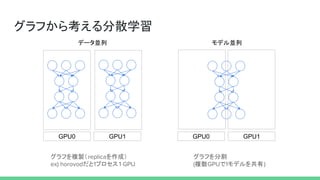
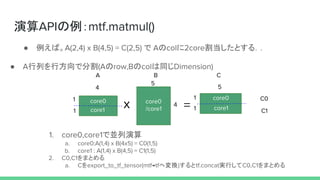
演算のデバイス割り振り
def parallel(devices, fn,*args, **kwargs):
...
for i, device in enumerate(devices):
with tf.device(device):
with tf.variable_scope("parallel_%d" % i):
my_args = [x[i] for x in args]
my_kwargs = {k: v[i] for k, v in six.iteritems(kwargs)}
ret.append(fn(*my_args, **my_kwargs))
内部的にwith tf.deviceで各デバイスに演算を割り当てている



![Mesh Tensorflow実行例
graph = mtf.Graph()
mesh = mtf.Mesh(graph, "my_mesh")
row_x = mtf.Dimension("row_x", 6)
col_x = mtf.Dimension("col_x", 4)
row_y = mtf.Dimension("row_y", 4)
col_y = mtf.Dimension("col_y", 5)
x = mtf.import_tf_tensor(
mesh, tf.random.uniform([6,4]),
mtf.Shape([row_x, col_x]))
y = mtf.import_tf_tensor(
mesh, tf.random.uniform([4,5]),
mtf.Shape([row_y, col_y]))
result = mtf.matmul(x, y, output_shape=[row_x, col_y])
mesh_shape = "b1:2"
mesh_layout = "col_x:b1"
mesh_shape = mtf.convert_to_shape(mesh_shape)
mesh_devices = [""] * mesh_shape.size
mesh_impl = mtf.placement_mesh_impl.PlacementMeshImpl(
mesh_shape, mesh_layout, mesh_devices)
lowering = mtf.Lowering(graph, {mesh: mesh_impl})
restore_hook = mtf.MtfRestoreHook(lowering)
tf_result = lowering.export_to_tf_tensor(result)
with tf.train.MonitoredTrainingSession(hooks=[restore_hook]) as sess:
print(sess.run(tf_result).shape)
mtf用のGraph, Mesh の作成
tfのtensor→mtfのtensorへ変換API
mtfの演算APIの呼び出し
mtf→tfへop,tensorの変換(lowering)
Session run()を実行](https://image.slidesharecdn.com/meshtensorflow2-190306132736/85/Mesh-tensorflow-7-320.jpg)
![Meshのshape, layout定義
mesh_shape = [("rows:2"), ("cols:2")]
layout_rules = [("batch", "rows"), ("hidden", "cols")]
mesh_impl = mtf.placement_mesh_impl.PlacementMeshImpl(
mesh_shape, layout_rules, mesh_devices)
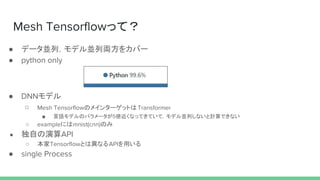
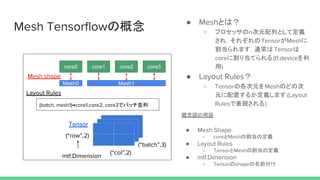
● meshのcore割当数を定義.
○ coreの割当数を定義(ex: rowsという名前のMeshに2個coreを割り当て)
○ [("rows:2"), ("cols:2")]
● meshとTensor Shapeの対応
○ mtf.Dimensionとmeshの対応を定義する
○ [("batch", "rows"), ("hidden", "cols")]
● PlacementMeshImpl(CPU,GPU向け)
○ 上記layout ruleに応じてvariableをデバイスに割当(session起動時)
○ 集合演算の実装がされている
○ TPU向けにSimdMeshImplというのも用意されている
Tensor
“cols”
“rows”
mtf.Dimension](https://image.slidesharecdn.com/meshtensorflow2-190306132736/85/Mesh-tensorflow-8-320.jpg)
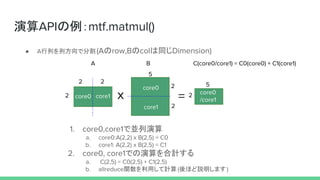
![演算のデバイス割り振り
def parallel(devices, fn, *args, **kwargs):
...
for i, device in enumerate(devices):
with tf.device(device):
with tf.variable_scope("parallel_%d" % i):
my_args = [x[i] for x in args]
my_kwargs = {k: v[i] for k, v in six.iteritems(kwargs)}
ret.append(fn(*my_args, **my_kwargs))
内部的にwith tf.deviceで各デバイスに演算を割り当てている](https://image.slidesharecdn.com/meshtensorflow2-190306132736/85/Mesh-tensorflow-9-320.jpg)

![演算API
# tensor importの例
x = mtf.import_tf_tensor(
mesh, tf.ones([50, 10]),
mtf.Shape([col_x, row_x]))
# 演算APIの例
f1 = mtf.relu(mtf.conv2d_with_blocks(
x, kernel1, strides=[1, 1, 1, 1], padding="SAME",
h_blocks_dim=row_blocks_dim, w_blocks_dim=col_blocks_dim))
● 演算APIにおける次元定義
○ 次元の定義はtf.Dimension()で定義した名前で行う。
○ この段階だとTensorの次元がどのように Mesh分割されるかは定義されない
● mtf.layer系 API
○ mtf.layer.dense, attention系など30個
○ Attention専用APIが多い(mtf.layer.masked_local_attention_1d()...)
● mtf 系 API
○ mtf.add, mtf.conv2d, mtf.maximum… 演算系APIが120個](https://image.slidesharecdn.com/meshtensorflow2-190306132736/85/Mesh-tensorflow-11-320.jpg)


![Allreduce(CPU,GPU)
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5
left center right center
tf.add
tf.add
tf.add
tf.add
SUM値 SUM値
tf.identitytf.identity
分配分配
for i in xrange(1, left_center + 1):
with tf.device(devices[i]):
left_sum = binary_reduction(left_sum, xs[i])
right_sum = xs[n-1]
演算デバイスを
制御
tf.add tf.add
1. 2グループに分割
2. 各グループ内でtf.add
3. 2グループ間でtf.add
4. tf.identityで分配
allreduceの方法](https://image.slidesharecdn.com/meshtensorflow2-190306132736/85/Mesh-tensorflow-16-320.jpg)

![mtf.Lowering, optimizer
# optimizerの登録
optimizer = mtf.optimize.SgdOptimizer()
update_ops = optimizer.apply_grads(var_grads, graph.trainable_variables)
lowering = mtf.Lowering(graph, {mesh: mesh_impl})
# optimizer operationのlowering
tf_update_ops = [lowering.lowered_operation(op) for op in update_ops]
tf_update_ops.append(tf.assign_add(global_step, 1))
train_op = tf.group(tf_update_ops)
● OptimizerはSGDとAdafactorのみサポート
● Lowering()の機能としてはmtf→tfの橋渡しで,tensorflowのAPIに変換したり
,実行デバイスの割当をおこなう
○ 演算ごとにどのようにloweringするか定義されている](https://image.slidesharecdn.com/meshtensorflow2-190306132736/85/Mesh-tensorflow-18-320.jpg)





![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=640&height=640&fit=bounds)





![[第2版]Python機械学習プログラミング 第14章](https://cdn.slidesharecdn.com/ss_thumbnails/14-190318023253-thumbnail.jpg?width=640&height=640&fit=bounds)




































