Download to read offline


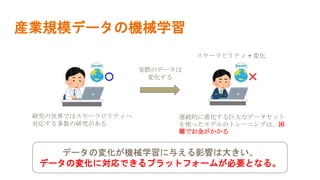











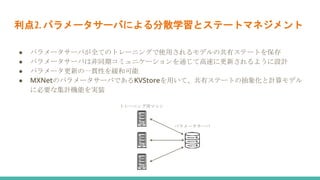
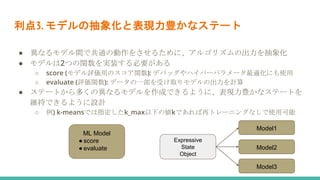


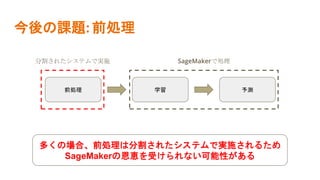





産業規模のデータを扱う機械学習では、データが変化することの影響により、計算にかかる時間やコストが爆発的に増えていきます。 Amazonが開発しているSageMakerを用いることで、時間もコストも大幅に減らすことができるという論文を解説しました。 参考にした論文はこちら Liberty, Edo, et al. "Elastic machine learning algorithms in amazon sagemaker." Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020.































![[CTO Night & Day 2019] ML services: MLOps #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessionml-191027185903-thumbnail.jpg?width=640&height=640&fit=bounds)



































