




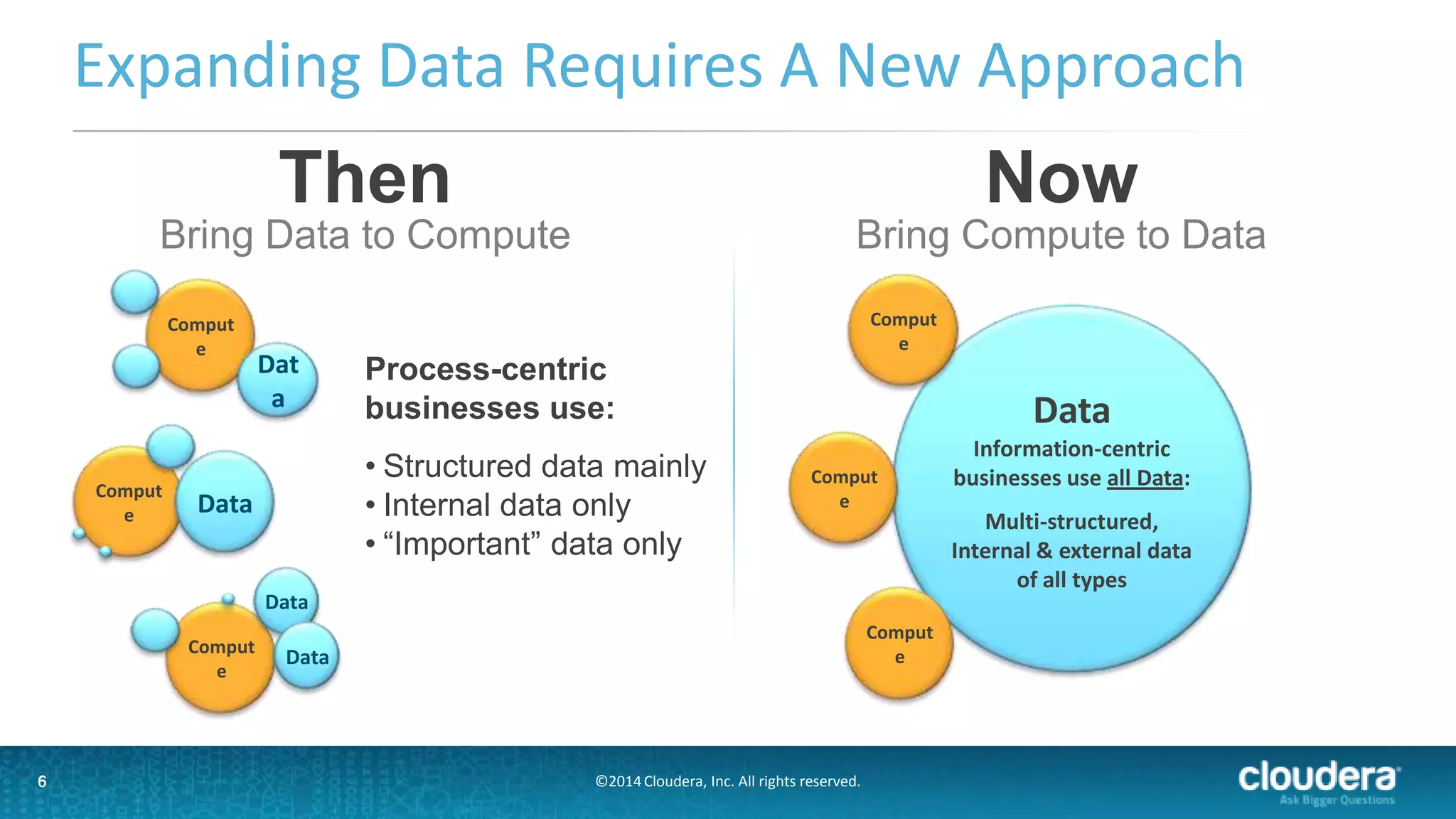

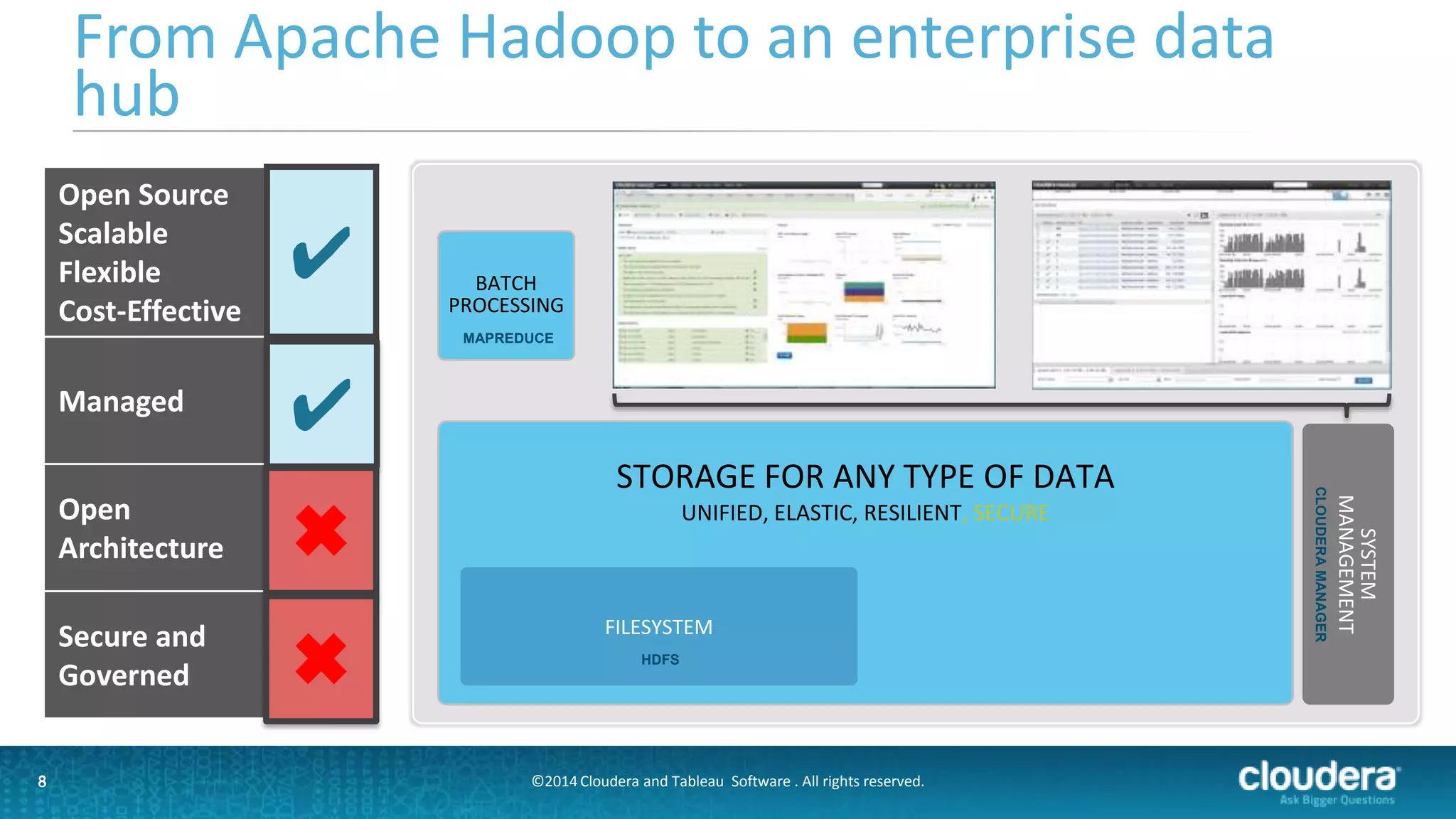
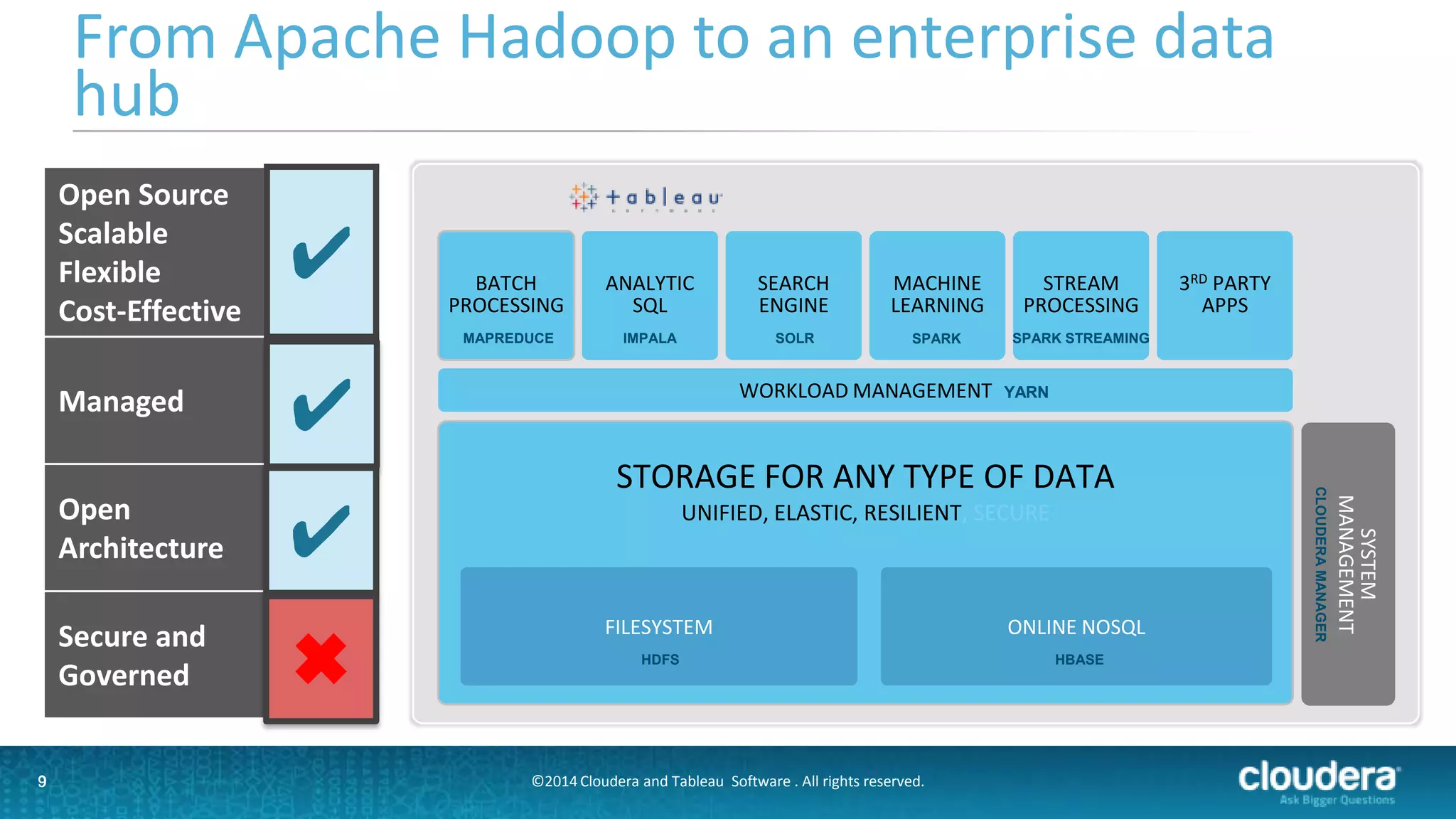
