FAIR Signposting: A KISS Approach to a Burning Issue

Various FAIR criteria pertaining to machine interaction with scholarly artifacts can commonly be addressed by means of repository-wide affordances that are uniformly provided for all hosted artifacts rather than through artifact-specific interventions. If various repository platforms provide such affordances in an interoperable manner, devising tools - for both human and machine use - that leverage them becomes easier. My involvement, over the years, in a range of interoperability efforts has brought the insight that two factors strongly influence adoption: addressing a burning issue and delivering a KISS solution to tackle it. Undoubtedly, FAIR and FAIR DOs are burning issues. FAIR Signposting <https://signposting.org/FAIR/> is an ad-hoc repository interoperability effort that squarely fits in this problem space and that purposely specifies a KISS solution, hoping to inspire wide adoption.

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Similar to FAIR Signposting: A KISS Approach to a Burning Issue
Similar to FAIR Signposting: A KISS Approach to a Burning Issue (20)
More from Herbert Van de Sompel
More from Herbert Van de Sompel (20)
Recently uploaded
Recently uploaded (16)
FAIR Signposting: A KISS Approach to a Burning Issue
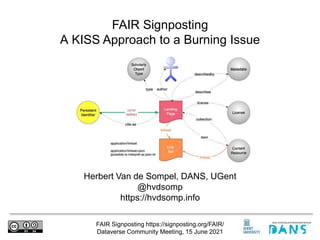
- 1. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 Herbert Van de Sompel, DANS, UGent @hvdsomp https://hvdsomp.info FAIR Signposting A KISS Approach to a Burning Issue
- 2. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 20+ Years Interoperability Efforts Related To Scholarly Objects OAI-PMH OAI-ORE Memento IIIF info URI Web Annotation ResourceSync Robust Links OpenURL
- 3. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 Cartoon by Patrick Hochstenbach The FAIR Signposting Profile is an Implementation Guideline Signposting, since 2015
- 4. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 Burning Issue: Clarify How Scholarly Objects Exist on the Web
- 5. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 Burning Issue: Clarify How Scholarly Objects Exist on the Web
- 6. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 • Make it easy for machines to interact with scholarly objects on the Web • This is a burning issue because the lack of a uniform interface to scholarly objects on the web requires ad-hoc platform-specific solutions for the creation of cross-platform services • Think of e.g. Zotero, LOCKSS, numerous APIs, … • There’s not even a uniform way to determine the PID of a scholarly object from the landing page • This makes the barrier to entry for the creation of cross-platform services high. Which tends to lead to centralization, monopolies, lack of innovation. Burning Issue: Clarify How Scholarly Objects Exist on the Web
- 7. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 • The problem has been around for a long time • OAI-ORE (1) (2008) addressed it in a descriptive way using linked data technology • RO-Crate (2) (2019) addresses it in a descriptive and simpler way using linked data technology • The problem directly relates to • FAIR • FAIR Digital Object Protocol/Framework both of which are quite on fire Burning Issue: Clarify How Scholarly Objects Exist on the Web (1) OAI-ORE ; https://www.openarchives.org/ore/ (2) RO-Crate ; https://www.researchobject.org/ro-crate/
- 8. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 • Addresses the problem in a navigational way, by providing meaningful links (signposts) allowing machines to follow their nose to obtain the information they are after • Uses a KISS, standards-based REST/HATEOAS approach consisting of: • Typed web links (1) • IANA-registered relation types (2) defined in formal specifications • Recognizes the status quo - scholarly objects are represented by landing pages on the web - but enhances it to empower machines KISS Approach: FAIR Signposting Profile (1) RFC8288 – Web Linking ; https://tools.ietf.org/html/rfc8288 (2) IANA Link Relations ; https://www.iana.org/assignments/link-relations/
- 9. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 • Concrete Implementation Guideline for Signposting, indicating which typed links to convey for each of the resources that make up a scholarly object on the web • Implementation targets are platforms that host research outputs e.g. data repositories, institutional repositories, publisher platforms, etc. • Dataverse implementation currently in Pull Request Status, courtesy of DANS • Two complementary approaches to provide typed links: • Concise set of links provided by-value • Comprehensive set of links provided by-reference KISS Approach: FAIR Signposting Profile
- 10. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 Typed Links By Value (HTTP Link, HTML <link>)
- 11. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 HTTP Link (for resources of all media types) $ curl -i "https://example.org/page/7507" HTTP/1.1 200 OK Date: Fri, 9 Oct 2020 19:19:22 GMT Content-Type: text/html Content-Length: 25414 Link: <https://doi.org/10.5061/dryad.5d23f> ; rel="cite-as" , <https://orcid.org/0000-0002-1825-0097> ; rel="author" , <https://example.org/meta/7507/bibtex> ; rel="describedby" ; type="application/x-bibtex" , <https://creativecommons.org/licenses/by/4.0/> ; rel="license" , <https://schema.org/ScholarlyArticle> ; rel="type" , <https://schema.org/AboutPage> ; rel="type” , <https://example.org/file/7507/1> ; rel="item" ; type="application/pdf” <html lang="en"> <head> <meta charset="utf-8"> ...
