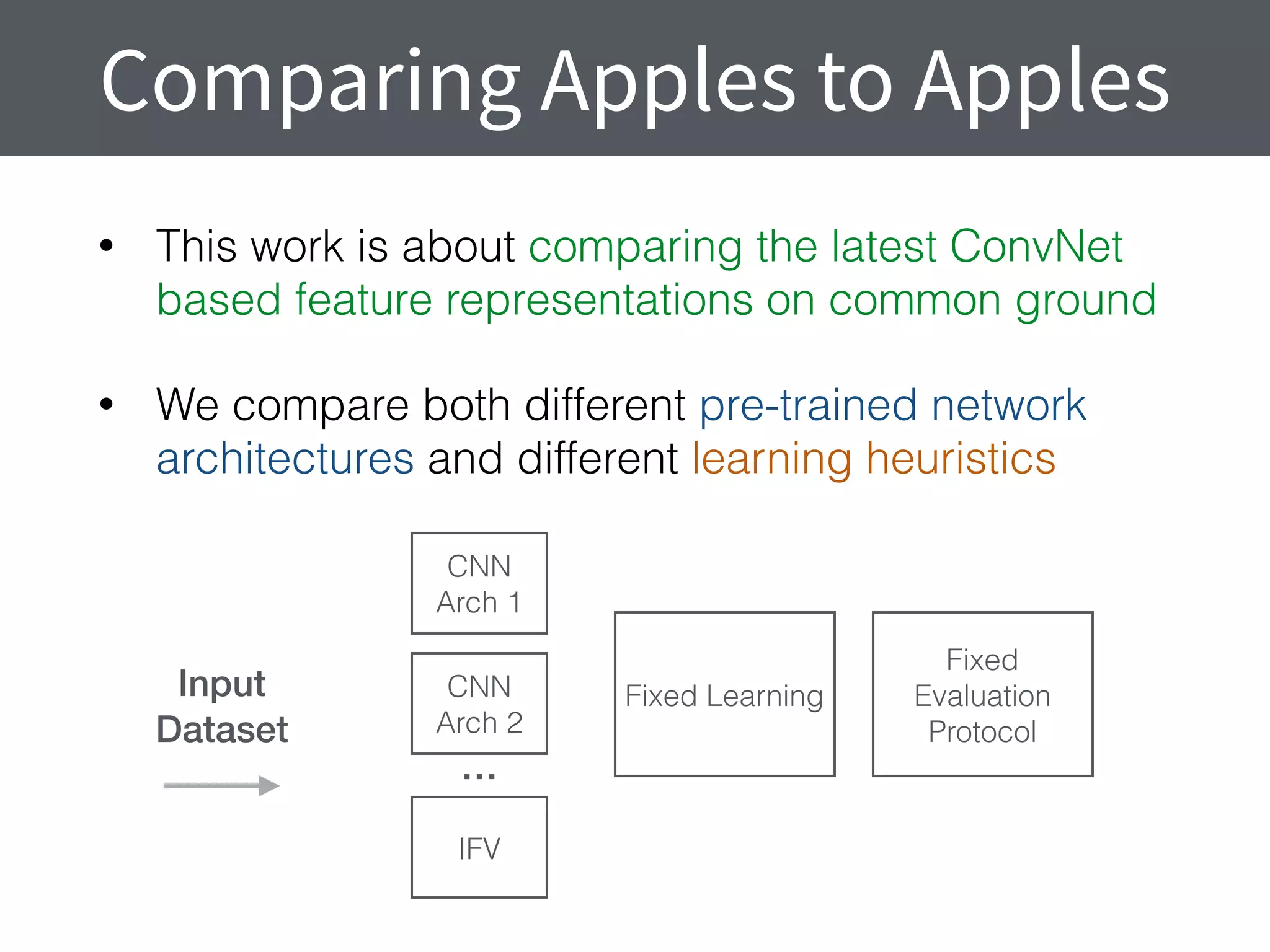
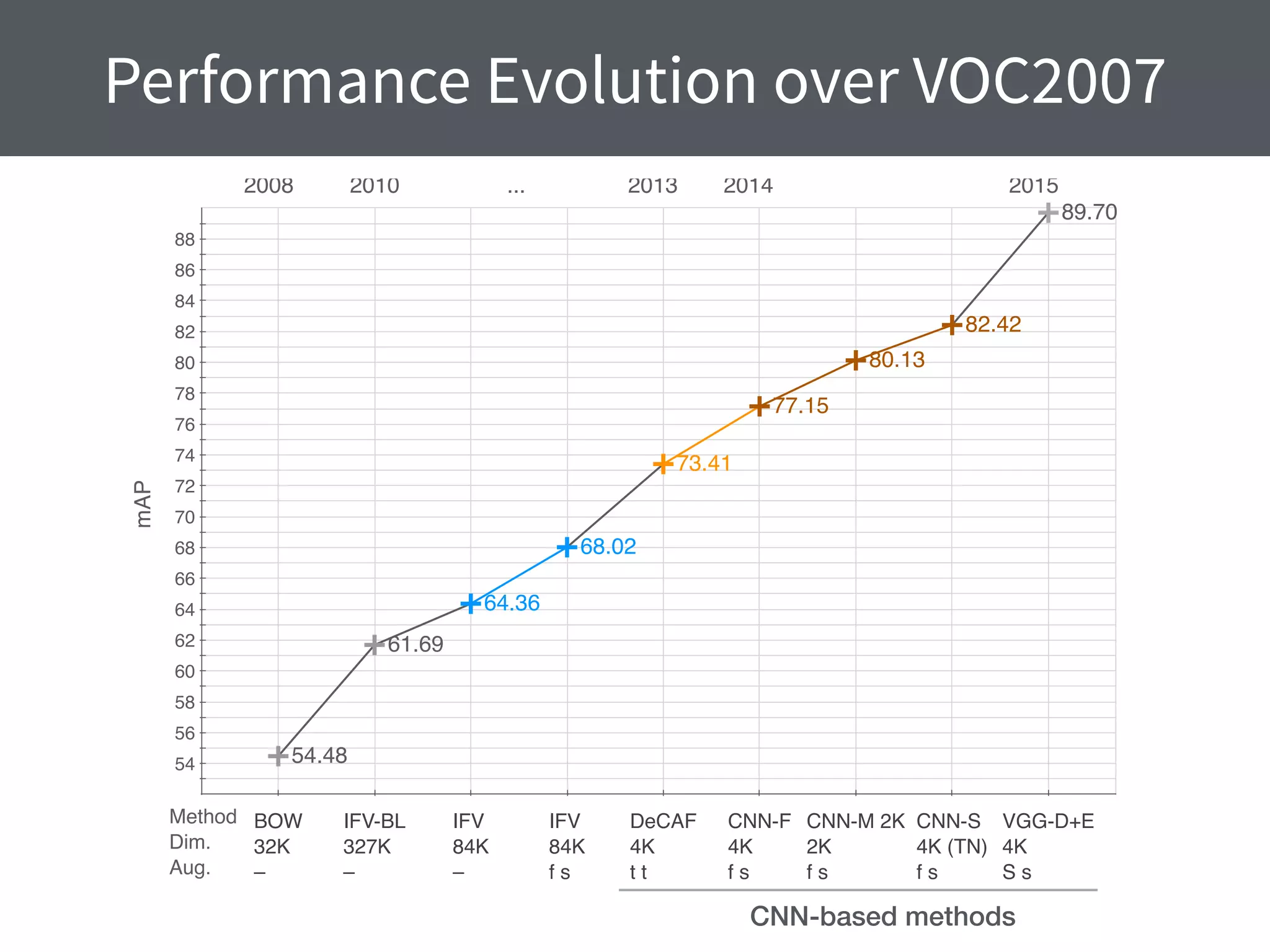
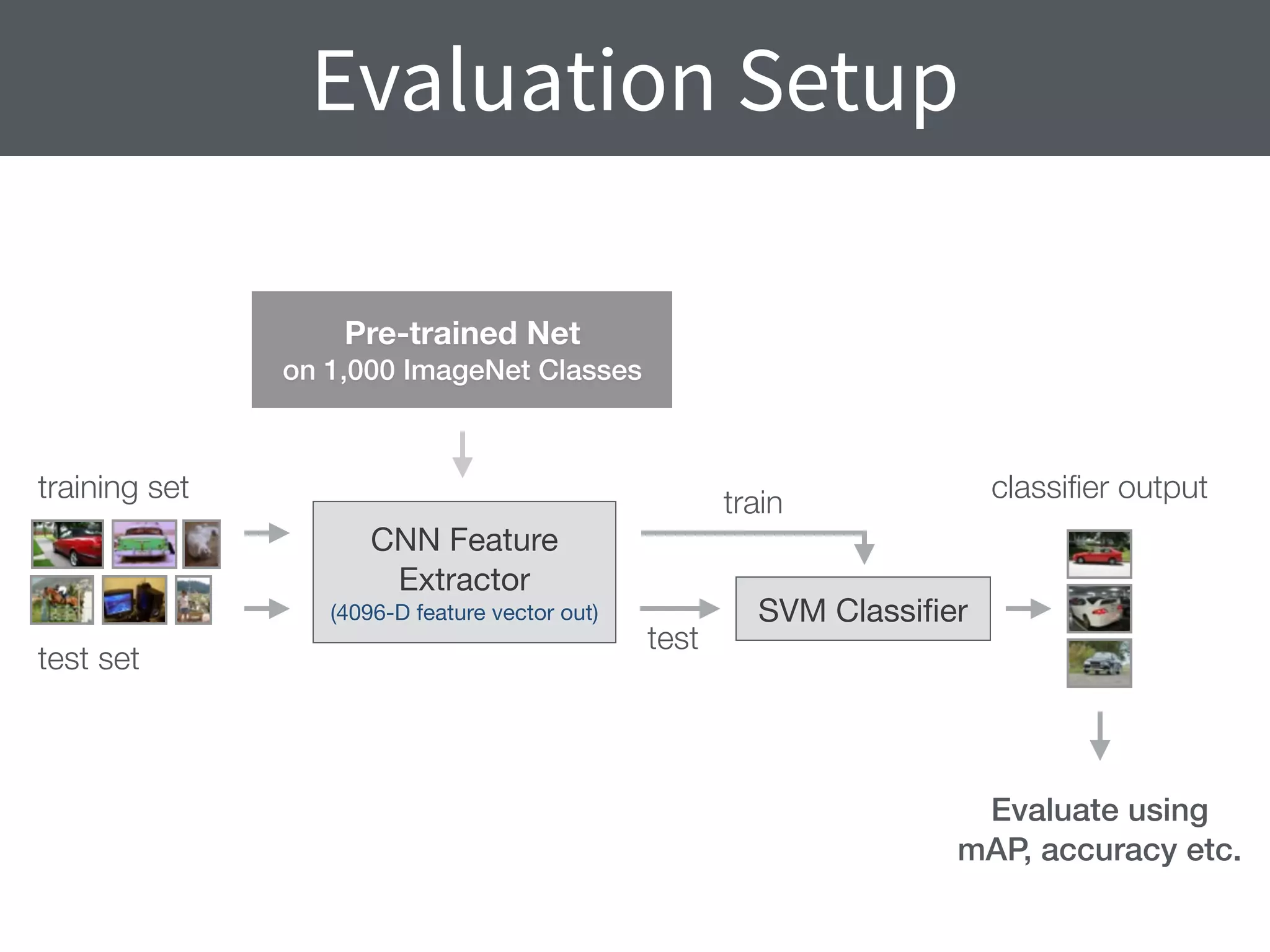
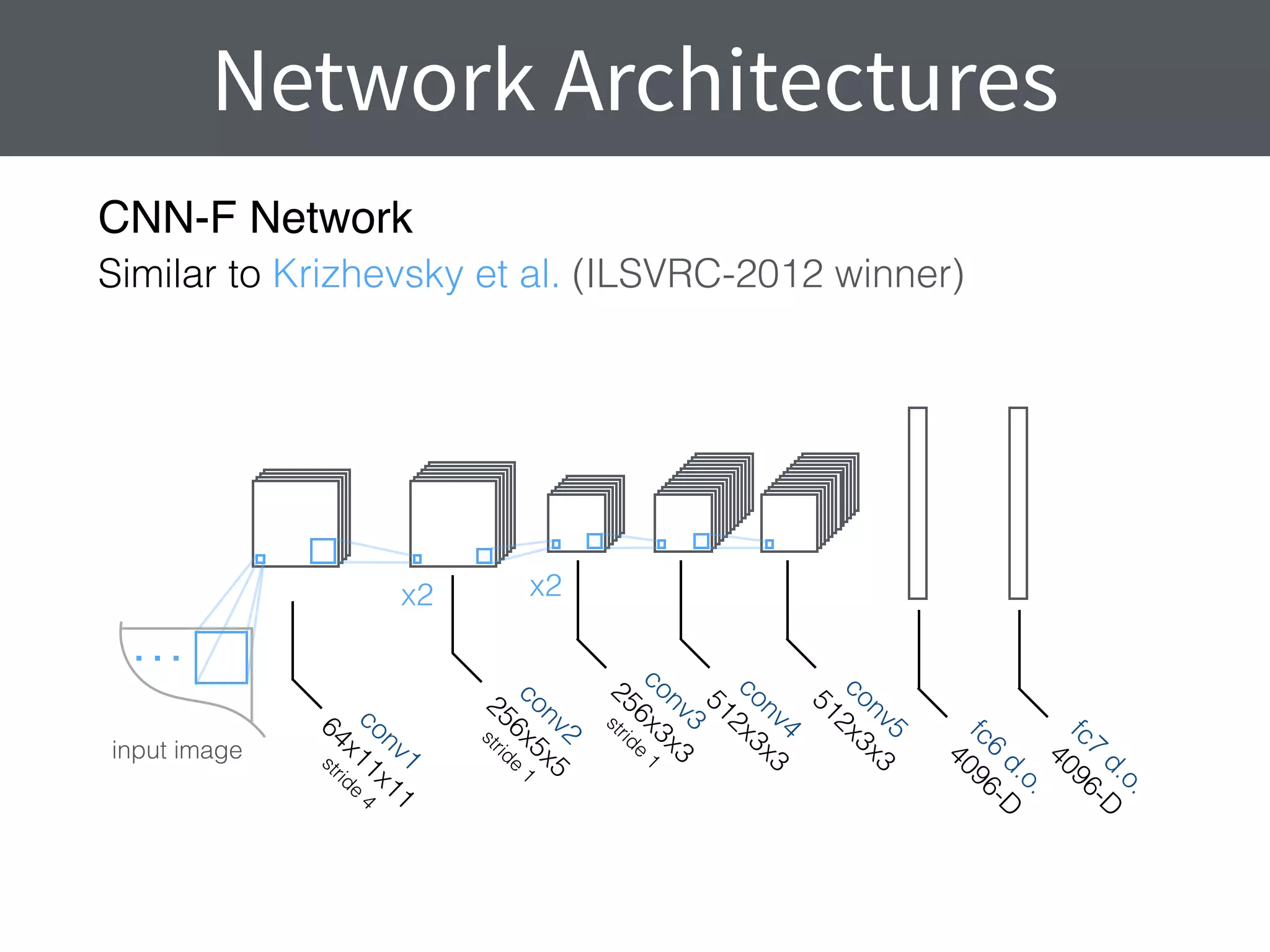
