Downloaded 29 times


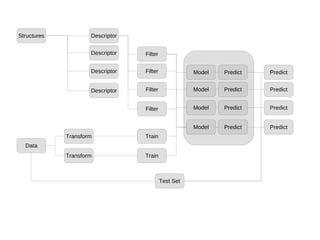
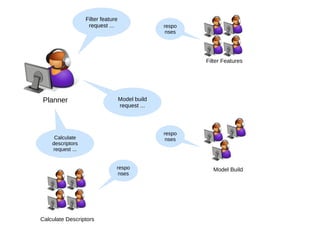
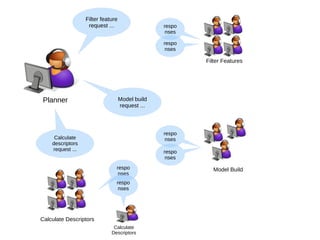
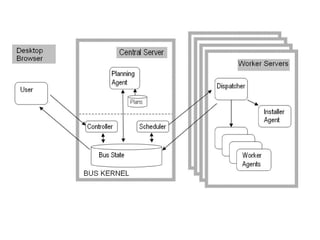

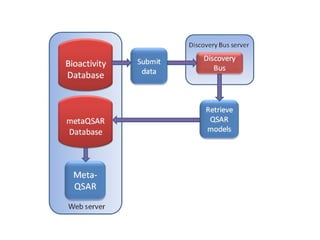



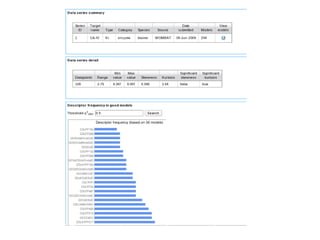
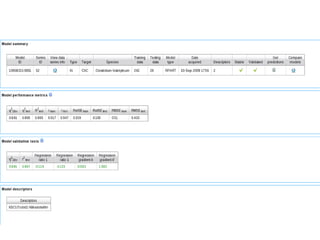
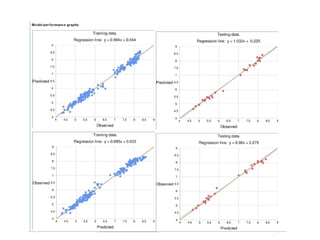
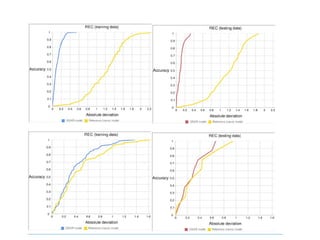



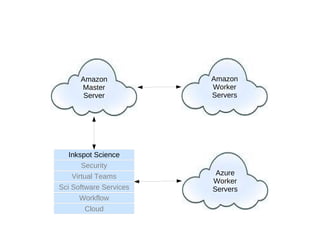
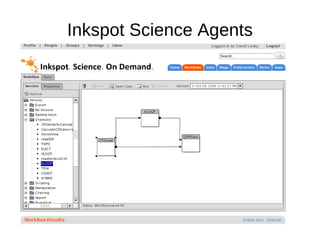
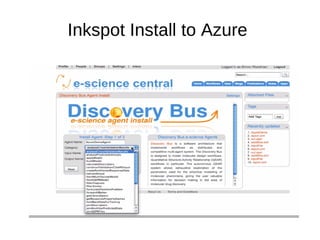


The document discusses advancements in QSAR modeling methods and automation, focusing on the meta QSAR framework and associated databases such as Wombat and EBI Stardrop. It details model building techniques, evaluation, and the integration of cloud computing resources for expanded data analysis. Additionally, it addresses the ongoing development of new methods and their applications in property prediction and classification models.
























































![CASE_PRESENTATION_ON_subdural_hematoma(SDH)[1 FINAL PPT]-1.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/casepresentationonsubduralhematomasdh1finalppt-1-260129172522-d405d375-thumbnail.jpg?width=640&height=640&fit=bounds)