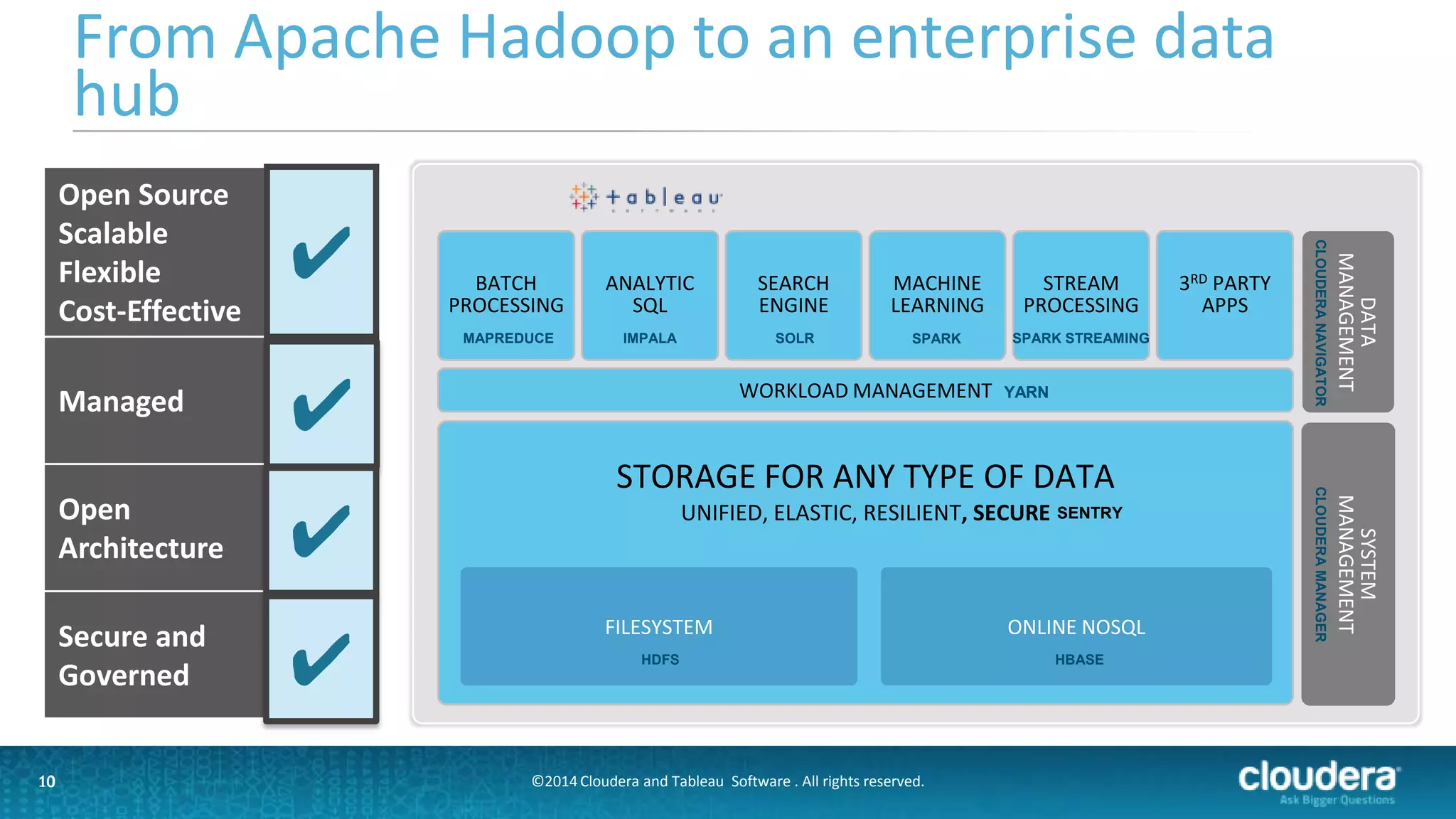
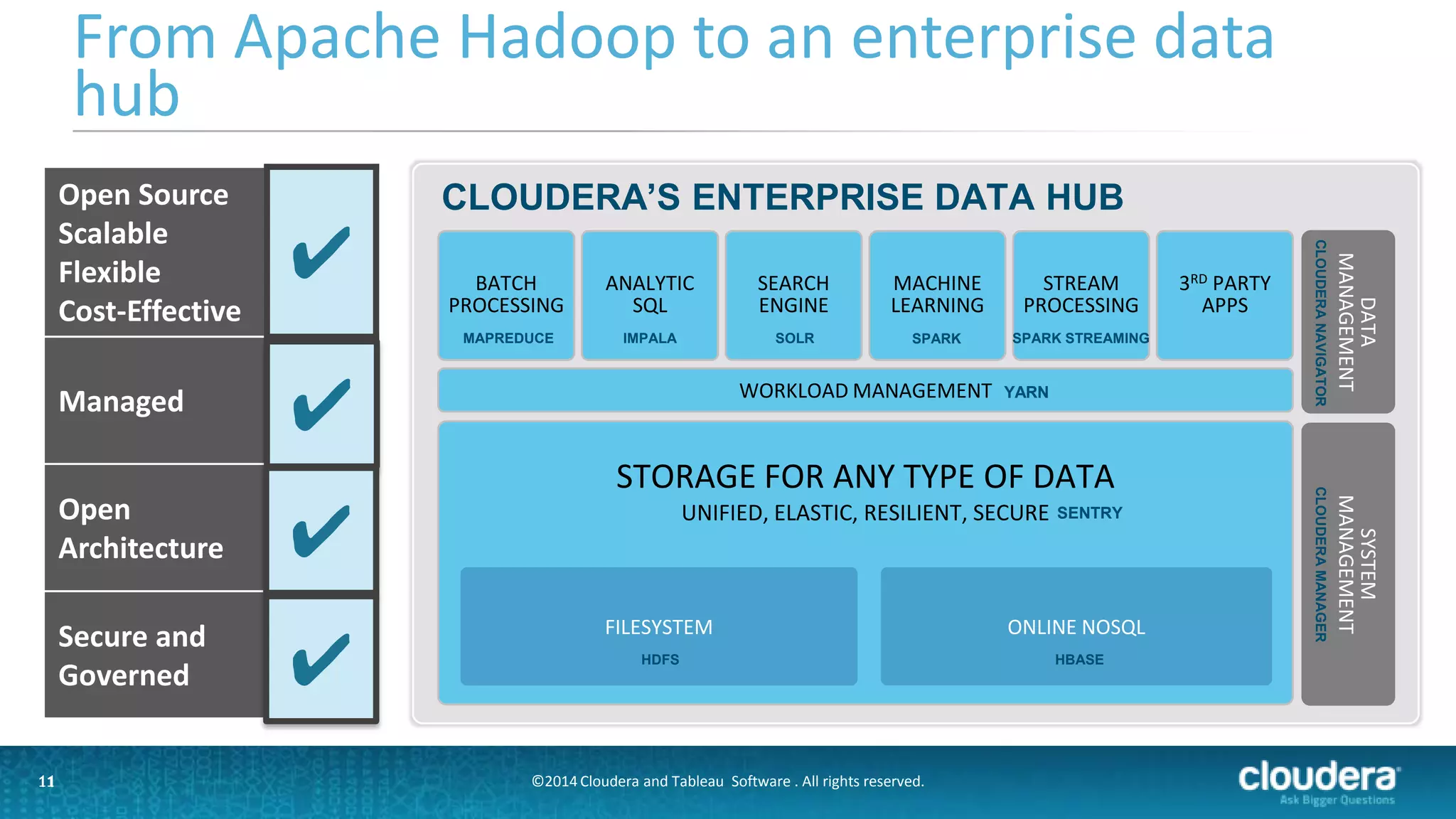




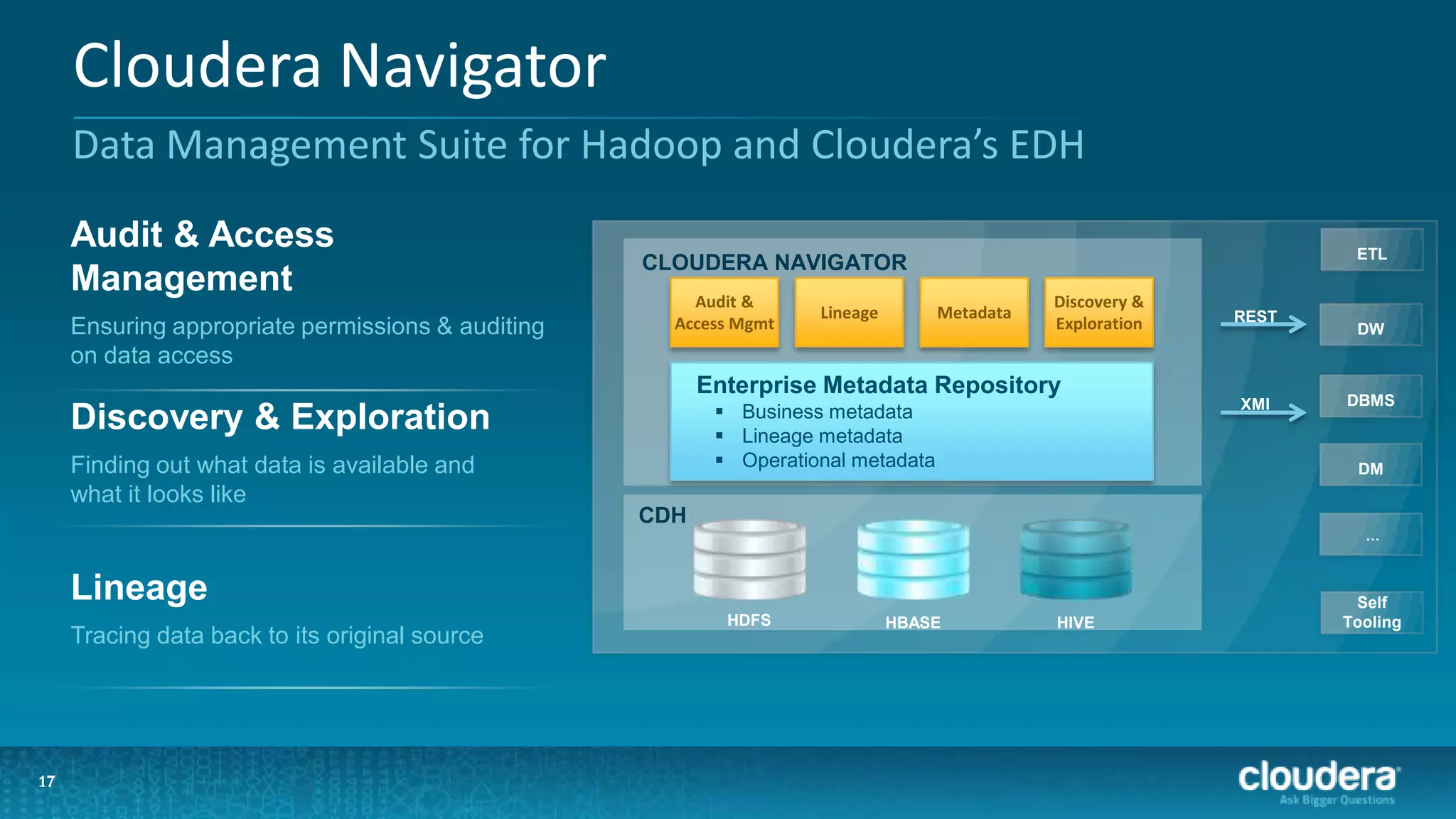



