Downloaded 72 times


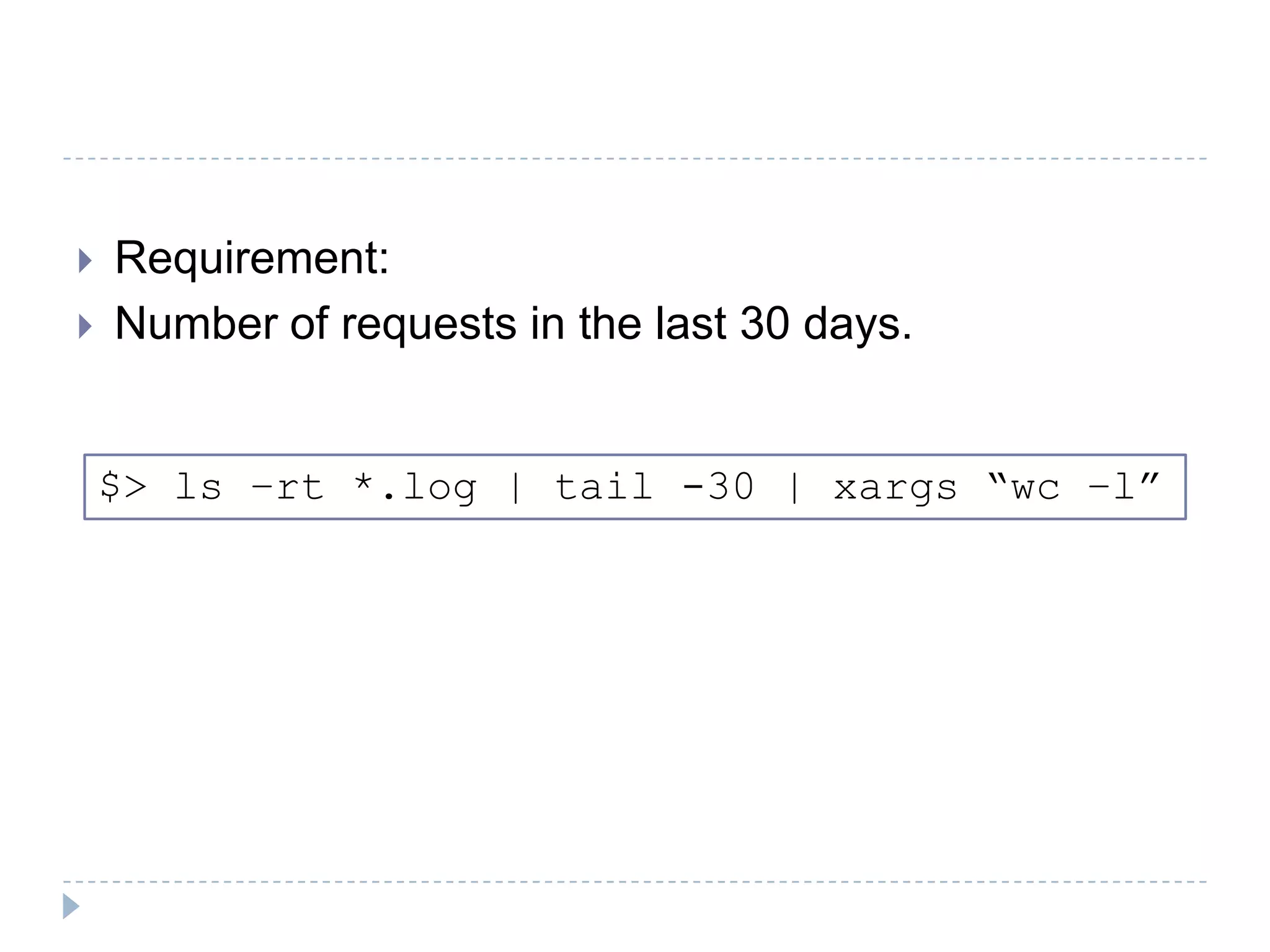
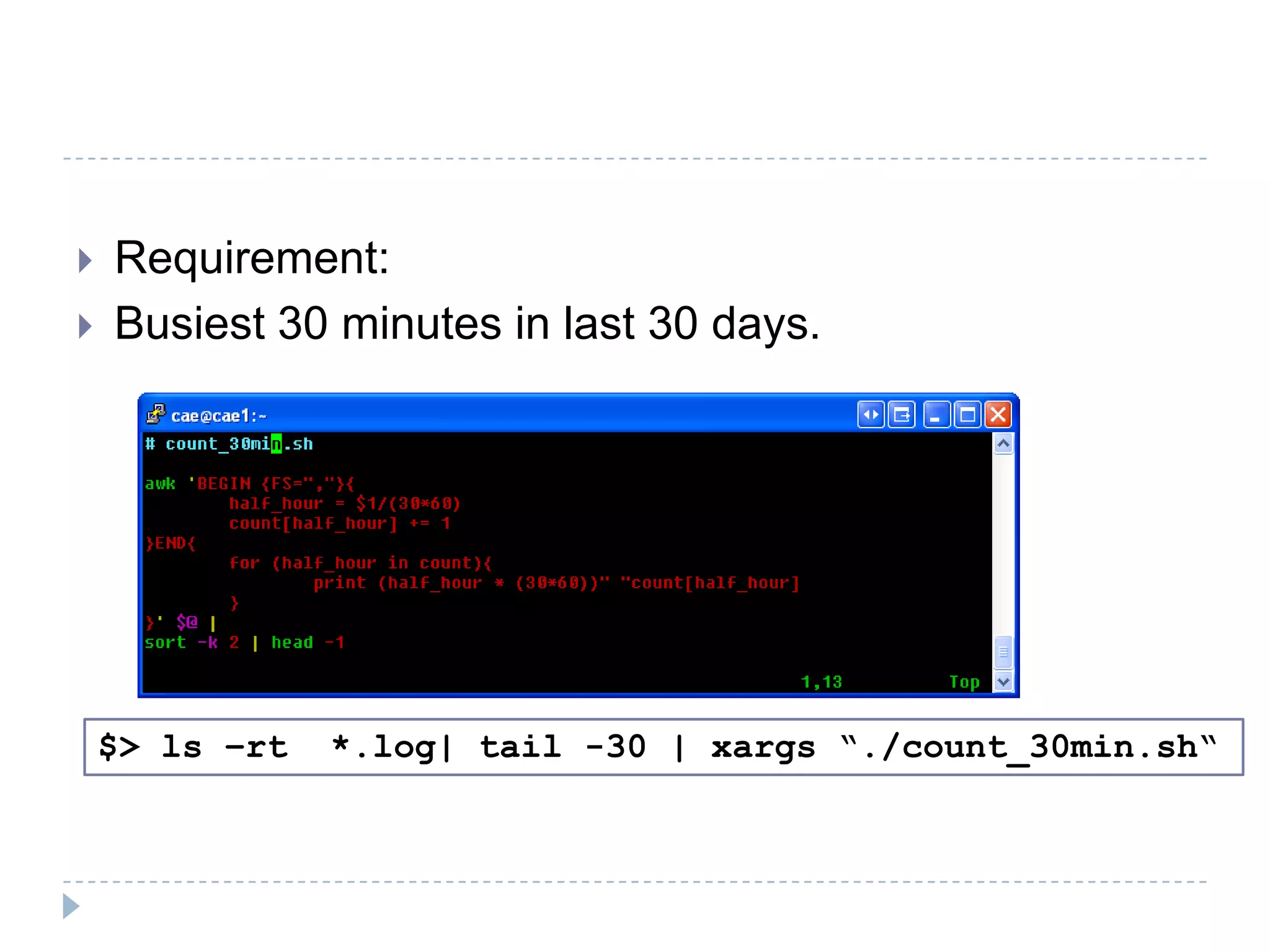
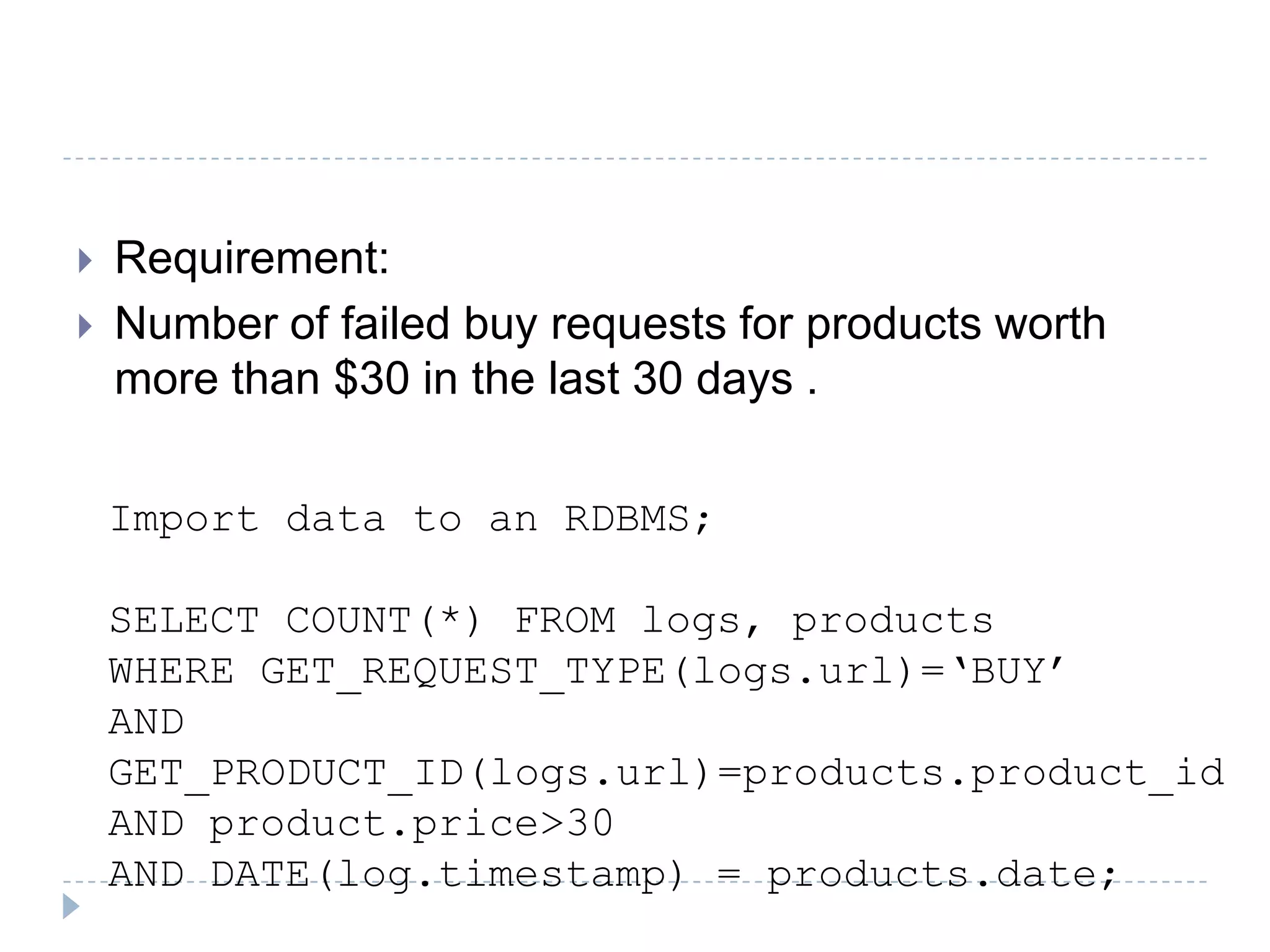




