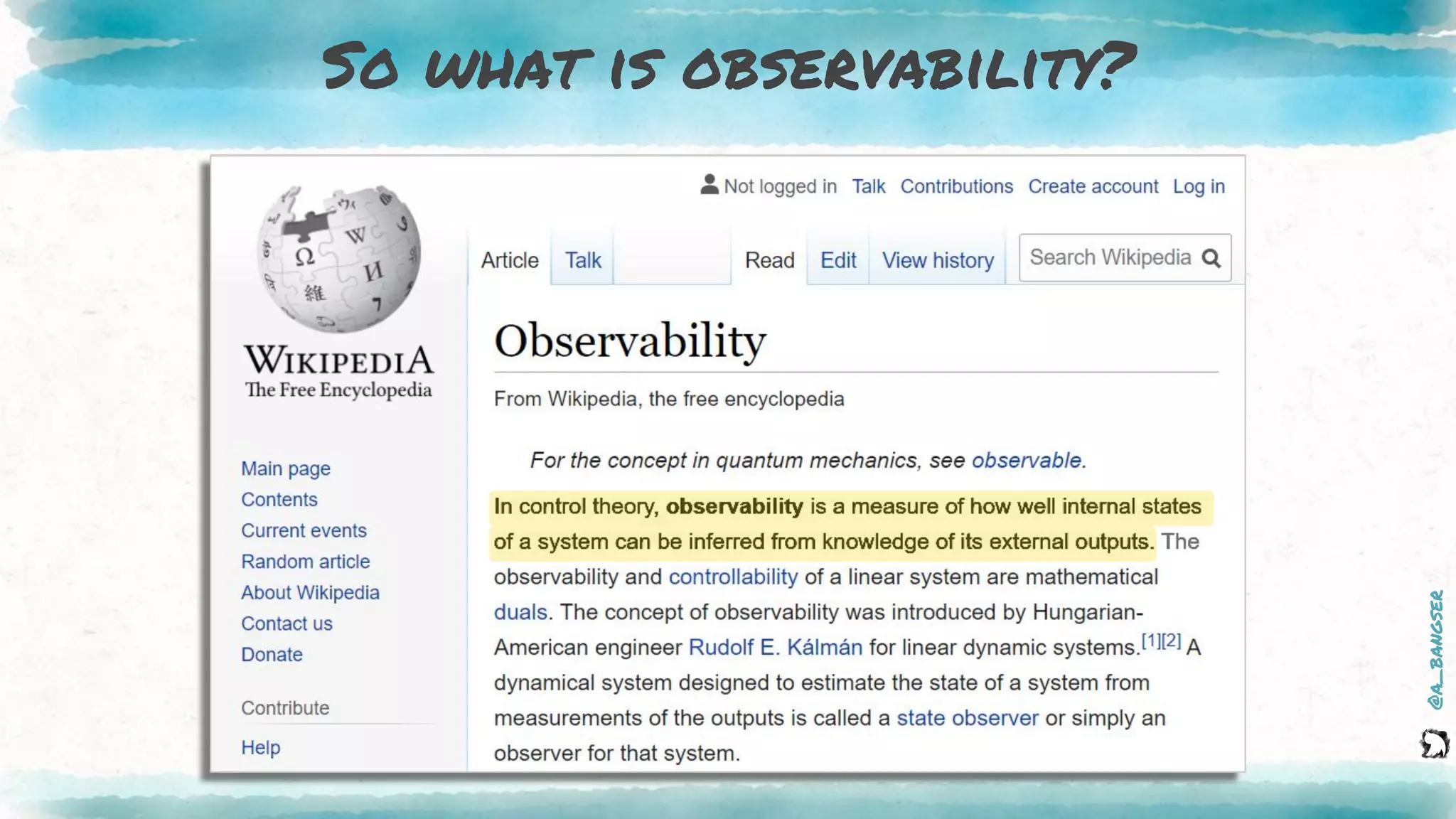
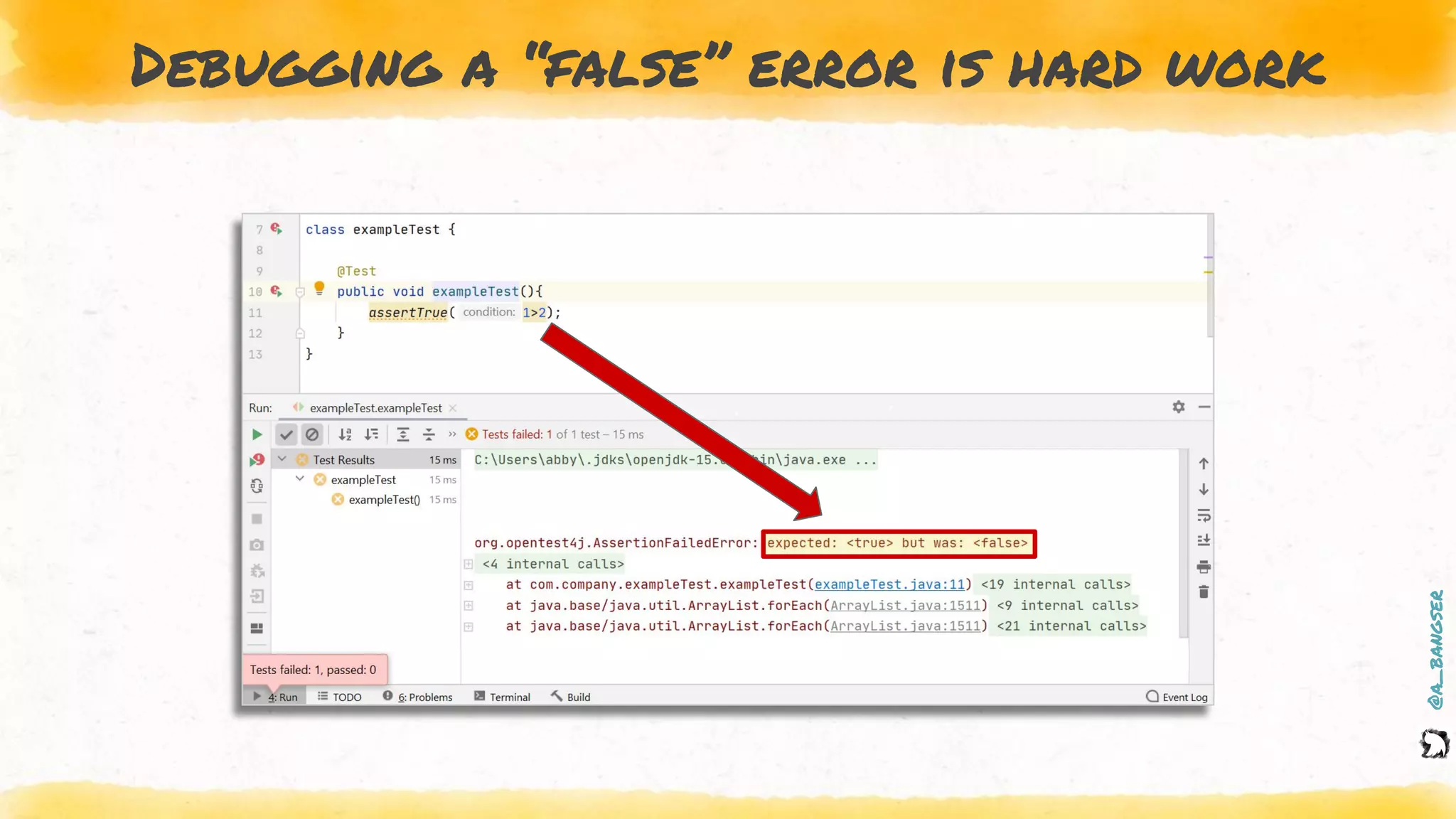
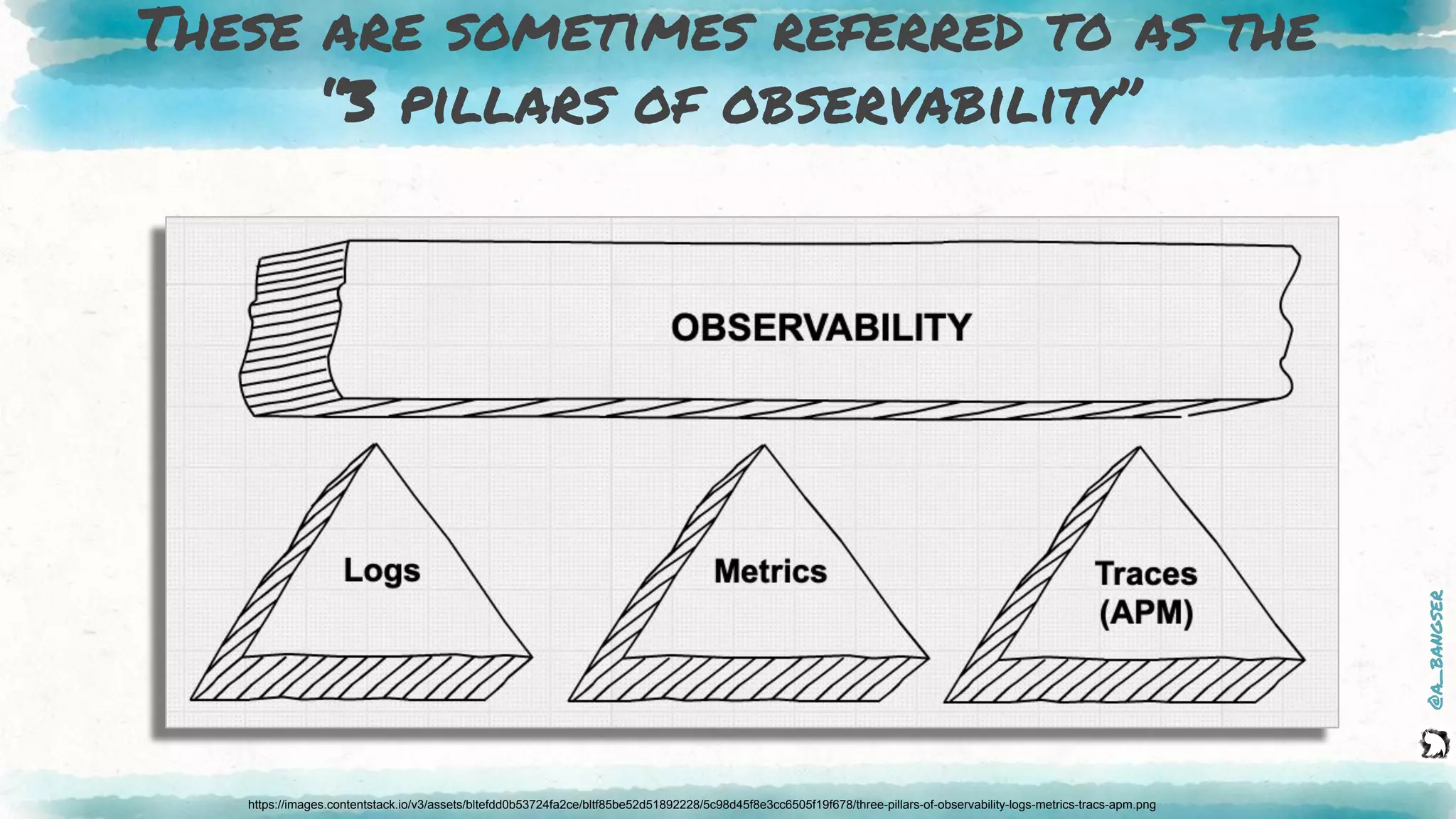
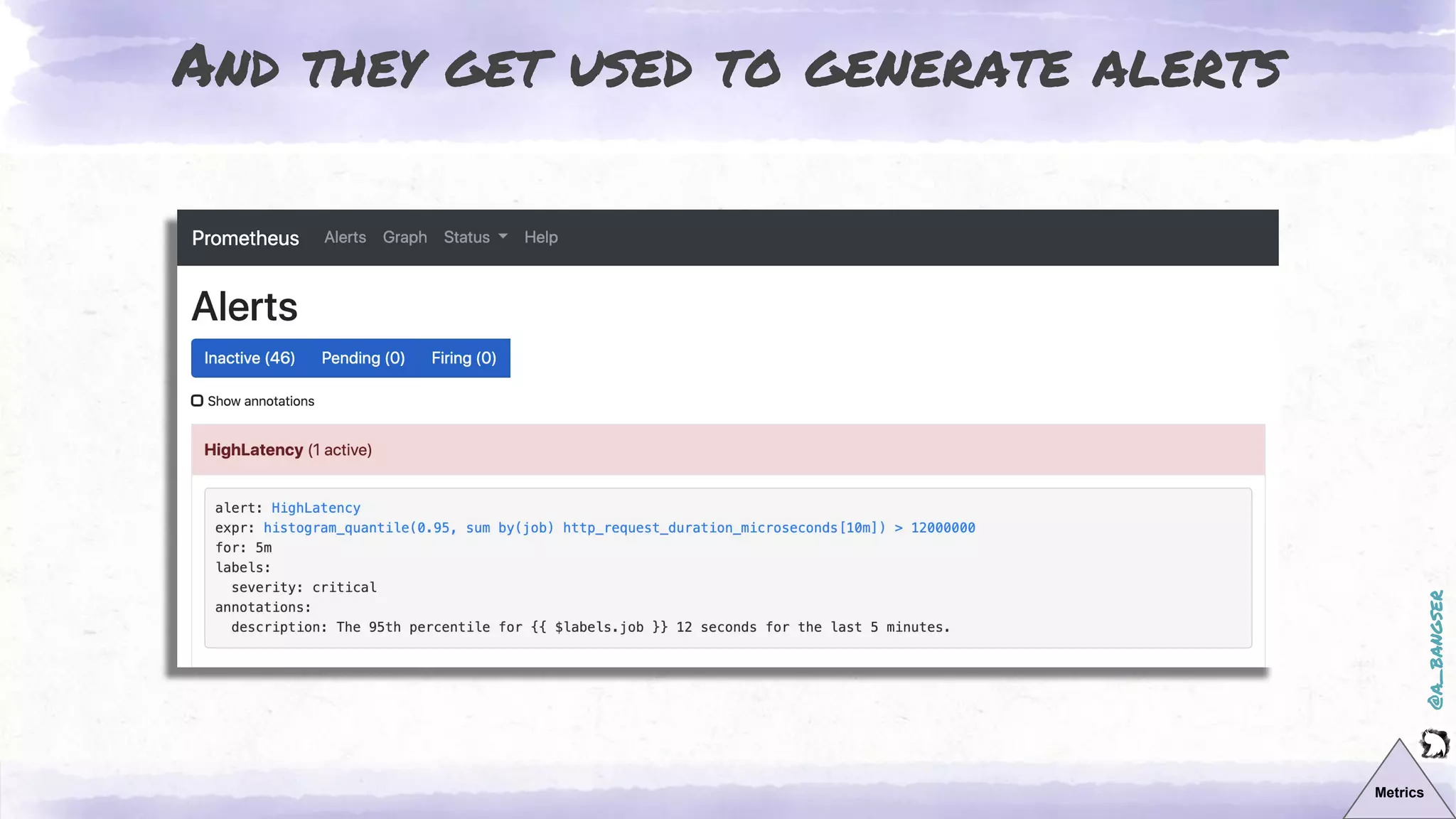
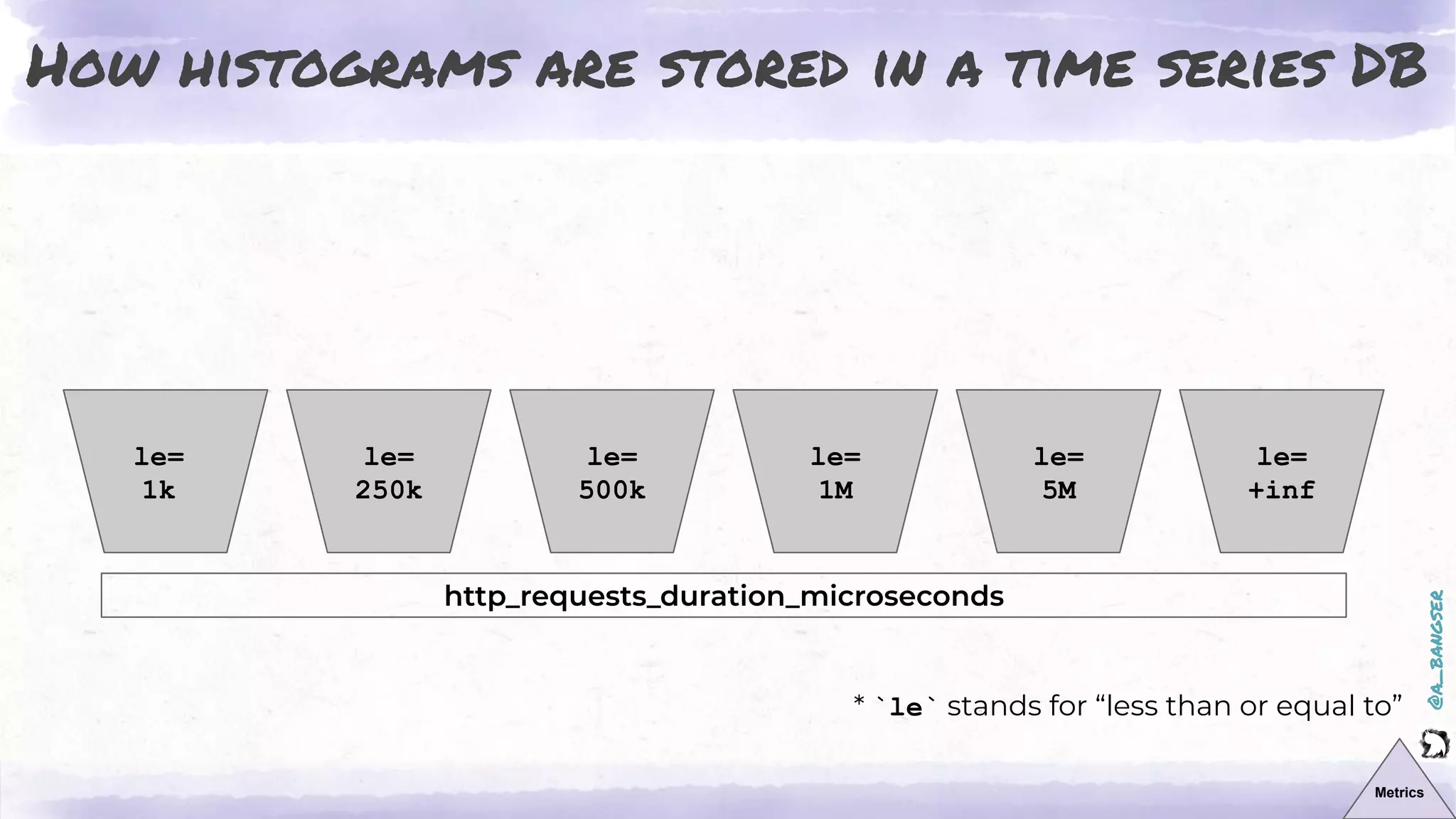
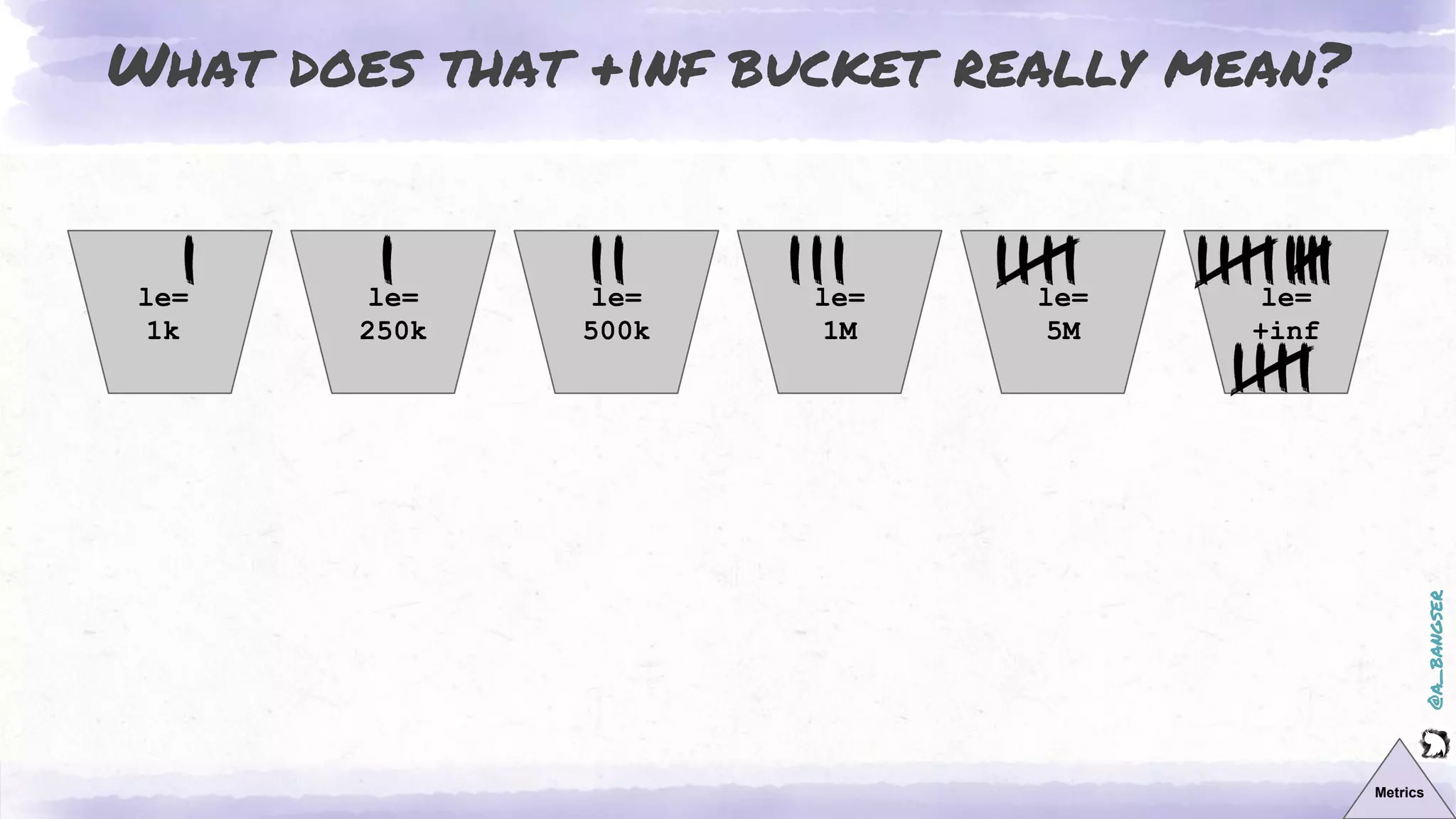
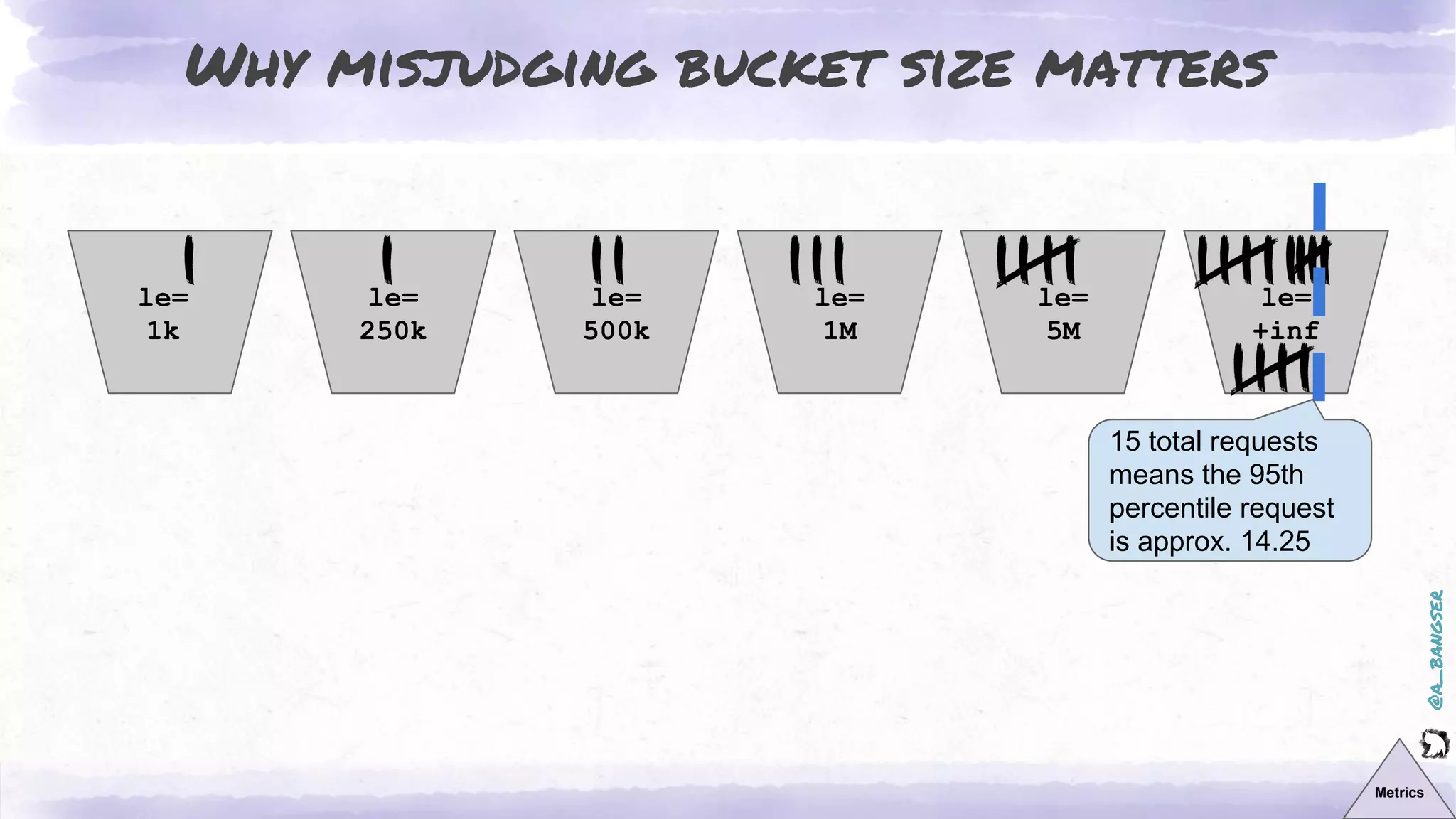
