Downloaded 17 times































![Herbert Van de Sompel @hvdsomp
EuropeanaTech 2018, Rotterdam, The Netherlands, 15/05/18
A Trace for slideshare Presentations
{ "portal_url_match":
"(slideshare.net)/([^/]+)/([^/]+)",
"actions": [{ "action_order": "1",
"value": "div.j-next-btn.arrow-right",
"type": "CSSSelector",
"action": "repeated_click",
"repeat_until": {
"condition": "changes",
"type": "resource_url"
}
},
{ "action_order": "2",
"value": "div.notranslate.transcript.add-
padding-right.j-transcript a",
"type": "CSSSelector",
"action": "click"
}
], …](https://image.slidesharecdn.com/perseveranceonpersistence-180516083647/85/Perseverance-on-Persistence-72-320.jpg)

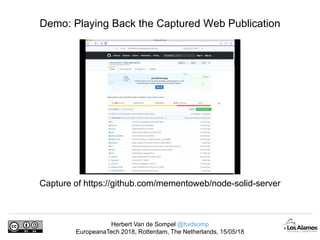


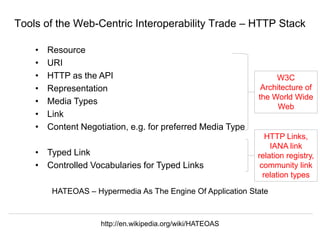
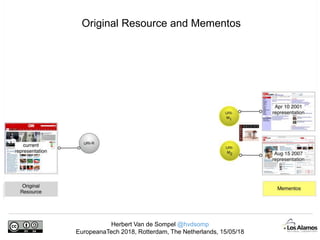
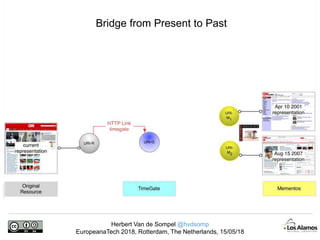
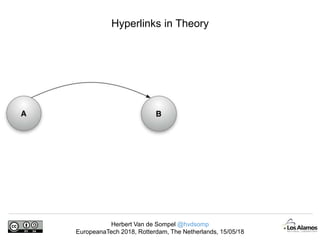
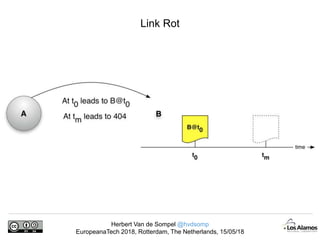
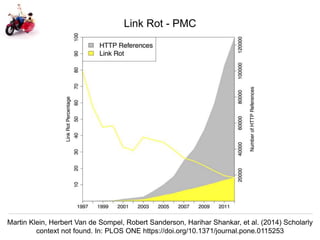
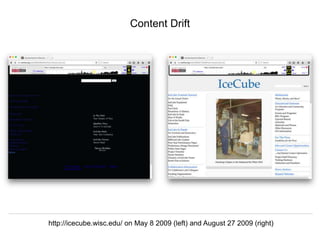
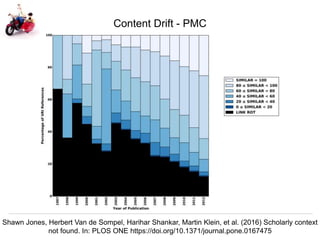
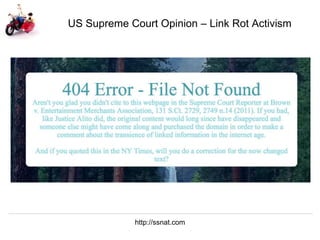
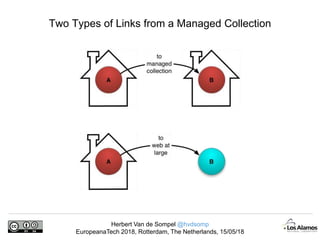
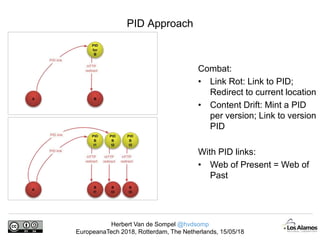
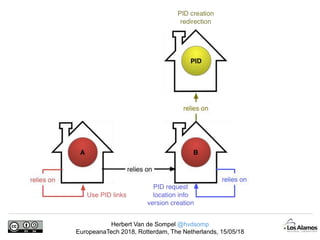
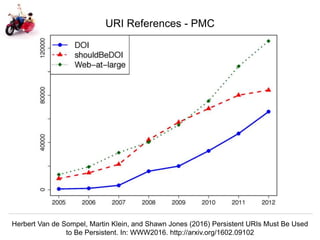
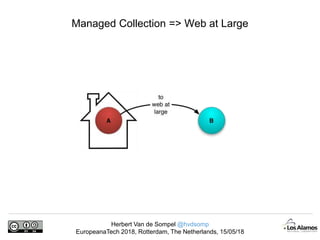