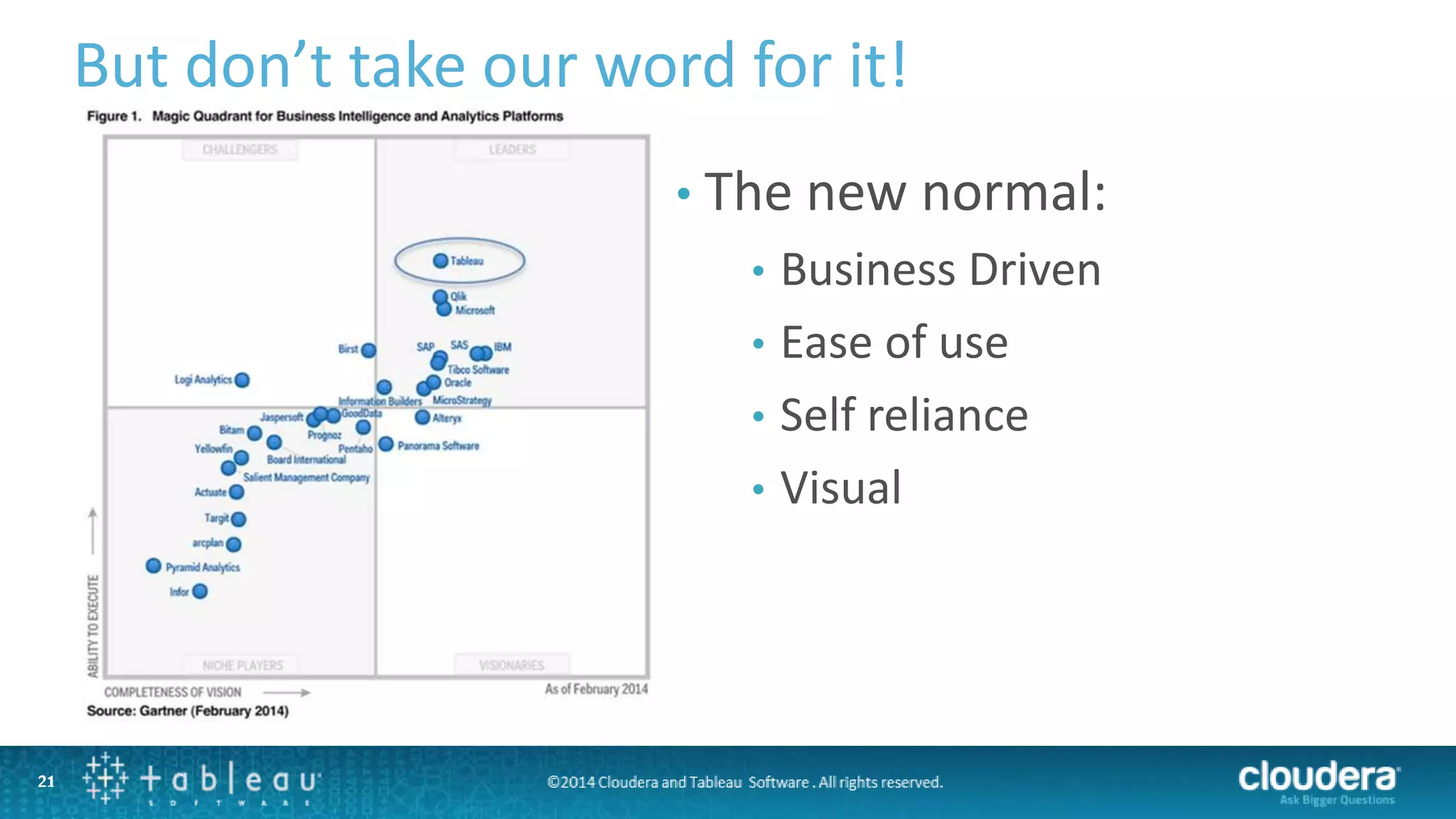








The document outlines a webinar on data governance and discovery led by Cloudera and Tableau, highlighting the shift from traditional data processing to an enterprise data hub powered by Hadoop. It discusses the importance of data governance, the challenges faced in data management, and introduces Cloudera Navigator and Tableau's data discovery capabilities. The focus is on enabling organizations to become data-driven through collaborative efforts between IT and business users.


















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




