Downloaded 34 times
![MESUR Making Use and Sense of Scholarly Usage Data <http://www.mesur.org> Johan Bollen - [email_address] Herbert Van de Sompel - herbertv@lanl.gov Digital Library Research & Prototyping Team Research Library Los Alamos National Laboratory, USA Acknowledgements: Marko A. Rodriguez (LANL), Ryan Chute (LANL), Lyudmila L. Balakireva (LANL), Aric Hagberg (LANL), Luis Bettencourt (LANL) The MESUR research was funded by the Andrew W. Mellon Foundation](https://image.slidesharecdn.com/mesurinforum2009hvds-090519163647-phpapp02/75/MESUR-Making-sense-and-use-of-usage-data-1-2048.jpg)




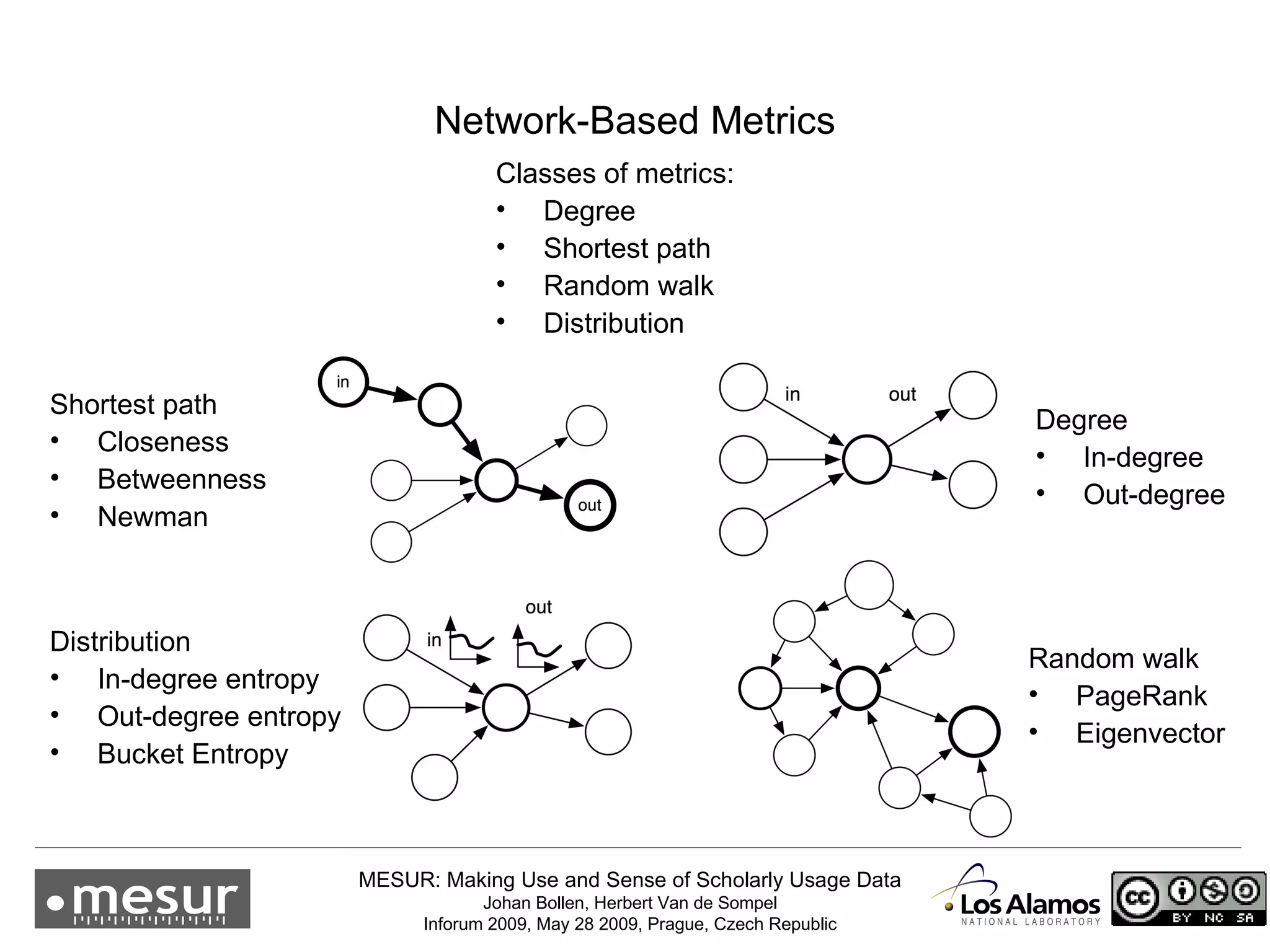
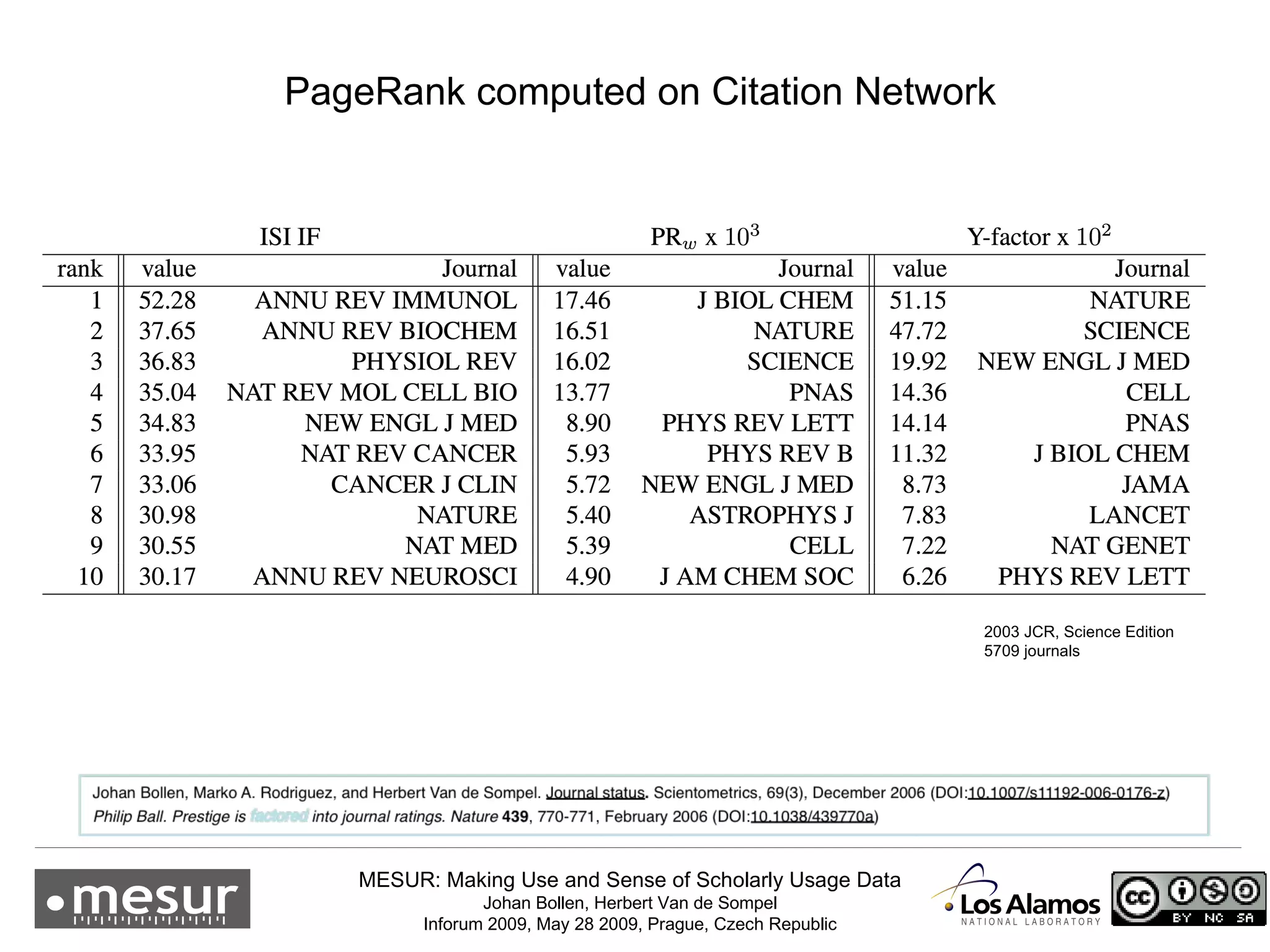

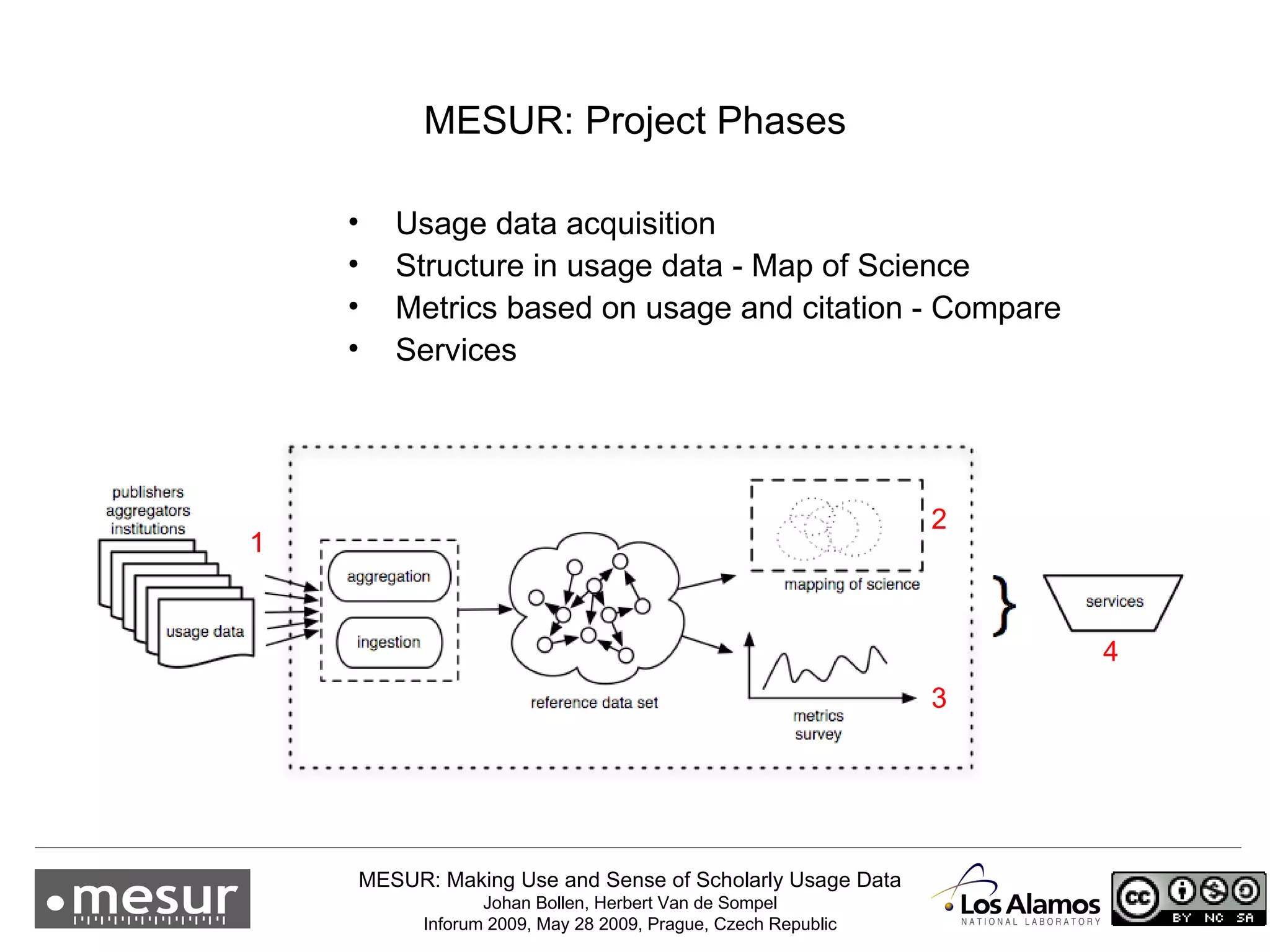
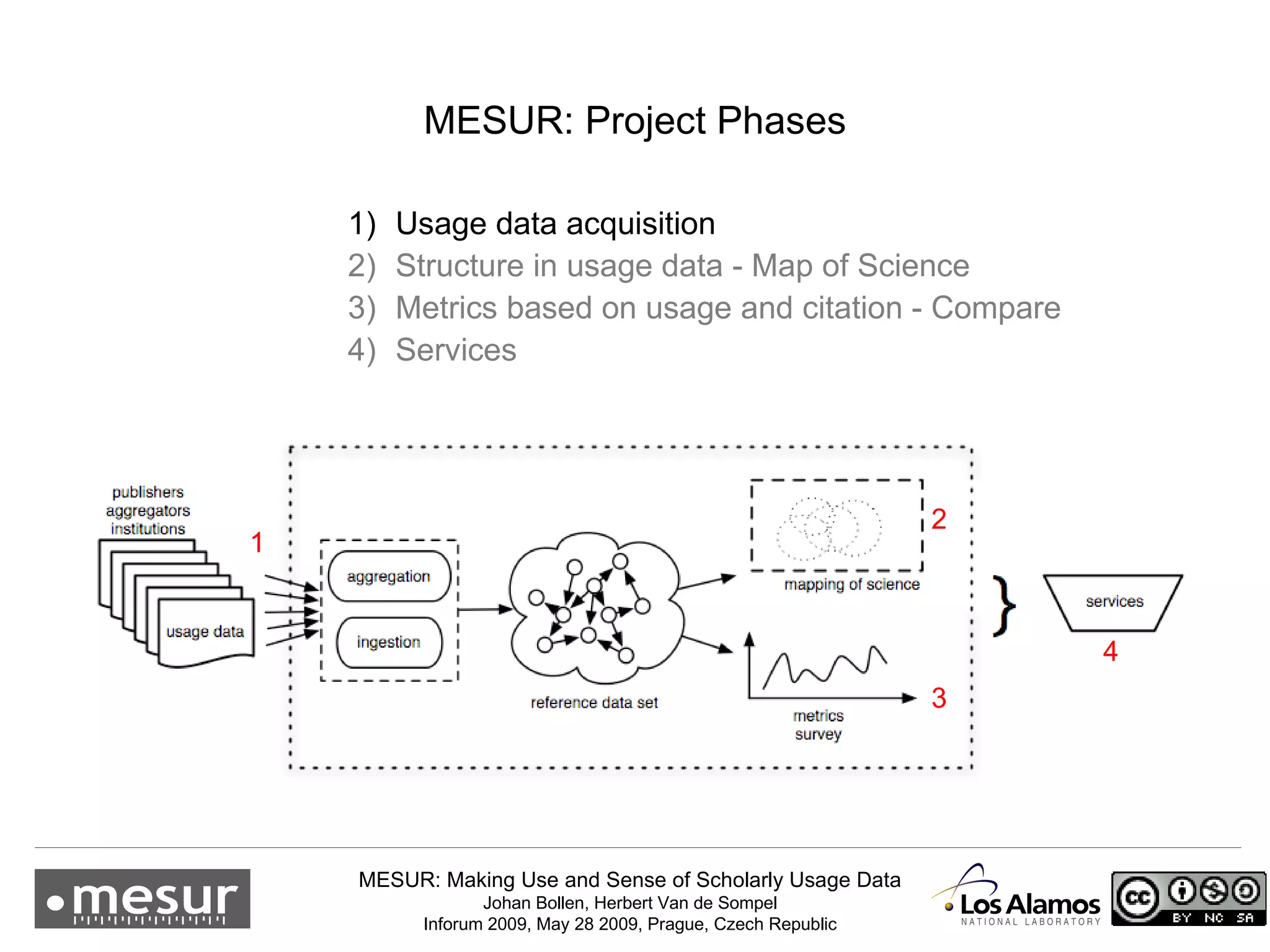


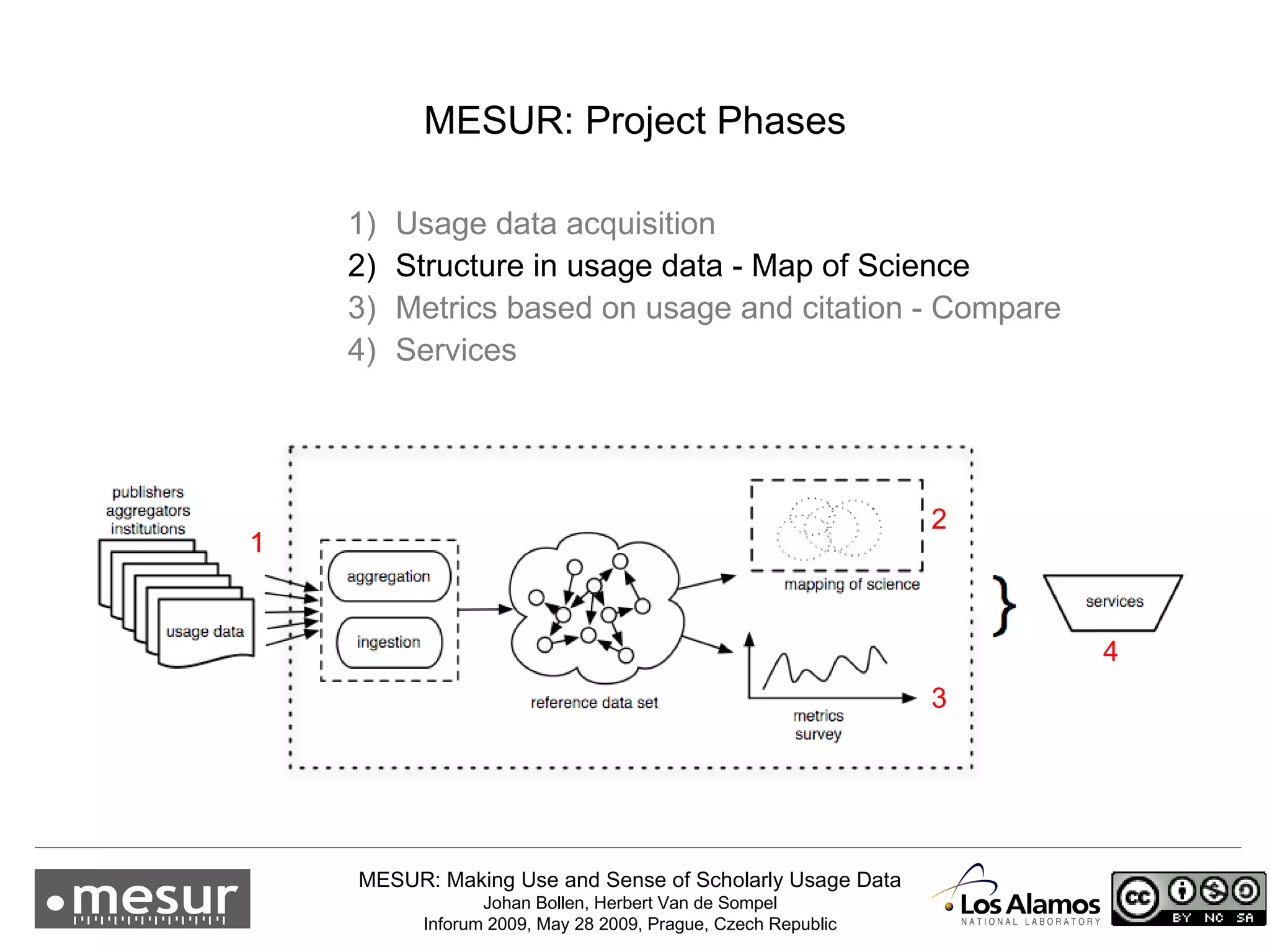