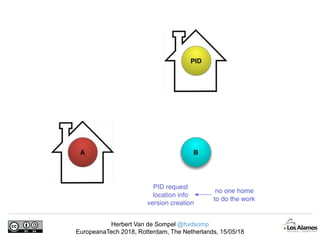
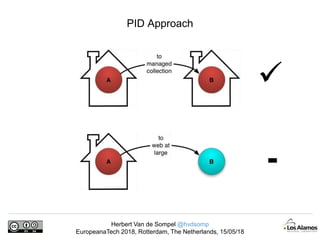
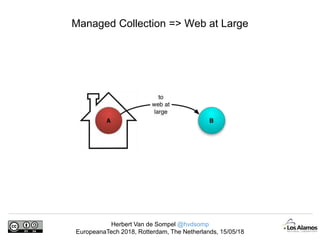
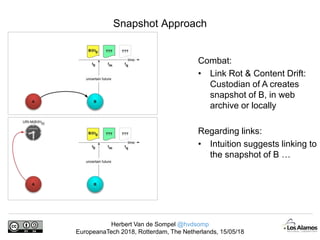
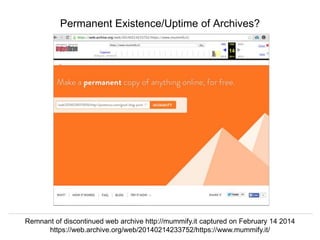
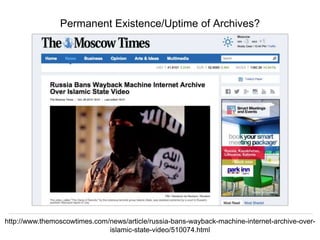
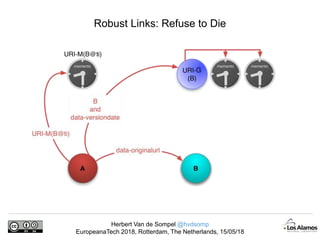
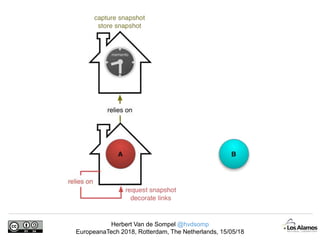
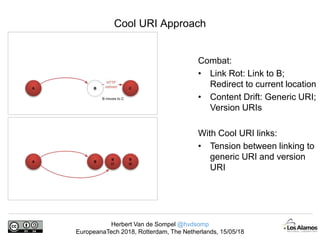
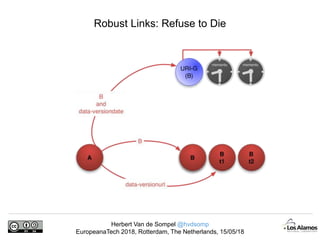
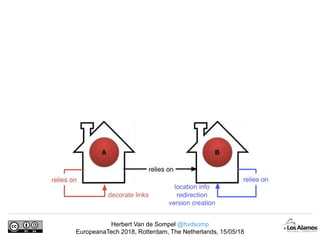
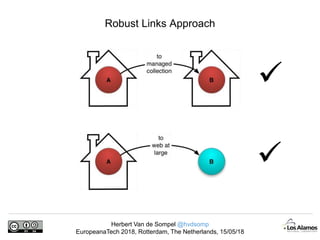
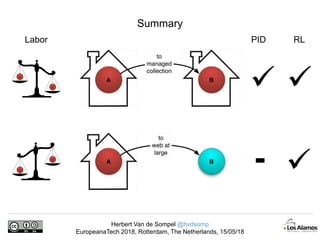
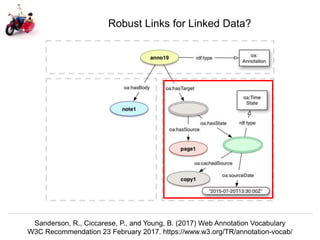
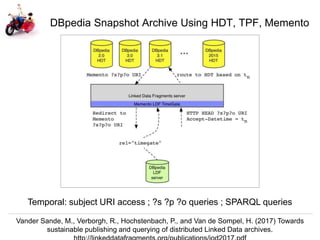
The document discusses Herbert Van de Sompel's insights on digital persistence and interoperability challenges in the context of scholarly assets, emphasizing the need for a web-centric paradigm. It addresses issues like 'link rot' and 'content drift,' which hinder faithful navigation of archived web content, and proposes solutions like persistent identifiers (PIDs) and robust linking practices to manage these challenges. Furthermore, it highlights the importance of machine learning for routing web archive requests and presents the Memento framework for temporal access to historical web states.
































































