Download to read offline


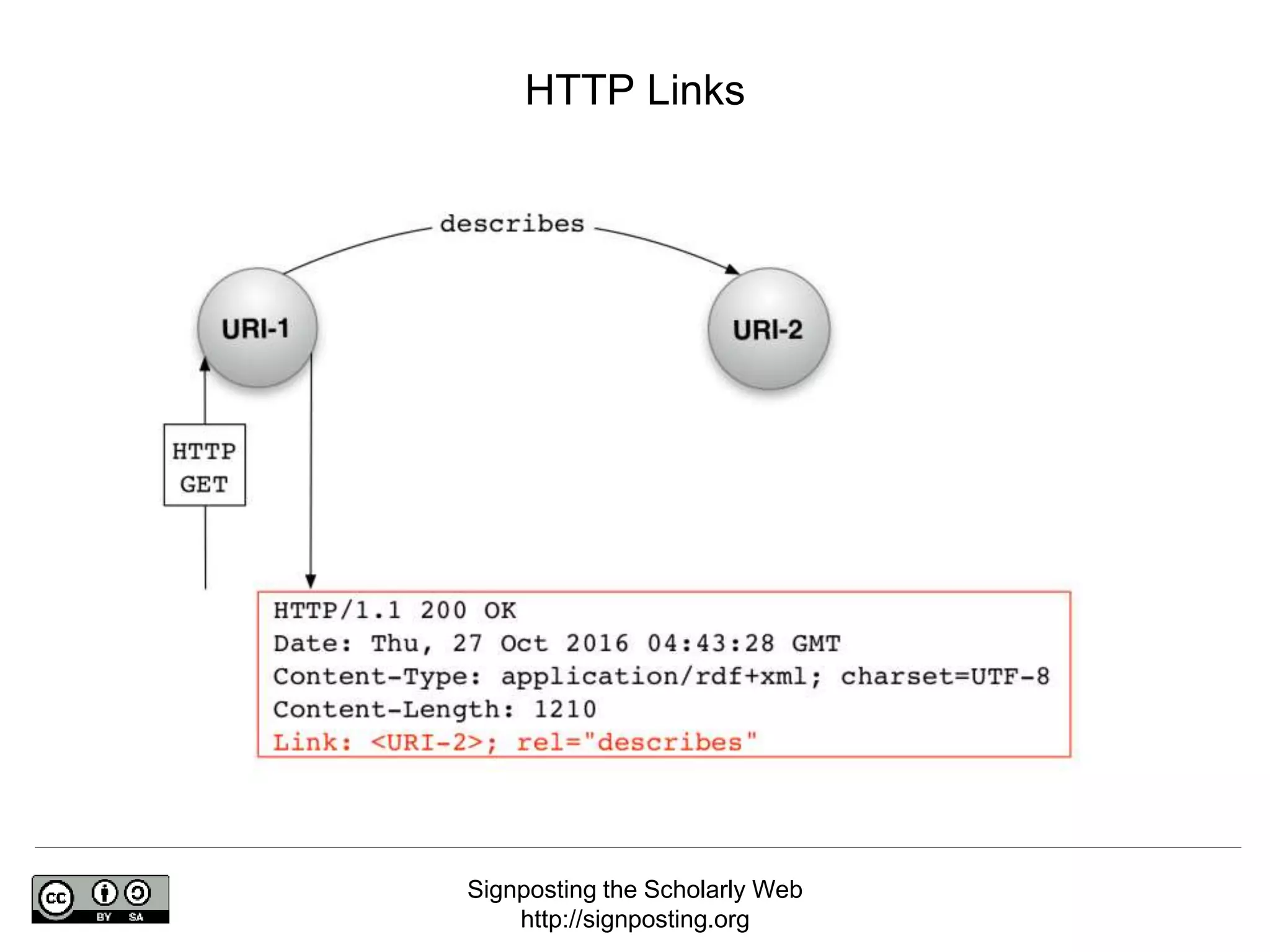














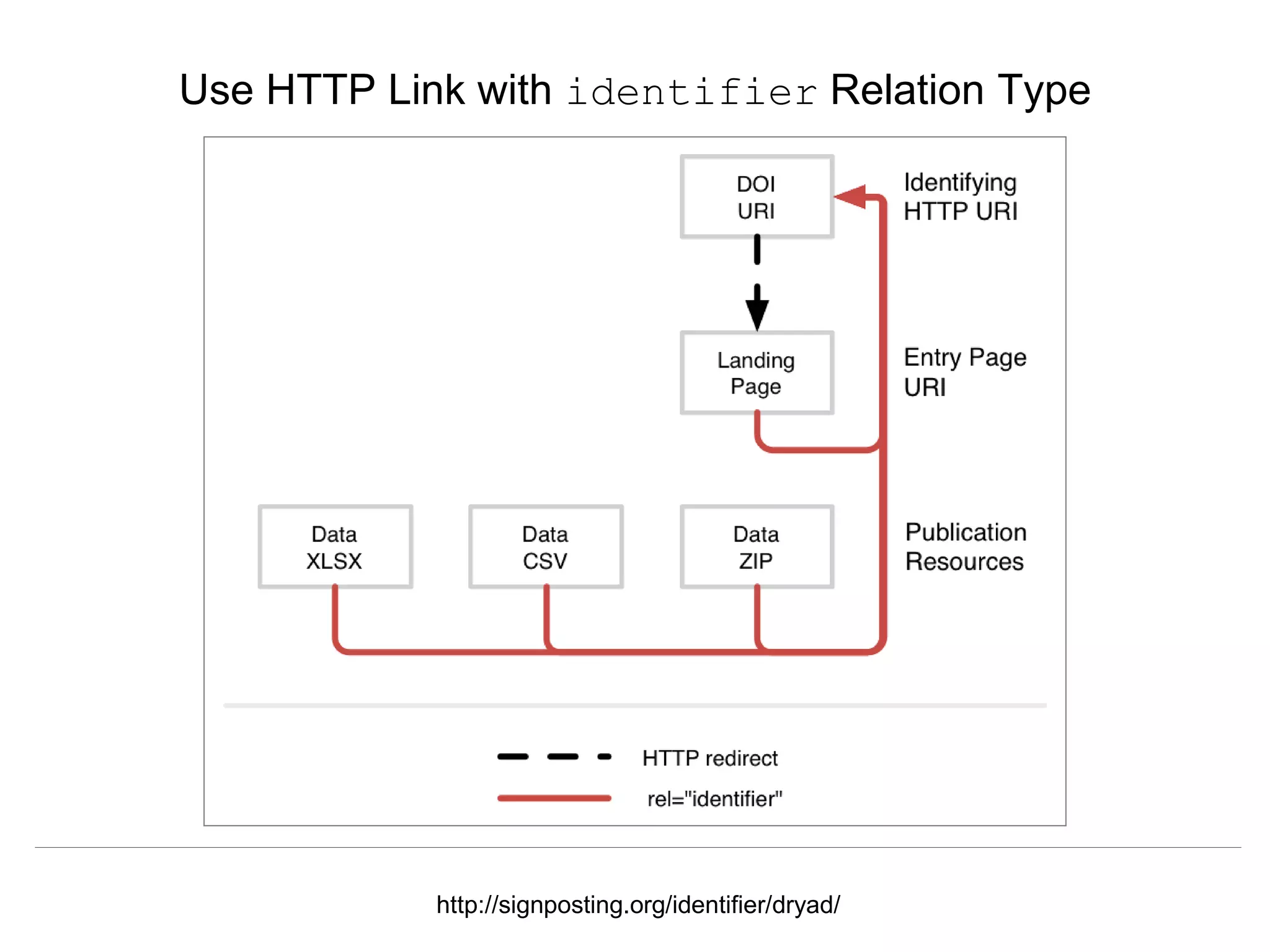
