Downloaded 11 times





![08-May-20 7:12 AM
7
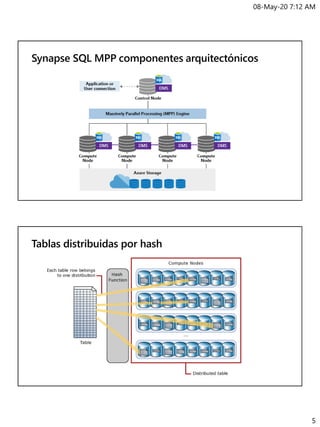
Gestión de la
carga de
trabajo
Scale-In Isolation
Coste predecible
Elasticidaden línea
Eficiente paracargasde trabajo impredecibles
Intra Cluster Workload Isolation
(Scale In)
Marketing
CREATE WORKLOAD GROUP Sales
WITH
(
[ MIN_PERCENTAGE_RESOURCE = 60 ]
[ CAP_PERCENTAGE_RESOURCE = 100 ]
[ MAX_CONCURRENCY = 6 ] )
40%
Compute
1000c DWU
60%
Sales
60%
100%
Seguridad integral
Category Feature
Data Protection
Data in Transit
Data Encryption at Rest
Data Discovery and Classification
Access Control
Object Level Security (Tables/Views)
Row Level Security
Column Level Security
Dynamic Data Masking
SQL Login
Authentication Azure Active Directory
Multi-Factor Authentication
Virtual Networks
Network Security Firewall
Azure ExpressRoute
Thread Detection
Threat Protection Auditing
Vulnerability Assessment](https://image.slidesharecdn.com/datawarehouseconazuresynapseanalytics-200508131618/85/Data-warehouse-con-azure-synapse-analytics-7-320.jpg)



![08-May-20 7:12 AM
11
Migración de tablas de base de datos
CREATE TABLE StoreSales (
[sales_city] varchar(60),
[sales_year] int,
[sales_state] char(2),
[item_sk] int,
[sales_zip] char(10),
[sales_date] date,
[customer_sk] int)
WITH(
CLUSTERED COLUMNSTORE INDEX ORDER ([customer_sk]),
DISTRIBUTION = HASH([sales_zip],[item_sk]),
PARTITION ([sales_year] RANGE RIGHT FOR VALUES (1998,1999,2000,2001,2002,2003)))
Vista de base de
datos
Migración Materialized Views
Views](https://image.slidesharecdn.com/datawarehouseconazuresynapseanalytics-200508131618/85/Data-warehouse-con-azure-synapse-analytics-11-320.jpg)
![08-May-20 7:12 AM
12
Migración de vista de base de
datos
Vista Vista materializada
Abstrae estructura a los usuarios YES YES
Requiere una referencia explícita YES No
Mejora el rendimiento No YES
Se requiere almacenamiento adicional No YES
Asegurable YES YES
Soporte completo de SQL
YES No
Migración de vista de base de datos
CREATE VIEW vw_TopSalesState
AS
SELECT
SubQ.StateAbbrev,
SubQ.FirstSoldDate,
(SubQ.SalesPrice / sum(SubQ.SalesPrice) OVER (order by (select null)))*100,
(1- (SalesPrice/ListPrice))*100 AS Discount,
RANK() OVER (order by (1- (SalesPrice/ListPrice))) AS StateDiscRank
FROM (
SELECT
s_state AS StateAbbrev,
MIN(d_date) AS FirstSoldDate,
SUM([ss_list_price]) AS ListPrice,
SUM([ss_sales_price]) AS SalesPrice
FROM [tpcds10TB].[store_sales2] ss
INNER JOIN [tpcds10TB].store s on s.[s_store_sk] = ss.[ss_store_sk]
INNER JOIN [tpcds10TB].[date_dim] d on d.[d_date_sk] = ss.ss_sold_date_sk
GROUP BY
s_state) AS SubQ](https://image.slidesharecdn.com/datawarehouseconazuresynapseanalytics-200508131618/85/Data-warehouse-con-azure-synapse-analytics-12-320.jpg)
![08-May-20 7:12 AM
13
Migración de la vista materializada de la base de datos
CREATE MATERIALIZED VIEW [dbo].[mvw_StoreSalesSummary]
WITH (DISTRIBUTION = HASH(ss_store_sk))
AS
SELECT
s_state,
c_birth_country,
ss_store_sk AS ss_store_sk,
ss_sold_date_sk AS ss_sold_date_sk,
SUM([ss_list_price]) AS [ss_list_price],
SUM([ss_sales_price]) AS [ss_sales_price],
count_big(*) AS cb
FROM [tpcds10TB].[store_sales2] ss
INNER JOIN [tpcds10TB].customer c ON c.[c_customer_sk] = ss.[ss_customer_sk]
INNER JOIN [tpcds10TB].store s on s.[s_store_sk] = ss.[ss_store_sk]
GROUP BY
s_state,c_birth_country,ss_store_sk, ss_sold_date_sk
Customer
65
Million
Rows
Store
1500
Rows
Store Sales
26
Billion
Rows
Materialized View
287
Million
Rows
Data Integration Data Warehouse Informes](https://image.slidesharecdn.com/datawarehouseconazuresynapseanalytics-200508131618/85/Data-warehouse-con-azure-synapse-analytics-13-320.jpg)


