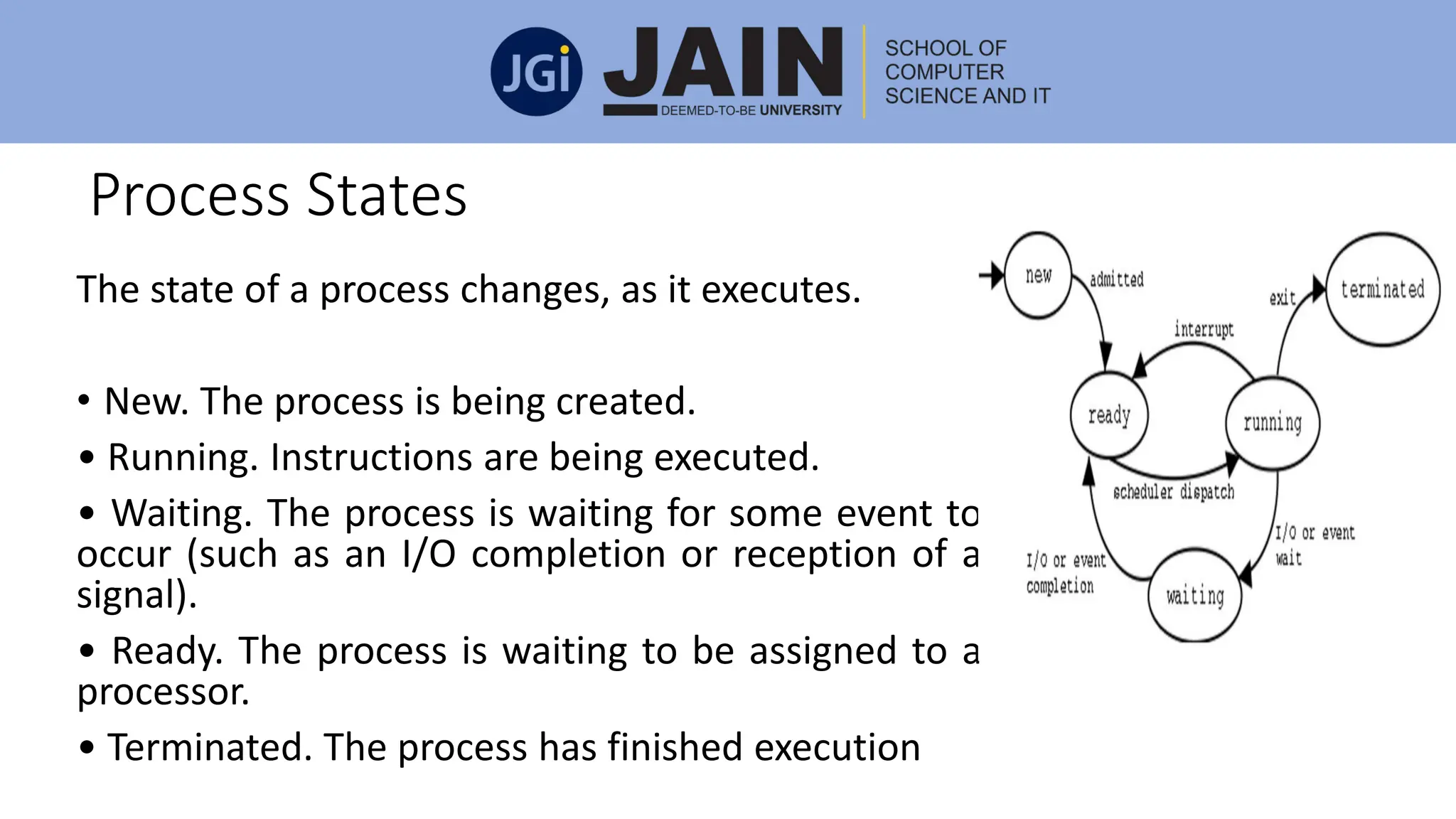
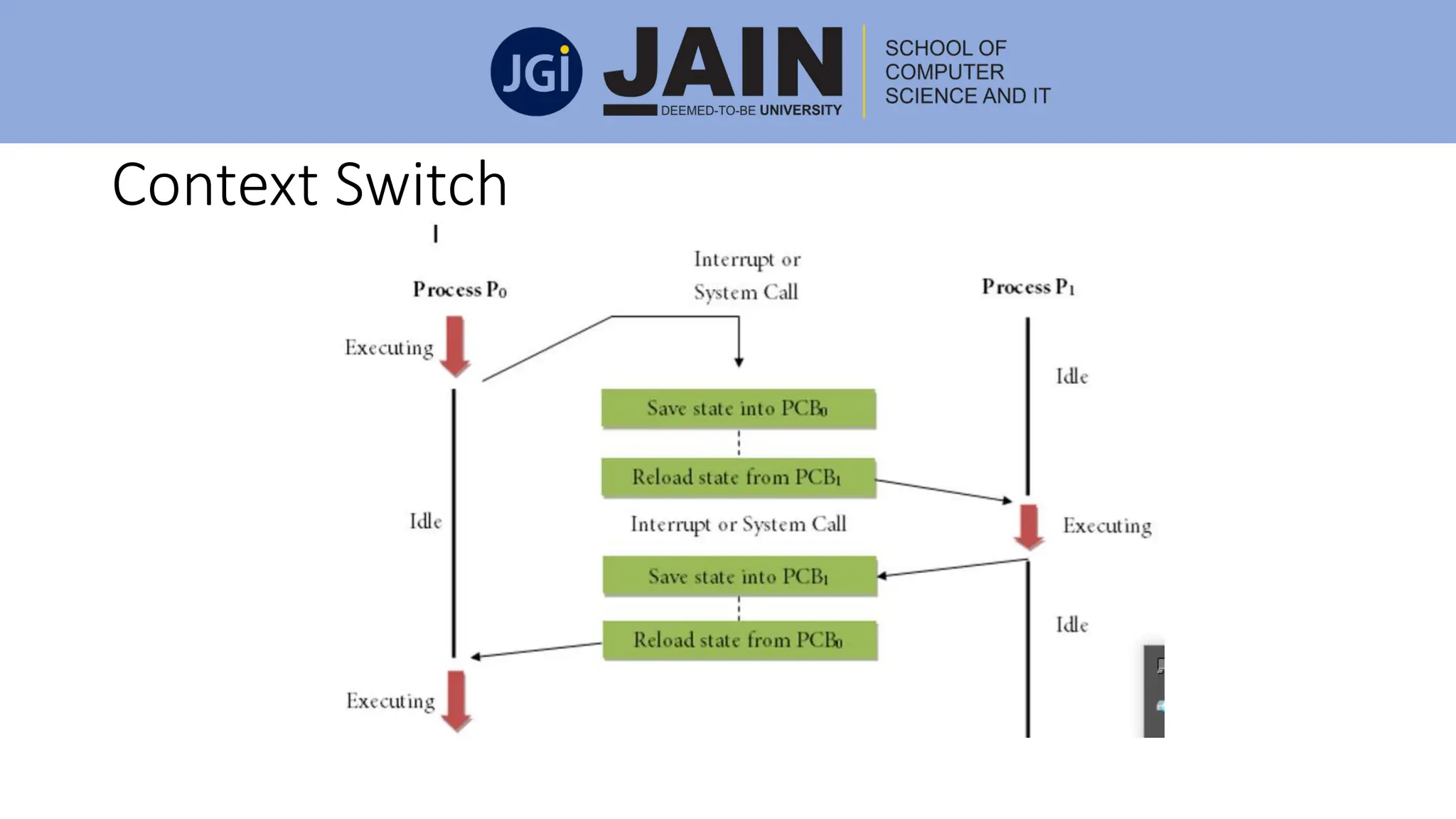
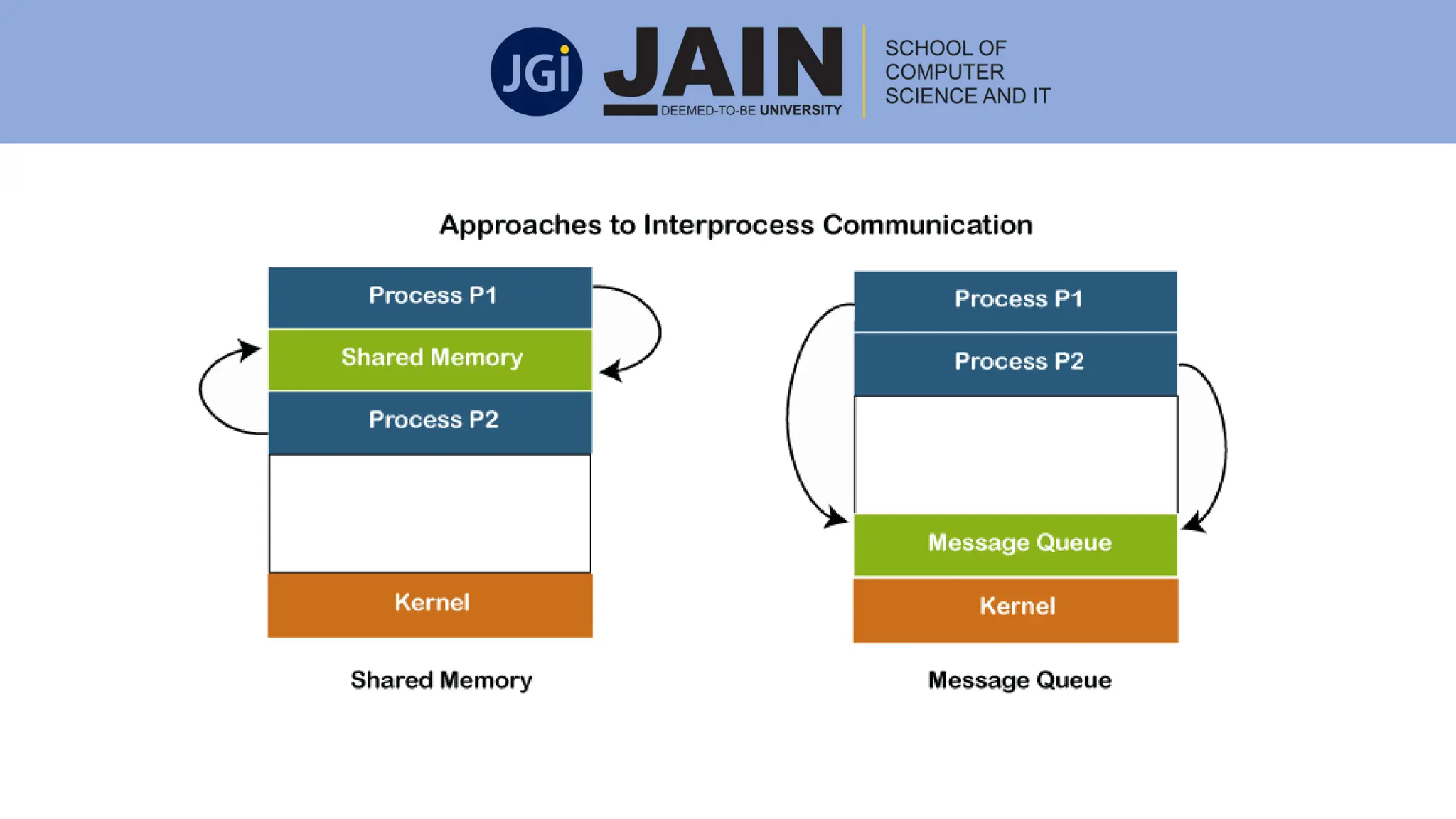