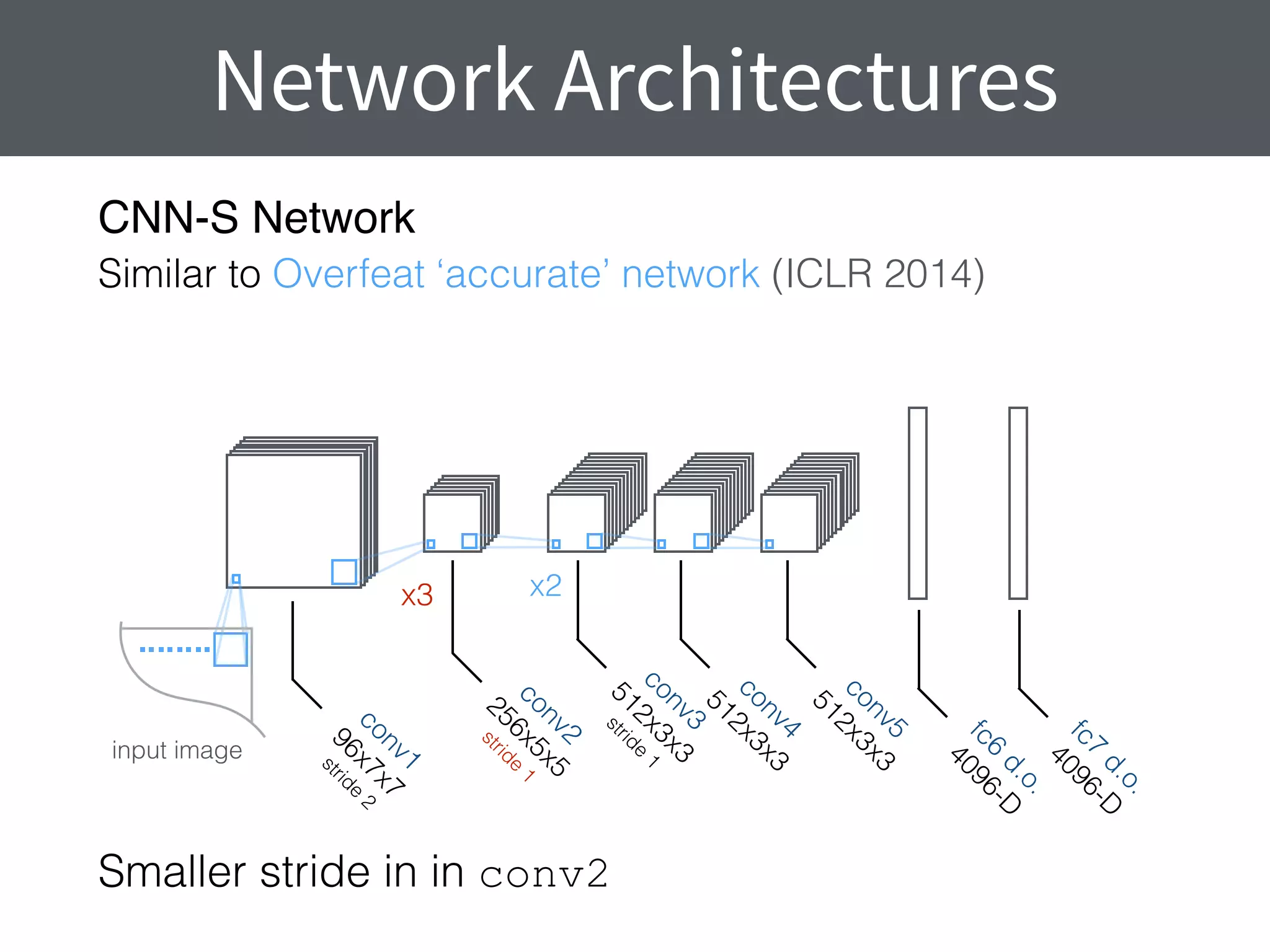
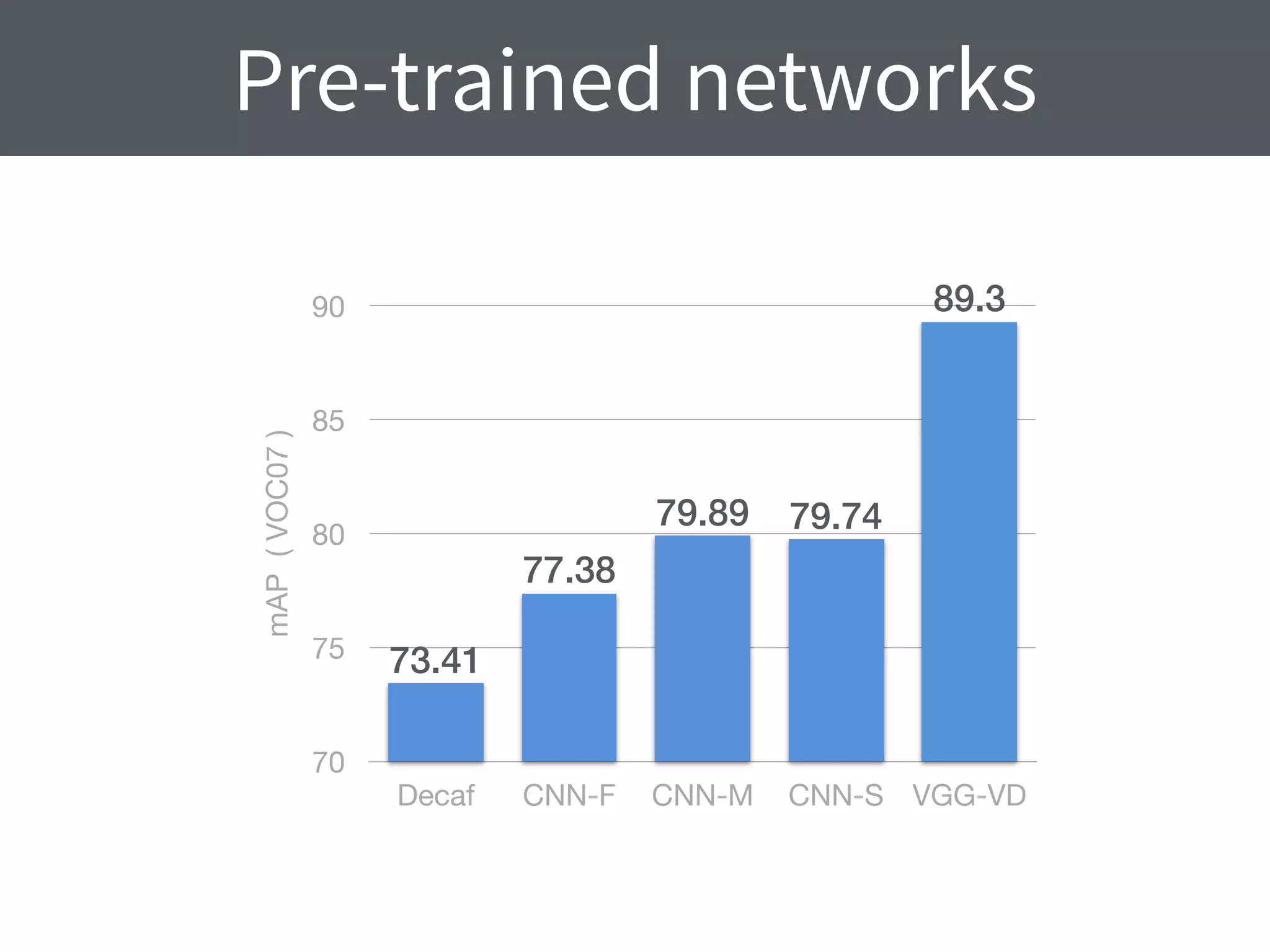
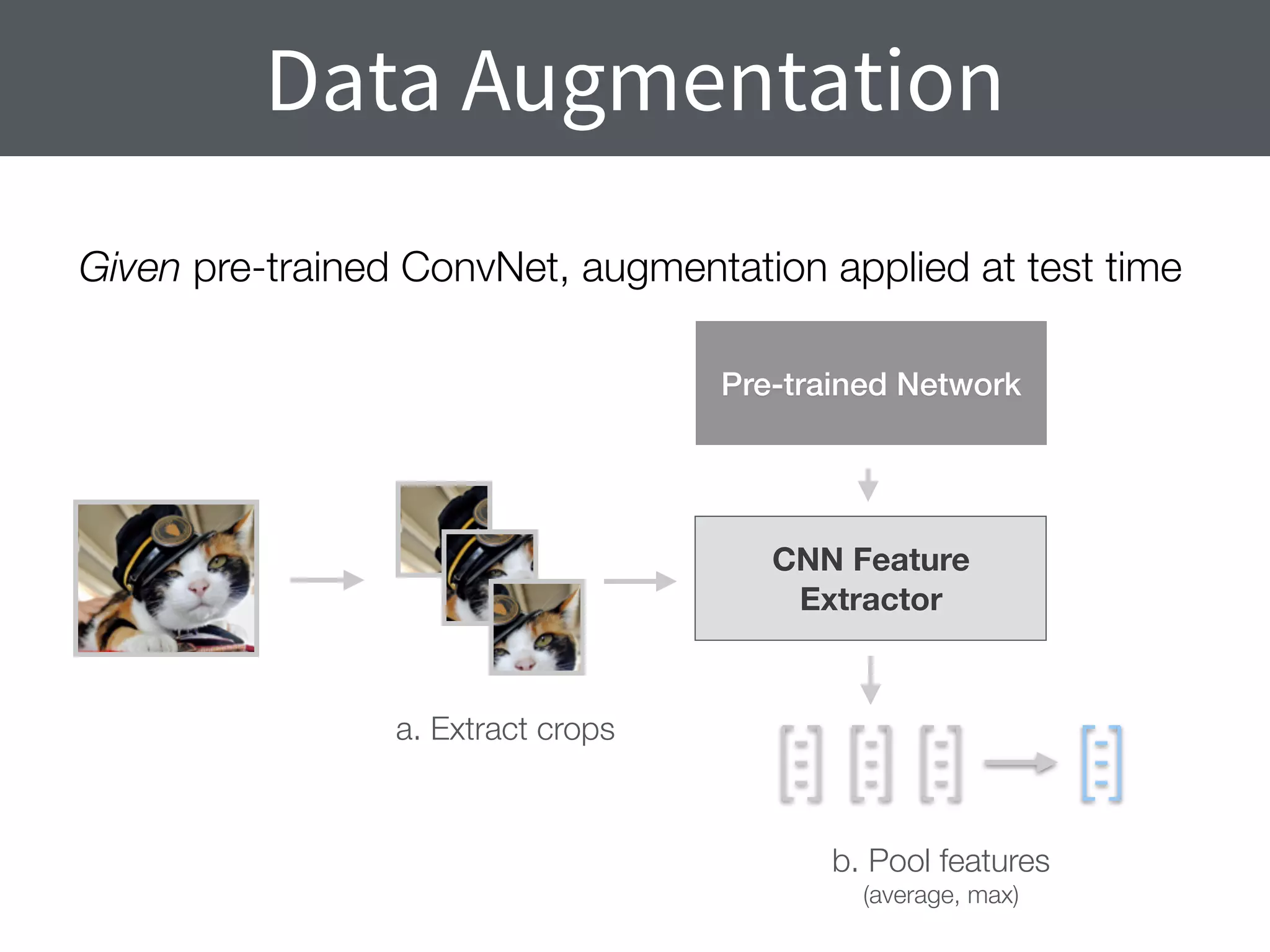
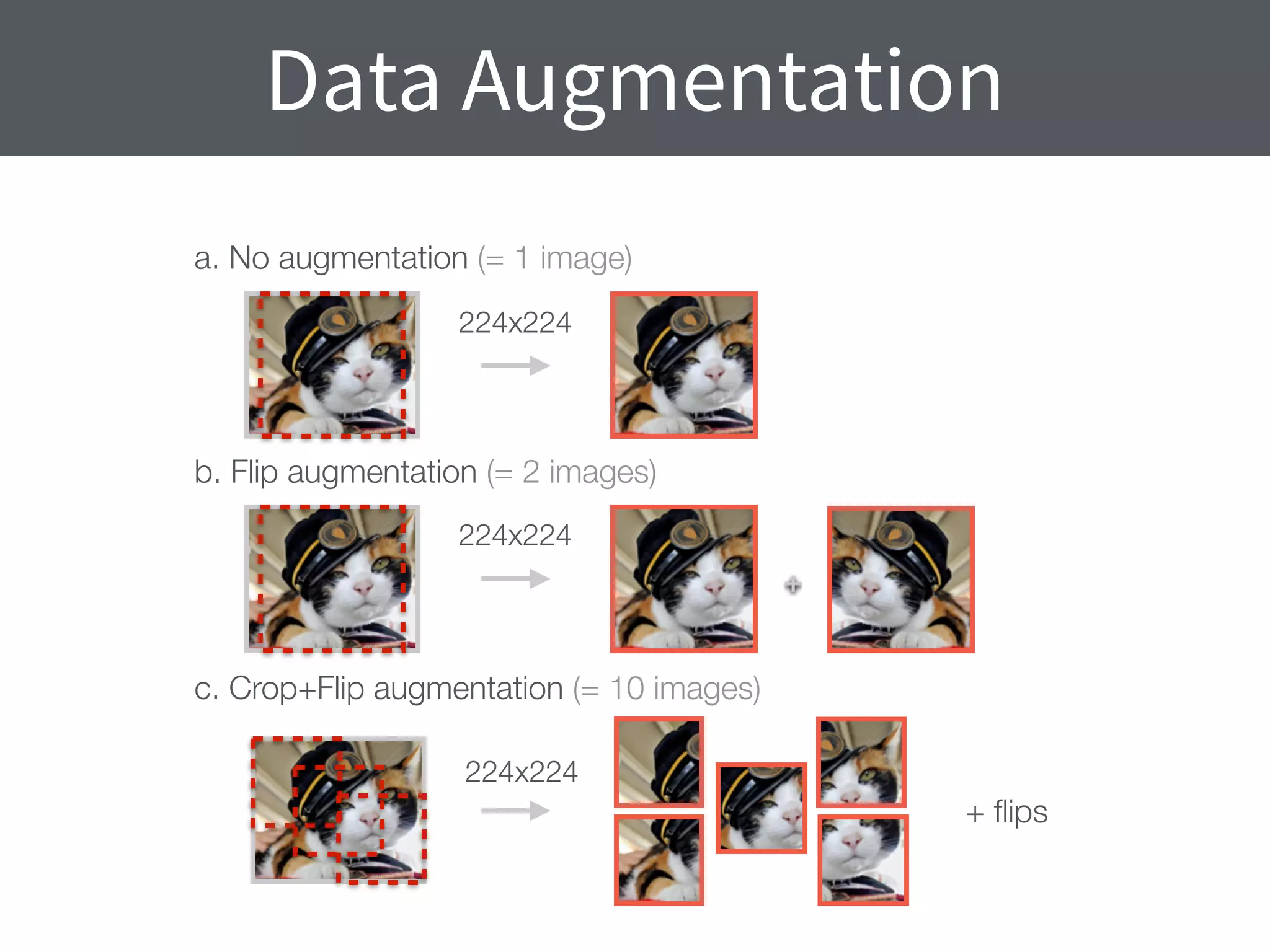
