Downloaded 21 times






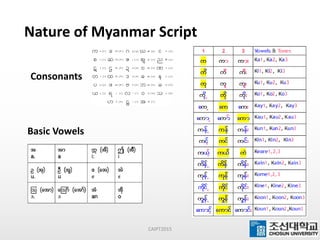
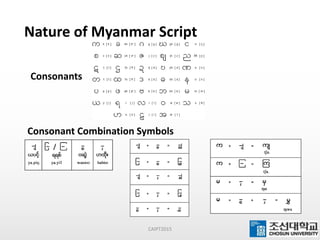
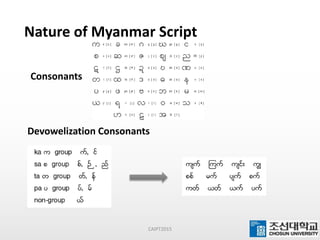
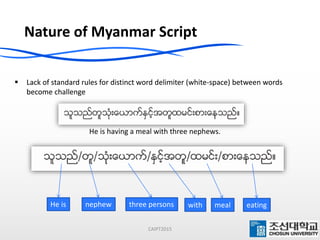

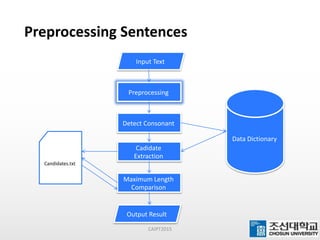
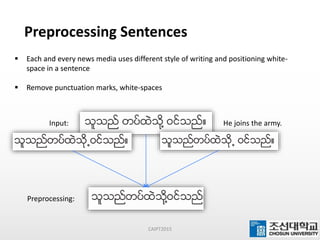
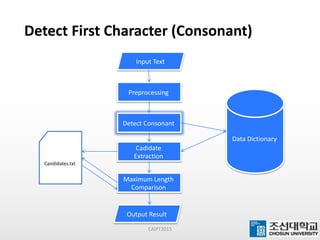

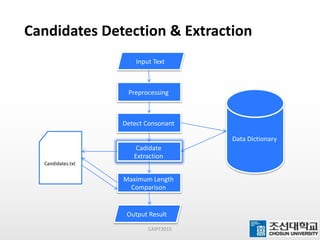
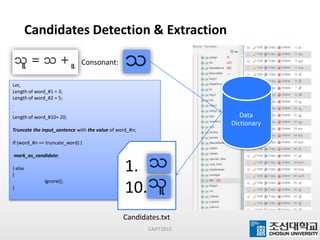
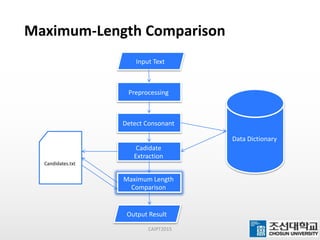

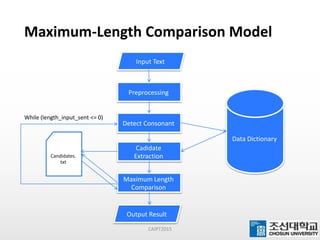





This document presents a maximum-length comparison method for automatic word segmentation of Myanmar text. It consists of four main steps: (1) preprocessing the sentences, (2) detecting the first character (consonant), (3) extracting candidate words from a data dictionary by truncating the input based on word lengths, and (4) comparing word lengths to select the candidate with the maximum length as the segmented word. The method was tested on a dataset of 30147 sentences, correctly segmenting 21577 words (92% accuracy). Future work could involve increasing the data dictionary and analyzing word meanings to improve segmentation for natural language processing tasks.





