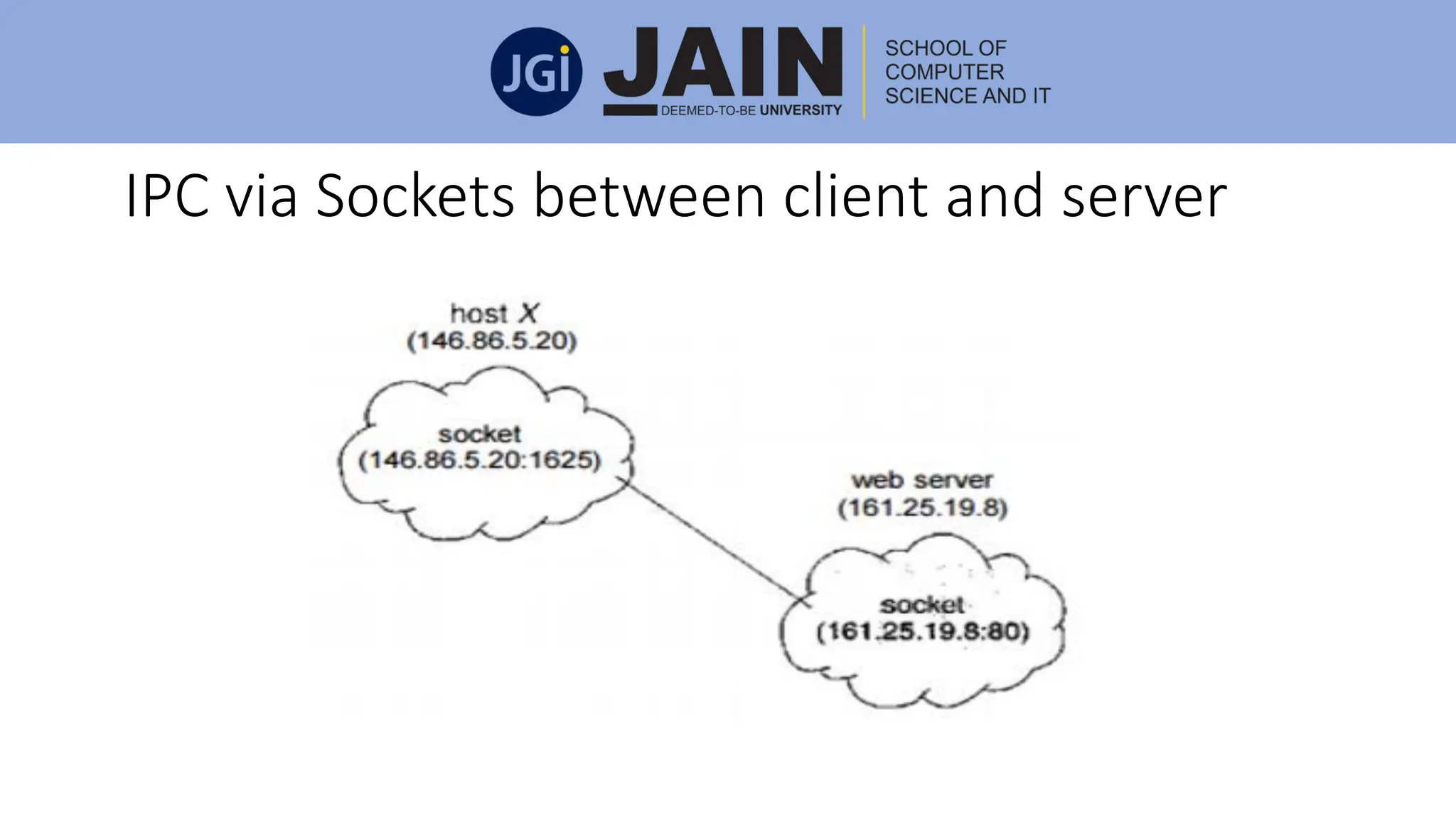
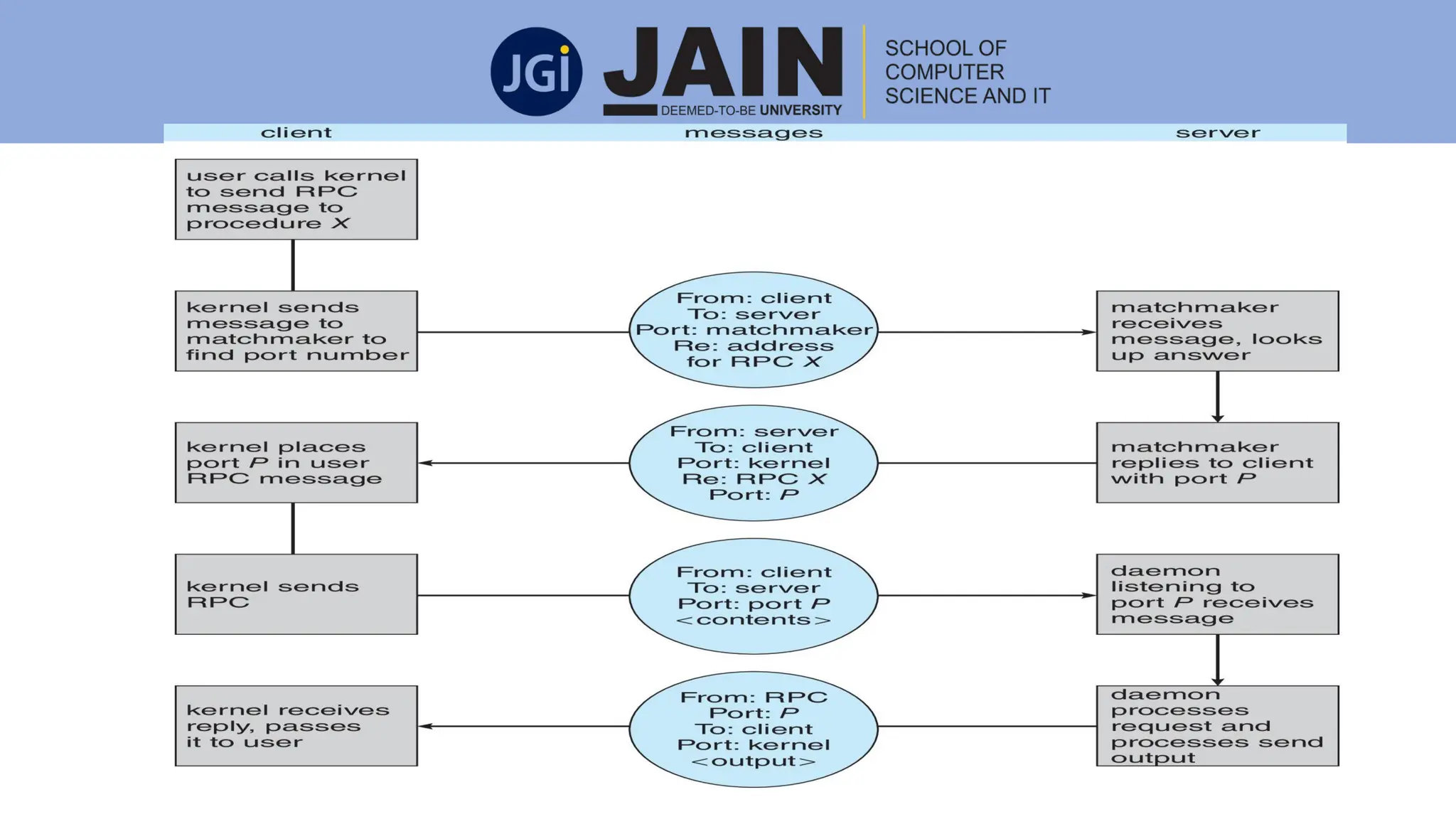
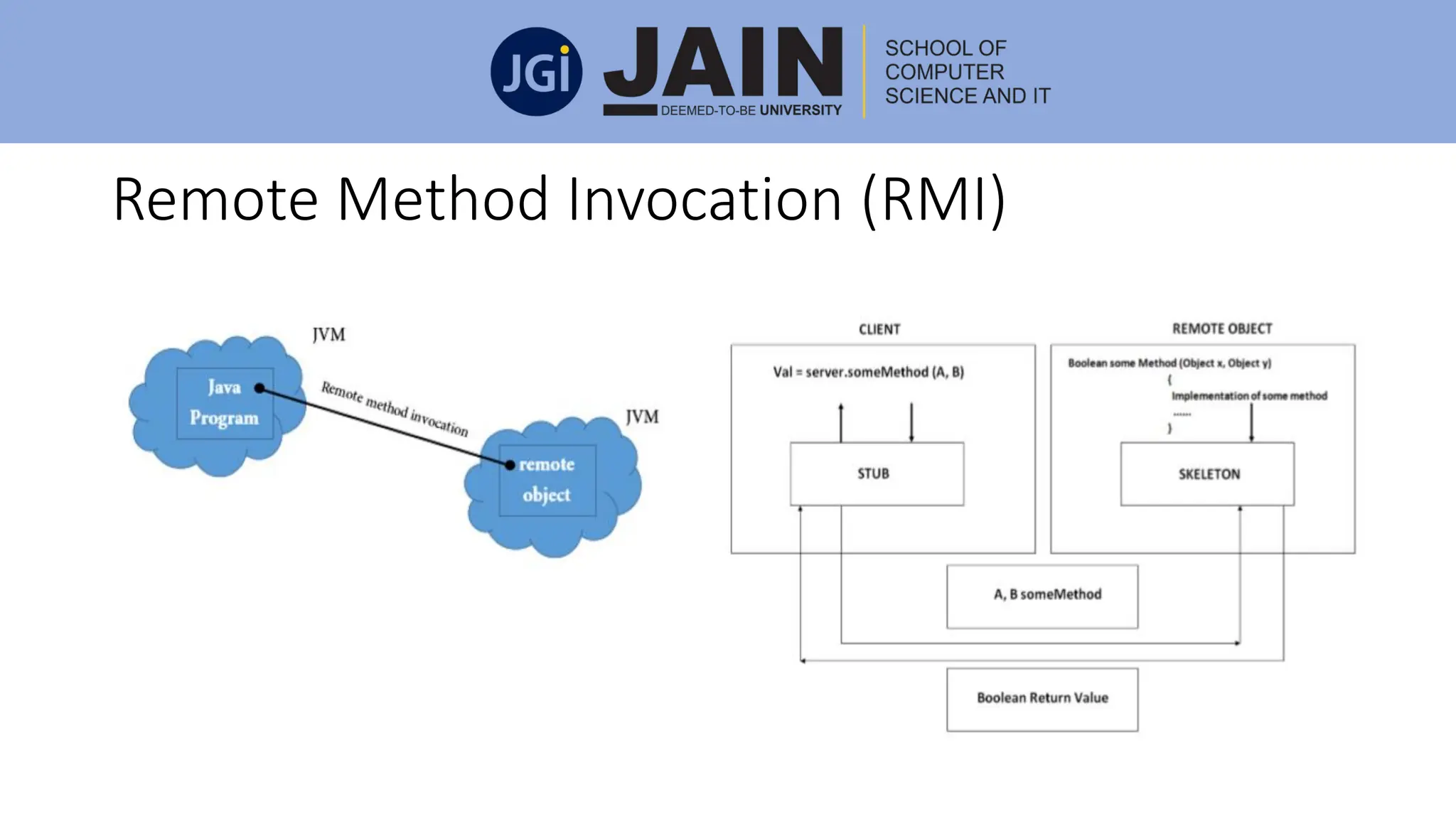
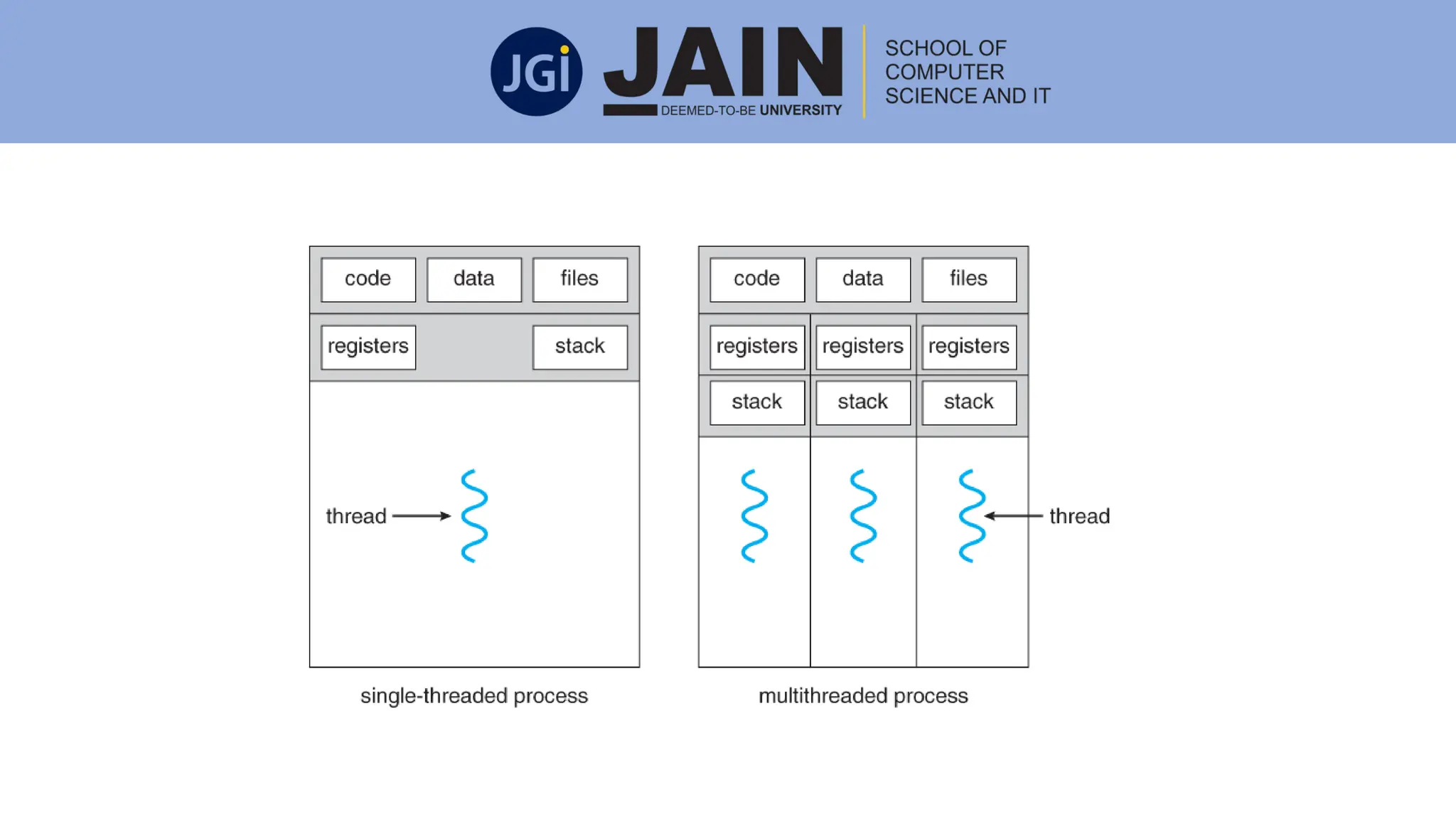
