Download to read offline






![Literature/ Related Work
• Malware analysis and detection have been significantly enhanced by the
application of deep learning and machine learning systems. Several studies
demonstrated the effectiveness of these approaches in identifying and
classifying malware based on various features, such as API calls, PE headers,
and behavior-based characteristics. Machine learning algorithms are being used
for fraud detection techniques[1-3].
• Many machine learning algorithms are also used in health sector[4-6], where as
some algorithms are used in disease detection in agriculture field. [7-9].
• Machine learning is used in security field to detect the malwares present in a
document. Analyze malware utilizing artificial intelligence and deep learning:
This book explores the effective use of deep learning and artificial intelligence
in malware detection and analysis, showcasing state-of-the-art tools,
frameworks, and methods in the field of cybersecurity and malware detection.
[10-12] paper discusses the superiority of deep learning methodologies over
old shallow machine learning approaches in malware analysis.
• The detection of malware in Windows systems based on static analysis depends
on multiple features.](https://image.slidesharecdn.com/pid1160presenttaion-250117085943-33a53120/85/MALWARE-ANALYSIS-USING-DEEP-LEARNING-PRE-6-320.jpg)








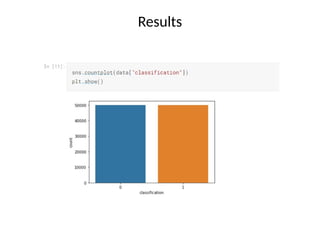



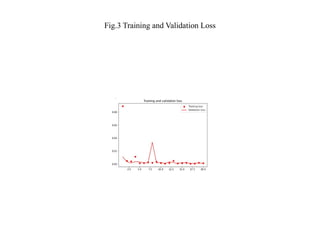




The document presents a study on malware analysis utilizing deep learning to enhance threat detection and response in cybersecurity. It emphasizes the superiority of deep learning models over traditional methods by leveraging their generalization capabilities to identify evolving malware without relying on specific signatures. The findings advocate for the integration of advanced machine learning algorithms to improve resilience against malicious activities and fraud detection within the digital realm.

























![Machine_Learning_Application_In_Automated_Vulnerability_Detection[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningapplicationinautomatedvulnerabilitydetection1-260209031240-0f6ff0fd-thumbnail.jpg?width=640&height=640&fit=bounds)









