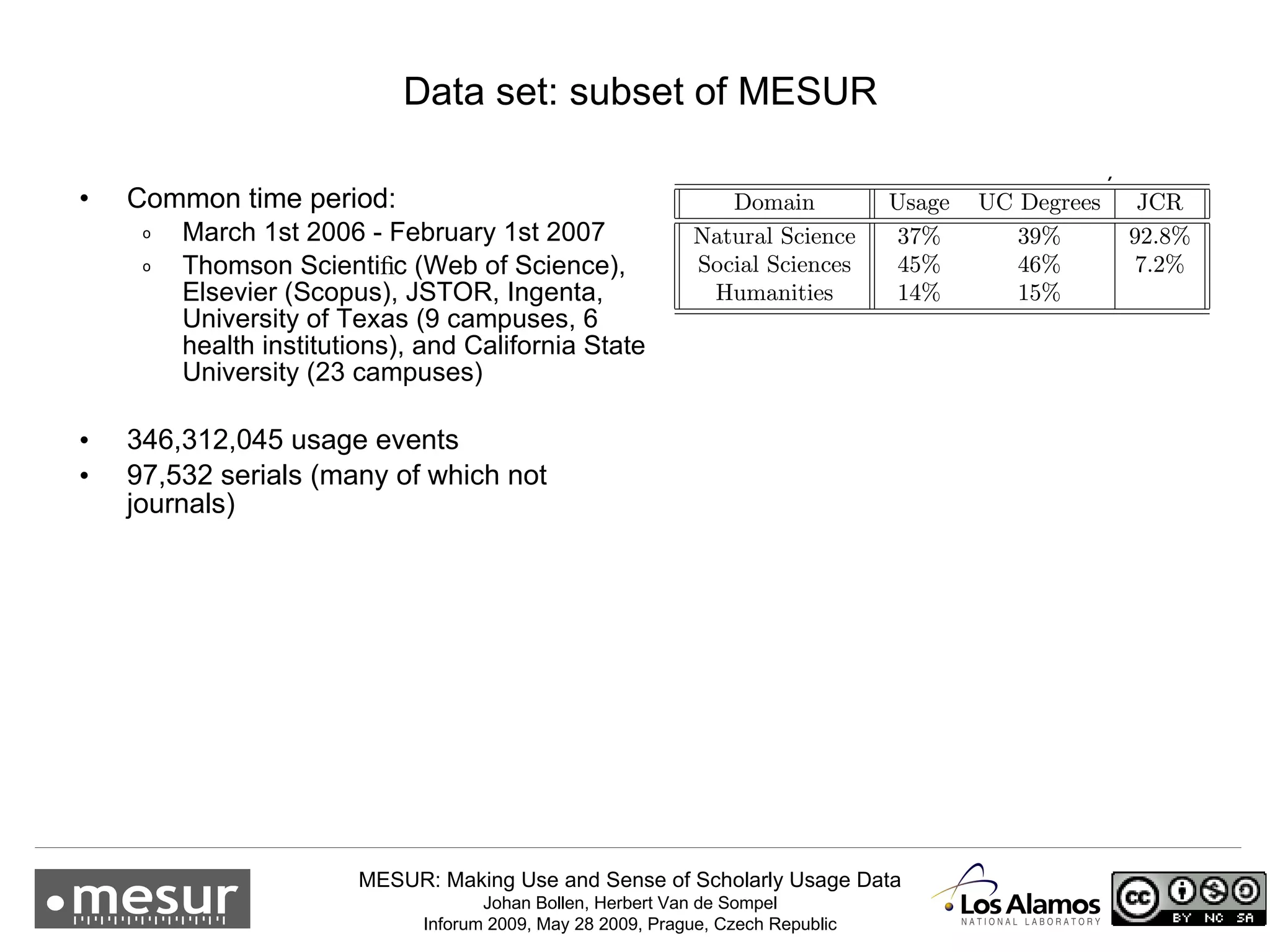
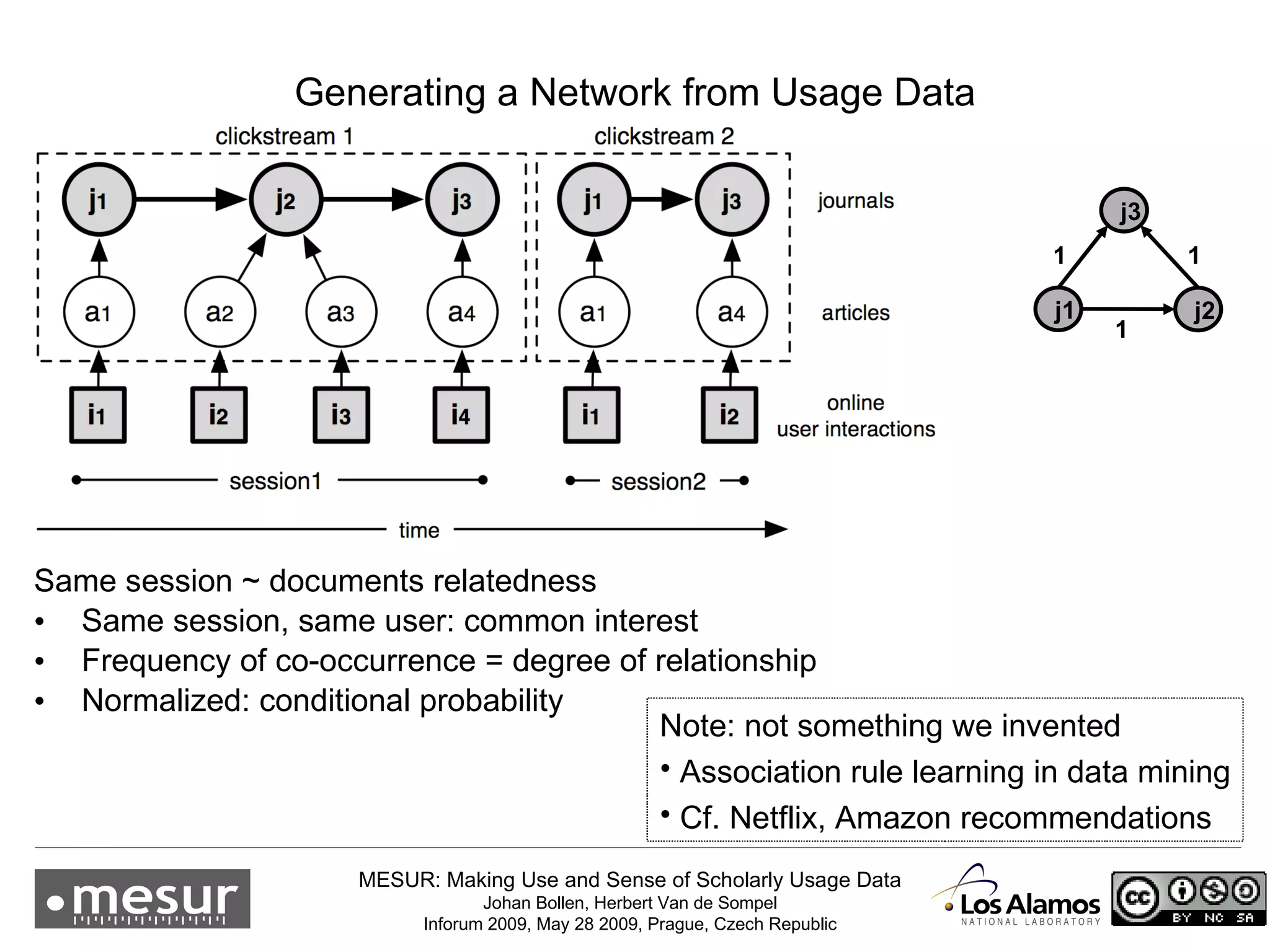
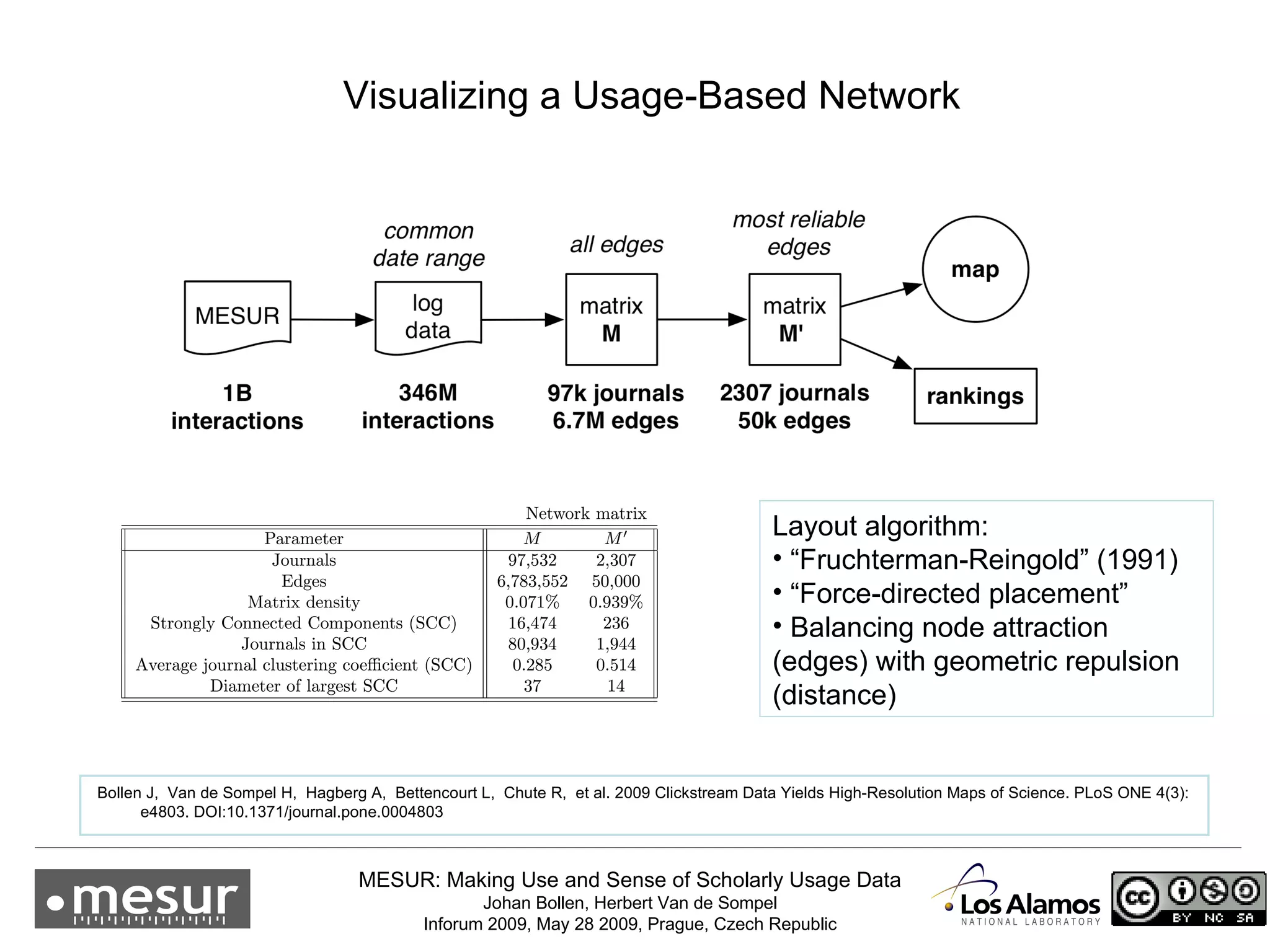


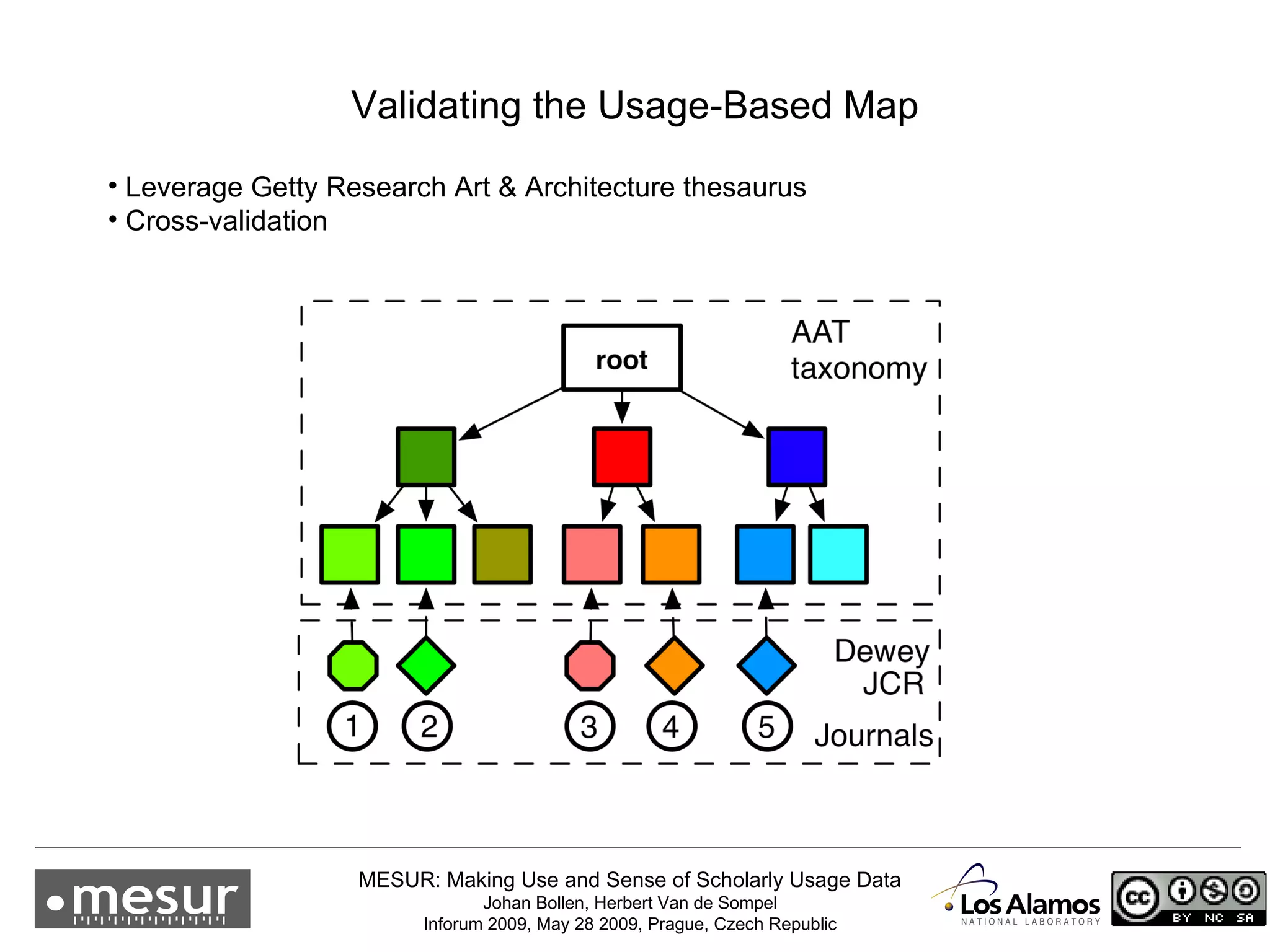

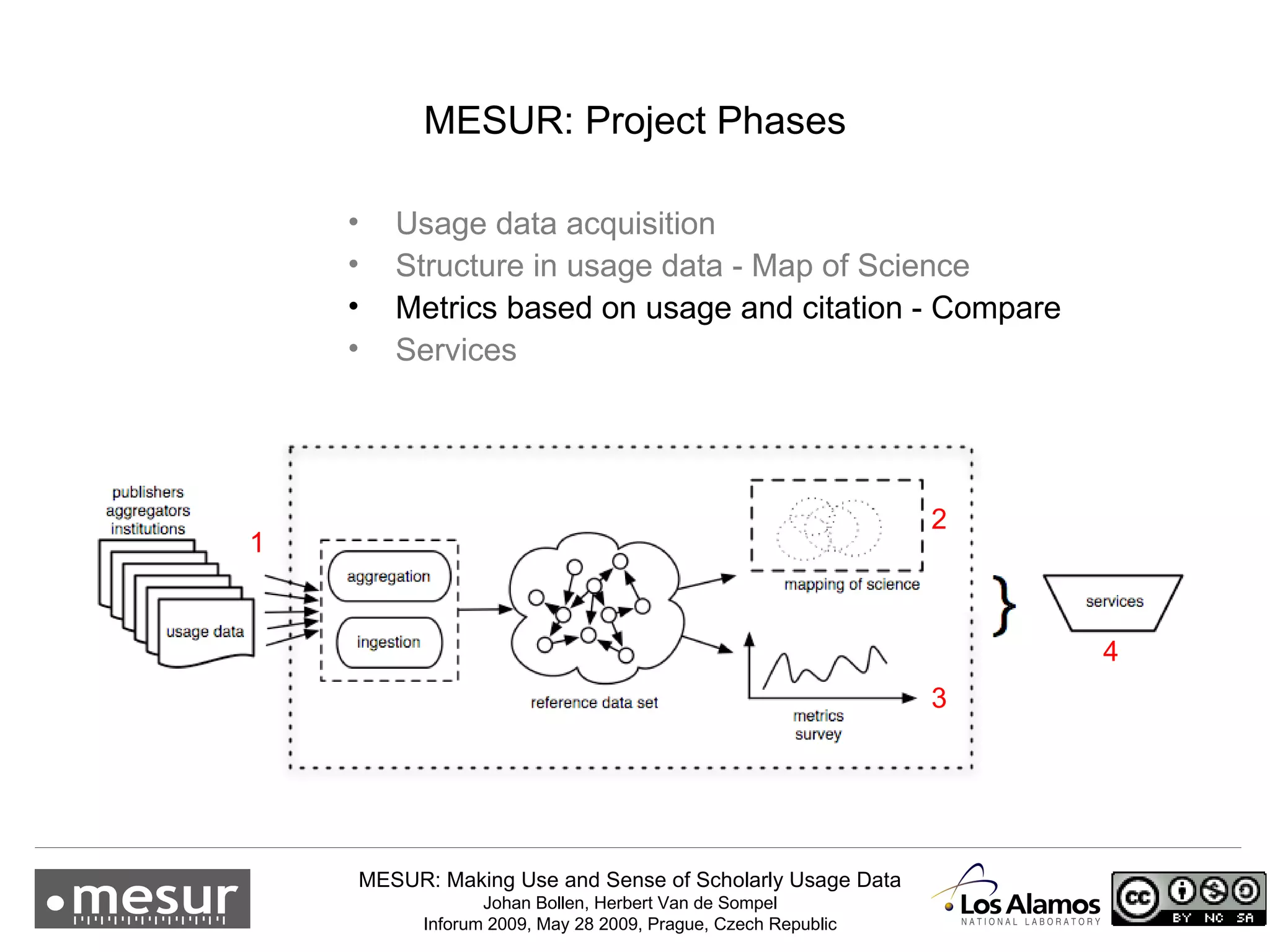

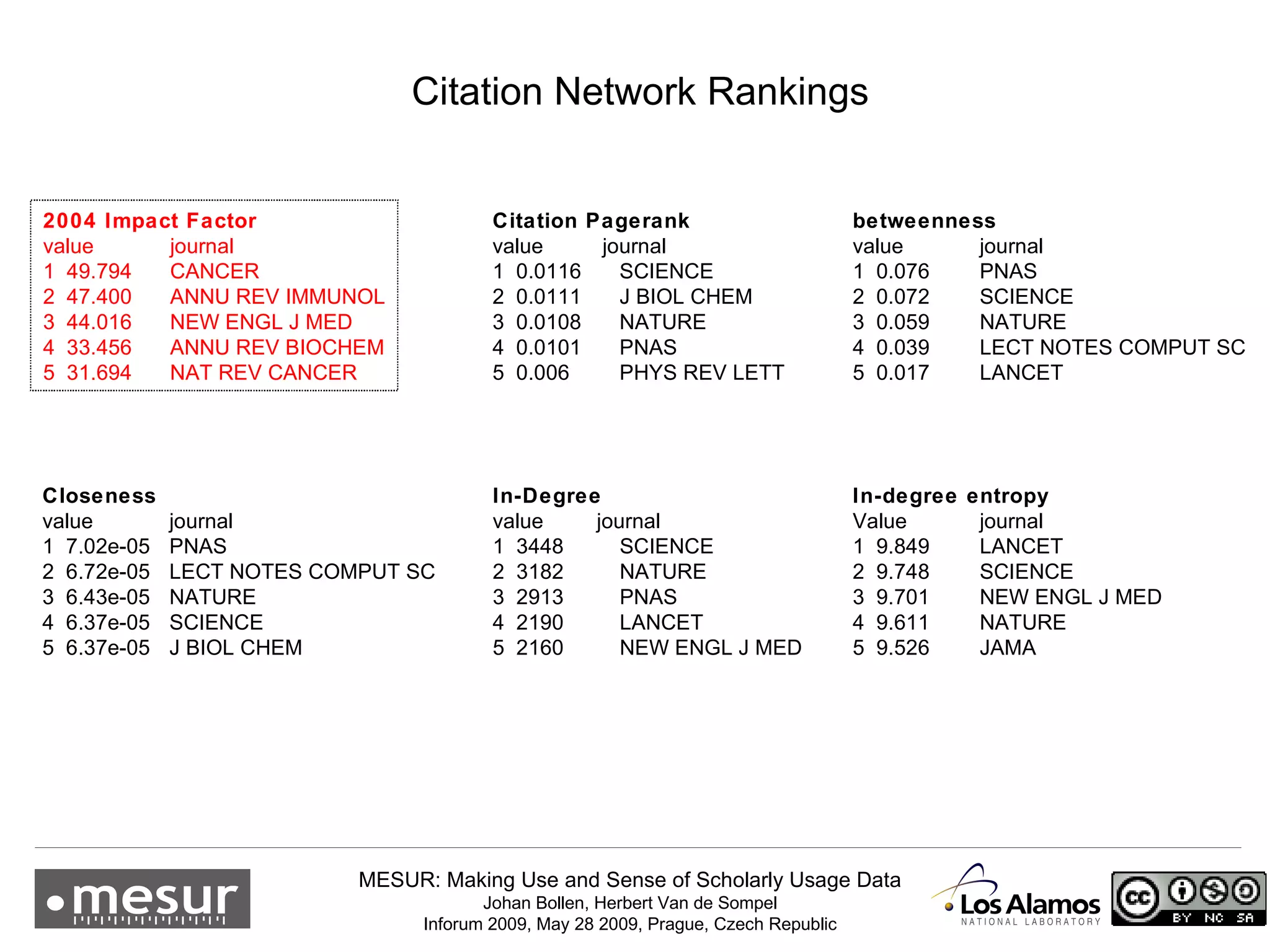