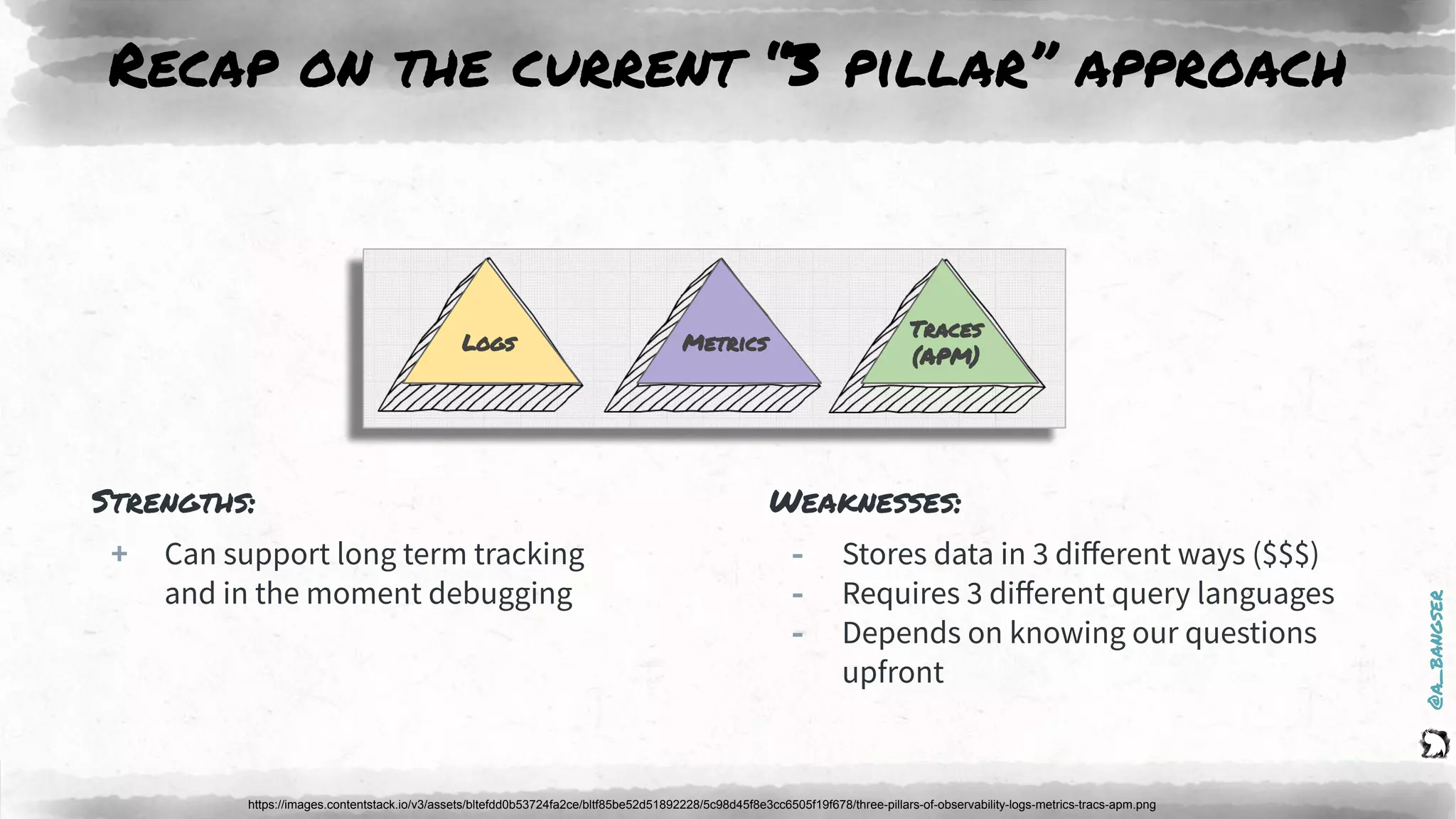
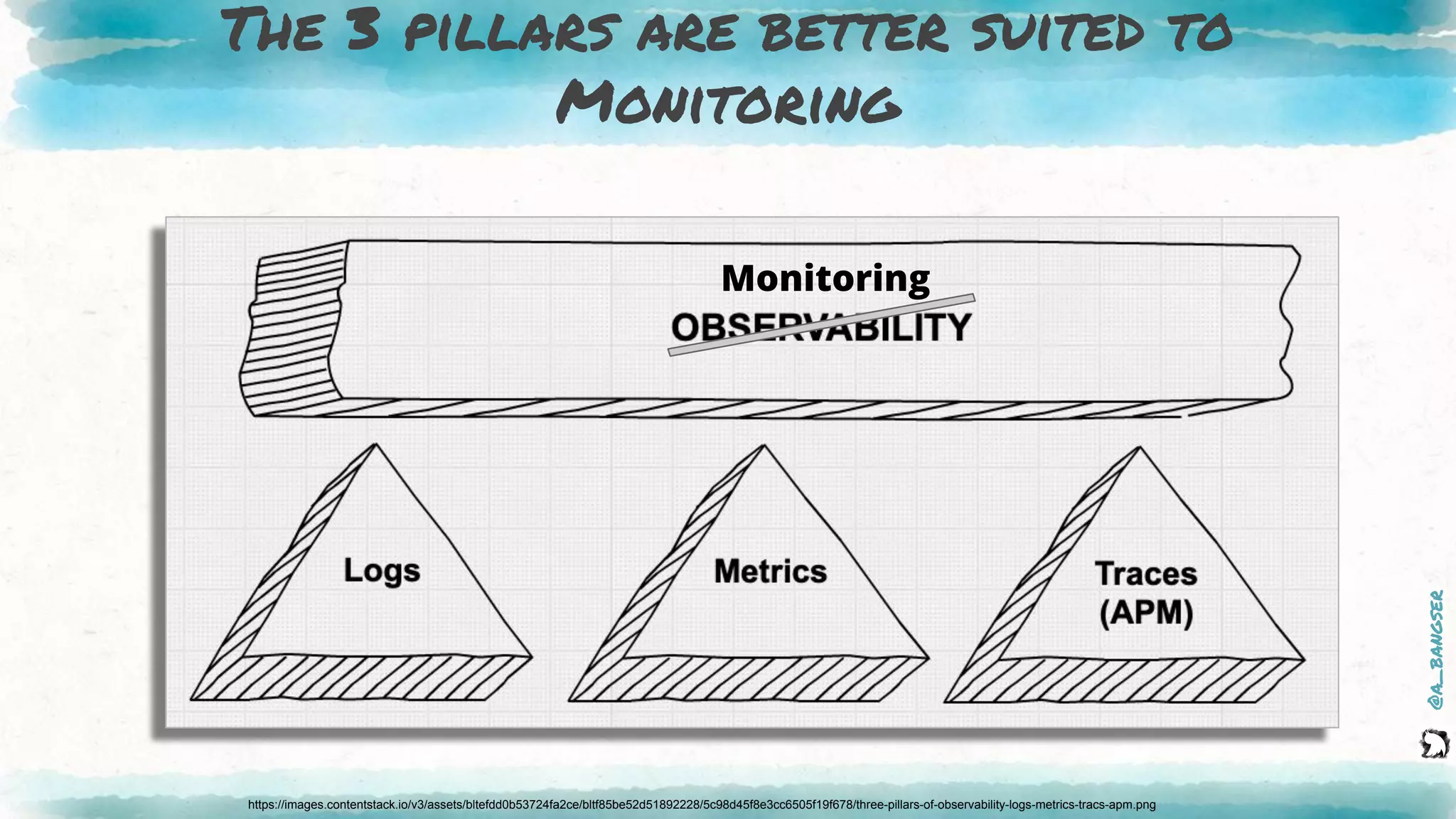
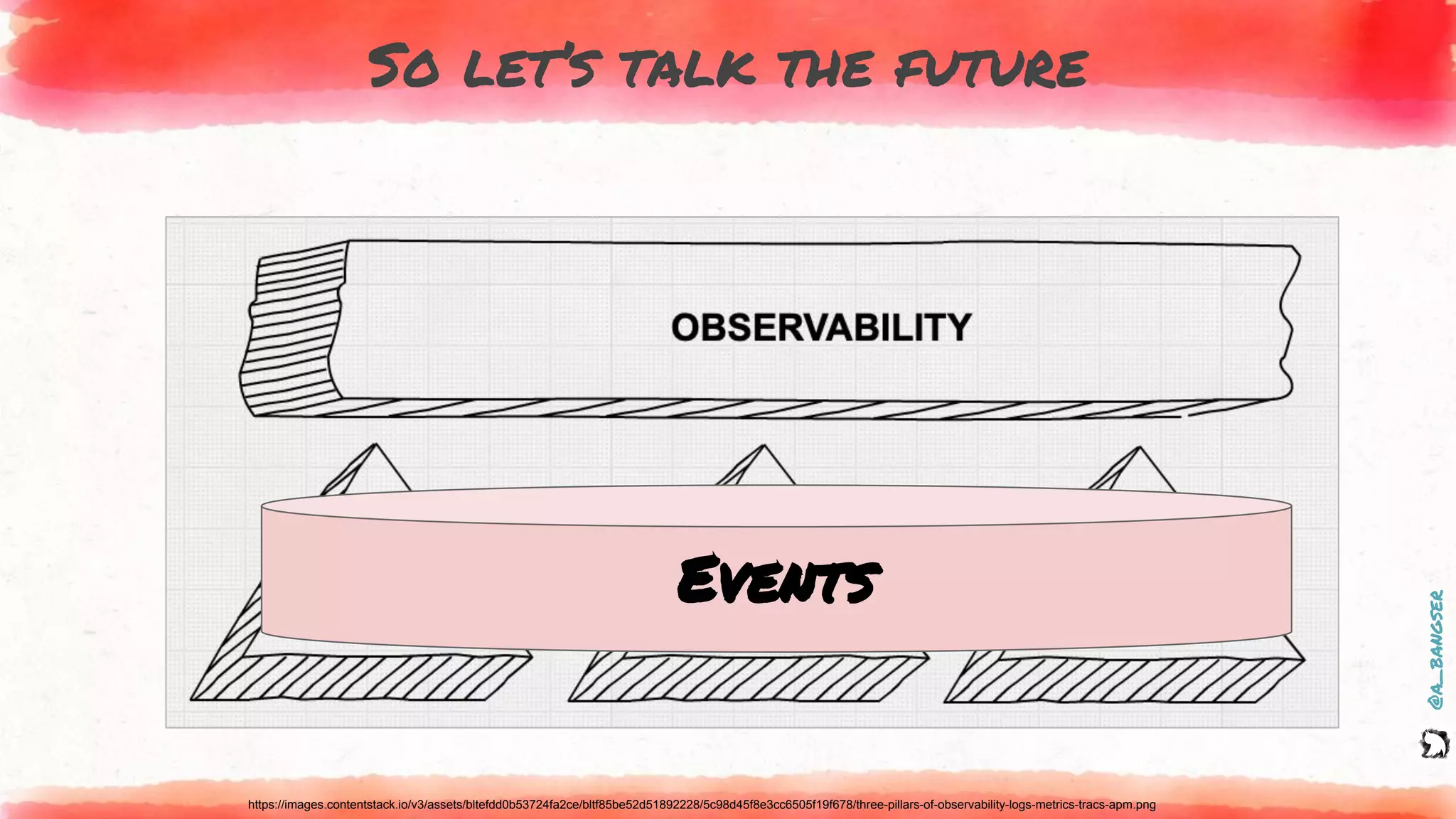
The document discusses observability as a vital tool in platform engineering, emphasizing its role in understanding systems and improving testing methodologies. It outlines the three pillars of