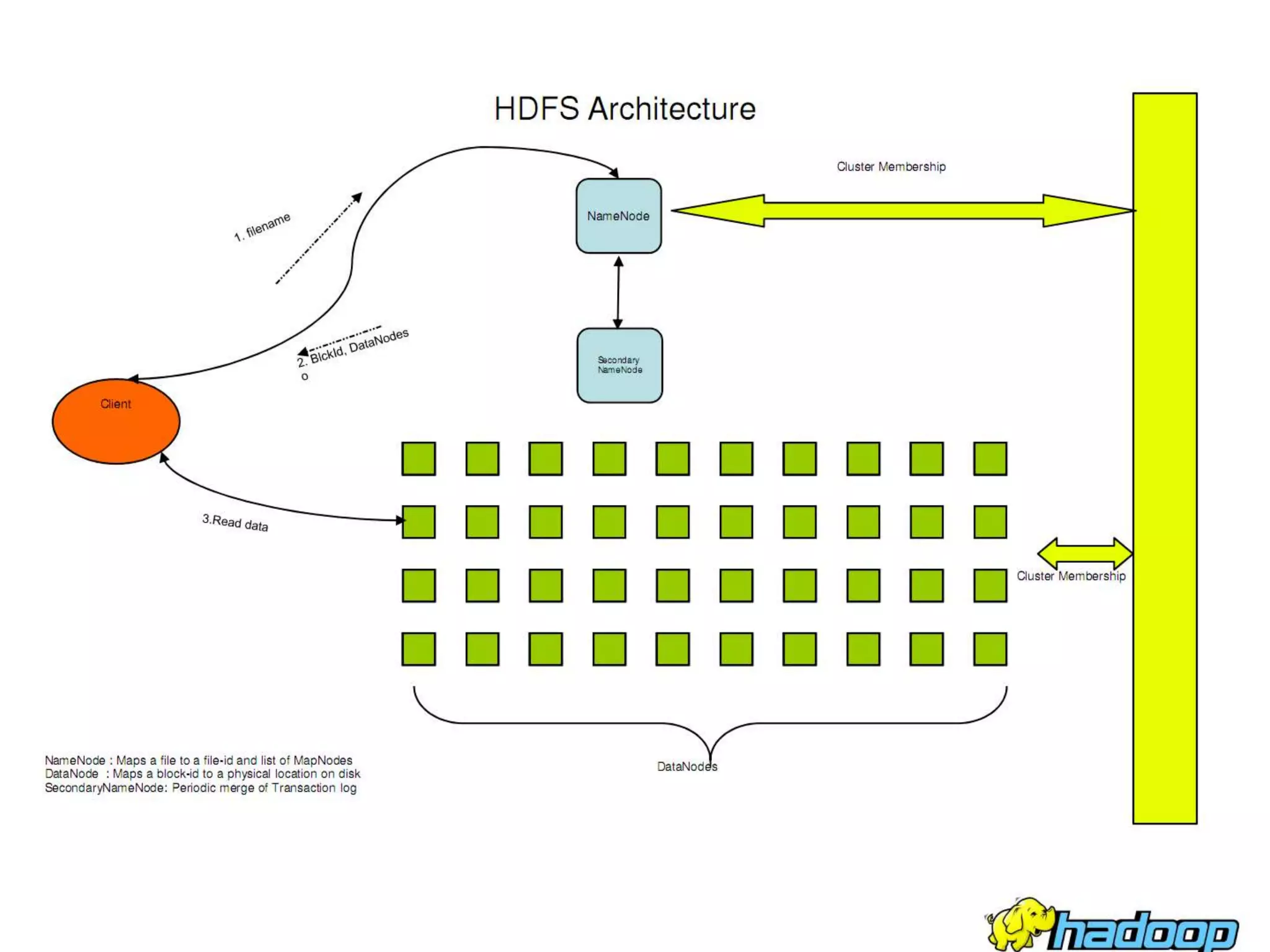
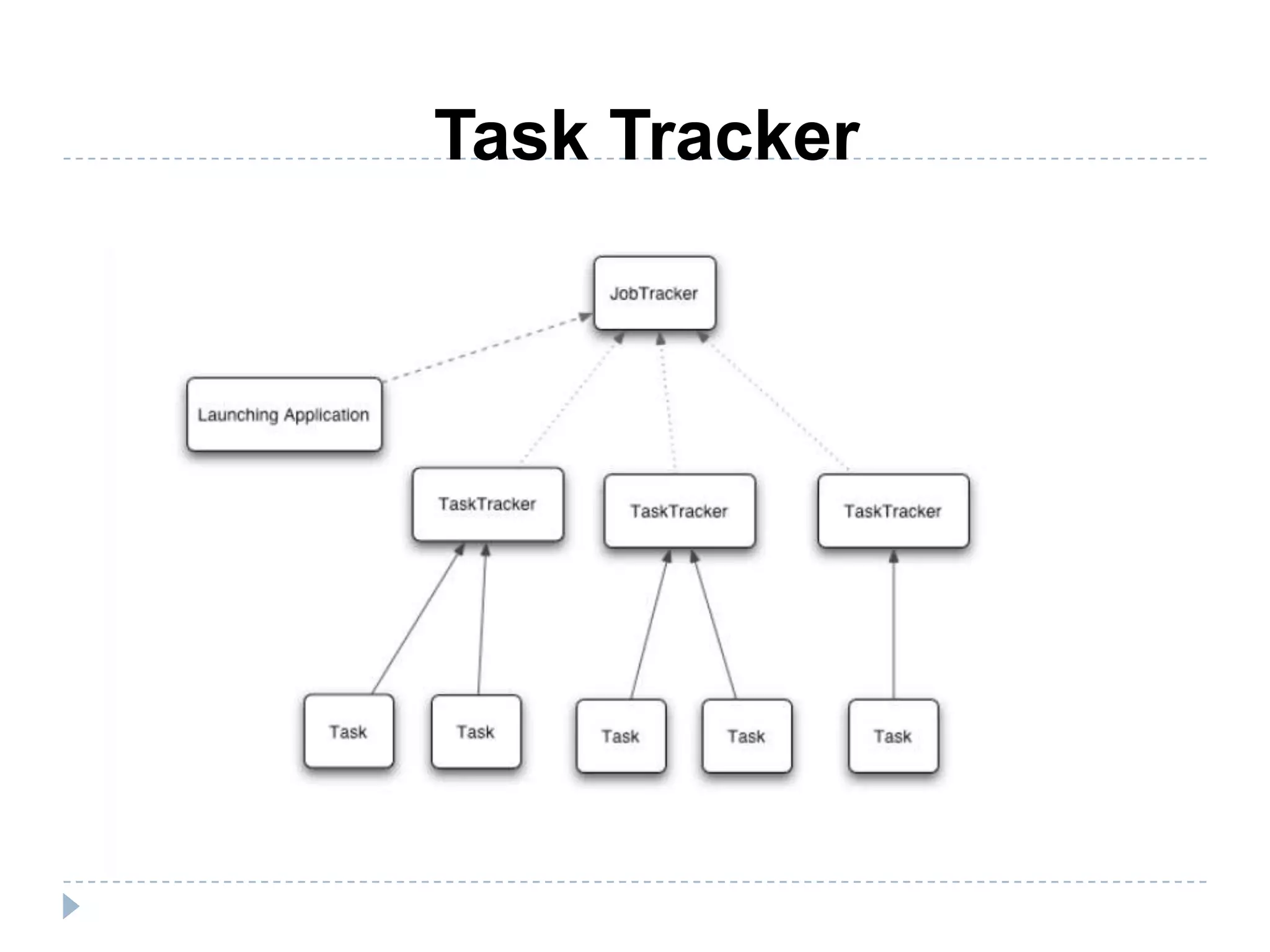
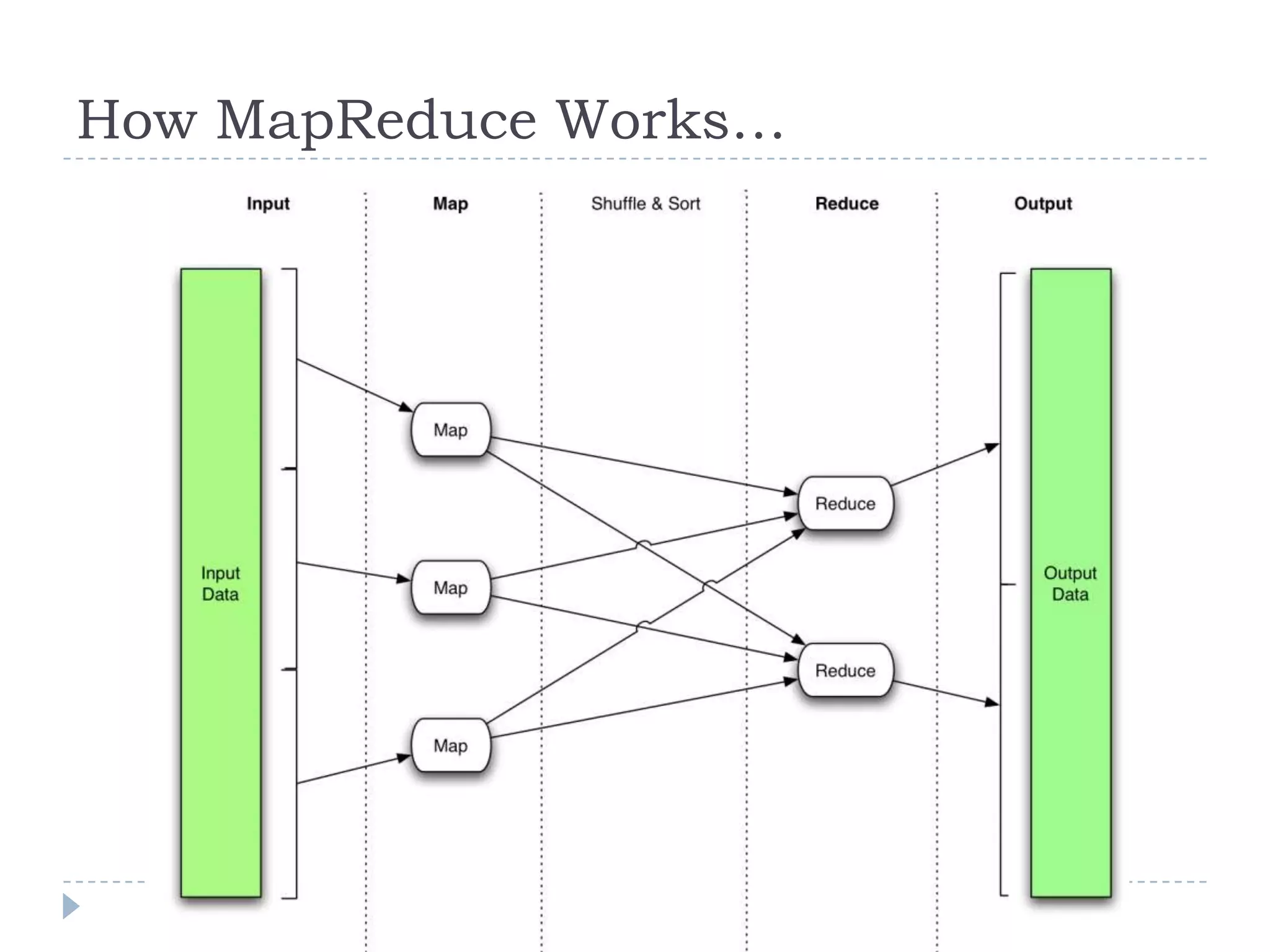



The document discusses the implementation of MapReduce using Hadoop for processing large datasets and performing specific tasks such as tracking requests and analyzing log data. It provides examples of querying data from logs and products, using both SQL and Pig Latin for data manipulation. The text highlights the advantages of Hadoop's distributed architecture and its capabilities for handling extensive data processing tasks efficiently.























































