![08-May-20 7:12 AM
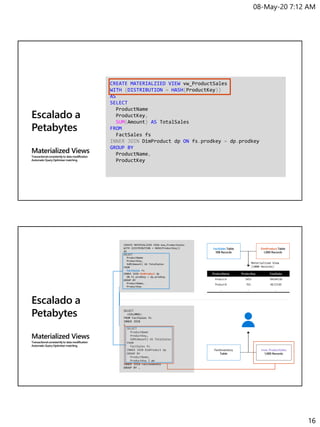
17
Escalado a
Petabytes
Materialized Views
Transactionalconsistentlyto datamodification
AutomaticQueryOptimizermatching
SELECT
c_customerkey,
c_nationkey,
SUM(l_quantity),
SUM(l_extendedprice)
FROM [dbo].[lineitem_MonthPartition] l
INNER JOIN [dbo].[orders] o on o.o_orderkey = l.l_orderkey
INNER JOIN [dbo].[customer] c on c.c_customerkey = o.o_customerkey
GROUP BY
c_customerkey,
c_nationkey
[dbo].[lineitem_MonthPartition] HASH(l_orderkey)
[dbo].[orders] HASH(o_orderkey)
[dbo].[customer] HASH(c_customerkey)
Table Distributions
Escalado a
Petabytes
Materialized Views
Transactionalconsistentlyto datamodification
AutomaticQueryOptimizermatching
LineItem Orders
Collocated Join (DistributionAligned)
Customer
Non-collocatedJoin (Shuffle Required)
FROM [dbo].[lineitem_MonthPartition] l
INNER JOIN [dbo].[orders] o on o.o_orderkey = l.l_orderkey
INNER JOIN [dbo].[customer] c on c.c_customerkey = o.o_customerkey](https://image.slidesharecdn.com/datawarehouseconazuresynapseanalytics-200508131618/85/Data-warehouse-con-azure-synapse-analytics-17-320.jpg)
![08-May-20 7:12 AM
18
Escalado a
Petabytes
Materialized Views
Transactionalconsistentlyto datamodification
AutomaticQueryOptimizermatching
(Shuffle Required)
LineItem Orders
Collocated Join (DistributionAligned)
Stage 1
Customer
Stage 2
#temp (Orders + Lineitem)
Nation
Collocated Join (Replicate Aligned)
Collocated Join (DistributionAligned)
Escalado a
Petabytes
Materialized Views
Transactionalconsistentlyto datamodification
AutomaticQueryOptimizermatching
CREATE MATERIALIZED VIEW mvw_CustomerSales
WITH (DISTRIBUTION = HASH(o_custkey))
AS
SELECT
o_custkey,
l_shipdate,
SUM(l_quantity) AS l_quantity,
SUM(l_extendedprice) AS l_extendedprice
FROM [dbo].[lineitem_MonthPartition] l
INNER JOIN [dbo].[orders] o on o.o_orderkey = l.l_orderkey
WHERE
l_shipdate >= CONVERT(DATETIME, '1998-11-01', 103)
GROUP BY
o_custkey,
l_shipdate](https://image.slidesharecdn.com/datawarehouseconazuresynapseanalytics-200508131618/85/Data-warehouse-con-azure-synapse-analytics-18-320.jpg)



Azure Synapse is the evolution of Azure SQL Data Warehouse, combining big data, data storage and data integration into a single service for end-to-end cloud scale analytics. It provides unlimited analytics with unparalleled speed to gain insights. Azure Synapse brings together enterprise data warehousing and big data analytics to give a unified experience with the advantages of both worlds.























































