- 12. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 HTML <link> (for HTML pages) $ curl -i "https://example.org/page/7507" HTTP/1.1 200 OK Date: Fri, 9 Oct 2020 19:19:48 GMT Content-Type: text/html Content-Length: 25414 <html lang="en"> <head> <meta charset="utf-8"> <link rel="cite-as" href="https://doi.org/10.5061/dryad.5d23"> <link rel="author" href="https://orcid.org/0000-0002-1825-0097"> <link rel="describedby" type="application/x-bibtex" href="https://example.org/meta/7507/bibtex"> <link rel="license" href="https://creativecommons.org/licenses/by/4.0/"> <link rel="type" href="https://schema.org/ScholarlyArticle"> <link rel="type" href="https://schema.org/AboutPage"> <link rel="item" type="application/pdf” href="https://example.org/file/7507/1"> …
- 13. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 Typed Links By Reference (Link Set) Wilde, E, Van de Sompel H. (2021) Linkset: Media Types and a Link Relation Type for Link Sets https://datatracker.ietf.org/doc/draft-ietf-httpapi-linkset/
- 14. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 { "linkset": [ { "anchor": "https://example.org/page/7507", "cite-as": [ { "href": "https://doi.org/10.5061/dryad.5d23f" } ], }, … { "anchor": "https://example.org/file/7507/1", "collection": [ { "href": "https://example.org/page/7507", "type": "text/html" } ] } ] } Link Set in application/linkset+json Wilde, E, Van de Sompel H. (2021) Linkset: Media Types and a Link Relation Type for Link Sets https://datatracker.ietf.org/doc/draft-ietf-httpapi-linkset/
- 15. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 • Contributes to FAIRs, F, A, and R by informing machines • what the persistent identifier of a scholarly objects is, • what type of scholarly object it is, • where and what its content is, • where metadata that describes it is, • which license applies to the scholarly object, • what the persistent identifier of its author is • Contributes to FAIRs I by providing this information • in a uniform way • in a way that is interoperable with the Web at large FAIR Signposting Profile
- 16. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Protocol FAIR Digital Objects Forum https://fairdo.org/
- 17. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Framework Bonino, L. (2021) FAIR Digital Object Framework Documentation https://fairdigitalobjectframework.org/
- 18. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Framework Bonino, L. (2021) FAIR Digital Object Framework Documentation https://fairdigitalobjectframework.org/ • Very much looks like a Link Set
- 19. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Framework Bonino, L. (2021) FAIR Digital Object Framework Documentation https://fairdigitalobjectframework.org/ • Content negotiation in an abstract dimension: • a non-existing concept • negotiation is about actual document formats • Content negotiation with the PID: • assumes control over the PID • requires further centralization
- 20. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Framework, the Signposting Way
- 21. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Framework, the Signposting Way
- 22. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Framework, the Signposting Way
- 23. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Framework, the Signposting Way
- 24. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 FAIR Digital Object Framework with Signposting Extras
- 25. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 • Achieves what the FAIR Digital Object Framework desires by: • using links, the core ingredient of the web • using IANA-registered link types defined in formal specifications • conveying typed links in HTTP Link and HTML <link> • conveying typed links in Link Sets (soon to be IETF-standardized), which support semantic interpretation if needed • devising a navigational approach usable by basic web clients • not requiring standardization on metadata formats or ontologies as is essential for descriptive approaches • not requiring centralized infrastructure • Bottom line: FAIR Signposting provides a KISS uniform interface for machine interaction with scholarly objects on the Web by using existing technology only FAIR Signposting Profile
- 26. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 • Shawn Jones, Martin Klein, Harihar Shankar @ Los Alamos National Laboratory • Michael L. Nelson @ Old Dominion University • Simeon Warner @ Cornell University • Erik Wilde - Axway • QiQing Ding, Eko Indarto, Wilko Steinhoff, Vyacheslav Tykhonov, Jan van Mansum @DANS • Anusuriya Devaraju @ Terrestrial Ecosystem Research Network • Robert Huber @ PANGEA • Geoff Bilder, Karl Ward, Joe Wass @ CrossRef • David Rosenthal @ Stanford University • Phil Archer, Dominique Guinard – GS1 • Stian Soiland-Reyes – University of Manchester • Sarven Capadisli - Inrupt • Jon Kunze – California Digital Library • Patrick Hochstenbach @ Ghent University • Luc Boruta @ Thunken • Enno Meijer @ The Royal Library of The Netherlands Acknowledgments
- 27. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 Please spread the word and provide feedback at https://github.com/hvdsomp/signposting FAIR Signposting A KISS Approach to a Burning Issue "Signposting has a ridiculously low cost of entry (if you serve scholarly content over HTTP, you're already almost there)" - Luc Boruta, thunken.com
- 28. FAIR Signposting https://signposting.org/FAIR/ Dataverse Community Meeting, 15 June 2021 Use Case: On Demand Dataset Archiving
Editor's Notes
- Two factors: burning issue & a solution as simple as possible to implement
- All link types IANA registered Cardinality of links Media types Collection link allows to climb back up to landing page and resources linked from there Type: schema.org but can obviously use other Content resources can override info at landing page
- Linkset motivation: large number of links, single point of access to all links, content resources can’t provide link (reside at 3rd party, don’t know they belong to an object)
- FDOF Identifier Record = Link Set (shows all links) Content Negotiation in Abstract Dimension Content Negotiation with PID, which assumes all info available there, i.e. further centralization and need for repo-to-resolver sync
- FDOF Identifier Record = Link Set (shows all links) Content Negotiation in Abstract Dimension Content Negotiation with PID, which assumes all info available there, i.e. further centralization and need for repo-to-resolver sync