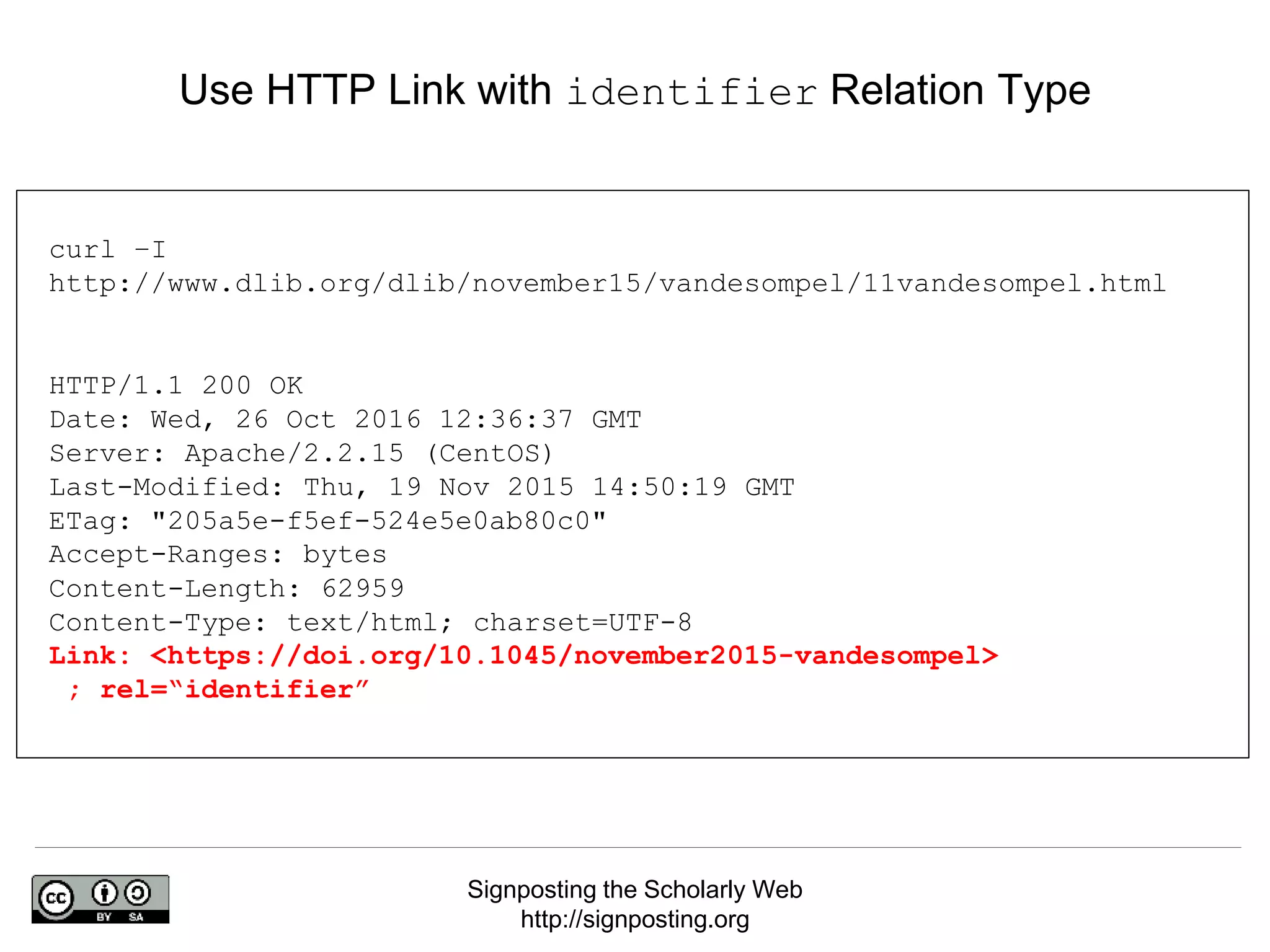

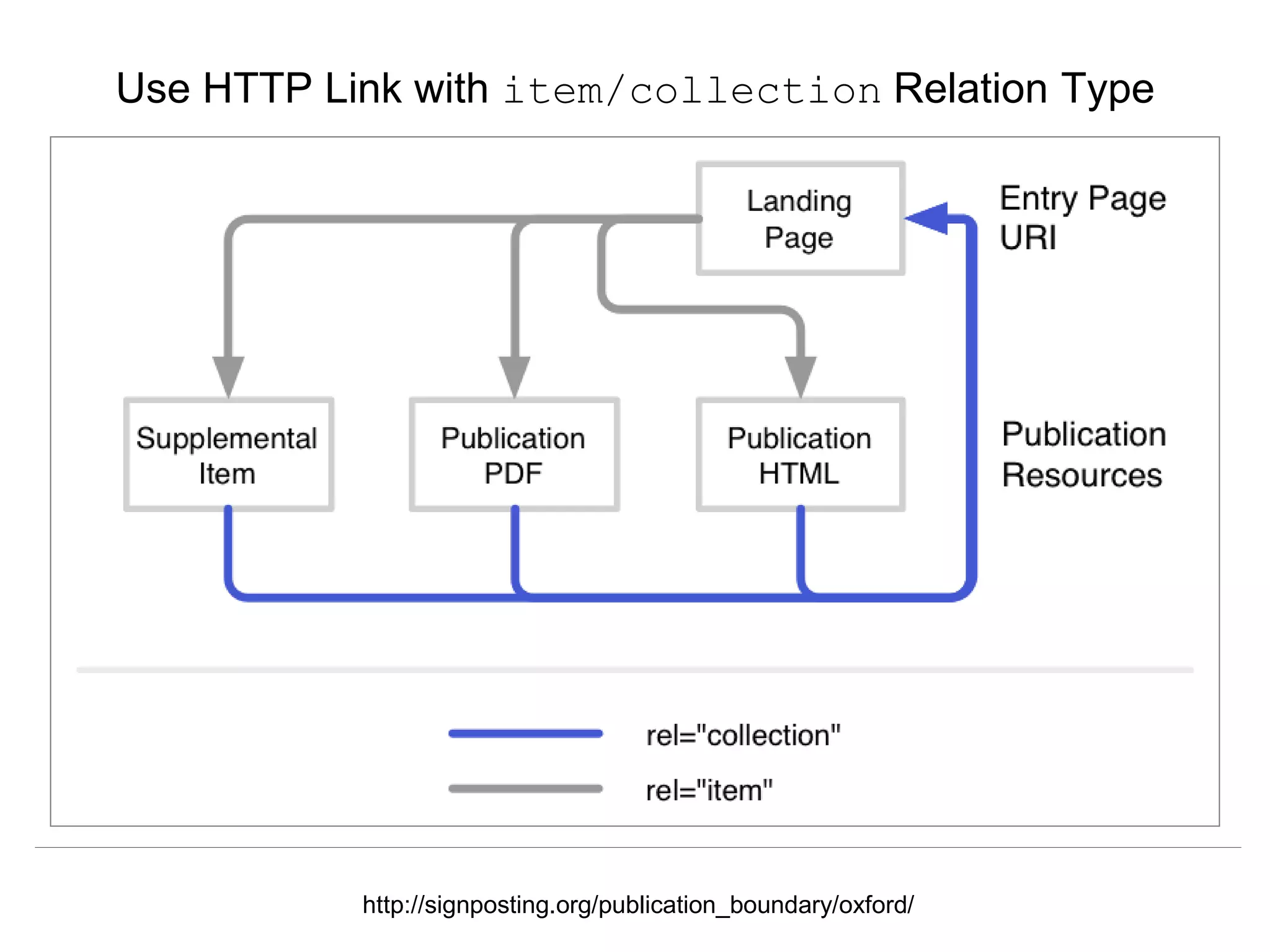
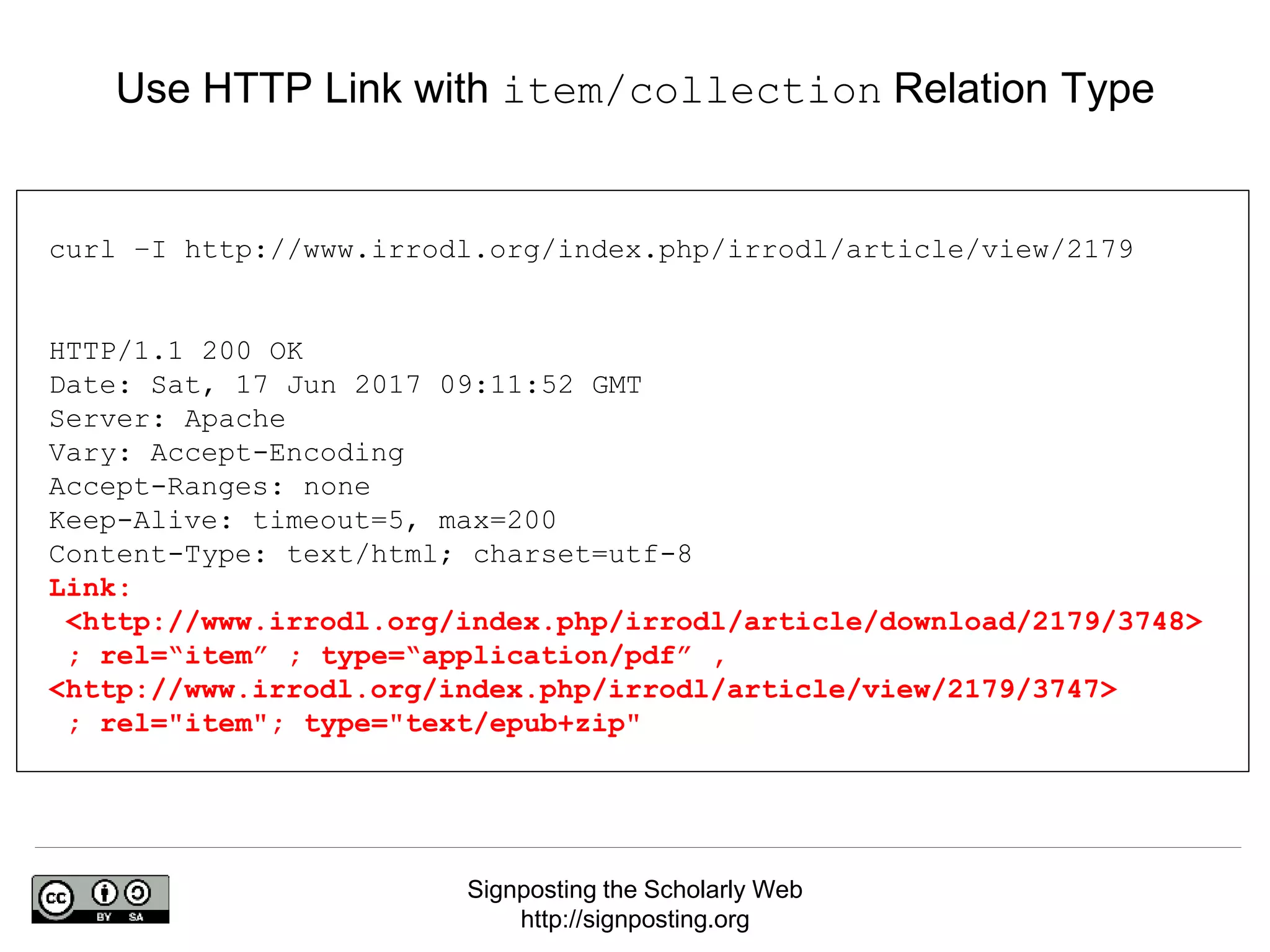

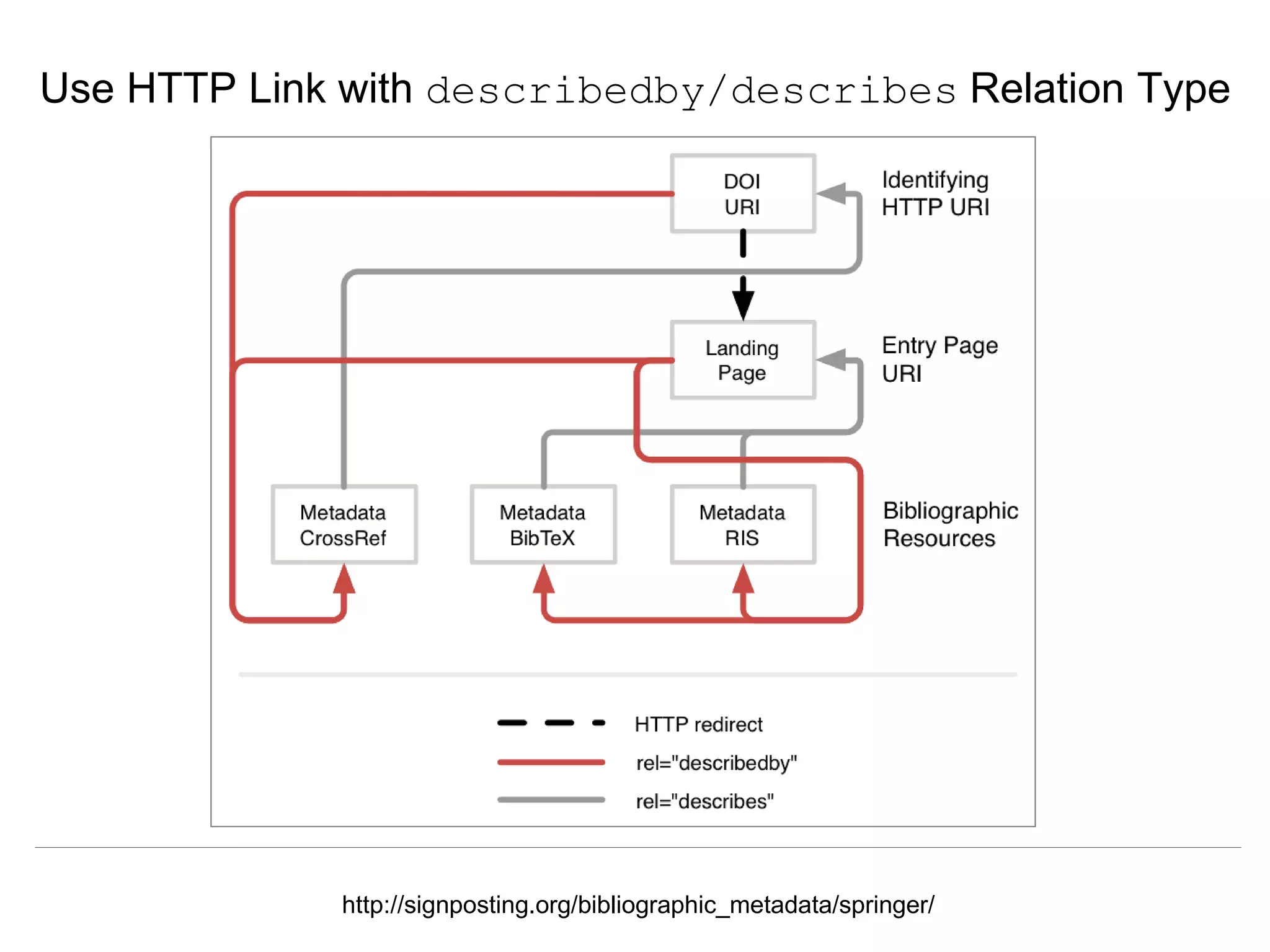