observability—logs, metrics, and traces—along with their strengths and weaknesses, and highlights future trends in observability, such as context-rich events. The author advocates for a focus on data-driven decision making and the importance of deep domain knowledge in driving effective observability practices.



























![@a_bangser
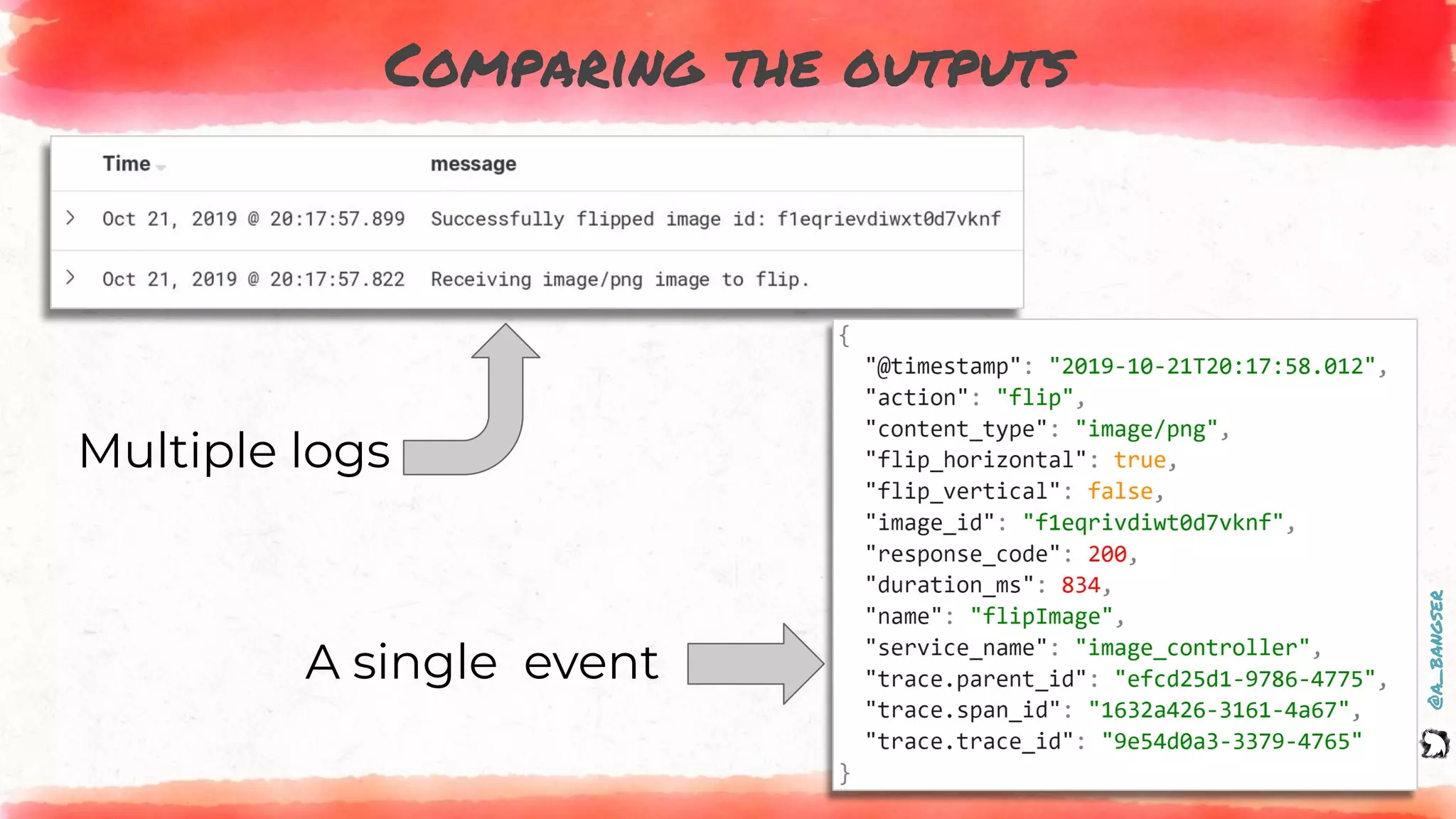
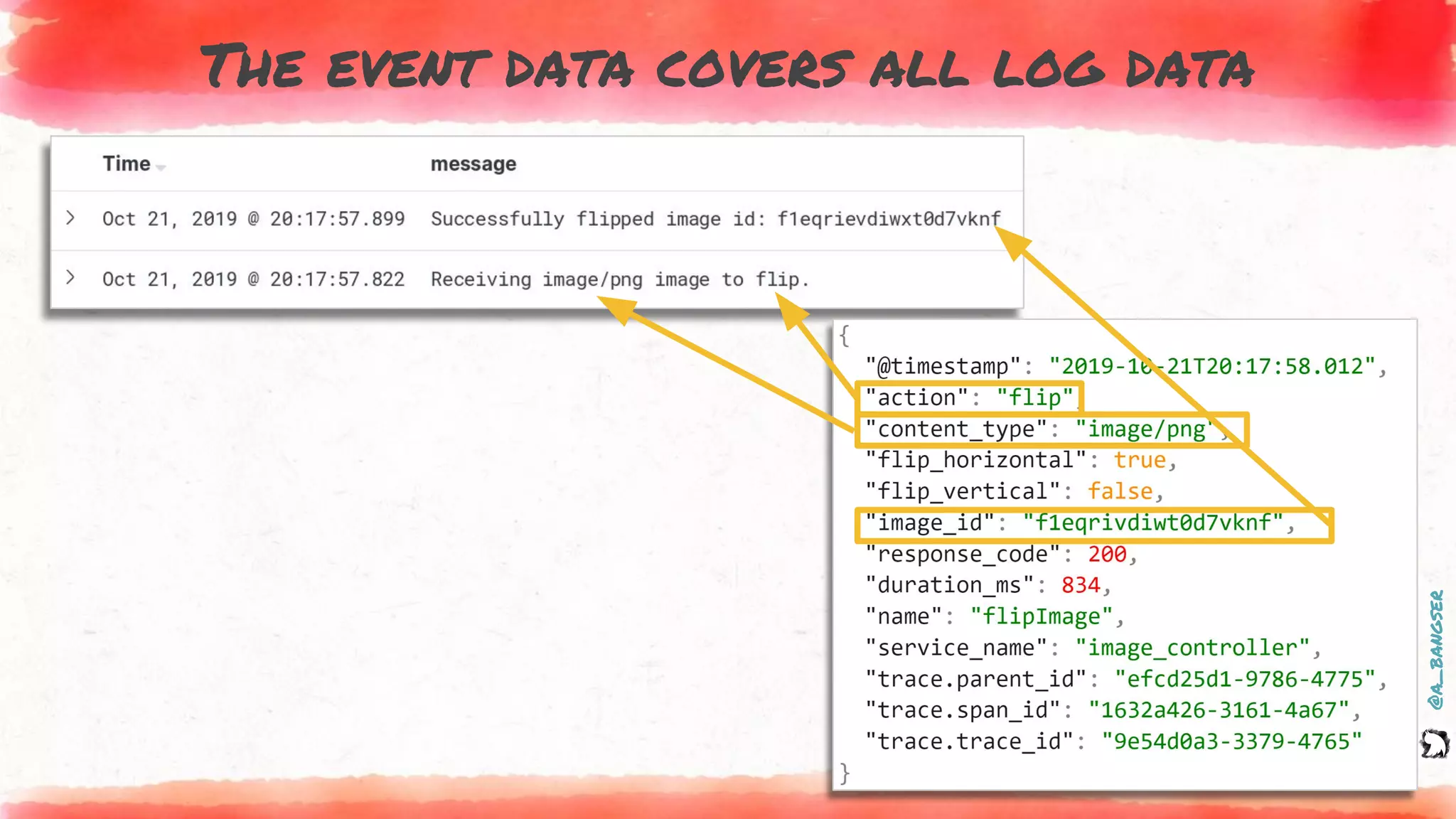
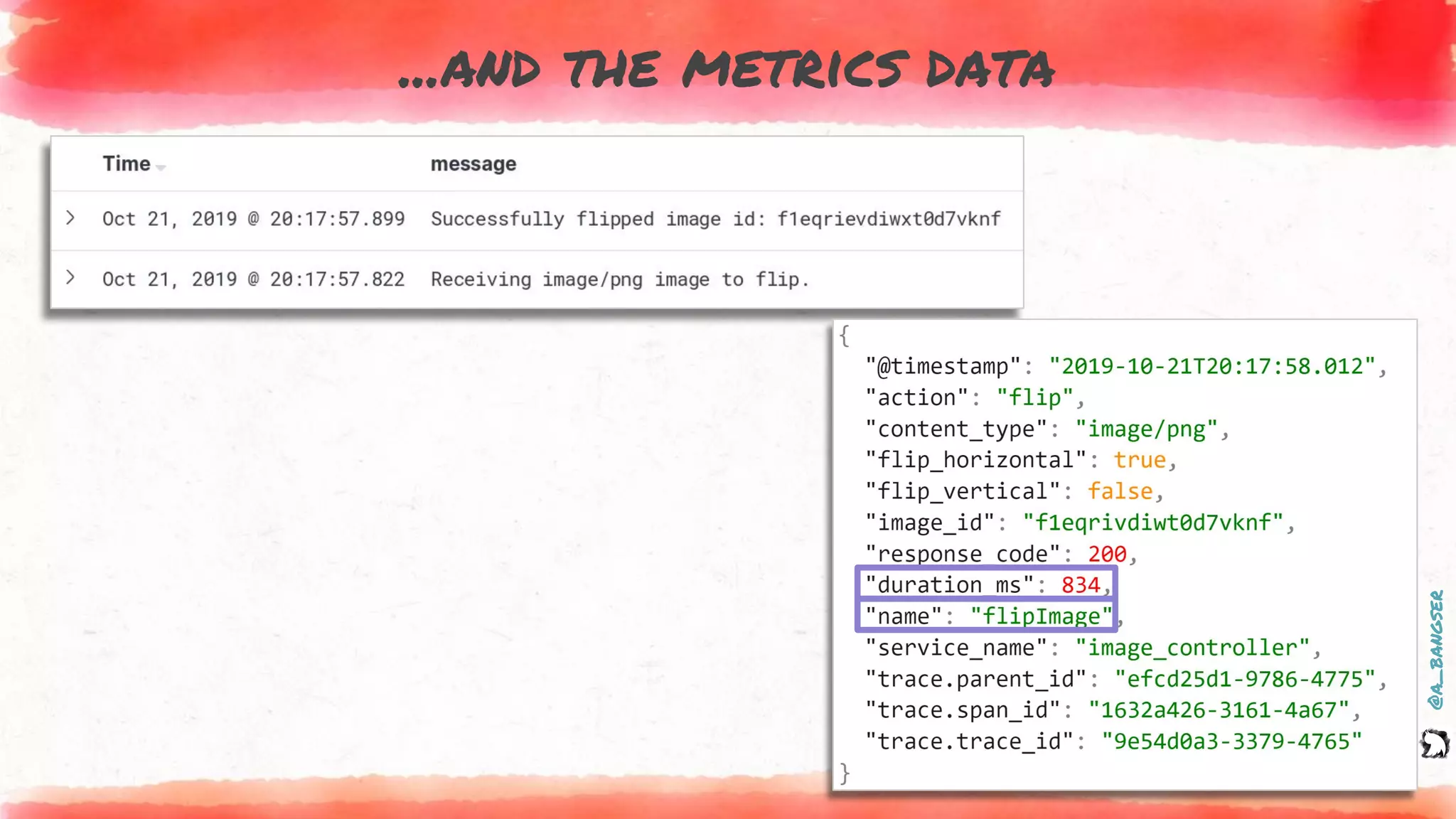
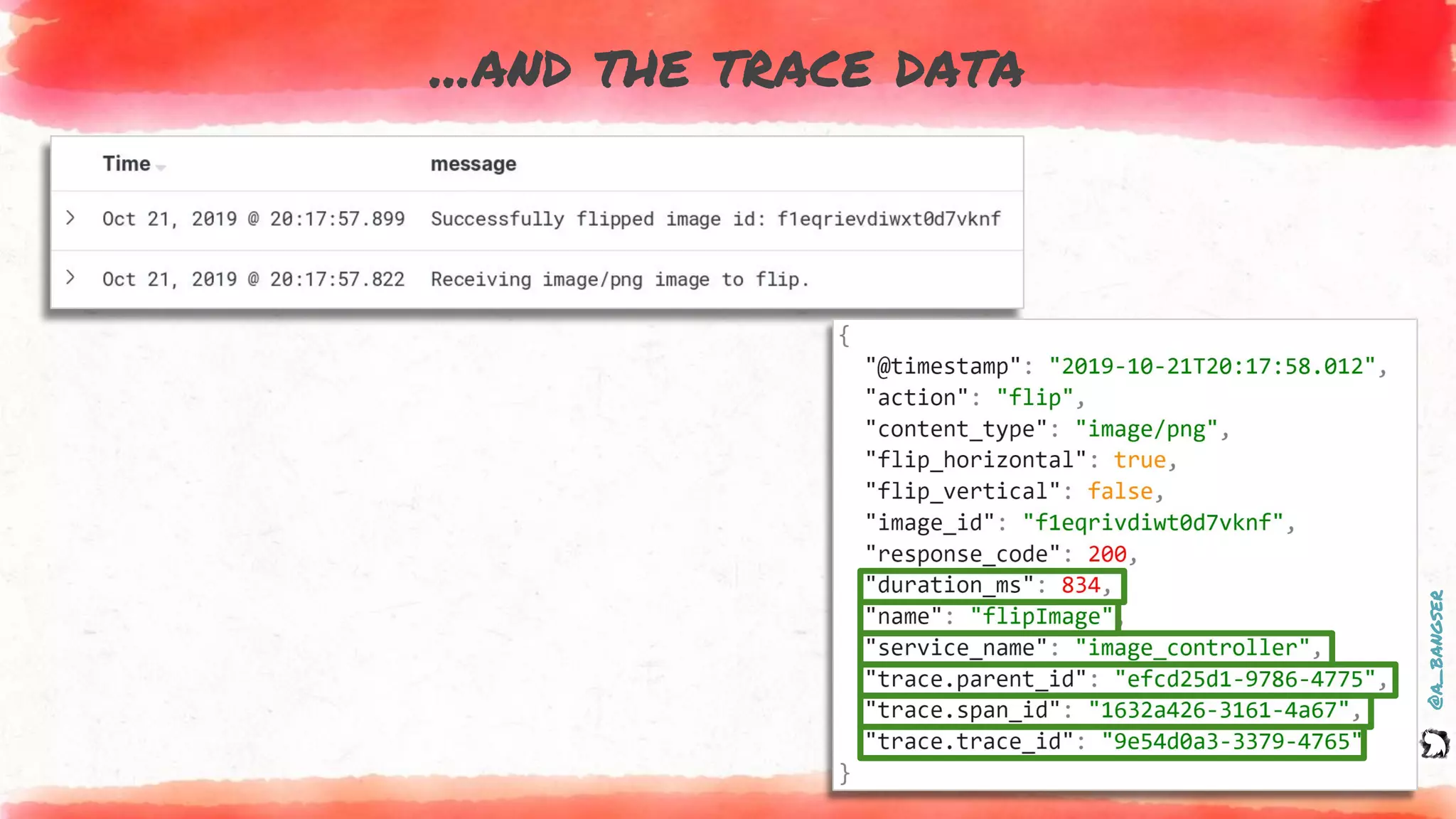
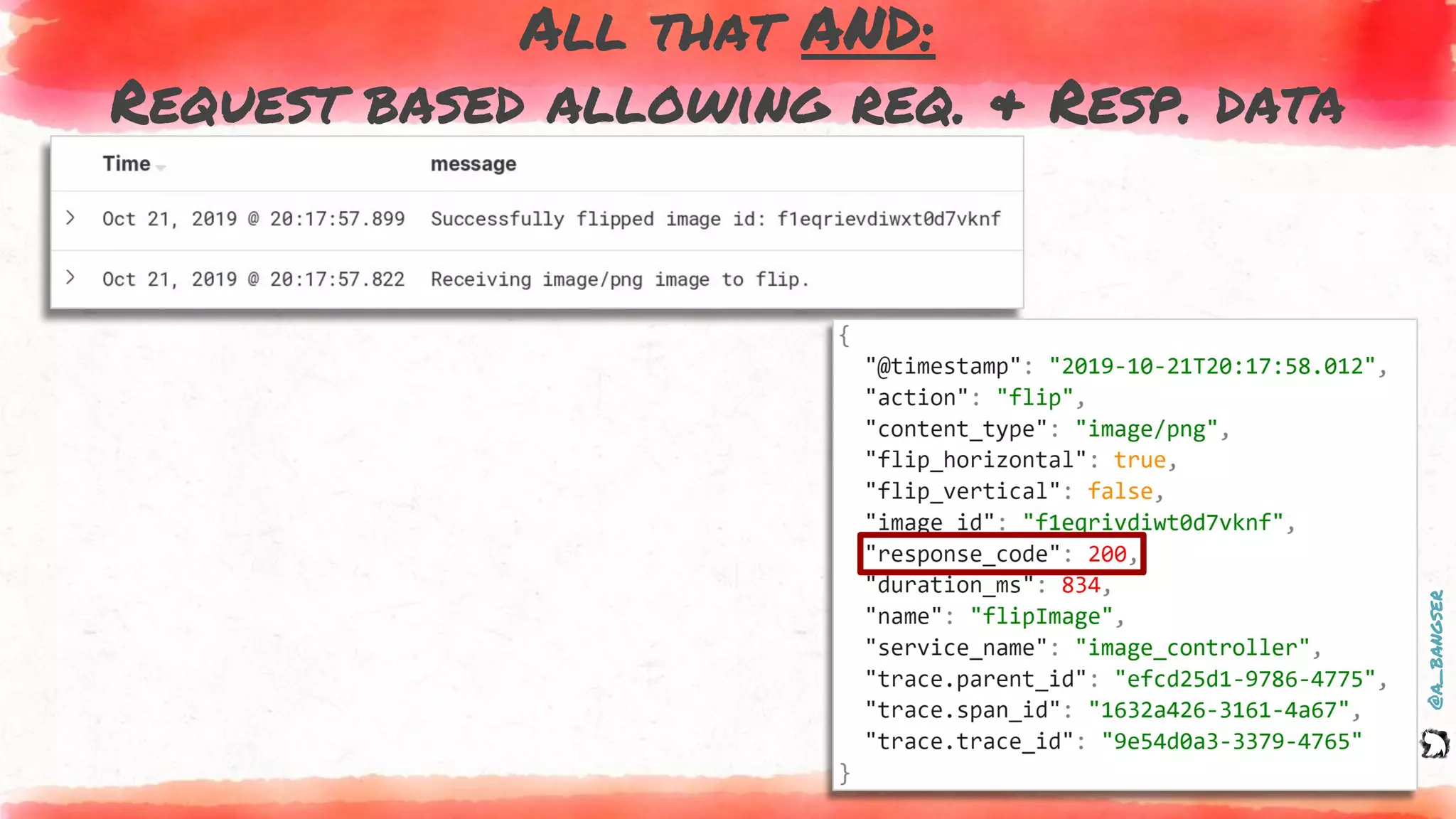
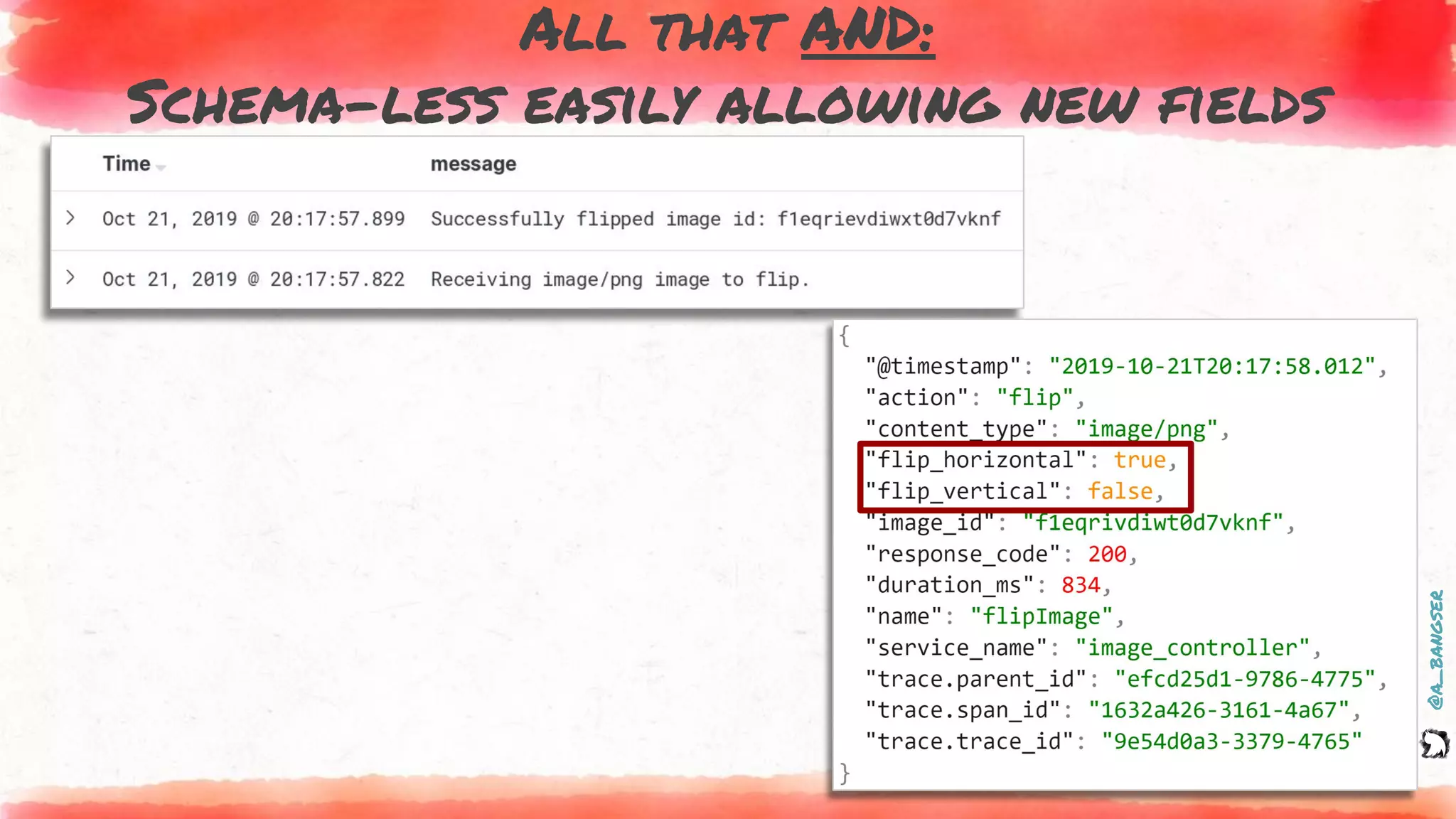