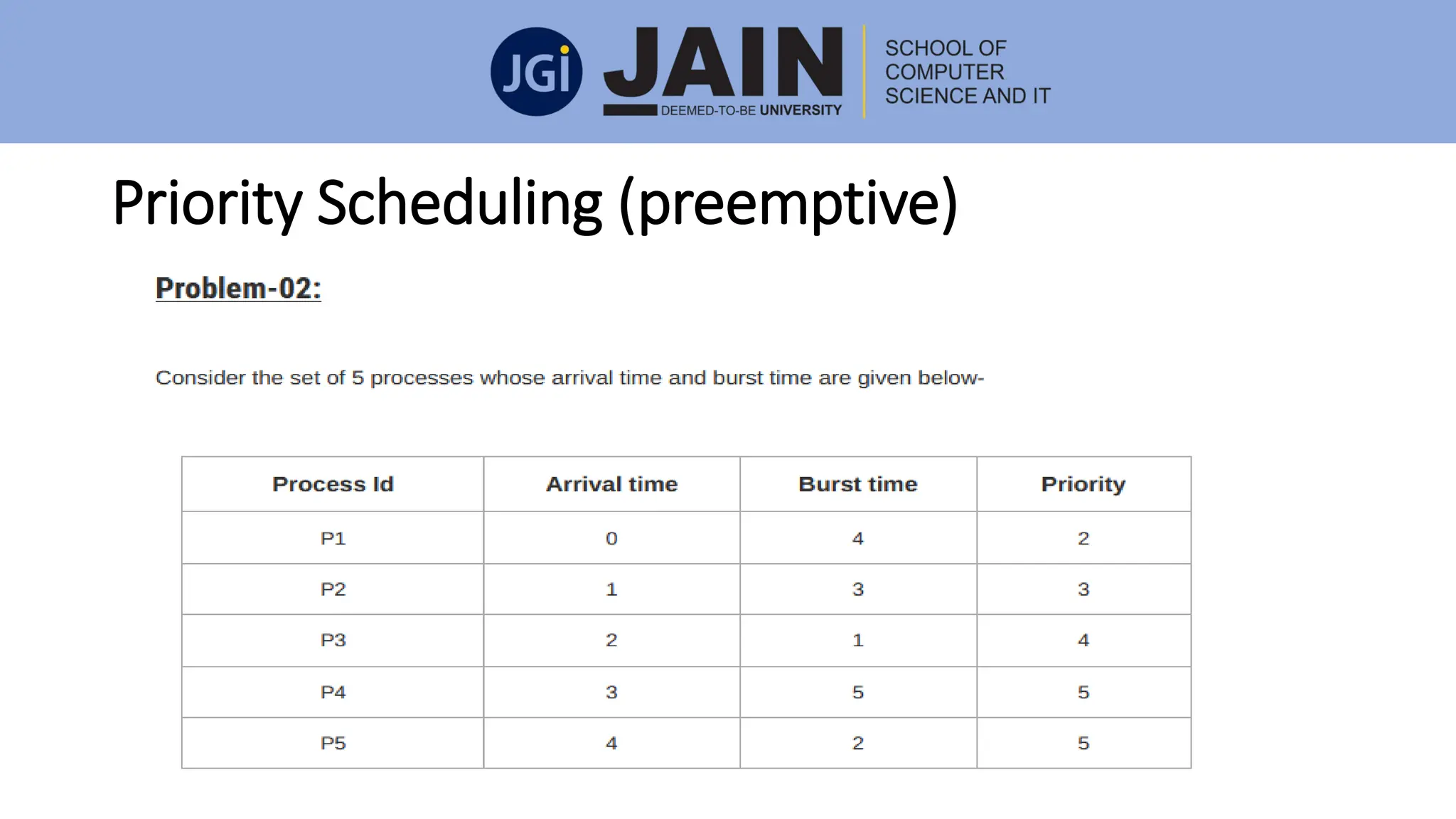
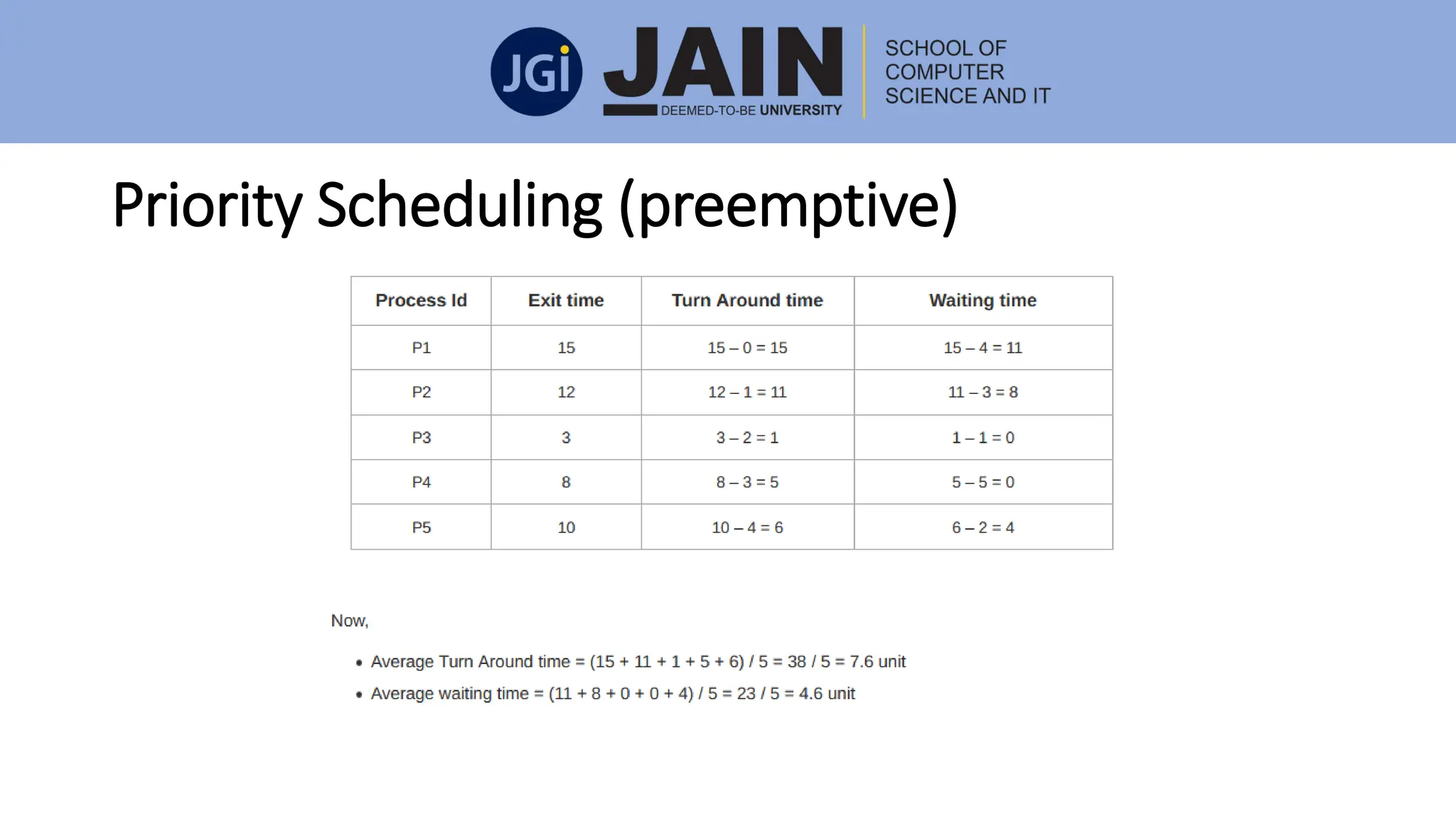
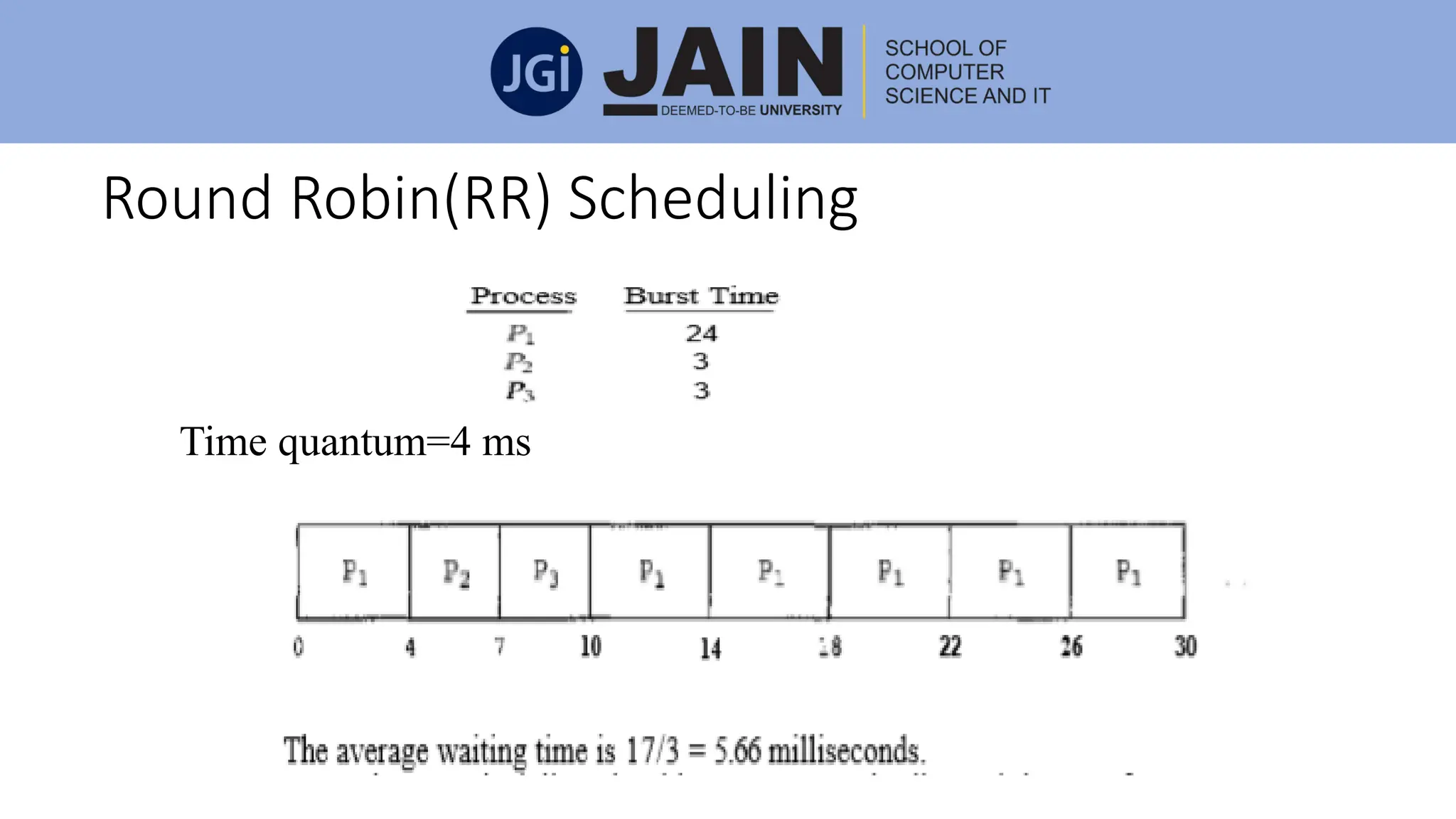
This document discusses process management concepts including processes, threads, process scheduling, and inter-process communication. A process is defined as the fundamental unit of work in a system and requires resources like CPU time and memory. Key process concepts covered include process states, process layout in memory, and the process control block. Threads allow a process to execute multiple tasks simultaneously. Process scheduling and context switching are also summarized. Methods of inter-process communication like shared memory and message passing are described along with examples of client-server communication using sockets, remote procedure calls, and remote method invocation.