





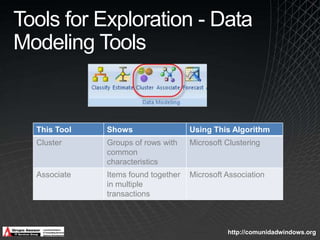
























The document discusses data mining capabilities in SQL Server 2008, highlighting tools for data preparation, exploration, and prediction model validation. It includes details on the time series algorithm enhancements and promotes the use of Excel add-ins for data mining tasks. The information presented is for informational purposes only and may not reflect the latest market conditions or guarantee accuracy post-publication.











































































