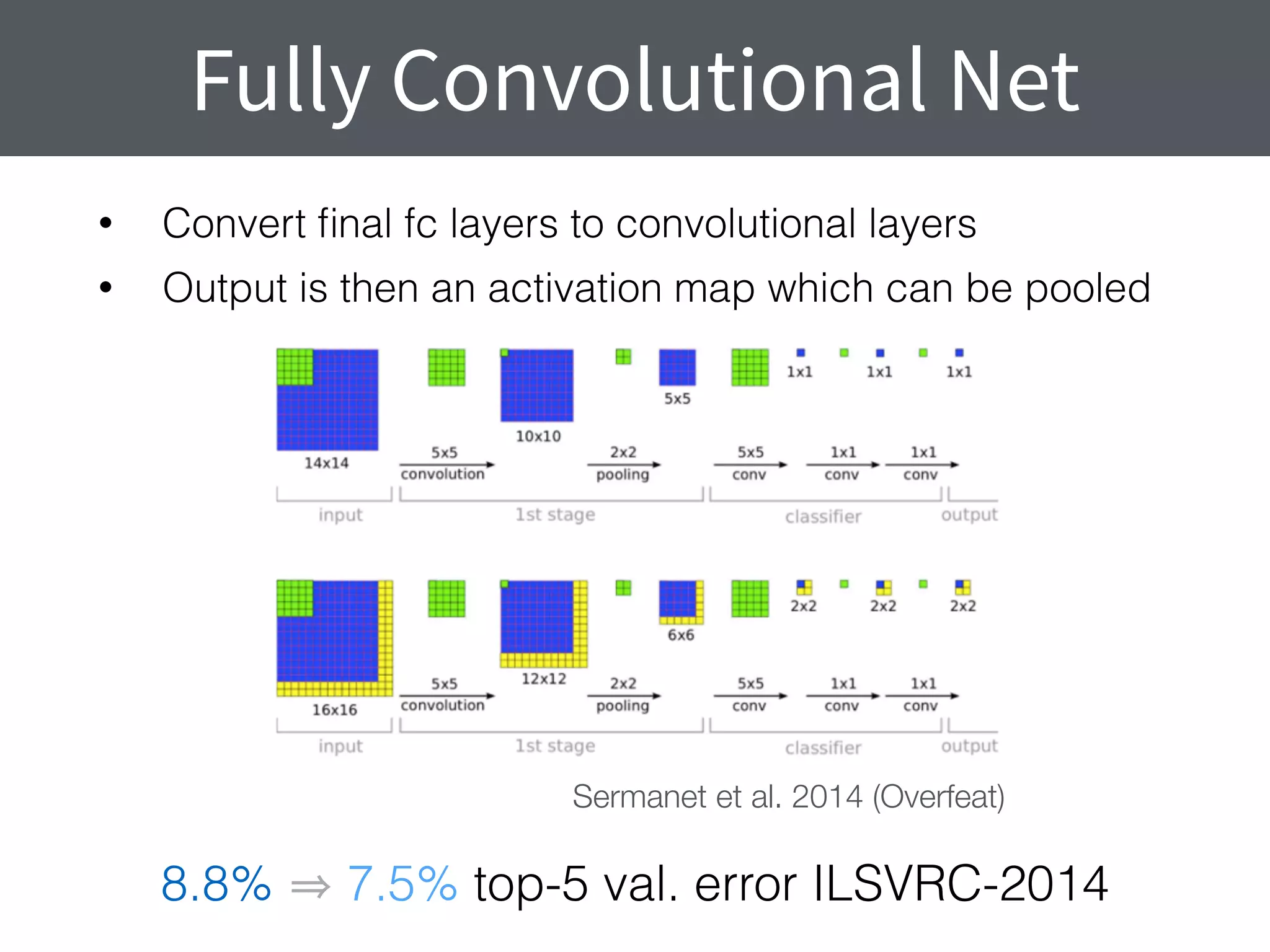
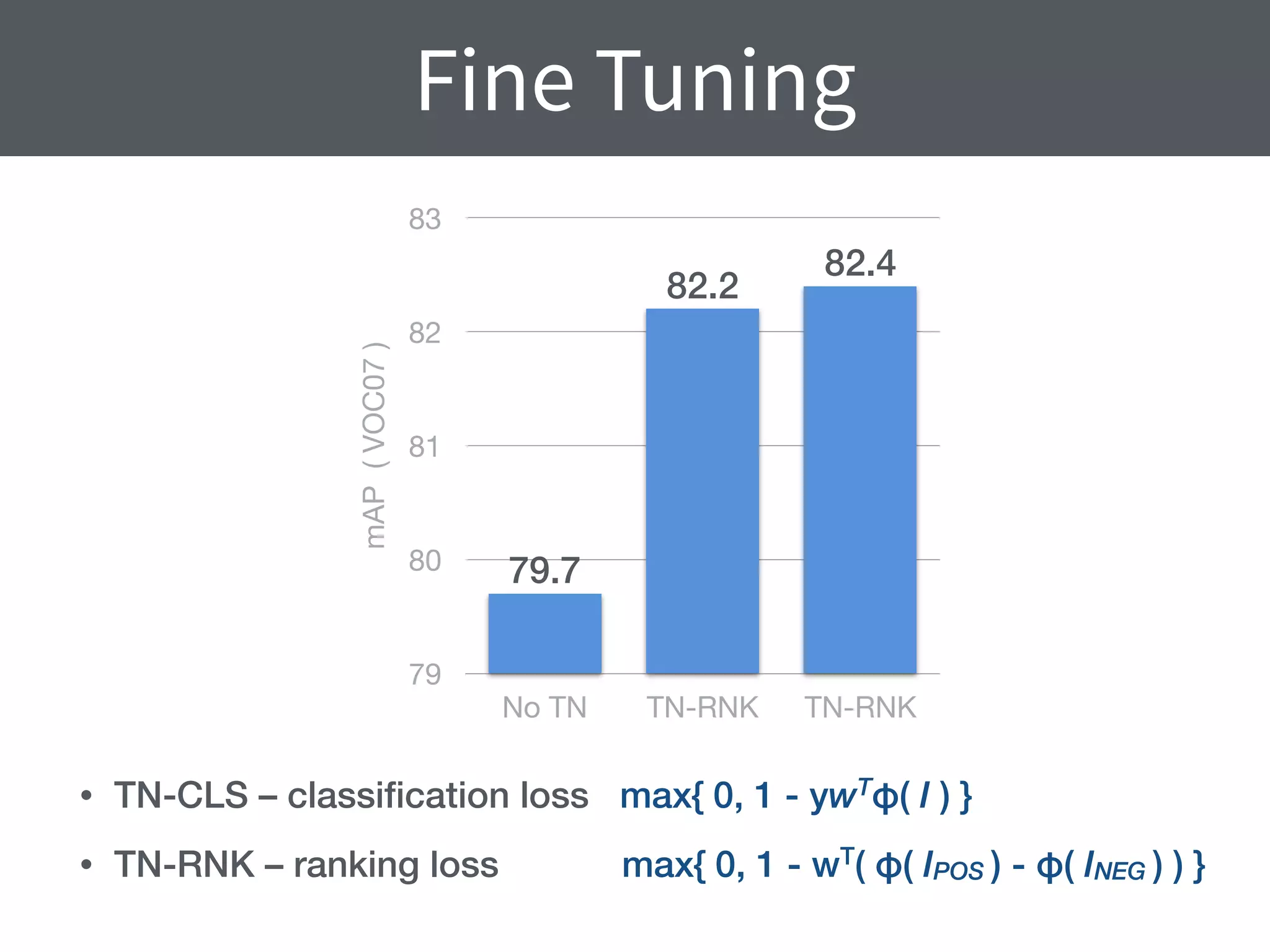
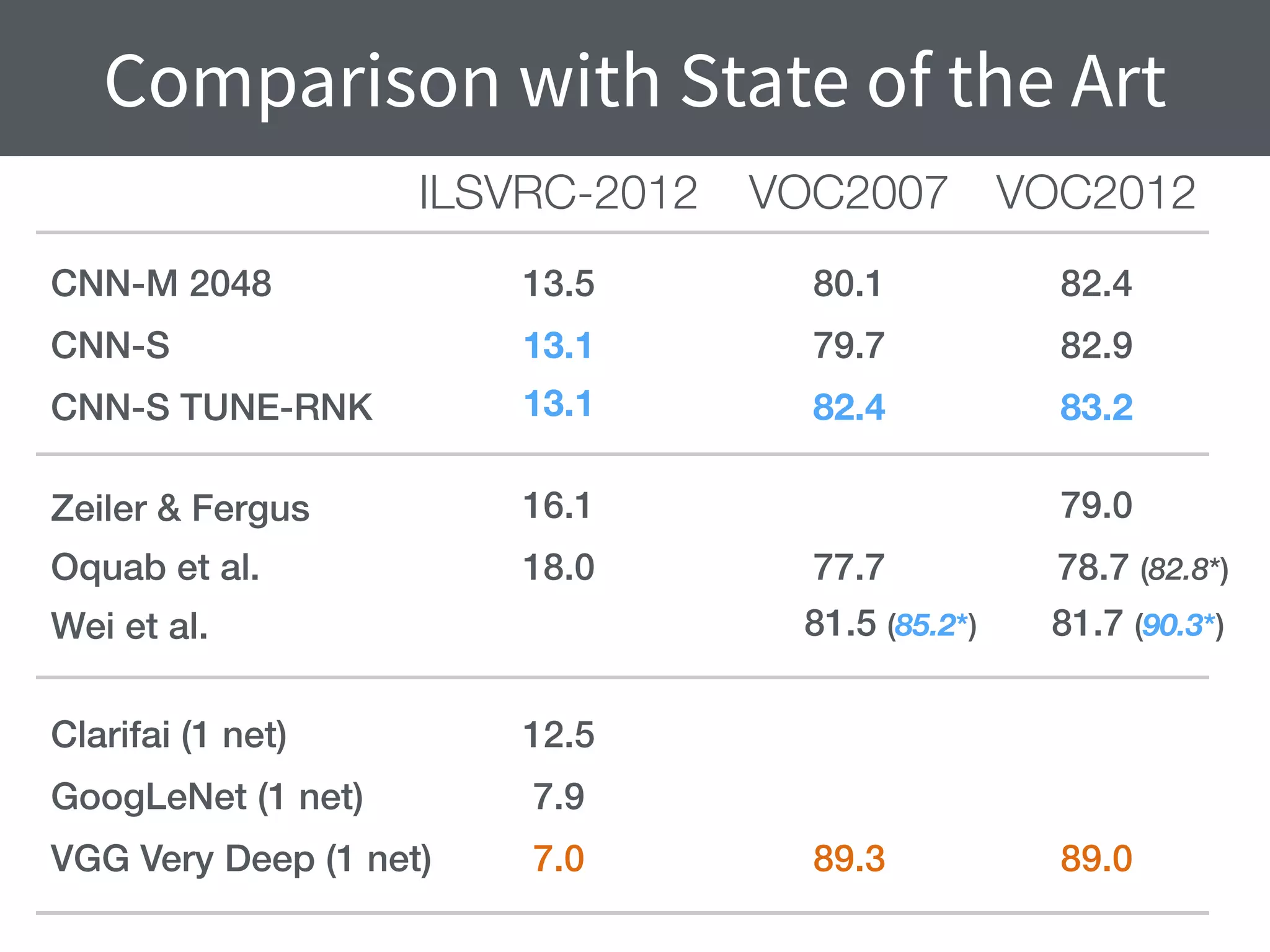
This document summarizes research comparing different convolutional neural network (CNN) architectures and feature representations on common image classification tasks. It finds that CNN-based methods outperform traditional bag-of-words models. Specifically, it compares different pre-trained CNNs, explores the effects of data augmentation, and shows that fine-tuning networks to target datasets improves performance. The best results are achieved with smaller filters, deeper networks, and ranking loss fine-tuning, outperforming more complex architectures. Code and models are available online for others to replicate the findings.