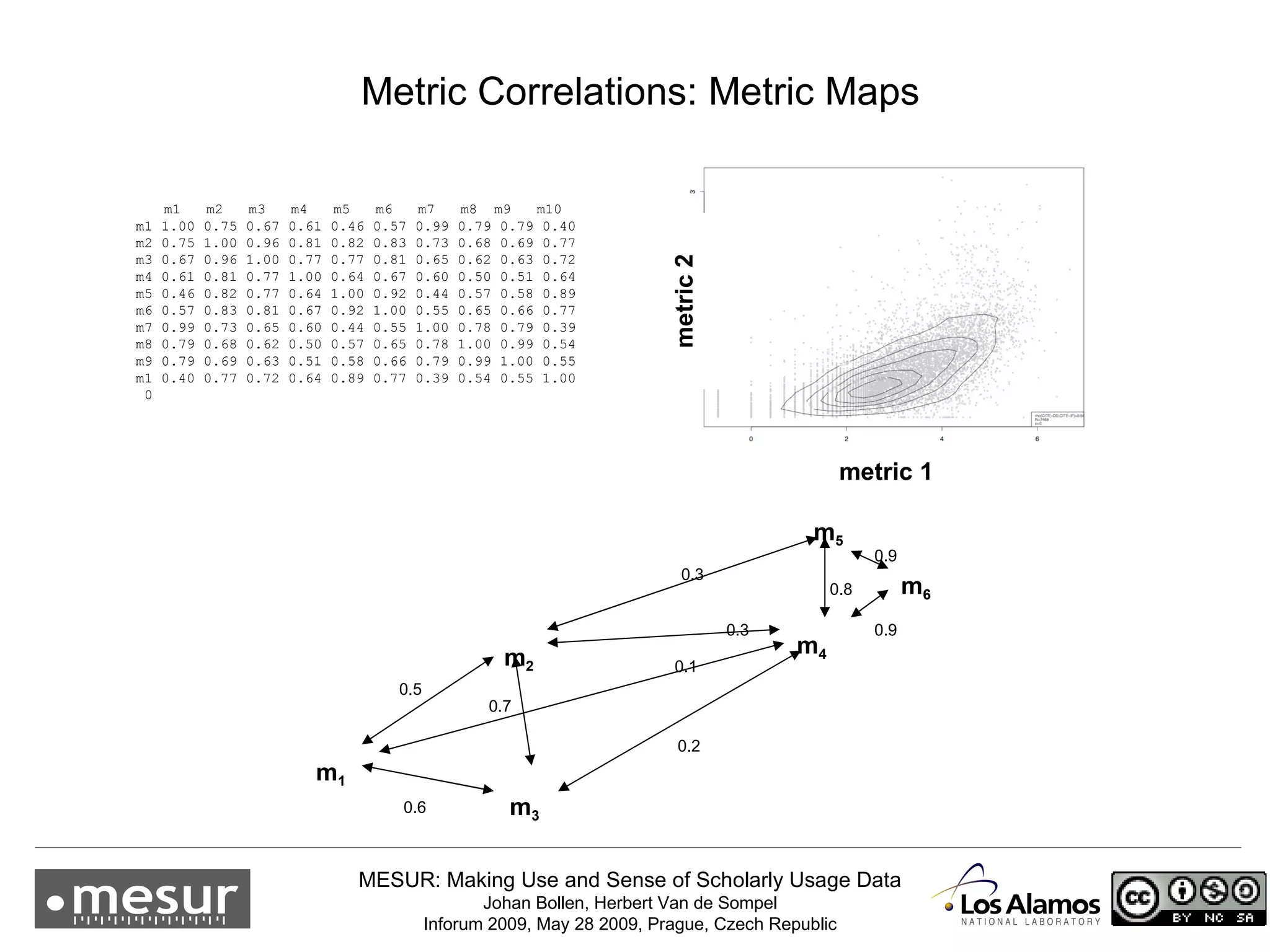
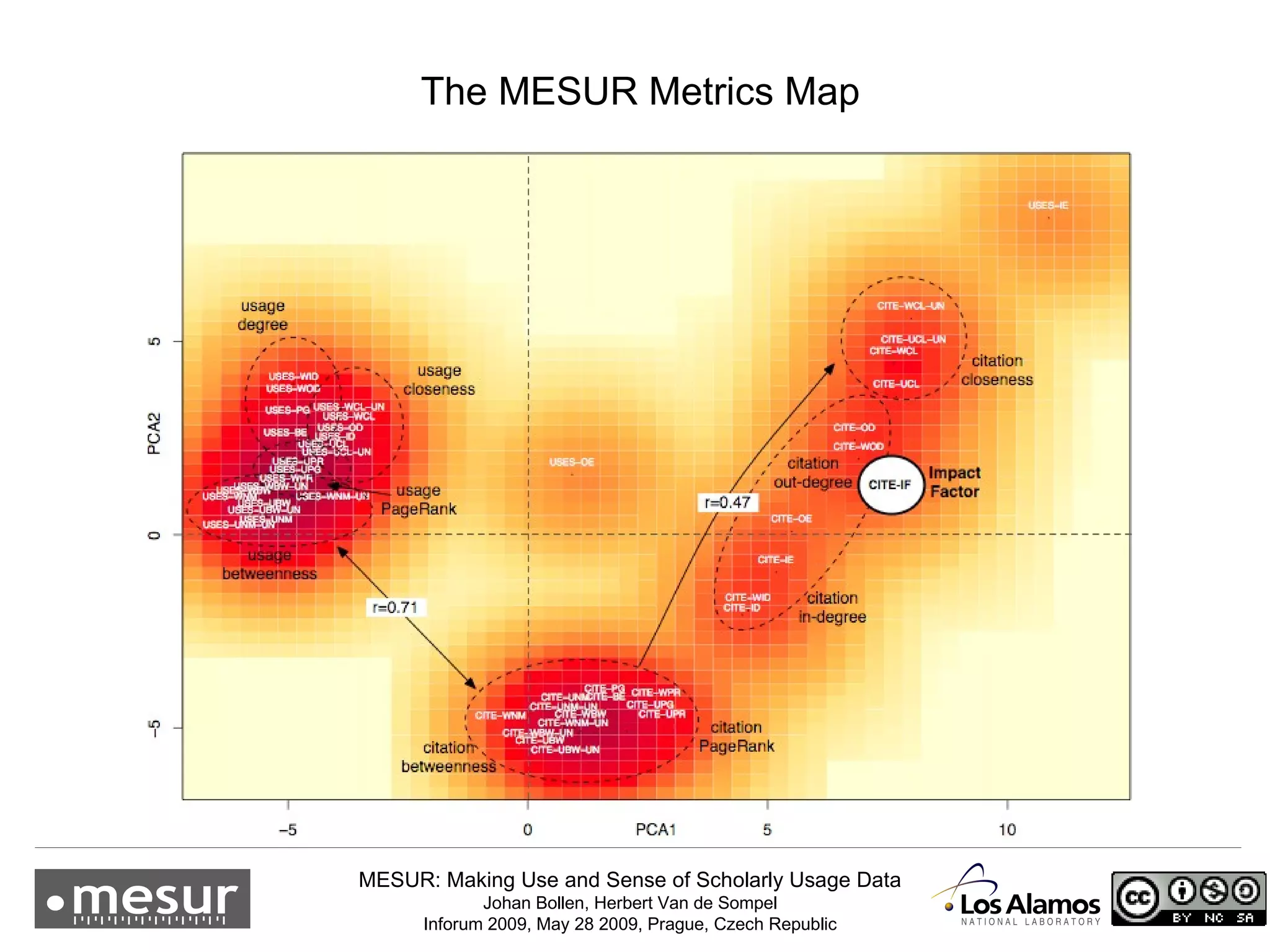
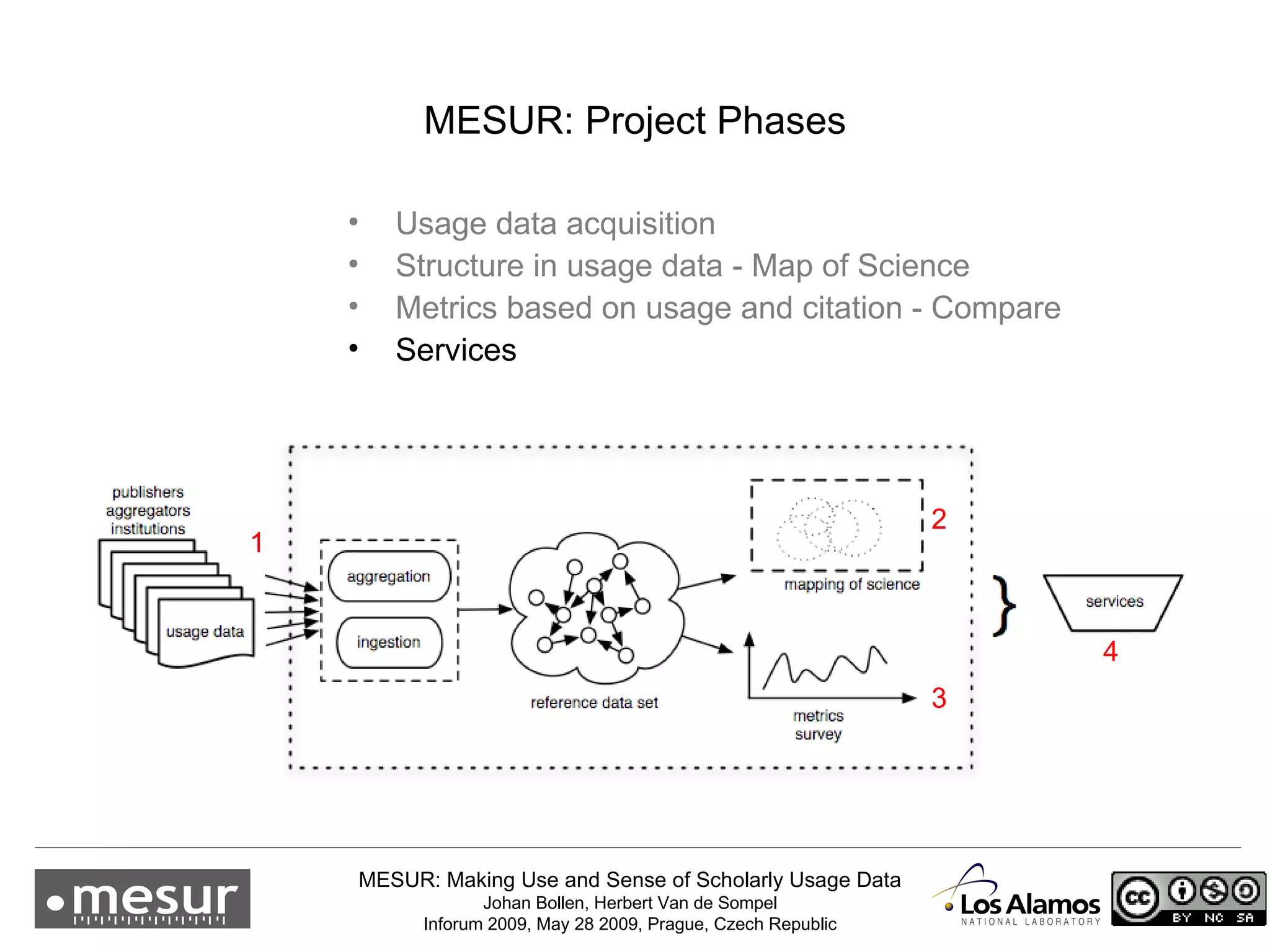
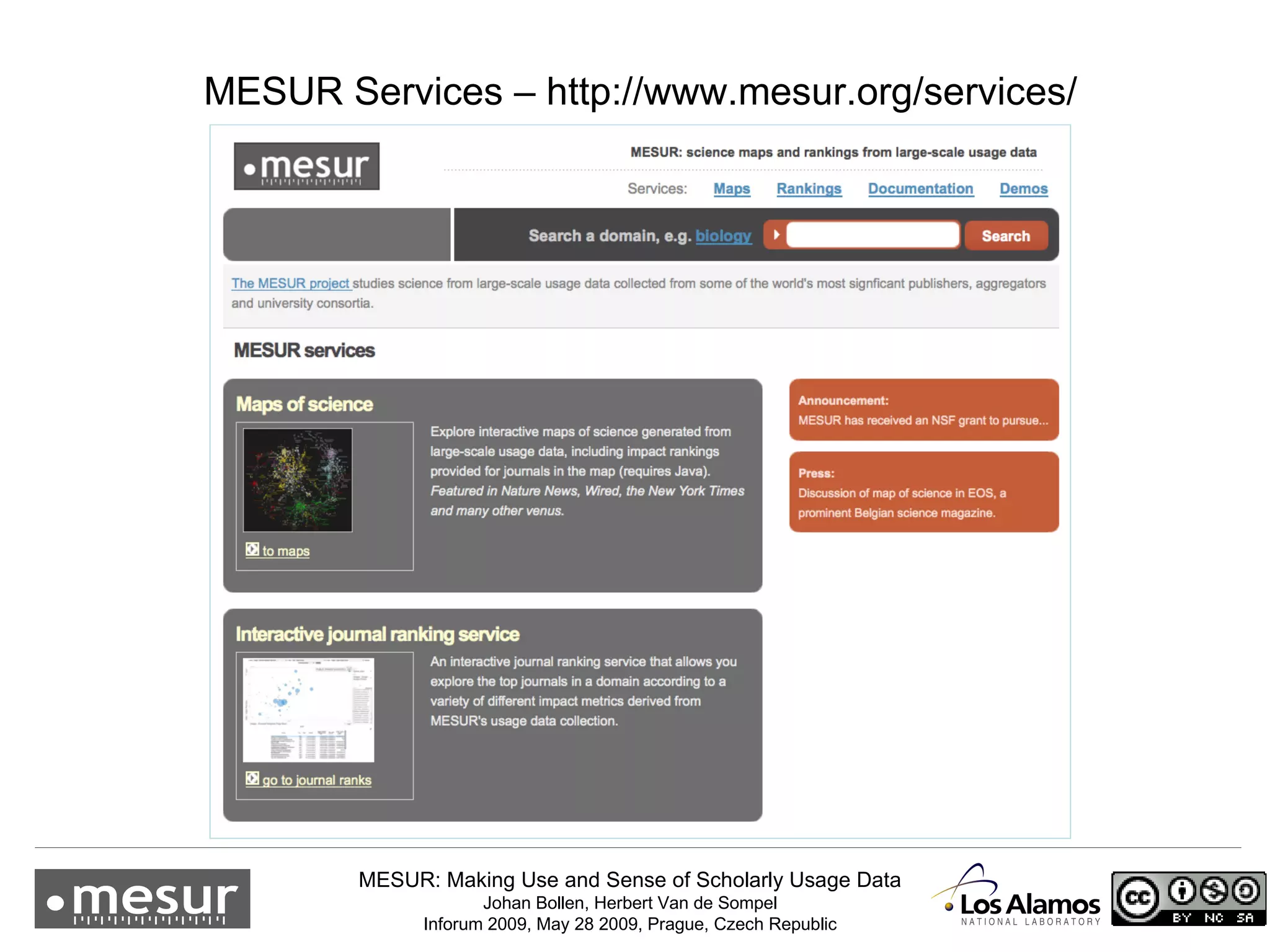
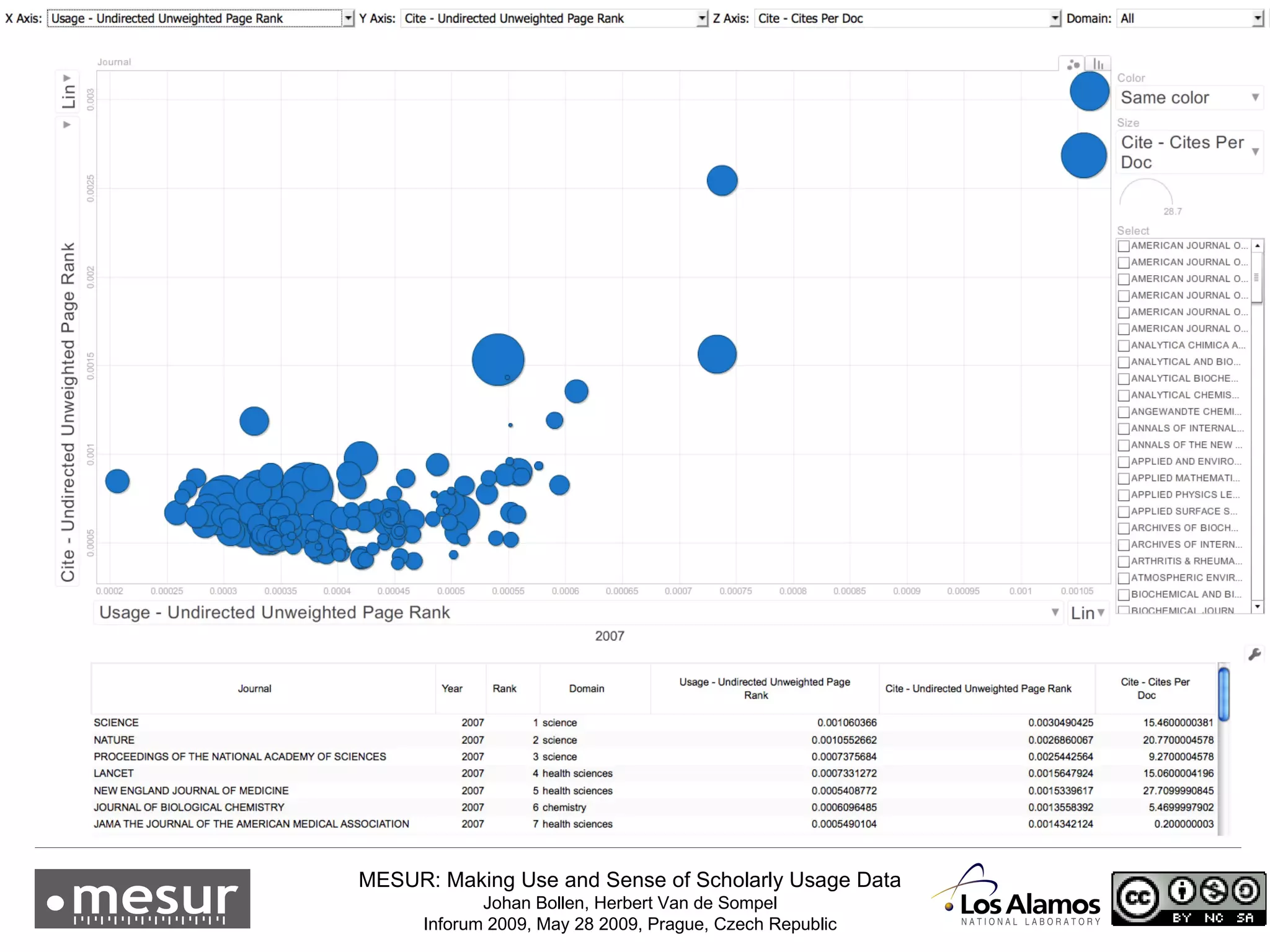
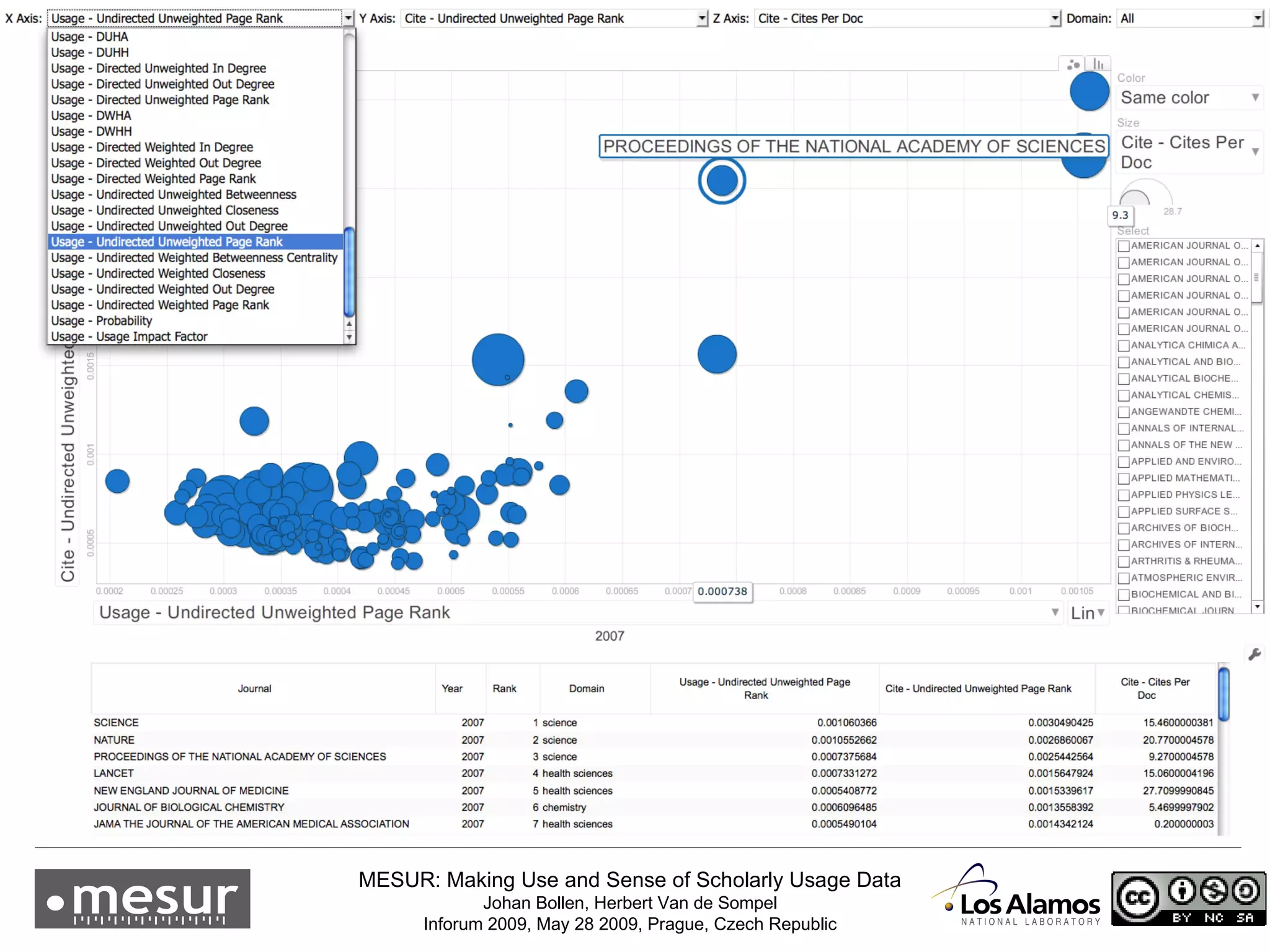
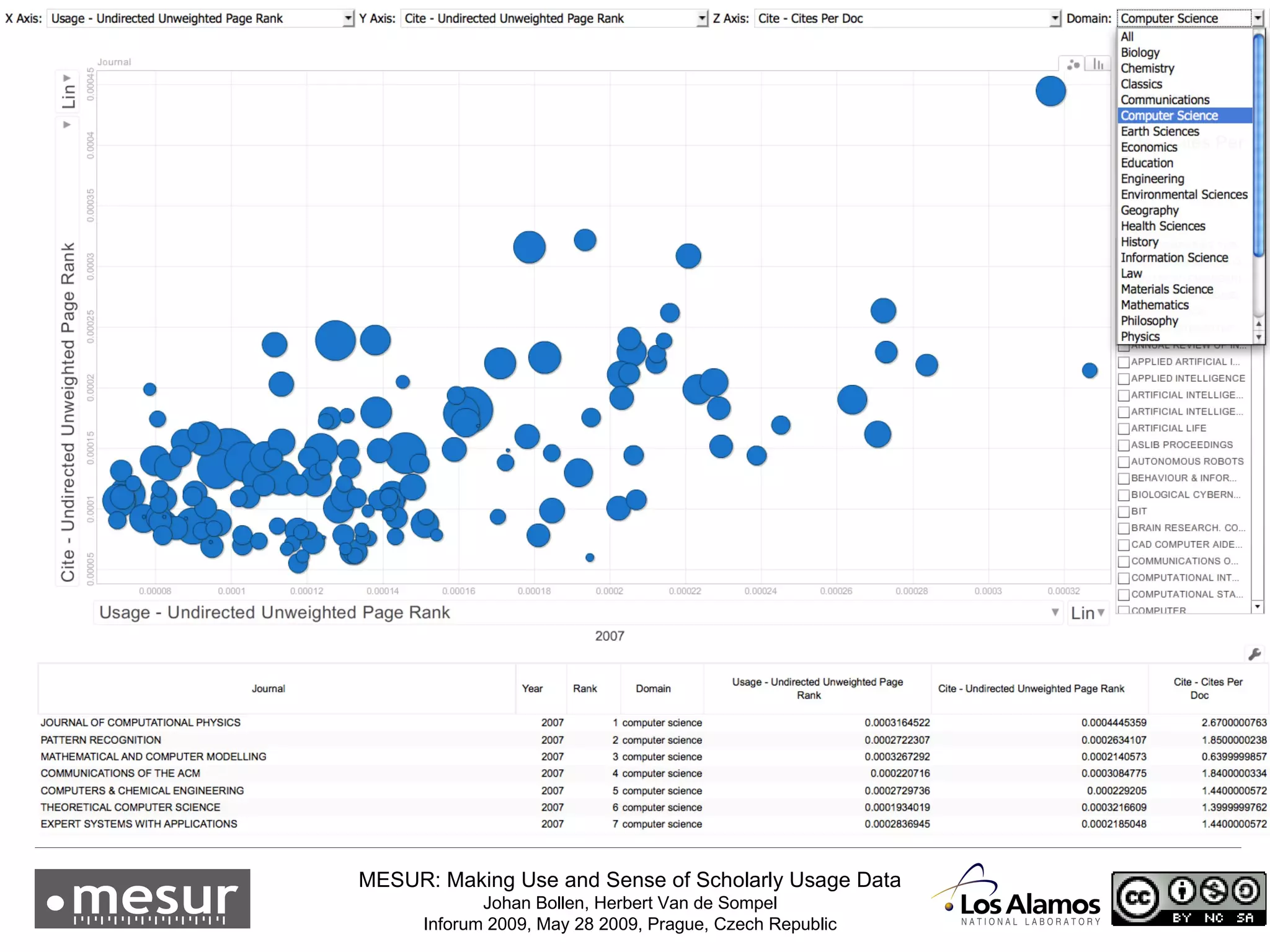