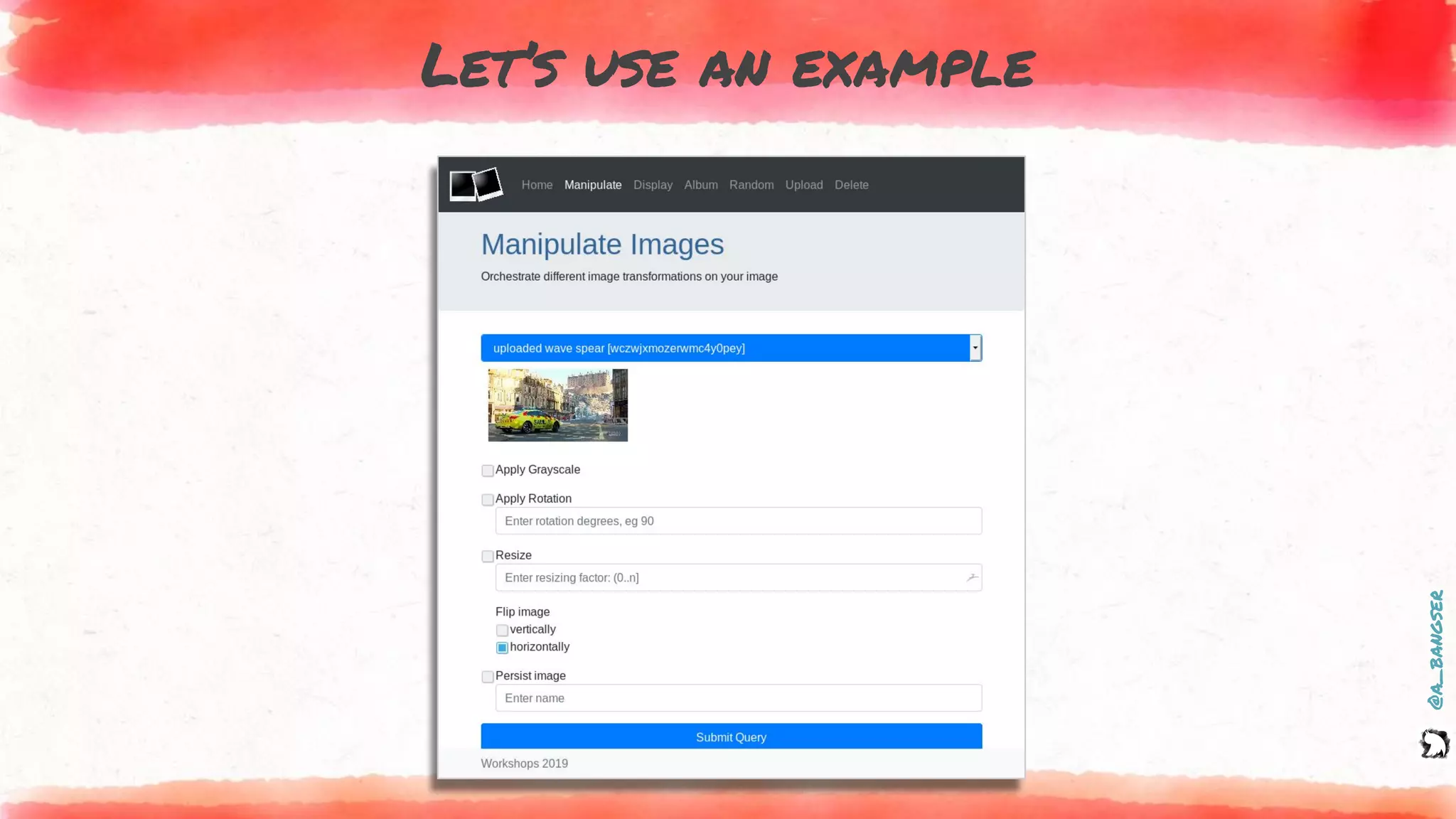
How logs and events are created
@PostMapping("flip")
public ResponseEntity flipImage(@RequestParam("image") MultipartFile file,
@RequestParam(value = "vertical") Boolean vertical,
@RequestParam(value = "horizontal") Boolean horizontal) {
EVENT.addFields(
new Pair("content.type", file.getContentType()),
new Pair("action", "flip"),
new Pair("flip_vertical", vertical),
new Pair("flip_horizontal", horizontal));
LOGGER.info("Receiving {} image to flip.", file.getContentType());
byte[] flippedImage = imageService.flip(file, vertical, horizontal);
LOGGER.info("Successfully flipped image id: {}", file.getId());
EVENT.addField("image_id", file.getId());
return new ResponseEntity<>(flippedImage, headers, HttpStatus.OK);
}
EVENT.addFields(
new Pair("content.type", file.getContentType()),
new Pair("action", "flip"),
new Pair("flip_vertical", vertical),
new Pair("flip_horizontal", horizontal));
LOGGER.info("Successfully flipped image id: {}", file.getId()");
LOGGER.info("Receiving {} image to flip.", file.getContentType());
EVENT.addField("image_id", file.getId());](https://image.slidesharecdn.com/copyof2020-11-18applitools1-201118101007/75/Demystifying-observability-51-2048.jpg)