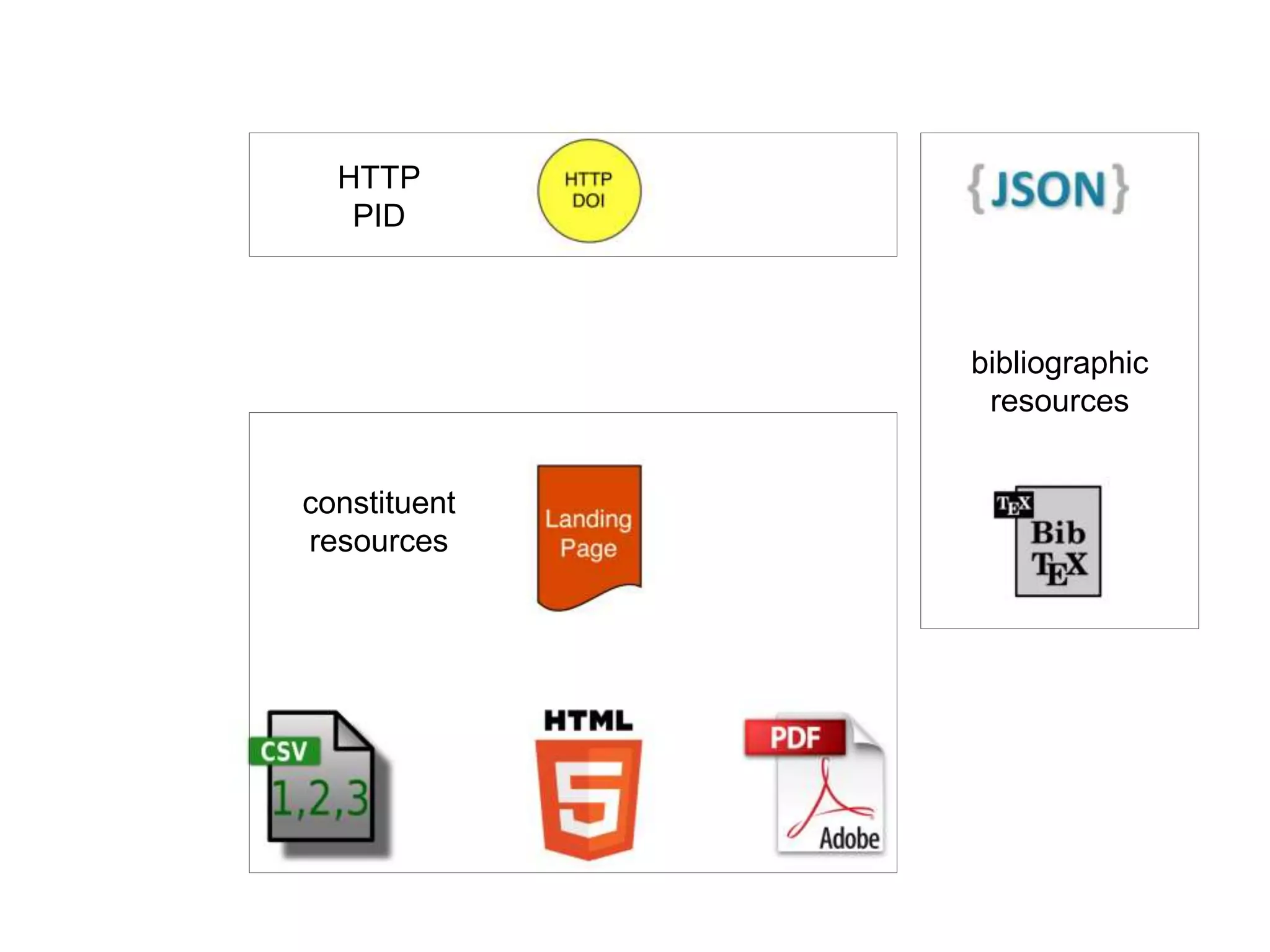
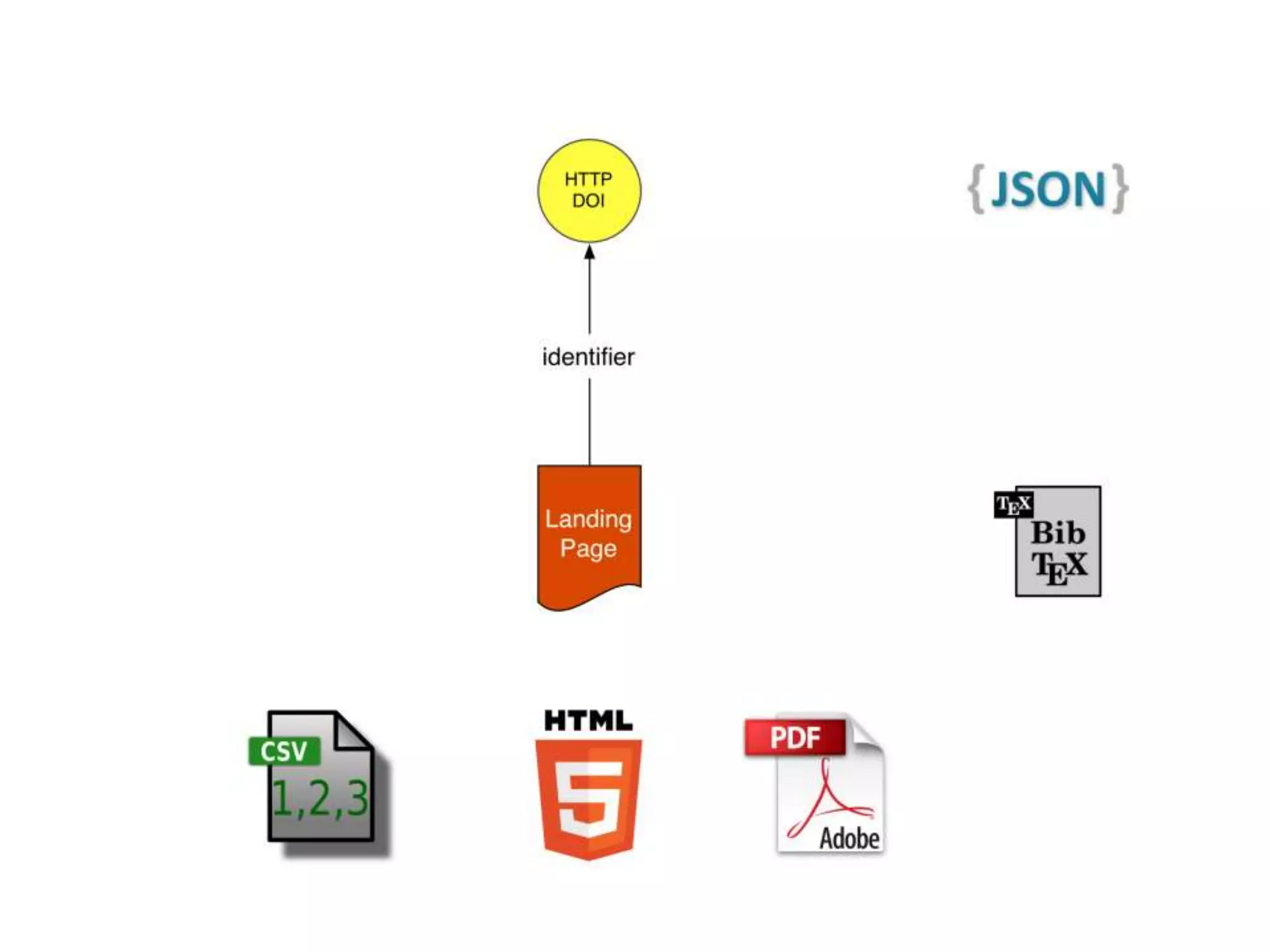
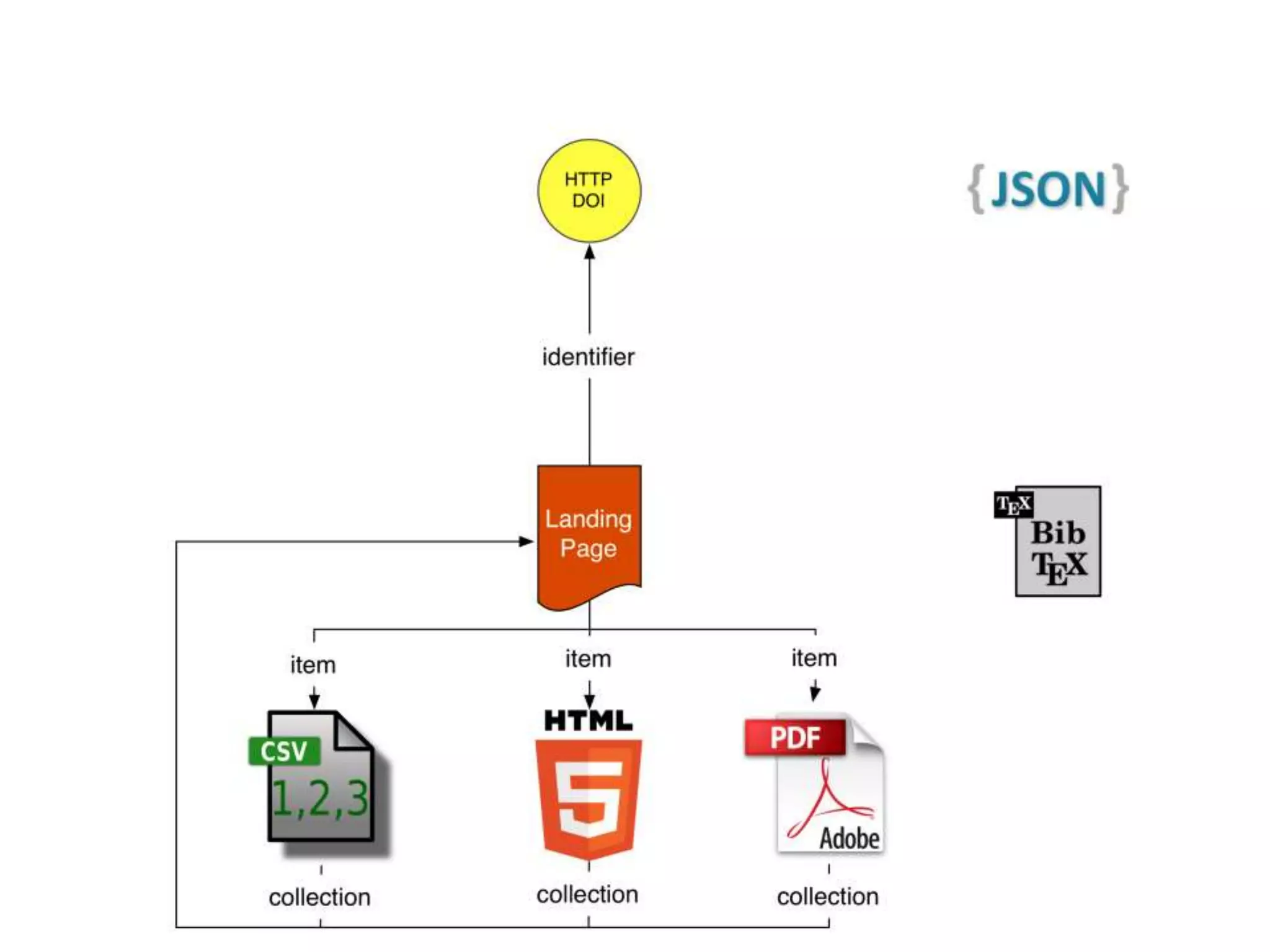