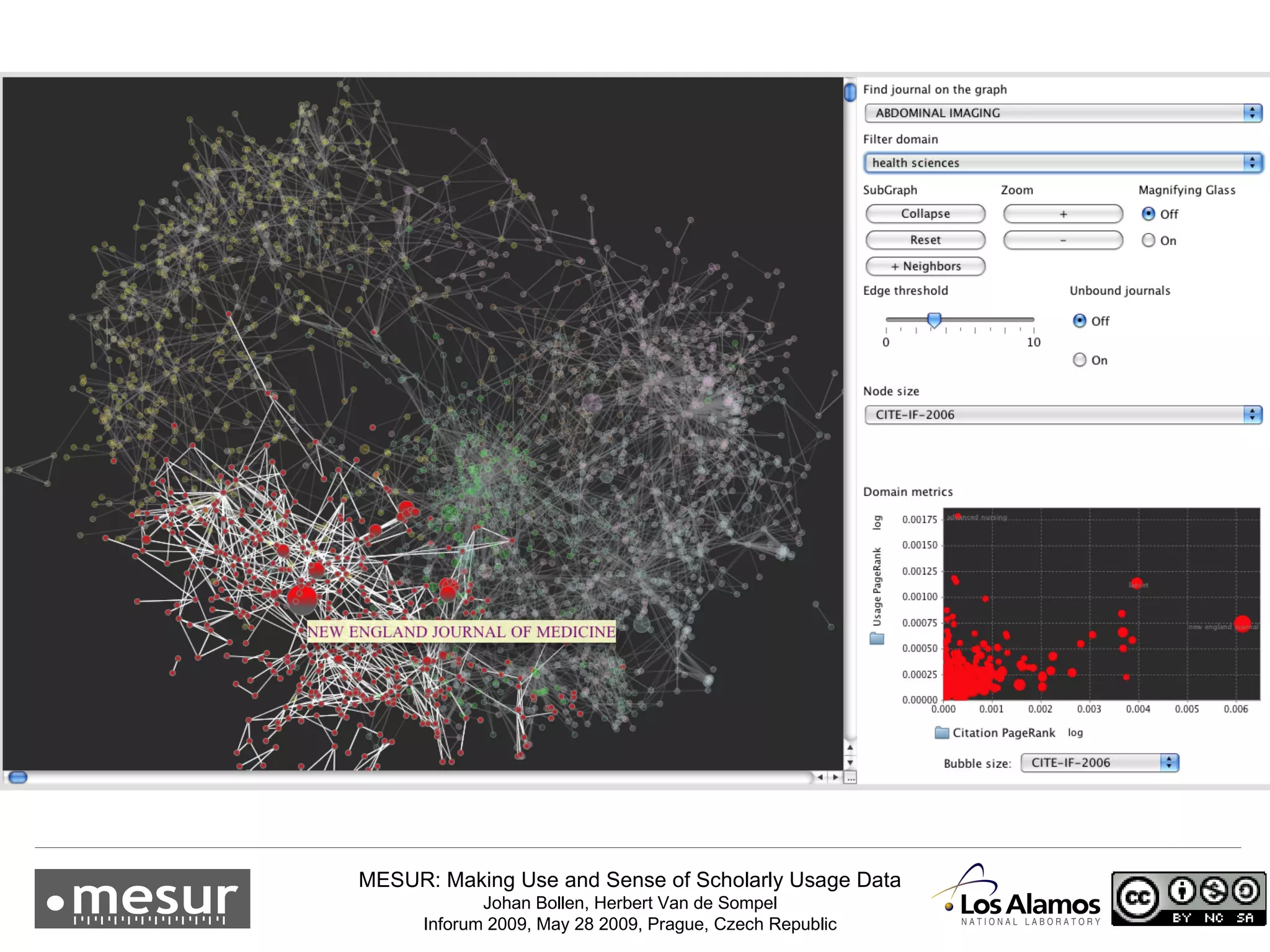




The document discusses the MESUR (Making Use and Sense of Scholarly Usage Data) project which aims to develop new metrics for scholarly impact and prestige based on usage data from digital scholarly resources rather than just citations. The key points are: 1) MESUR analyzes over 1 billion usage events of scholarly articles and develops network-based metrics from usage patterns to map the structure of science. 2) Preliminary results show relevant structure in usage-based network maps that correlate with traditional citation-based metrics. 3) MESUR has produced a variety of usage and citation-based metrics and developed online tools for exploring these metrics.











































































