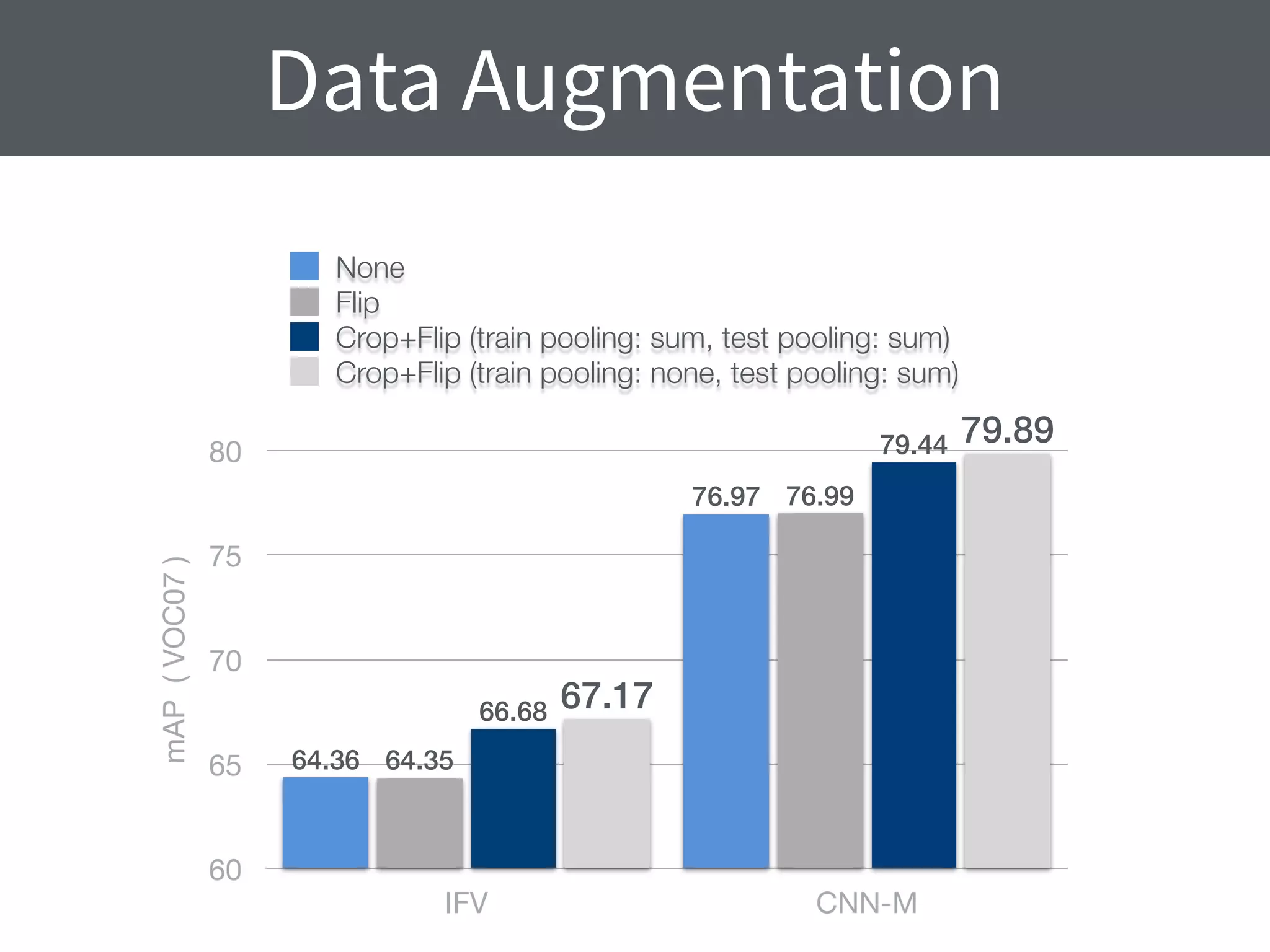
![Scale Augmentation
+ flips
224x224
[Smin, Smax] = [256, 512]
+ flips
224x224
256512
Q = {Smin, 0.5(Smin + Smax), Smax}](https://image.slidesharecdn.com/chatfield14-devil-150604135047-lva1-app6892/75/Devil-in-the-Details-Analysing-the-Performance-of-ConvNet-Features-17-2048.jpg)

















![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)


![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)



















