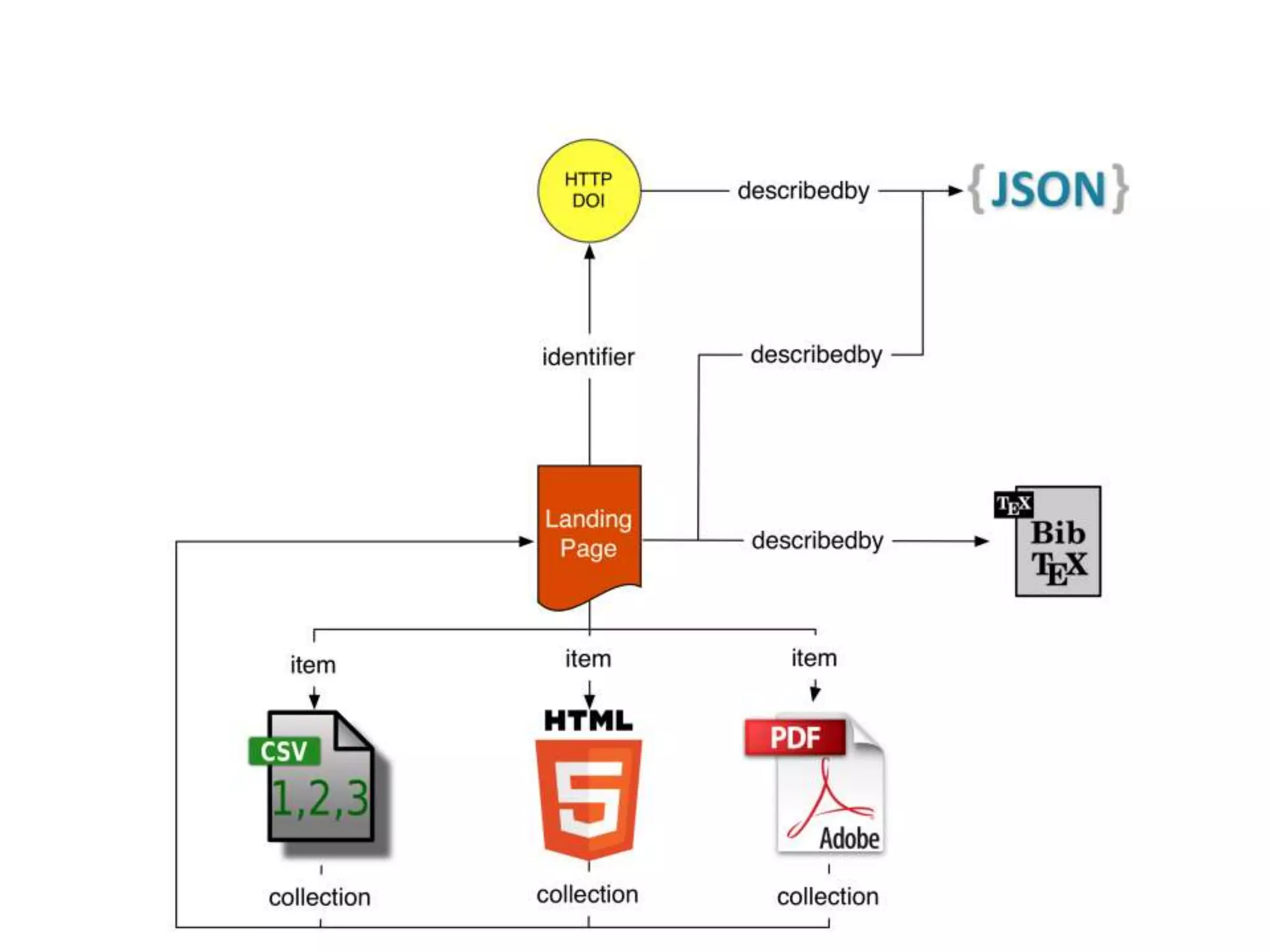
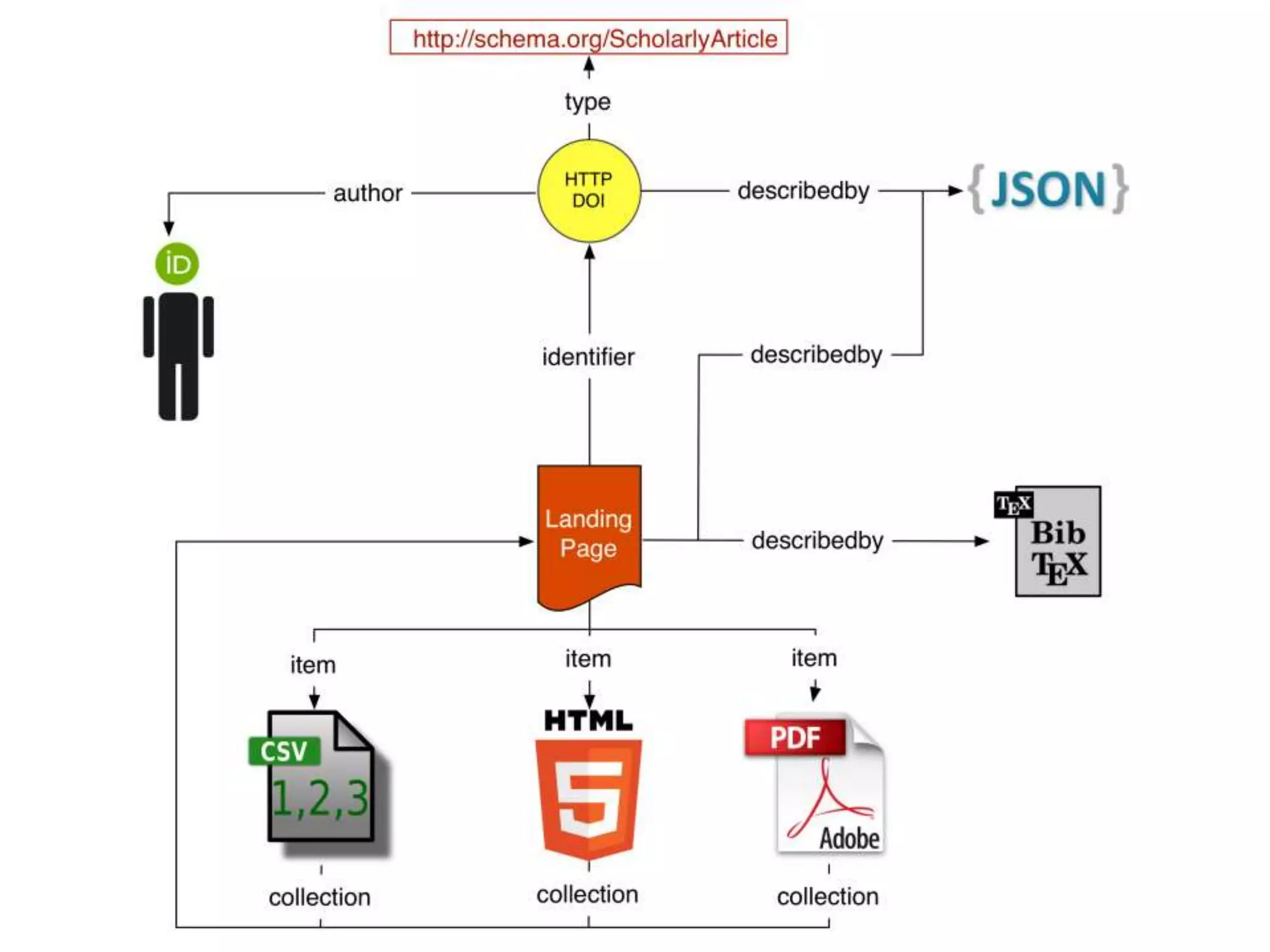


The document discusses 'signposting the scholarly web,' which involves using HTTP links to improve interlinking among scholarly resources. It outlines proposed patterns for conveying persistent identifiers, bibliographic metadata, and establishes a formal specification for HTTP link relation types to enhance interoperability. The initiative, funded by the Andrew W. Mellon Foundation, aims to resolve long-standing issues related to the discoverability and accessibility of scholarly resources online.


















































































